 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Unified Generative Framework based on Prompt Learning for Various Information Extraction Tasks
Sep 23, 2022
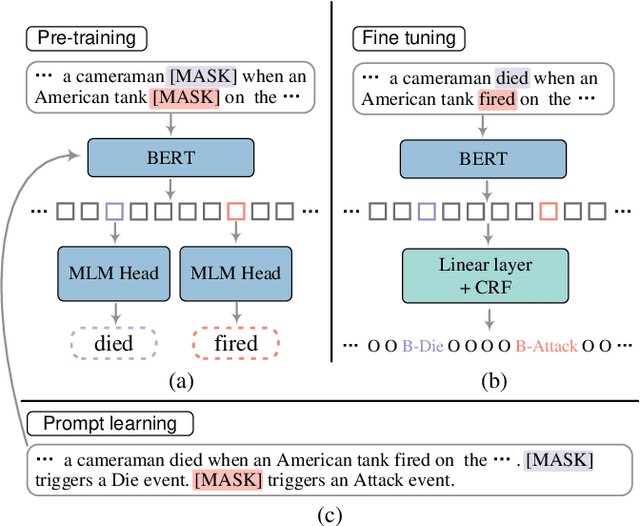
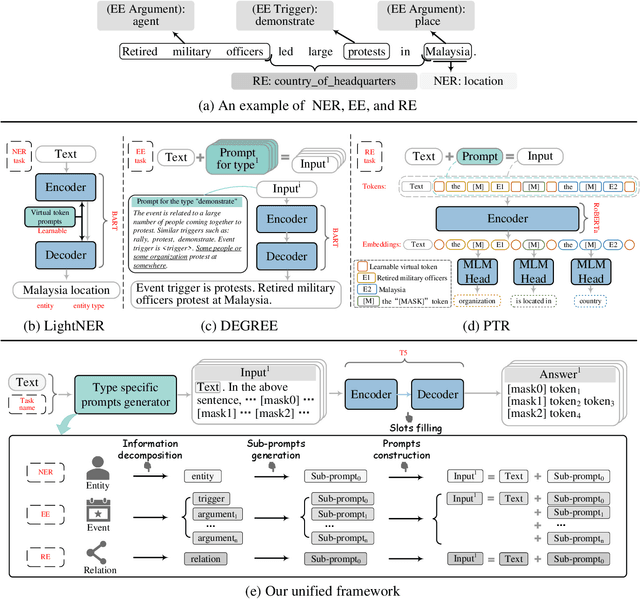
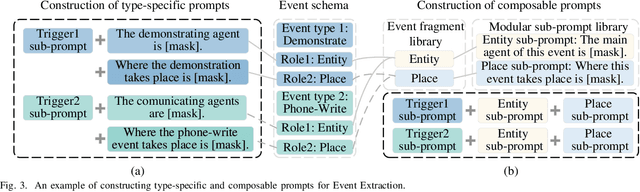
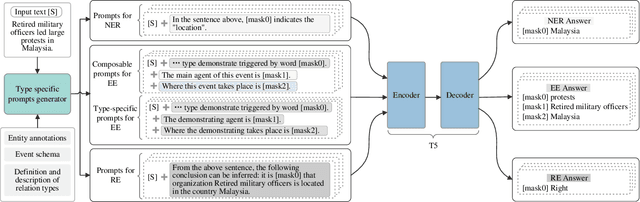
Prompt learning is an effective paradigm that bridges gaps between the pre-training tasks and the corresponding downstream applications. Approaches based on this paradigm have achieved great transcendent results in various applications. However, it still needs to be answered how to design a unified framework based on the prompt learning paradigm for various information extraction tasks. In this paper, we propose a novel composable prompt-based generative framework, which could be applied to a wide range of tasks in the field of Information Extraction. Specifically, we reformulate information extraction tasks into the form of filling slots in pre-designed type-specific prompts, which consist of one or multiple sub-prompts. A strategy of constructing composable prompts is proposed to enhance the generalization ability to extract events in data-scarce scenarios. Furthermore, to fit this framework, we transform Relation Extraction into the task of determining semantic consistency in prompts. The experimental results demonstrate that our approach surpasses compared baselines on real-world datasets in data-abundant and data-scarce scenarios. Further analysis of the proposed framework is presented, as well as numerical experiments conducted to investigate impact factors of performance on various tasks.
Self-Supervised Learning for Place Representation Generalization across Appearance Changes
Mar 09, 2023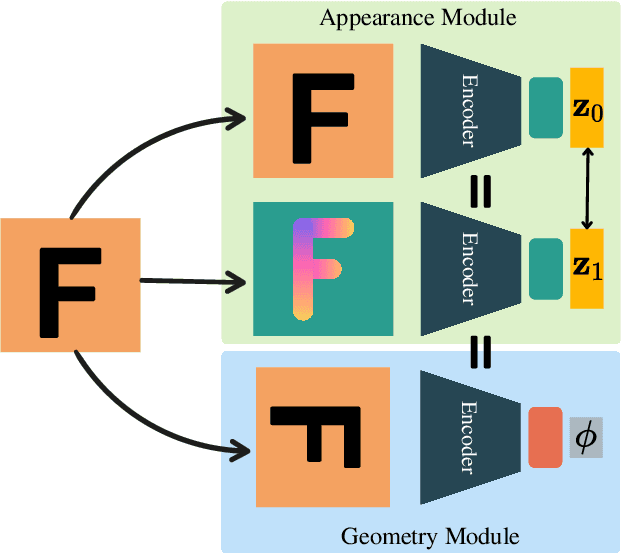
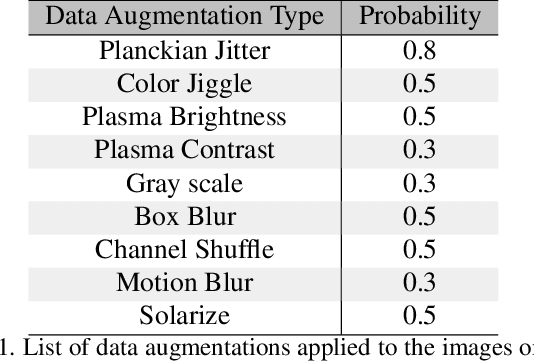
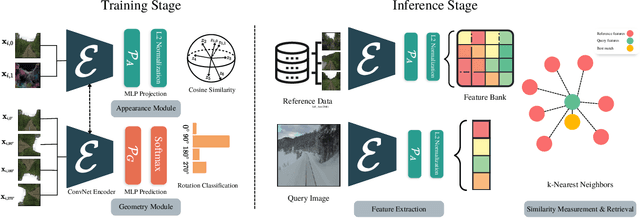
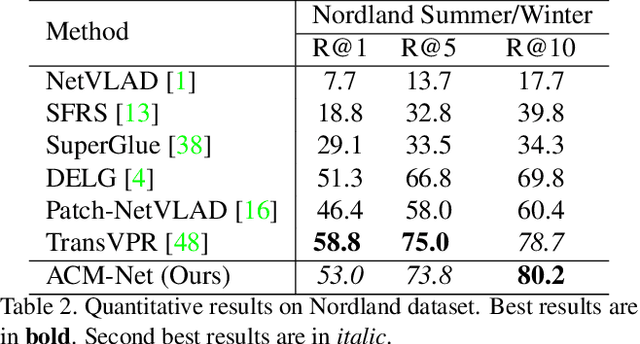
Visual place recognition is a key to unlocking spatial navigation for animals, humans and robots. While state-of-the-art approaches are trained in a supervised manner and therefore hardly capture the information needed for generalizing to unusual conditions, we argue that self-supervised learning may help abstracting the place representation so that it can be foreseen, irrespective of the conditions. More precisely, in this paper, we investigate learning features that are robust to appearance modifications while sensitive to geometric transformations in a self-supervised manner. This dual-purpose training is made possible by combining the two self-supervision main paradigms, \textit{i.e.} contrastive and predictive learning. Our results on standard benchmarks reveal that jointly learning such appearance-robust and geometry-sensitive image descriptors leads to competitive visual place recognition results across adverse seasonal and illumination conditions, without requiring any human-annotated labels.
Types of Approaches, Applications and Challenges in the Development of Sentiment Analysis Systems
Mar 09, 2023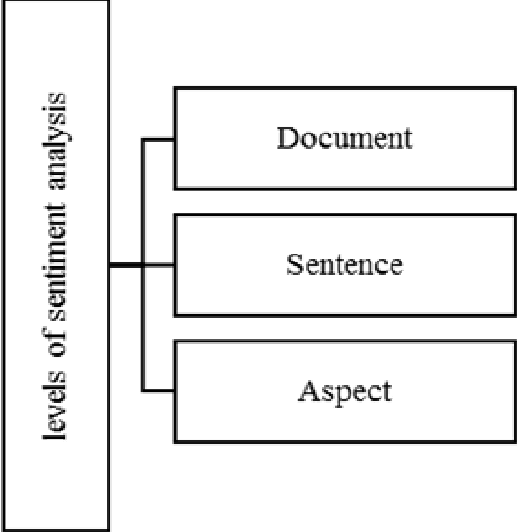
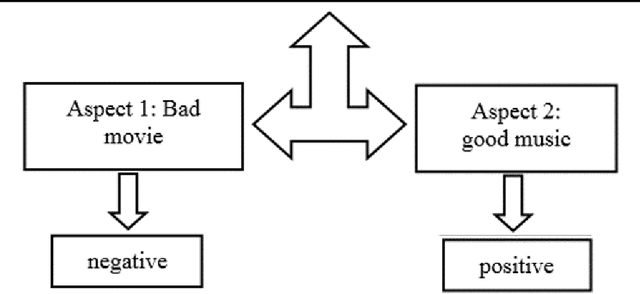
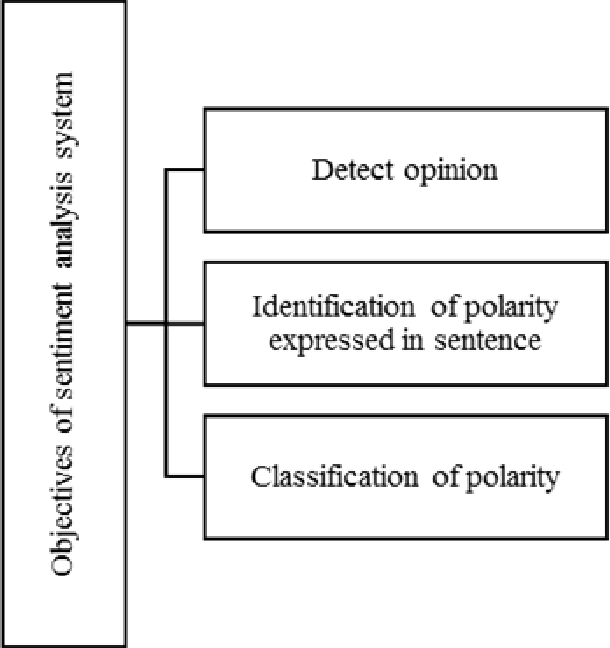

Today, the web has become a mandatory platform to express users' opinions, emotions and feelings about various events. Every person using his smartphone can give his opinion about the purchase of a product, the occurrence of an accident, the occurrence of a new disease, etc. in blogs and social networks such as (Twitter, WhatsApp, Telegram and Instagram) register. Therefore, millions of comments are recorded daily and it creates a huge volume of unstructured text data that can extract useful knowledge from this type of data by using natural language processing methods. Sentiment analysis is one of the important applications of natural language processing and machine learning, which allows us to analyze the sentiments of comments and other textual information recorded by web users. Therefore, the analysis of sentiments, approaches and challenges in this field will be explained in the following.
MMCosine: Multi-Modal Cosine Loss Towards Balanced Audio-Visual Fine-Grained Learning
Mar 11, 2023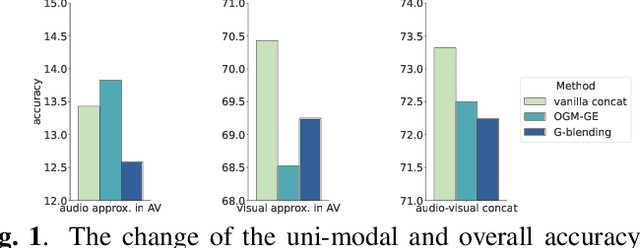
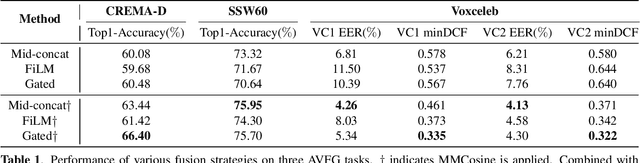
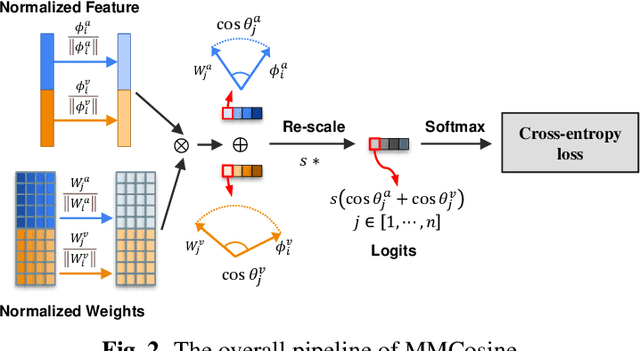
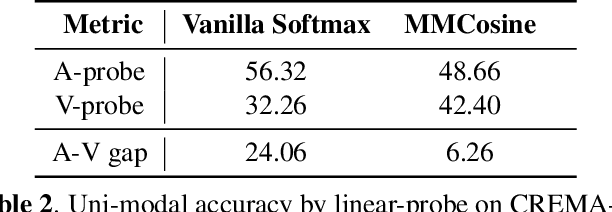
Audio-visual learning helps to comprehensively understand the world by fusing practical information from multiple modalities. However, recent studies show that the imbalanced optimization of uni-modal encoders in a joint-learning model is a bottleneck to enhancing the model's performance. We further find that the up-to-date imbalance-mitigating methods fail on some audio-visual fine-grained tasks, which have a higher demand for distinguishable feature distribution. Fueled by the success of cosine loss that builds hyperspherical feature spaces and achieves lower intra-class angular variability, this paper proposes Multi-Modal Cosine loss, MMCosine. It performs a modality-wise $L_2$ normalization to features and weights towards balanced and better multi-modal fine-grained learning. We demonstrate that our method can alleviate the imbalanced optimization from the perspective of weight norm and fully exploit the discriminability of the cosine metric. Extensive experiments prove the effectiveness of our method and the versatility with advanced multi-modal fusion strategies and up-to-date imbalance-mitigating methods.
Semantic-Preserving Augmentation for Robust Image-Text Retrieval
Mar 10, 2023

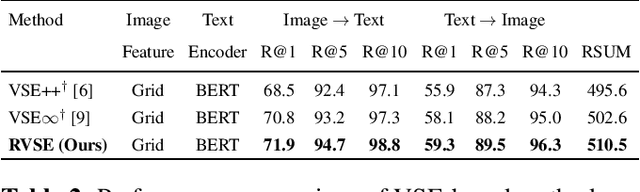
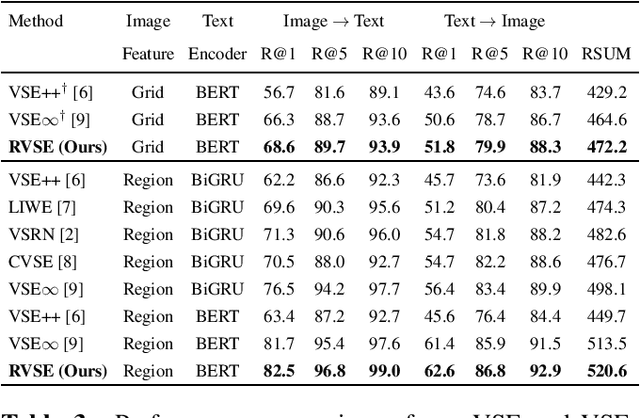
Image text retrieval is a task to search for the proper textual descriptions of the visual world and vice versa. One challenge of this task is the vulnerability to input image and text corruptions. Such corruptions are often unobserved during the training, and degrade the retrieval model decision quality substantially. In this paper, we propose a novel image text retrieval technique, referred to as robust visual semantic embedding (RVSE), which consists of novel image-based and text-based augmentation techniques called semantic preserving augmentation for image (SPAugI) and text (SPAugT). Since SPAugI and SPAugT change the original data in a way that its semantic information is preserved, we enforce the feature extractors to generate semantic aware embedding vectors regardless of the corruption, improving the model robustness significantly. From extensive experiments using benchmark datasets, we show that RVSE outperforms conventional retrieval schemes in terms of image-text retrieval performance.
Clustering with minimum spanning trees: How good can it be?
Mar 10, 2023


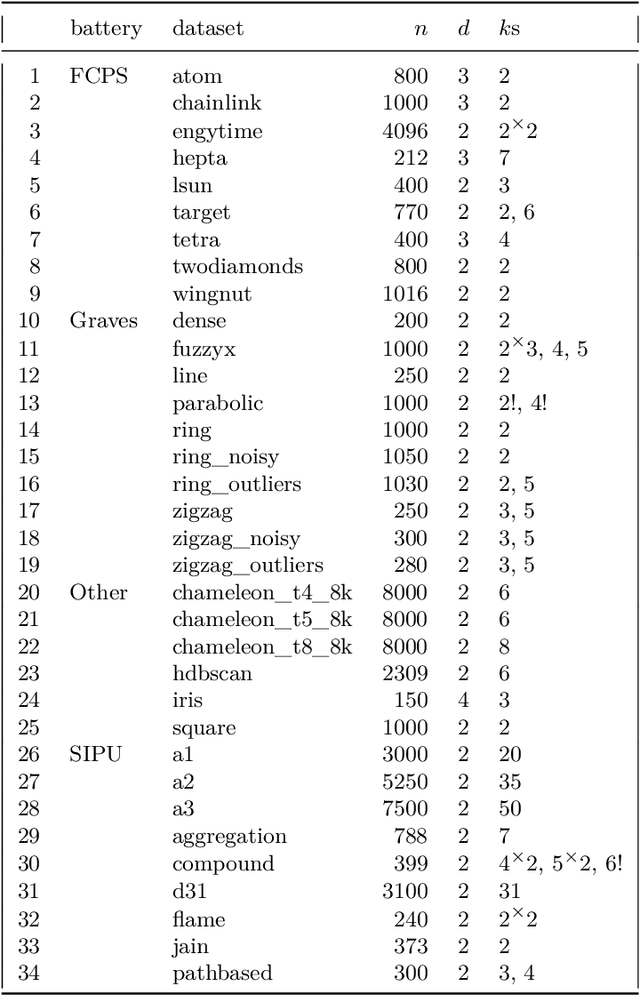
Minimum spanning trees (MSTs) provide a convenient representation of datasets in numerous pattern recognition activities. Moreover, they are relatively fast to compute. In this paper, we quantify the extent to which they can be meaningful in data clustering tasks. By identifying the upper bounds for the agreement between the best (oracle) algorithm and the expert labels from a large battery of benchmark data, we discover that MST methods can overall be very competitive. Next, instead of proposing yet another algorithm that performs well on a limited set of examples, we review, study, extend, and generalise existing, the state-of-the-art MST-based partitioning schemes, which leads to a few new and interesting approaches. It turns out that the Genie method and the information-theoretic approaches often outperform the non-MST algorithms such as k-means, Gaussian mixtures, spectral clustering, BIRCH, and classical hierarchical agglomerative procedures.
Interactive Segmentation as Gaussian Process Classification
Feb 28, 2023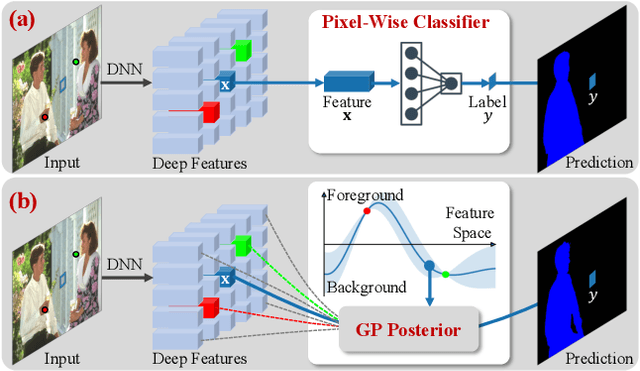
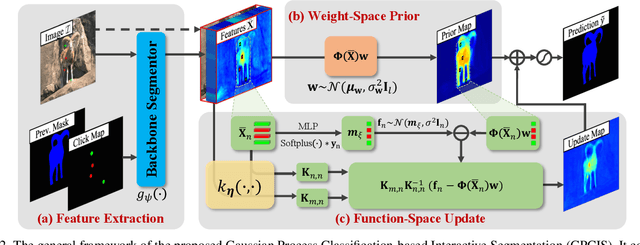
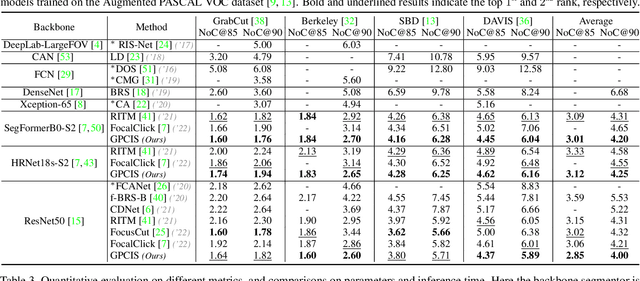

Click-based interactive segmentation (IS) aims to extract the target objects under user interaction. For this task, most of the current deep learning (DL)-based methods mainly follow the general pipelines of semantic segmentation. Albeit achieving promising performance, they do not fully and explicitly utilize and propagate the click information, inevitably leading to unsatisfactory segmentation results, even at clicked points. Against this issue, in this paper, we propose to formulate the IS task as a Gaussian process (GP)-based pixel-wise binary classification model on each image. To solve this model, we utilize amortized variational inference to approximate the intractable GP posterior in a data-driven manner and then decouple the approximated GP posterior into double space forms for efficient sampling with linear complexity. Then, we correspondingly construct a GP classification framework, named GPCIS, which is integrated with the deep kernel learning mechanism for more flexibility. The main specificities of the proposed GPCIS lie in: 1) Under the explicit guidance of the derived GP posterior, the information contained in clicks can be finely propagated to the entire image and then boost the segmentation; 2) The accuracy of predictions at clicks has good theoretical support. These merits of GPCIS as well as its good generality and high efficiency are substantiated by comprehensive experiments on several benchmarks, as compared with representative methods both quantitatively and qualitatively.
DKT-STDRL: Spatial and Temporal Representation Learning Enhanced Deep Knowledge Tracing for Learning Performance Prediction
Feb 15, 2023
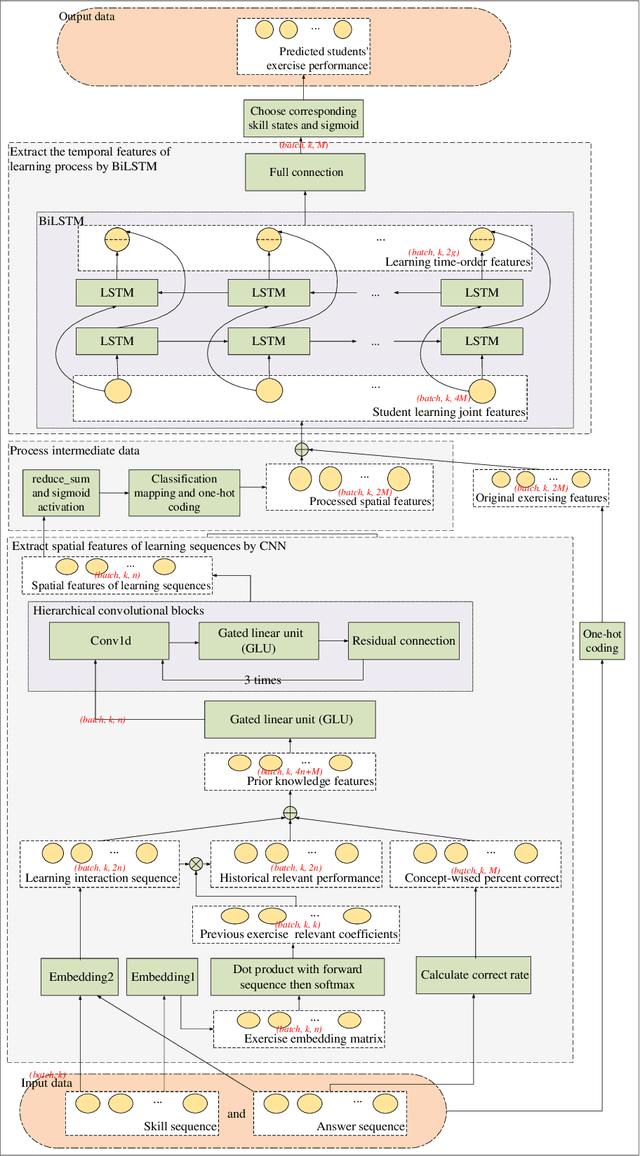


Knowledge tracing (KT) serves as a primary part of intelligent education systems. Most current KTs either rely on expert judgments or only exploit a single network structure, which affects the full expression of learning features. To adequately mine features of students' learning process, Deep Knowledge Tracing Based on Spatial and Temporal Deep Representation Learning for Learning Performance Prediction (DKT-STDRL) is proposed in this paper. DKT-STDRL extracts spatial features from students' learning history sequence, and then further extracts temporal features to extract deeper hidden information. Specifically, firstly, the DKT-STDRL model uses CNN to extract the spatial feature information of students' exercise sequences. Then, the spatial features are connected with the original students' exercise features as joint learning features. Then, the joint features are input into the BiLSTM part. Finally, the BiLSTM part extracts the temporal features from the joint learning features to obtain the prediction information of whether the students answer correctly at the next time step. Experiments on the public education datasets ASSISTment2009, ASSISTment2015, Synthetic-5, ASSISTchall, and Statics2011 prove that DKT-STDRL can achieve better prediction effects than DKT and CKT.
Neural networks for learning personality traits from natural language
Feb 23, 2023Personality is considered one of the most influential research topics in psychology, as it predicts many consequential outcomes such as mental and physical health and explains human behaviour. With the widespread use of social networks as a means of communication, it is becoming increasingly important to develop models that can automatically and accurately read the essence of individuals based solely on their writing. In particular, the convergence of social and computer sciences has led researchers to develop automatic approaches for extracting and studying "hidden" information in textual data on the internet. The nature of this thesis project is highly experimental, and the motivation behind this work is to present detailed analyses on the topic, as currently there are no significant investigations of this kind. The objective is to identify an adequate semantic space that allows for defining the personality of the object to which a certain text refers. The starting point is a dictionary of adjectives that psychological literature defines as markers of the five major personality traits, or Big Five. In this work, we started with the implementation of fully-connected neural networks as a basis for understanding how simple deep learning models can provide information on hidden personality characteristics. Finally, we use a class of distributional algorithms invented in 2013 by Tomas Mikolov, which consists of using a convolutional neural network that learns the contexts of words in an unsupervised way. In this way, we construct an embedding that contains the semantic information on the text, obtaining a kind of "geometry of meaning" in which concepts are translated into linear relationships. With this last experiment, we hypothesize that an individual writing style is largely coupled with their personality traits.
The Joint Weighted Average (JWA) Operator
Feb 23, 2023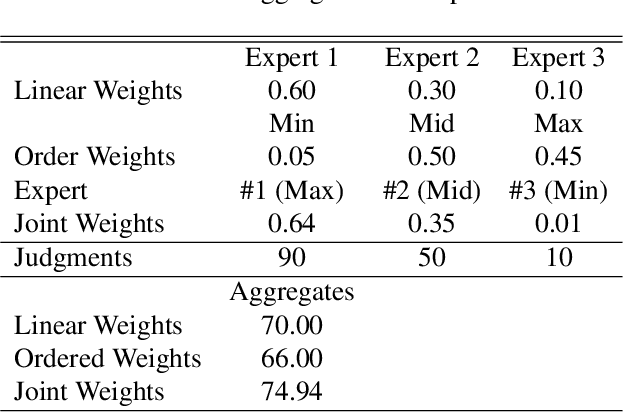
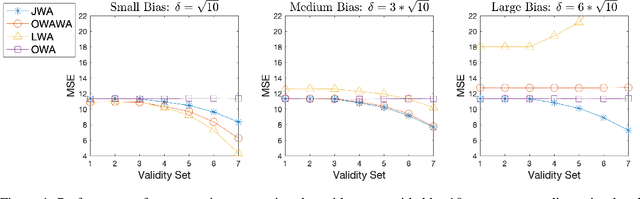
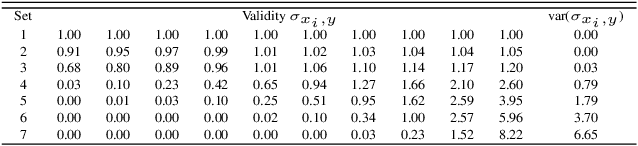
Information aggregation is a vital tool for human and machine decision making, especially in the presence of noise and uncertainty. Traditionally, approaches to aggregation broadly diverge into two categories, those which attribute a worth or weight to information sources and those which attribute said worth to the evidence arising from said sources. The latter is pervasive in particular in the physical sciences, underpinning linear order statistics and enabling non-linear aggregation. The former is popular in the social sciences, providing interpretable insight on the sources. Thus far, limited work has sought to integrate both approaches, applying either approach to a different degree. In this paper, we put forward an approach which integrates--rather than partially applies--both approaches, resulting in a novel joint weighted averaging operator. We show how this operator provides a systematic approach to integrating a priori beliefs about the worth of both source and evidence by leveraging compositional geometry--producing results unachievable by traditional operators. We conclude and highlight the potential of the operator across disciplines, from machine learning to psychology.