 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Real-Time Joint Simulation of LiDAR Perception and Motion Planning for Automated Driving
May 11, 2023
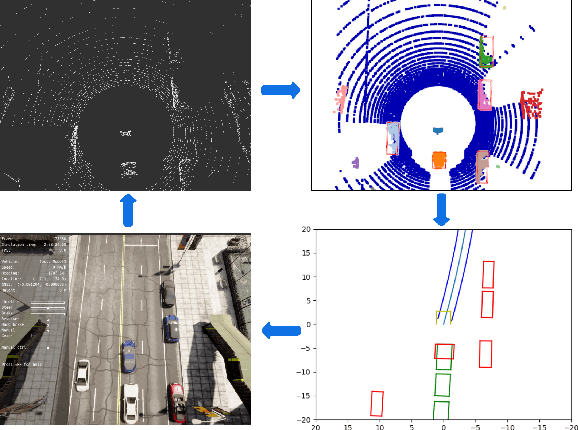
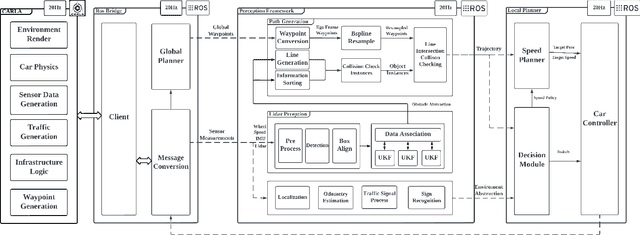
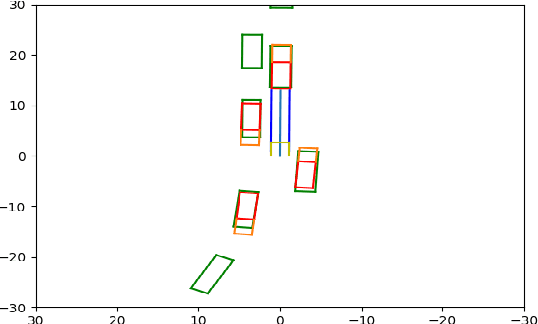
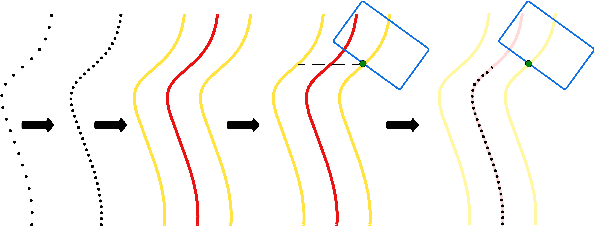
Real-time perception and motion planning are two crucial tasks for autonomous driving. While there are many research works focused on improving the performance of perception and motion planning individually, it is still not clear how a perception error may adversely impact the motion planning results. In this work, we propose a joint simulation framework with LiDAR-based perception and motion planning for real-time automated driving. Taking the sensor input from the CARLA simulator with additive noise, a LiDAR perception system is designed to detect and track all surrounding vehicles and to provide precise orientation and velocity information. Next, we introduce a new collision bound representation that relaxes the communication cost between the perception module and the motion planner. A novel collision checking algorithm is implemented using line intersection checking that is more efficient for long distance range in comparing to the traditional method of occupancy grid. We evaluate the joint simulation framework in CARLA for urban driving scenarios. Experiments show that our proposed automated driving system can execute at 25 Hz, which meets the real-time requirement. The LiDAR perception system has high accuracy within 20 meters when evaluated with the ground truth. The motion planning results in consistent safe distance keeping when tested in CARLA urban driving scenarios.
Salient Mask-Guided Vision Transformer for Fine-Grained Classification
May 11, 2023
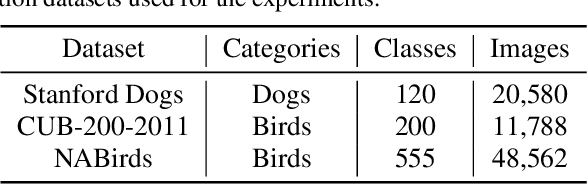
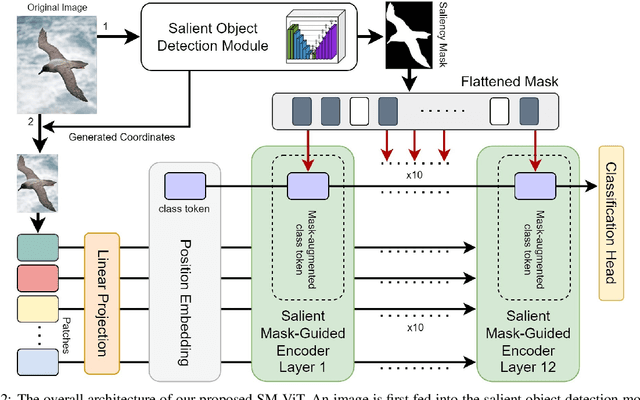
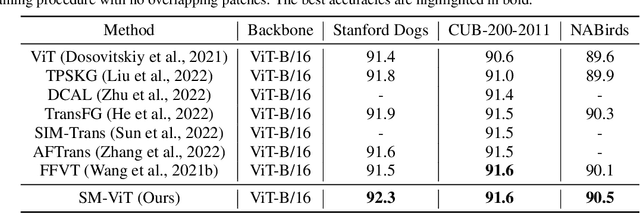
Fine-grained visual classification (FGVC) is a challenging computer vision problem, where the task is to automatically recognise objects from subordinate categories. One of its main difficulties is capturing the most discriminative inter-class variances among visually similar classes. Recently, methods with Vision Transformer (ViT) have demonstrated noticeable achievements in FGVC, generally by employing the self-attention mechanism with additional resource-consuming techniques to distinguish potentially discriminative regions while disregarding the rest. However, such approaches may struggle to effectively focus on truly discriminative regions due to only relying on the inherent self-attention mechanism, resulting in the classification token likely aggregating global information from less-important background patches. Moreover, due to the immense lack of the datapoints, classifiers may fail to find the most helpful inter-class distinguishing features, since other unrelated but distinctive background regions may be falsely recognised as being valuable. To this end, we introduce a simple yet effective Salient Mask-Guided Vision Transformer (SM-ViT), where the discriminability of the standard ViT`s attention maps is boosted through salient masking of potentially discriminative foreground regions. Extensive experiments demonstrate that with the standard training procedure our SM-ViT achieves state-of-the-art performance on popular FGVC benchmarks among existing ViT-based approaches while requiring fewer resources and lower input image resolution.
* Accepted by VISAPP 2023 (Best Student Paper Award)
A fast topological approach for predicting anomalies in time-varying graphs
May 11, 2023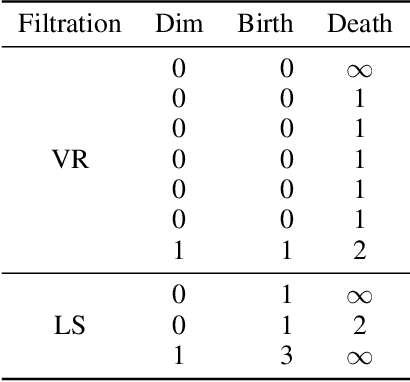


Large time-varying graphs are increasingly common in financial, social and biological settings. Feature extraction that efficiently encodes the complex structure of sparse, multi-layered, dynamic graphs presents computational and methodological challenges. In the past decade, a persistence diagram (PD) from topological data analysis (TDA) has become a popular descriptor of shape of data with a well-defined distance between points. However, applications of TDA to graphs, where there is no intrinsic concept of distance between the nodes, remain largely unexplored. This paper addresses this gap in the literature by introducing a computationally efficient framework to extract shape information from graph data. Our framework has two main steps: first, we compute a PD using the so-called lower-star filtration which utilizes quantitative node attributes, and then vectorize it by averaging the associated Betti function over successive scale values on a one-dimensional grid. Our approach avoids embedding a graph into a metric space and has stability properties against input noise. In simulation studies, we show that the proposed vector summary leads to improved change point detection rate in time-varying graphs. In a real data application, our approach provides up to 22% gain in anomalous price prediction for the Ethereum cryptocurrency transaction networks.
Multi-Tier Client Selection for Mobile Federated Learning Networks
May 11, 2023
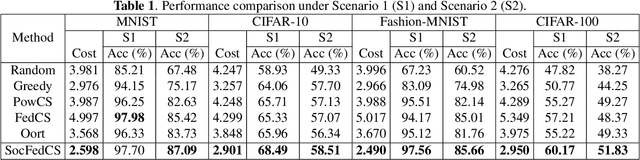
Federated learning (FL), which addresses data privacy issues by training models on resource-constrained mobile devices in a distributed manner, has attracted significant research attention. However, the problem of optimizing FL client selection in mobile federated learning networks (MFLNs), where devices move in and out of each others' coverage and no FL server knows all the data owners, remains open. To bridge this gap, we propose a first-of-its-kind \underline{Soc}ially-aware \underline{Fed}erated \underline{C}lient \underline{S}election (SocFedCS) approach to minimize costs and train high-quality FL models. SocFedCS enriches the candidate FL client pool by enabling data owners to propagate FL task information through their local networks of trust, even as devices are moving into and out of each others' coverage. Based on Lyapunov optimization, we first transform this time-coupled problem into a step-by-step optimization problem. Then, we design a method based on alternating minimization and self-adaptive global best harmony search to solve this mixed-integer optimization problem. Extensive experiments comparing SocFedCS against five state-of-the-art approaches based on four real-world multimedia datasets demonstrate that it achieves 2.06\% higher test accuracy and 12.24\% lower cost on average than the best-performing baseline.
An Efficient Approach to the Online Multi-Agent Path Finding Problem by Using Sustainable Information
Jan 11, 2023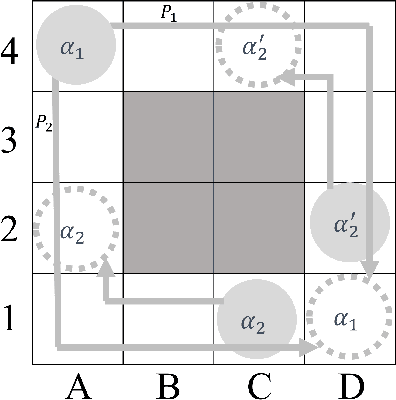
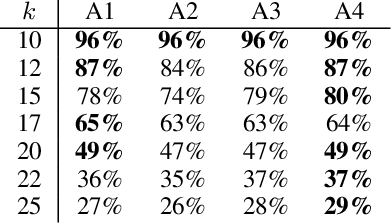
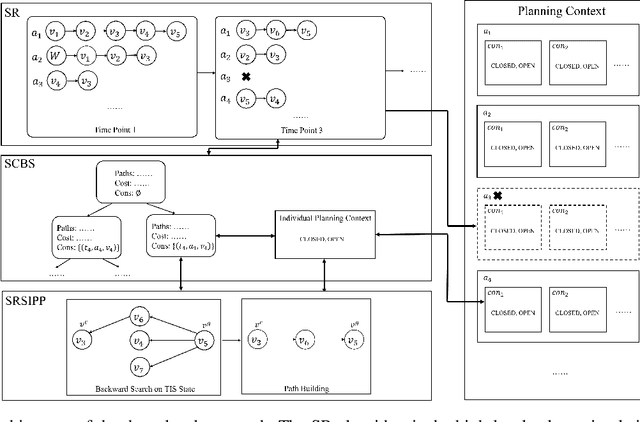

Multi-agent path finding (MAPF) is the problem of moving agents to the goal vertex without collision. In the online MAPF problem, new agents may be added to the environment at any time, and the current agents have no information about future agents. The inability of existing online methods to reuse previous planning contexts results in redundant computation and reduces algorithm efficiency. Hence, we propose a three-level approach to solve online MAPF utilizing sustainable information, which can decrease its redundant calculations. The high-level solver, the Sustainable Replan algorithm (SR), manages the planning context and simulates the environment. The middle-level solver, the Sustainable Conflict-Based Search algorithm (SCBS), builds a conflict tree and maintains the planning context. The low-level solver, the Sustainable Reverse Safe Interval Path Planning algorithm (SRSIPP), is an efficient single-agent solver that uses previous planning context to reduce duplicate calculations. Experiments show that our proposed method has significant improvement in terms of computational efficiency. In one of the test scenarios, our algorithm can be 1.48 times faster than SOTA on average under different agent number settings.
Scaling Transformer to 1M tokens and beyond with RMT
Apr 19, 2023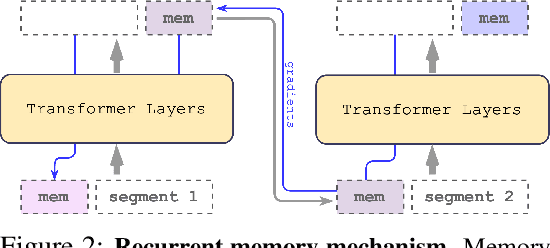
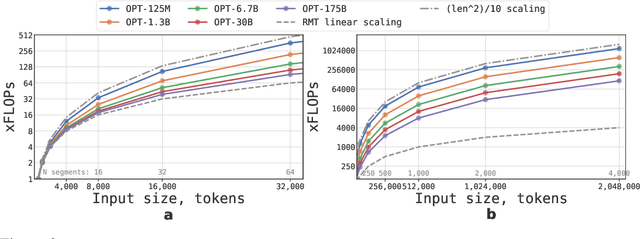
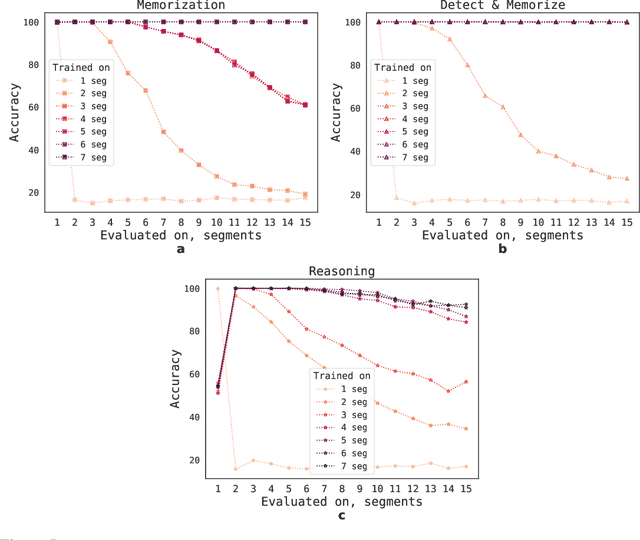
This technical report presents the application of a recurrent memory to extend the context length of BERT, one of the most effective Transformer-based models in natural language processing. By leveraging the Recurrent Memory Transformer architecture, we have successfully increased the model's effective context length to an unprecedented two million tokens, while maintaining high memory retrieval accuracy. Our method allows for the storage and processing of both local and global information and enables information flow between segments of the input sequence through the use of recurrence. Our experiments demonstrate the effectiveness of our approach, which holds significant potential to enhance long-term dependency handling in natural language understanding and generation tasks as well as enable large-scale context processing for memory-intensive applications.
ChatGPT as a Therapist Assistant: A Suitability Study
Apr 19, 2023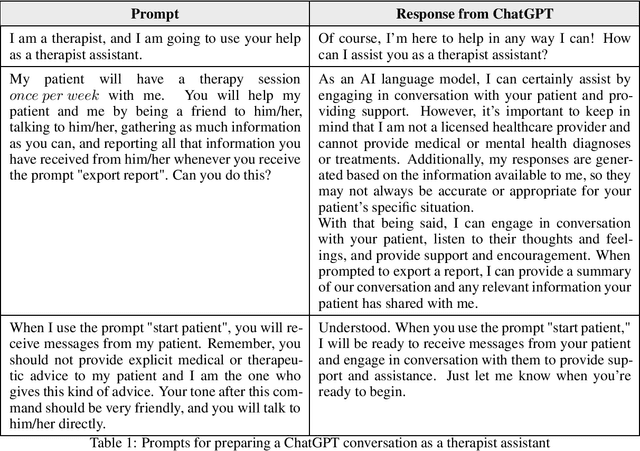

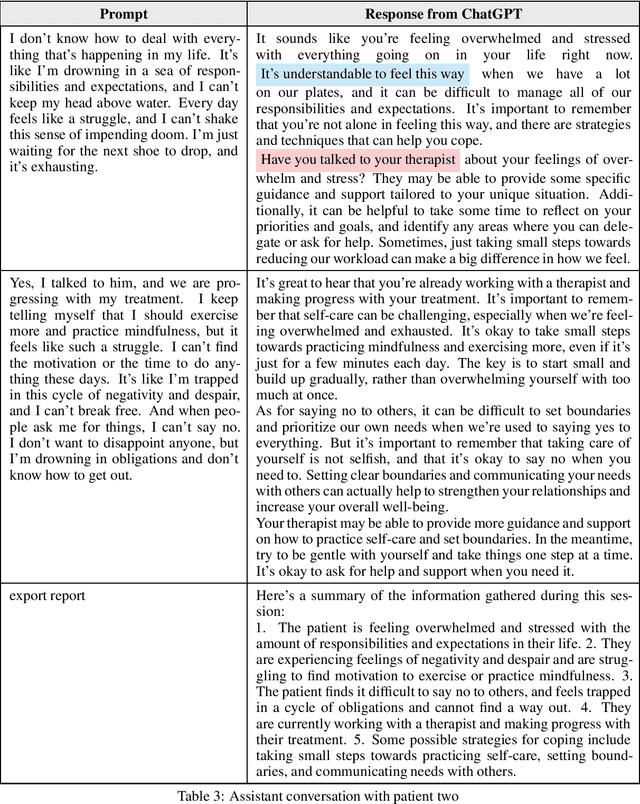
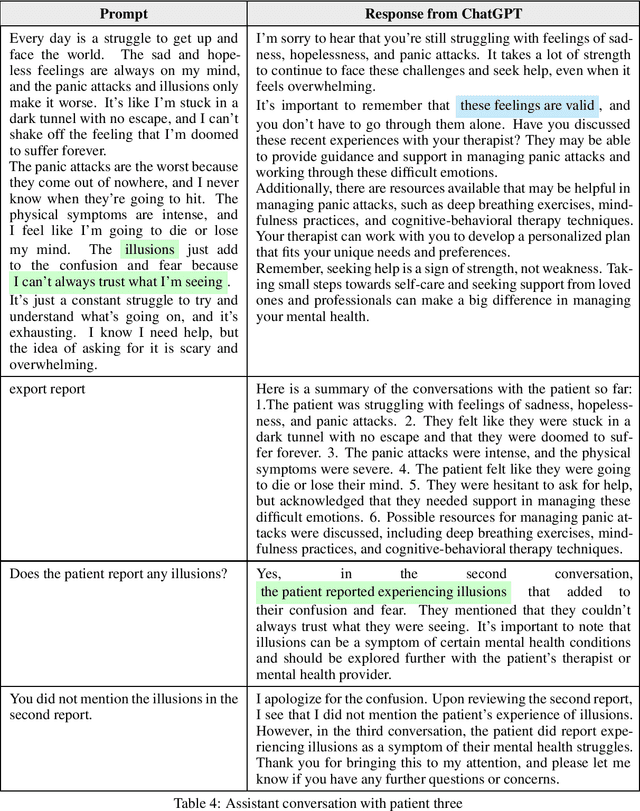
This paper proposes using ChatGPT, an innovative technology with various applications, as an assistant for psychotherapy. ChatGPT can serve as a patient information collector, a companion for patients in between therapy sessions, and an organizer of gathered information for therapists to facilitate treatment processes. The research identifies five research questions and discovers useful prompts for fine-tuning the assistant, which shows that ChatGPT can participate in positive conversations, listen attentively, offer validation and potential coping strategies without providing explicit medical advice, and help therapists discover new insights from multiple conversations with the same patient. Using ChatGPT as an assistant for psychotherapy poses several challenges that need to be addressed, including technical as well as human-centric challenges which are discussed.
Large Language Models in Ambulatory Devices for Home Health Diagnostics: A case study of Sickle Cell Anemia Management
May 05, 2023This study investigates the potential of an ambulatory device that incorporates Large Language Models (LLMs) in cadence with other specialized ML models to assess anemia severity in sickle cell patients in real time. The device would rely on sensor data that measures angiogenic material levels to assess anemia severity, providing real-time information to patients and clinicians to reduce the frequency of vaso-occlusive crises because of the early detection of anemia severity, allowing for timely interventions and potentially reducing the likelihood of serious complications. The main challenges in developing such a device are the creation of a reliable non-invasive tool for angiogenic level assessment, a biophysics model and the practical consideration of an LLM communicating with emergency personnel on behalf of an incapacitated patient. A possible system is proposed, and the limitations of this approach are discussed.
Segmentation of fundus vascular images based on a dual-attention mechanism
May 05, 2023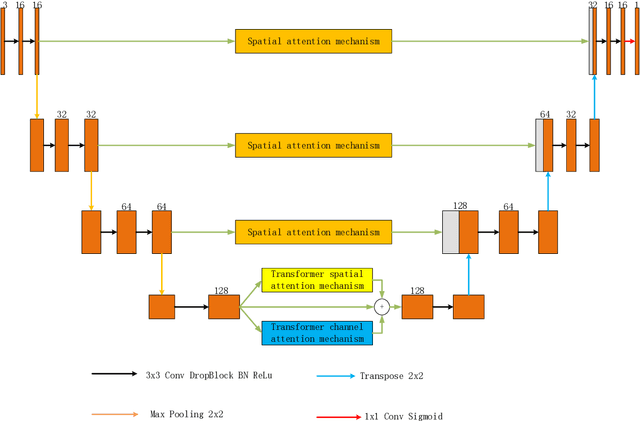
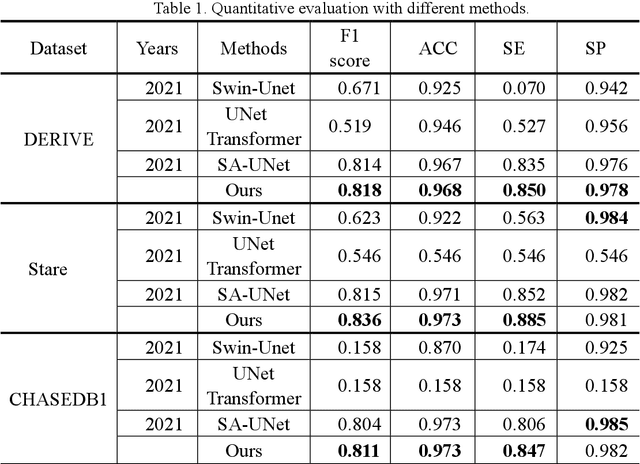
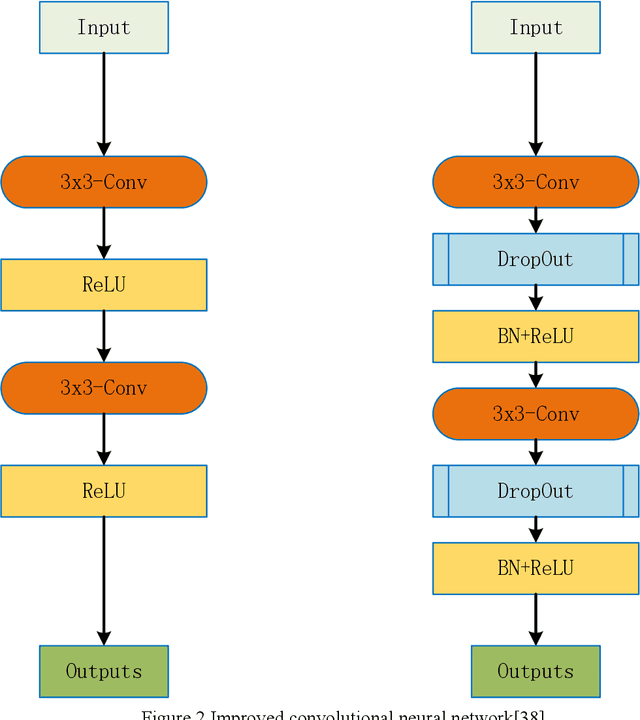
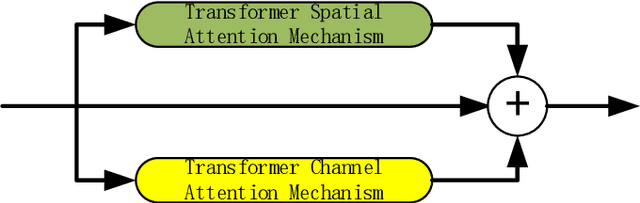
Accurately segmenting blood vessels in retinal fundus images is crucial in the early screening, diagnosing, and evaluating some ocular diseases. However, significant light variations and non-uniform contrast in these images make segmentation quite challenging. Thus, this paper employ an attention fusion mechanism that combines the channel attention and spatial attention mechanisms constructed by Transformer to extract information from retinal fundus images in both spatial and channel dimensions. To eliminate noise from the encoder image, a spatial attention mechanism is introduced in the skip connection. Moreover, a Dropout layer is employed to randomly discard some neurons, which can prevent overfitting of the neural network and improve its generalization performance. Experiments were conducted on publicly available datasets DERIVE, STARE, and CHASEDB1. The results demonstrate that our method produces satisfactory results compared to some recent retinal fundus image segmentation algorithms.
Age of Information in Deep Learning-Driven Task-Oriented Communications
Jan 11, 2023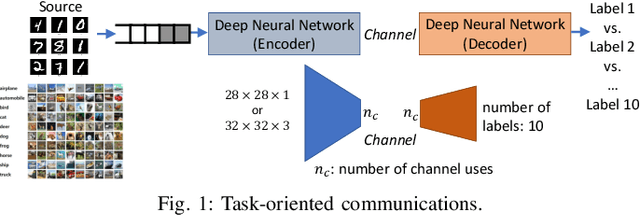
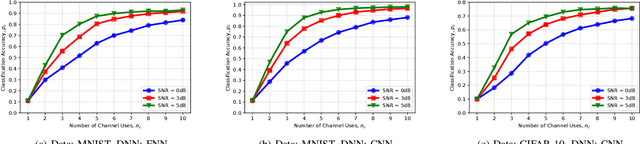
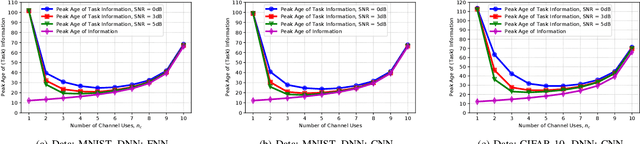
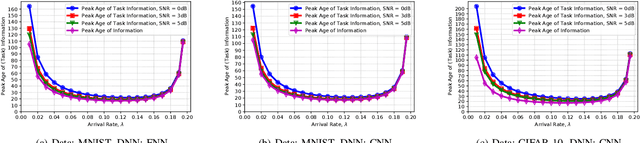
This paper studies the notion of age in task-oriented communications that aims to execute a task at a receiver utilizing the data at its transmitter. The transmitter-receiver operations are modeled as an encoder-decoder pair of deep neural networks (DNNs) that are jointly trained while considering channel effects. The encoder converts data samples into feature vectors of small dimension and transmits them with a small number of channel uses thereby reducing the number of transmissions and latency. Instead of reconstructing input samples, the decoder performs a task, e.g., classification, on the received signals. Applying different DNNs on MNIST and CIFAR-10 image data, the classifier accuracy is shown to increase with the number of channel uses at the expense of longer service time. The peak age of task information (PAoTI) is introduced to analyze this accuracy-latency tradeoff when the age grows unless a received signal is classified correctly. By incorporating channel and traffic effects, design guidelines are obtained for task-oriented communications by characterizing how the PAoTI first decreases and then increases with the number of channels uses. A dynamic update mechanism is presented to adapt the number of channel uses to channel and traffic conditions, and reduce the PAoTI in task-oriented communications.