 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-Aided CSI Estimation Using Affine-Precoded Superimposed Pilots in Orthogonal Time Frequency Space Modulated MIMO Systems
May 25, 2023
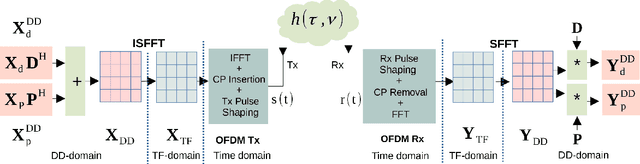
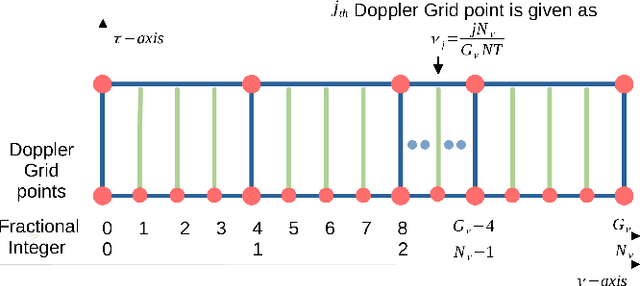
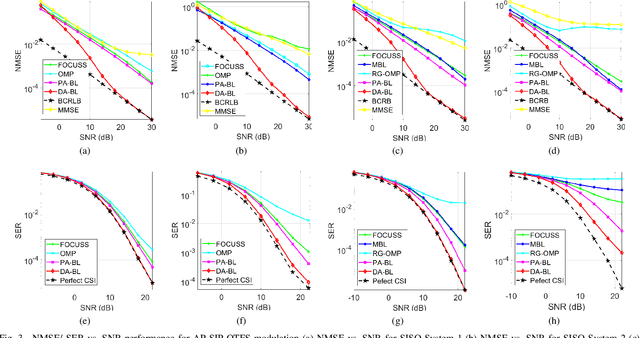
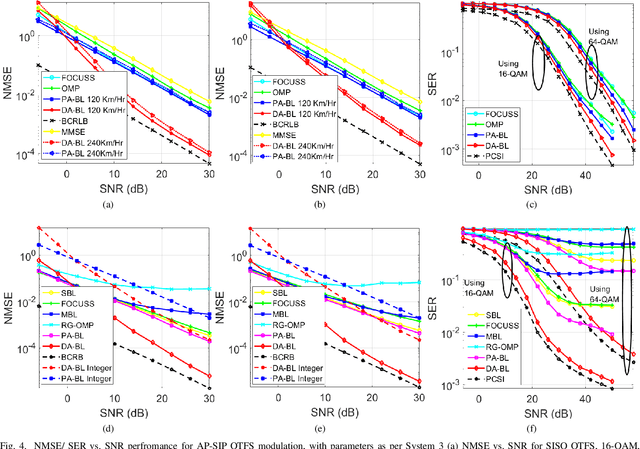
An orthogonal affine-precoded superimposed pilot-based architecture is developed for the cyclic prefix (CP)-aided SISO and MIMO orthogonal time frequency space systems relying on arbitrary transmitter-receiver pulse shaping. The data and pilot symbol matrices are affine-precoded and superimposed in the delay Doppler-domain followed by the development of an end-to-end DD-domain relationship for the input-output symbols. At the receiver, the decoupled pilot and data symbol are extracted by employing orthogonal precoder matrices, which eliminates the mutual interference. Furthermore, a novel pilot-aided Bayesian learning (PA-BL) technique is conceived for the channel state information (CSI) estimation of SISO OTFS systems based on the expectation-maximization (EM) technique. Subsequently, a data-aided Bayesian learning (DA-BL)-based joint CSI estimation and data detection technique is proposed, which beneficially harnesses the estimated data symbols for improved CSI estimation. In this scenario our sophisticated data detection rule also integrates the CSI uncertainty of channel estimation into our the linear minimum mean square error (LMMSE) detectors. The AP-SIP framework is also extended to MIMO OTFS systems, wherein the DD-domain input matrix is affine-precoded for each transmit antenna (TA). Then an EM algorithm-based PA-BL scheme is derived for simultaneous row-group sparse CSI estimation for this system, followed also by our data-aided DA-BL scheme that performs joint CSI estimation and data detection. Moreover, the Bayesian Cramer-Rao bounds (BCRBs) are also derived for both SISO as well as MIMO OTFS systems. Finally, simulation results are presented for characterizing the performance of the proposed CSI estimation techniques in a range of typical settings along with their bit error rate (BER) performance in comparison to an ideal system having perfect CSI.
Transfer Entropy Bottleneck: Learning Sequence to Sequence Information Transfer
Nov 29, 2022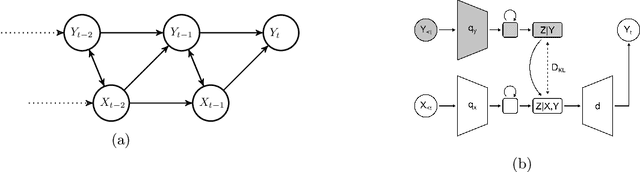



When presented with a data stream of two statistically dependent variables, predicting the future of one of the variables (the target stream) can benefit from information about both its history and the history of the other variable (the source stream). For example, fluctuations in temperature at a weather station can be predicted using both temperatures and barometric readings. However, a challenge when modelling such data is that it is easy for a neural network to rely on the greatest joint correlations within the target stream, which may ignore a crucial but small information transfer from the source to the target stream. As well, there are often situations where the target stream may have previously been modelled independently and it would be useful to use that model to inform a new joint model. Here, we develop an information bottleneck approach for conditional learning on two dependent streams of data. Our method, which we call Transfer Entropy Bottleneck (TEB), allows one to learn a model that bottlenecks the directed information transferred from the source variable to the target variable, while quantifying this information transfer within the model. As such, TEB provides a useful new information bottleneck approach for modelling two statistically dependent streams of data in order to make predictions about one of them.
Neural Boltzmann Machines
May 15, 2023
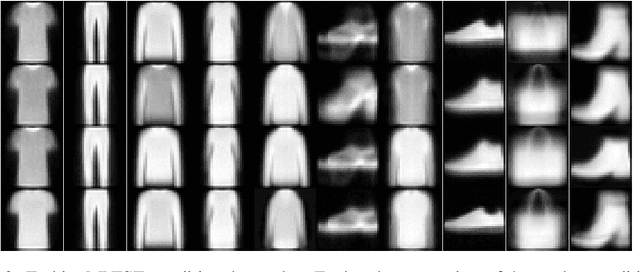

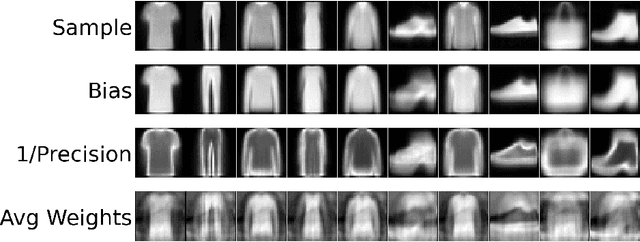
Conditional generative models are capable of using contextual information as input to create new imaginative outputs. Conditional Restricted Boltzmann Machines (CRBMs) are one class of conditional generative models that have proven to be especially adept at modeling noisy discrete or continuous data, but the lack of expressivity in CRBMs have limited their widespread adoption. Here we introduce Neural Boltzmann Machines (NBMs) which generalize CRBMs by converting each of the CRBM parameters to their own neural networks that are allowed to be functions of the conditional inputs. NBMs are highly flexible conditional generative models that can be trained via stochastic gradient descent to approximately maximize the log-likelihood of the data. We demonstrate the utility of NBMs especially with normally distributed data which has historically caused problems for Gaussian-Bernoulli CRBMs. Code to reproduce our results can be found at https://github.com/unlearnai/neural-boltzmann-machines.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023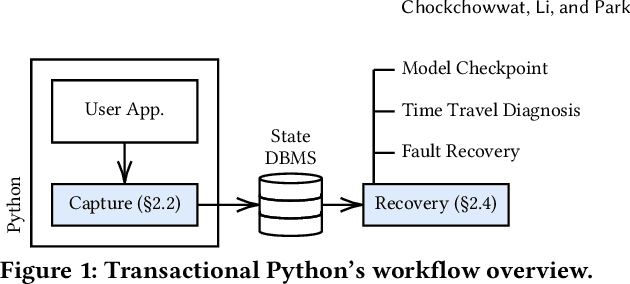
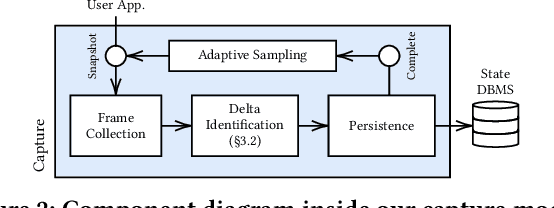
In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.
TAA-GCN: A Temporally Aware Adaptive Graph Convolutional Network for Age Estimation
May 15, 2023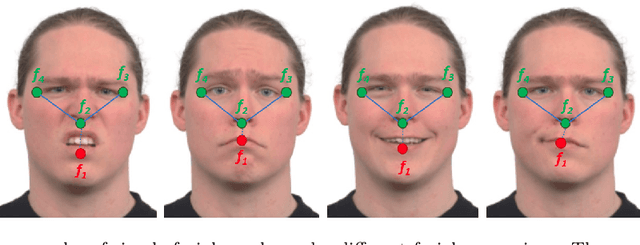


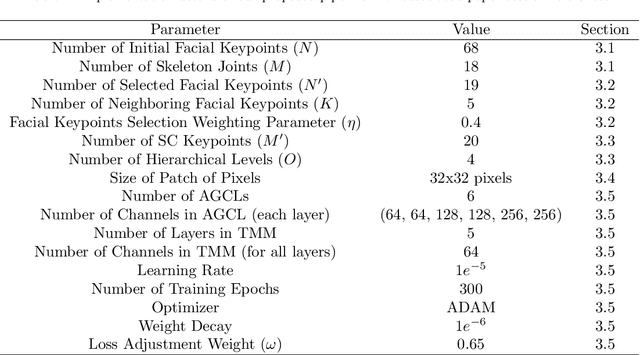
This paper proposes a novel age estimation algorithm, the Temporally-Aware Adaptive Graph Convolutional Network (TAA-GCN). Using a new representation based on graphs, the TAA-GCN utilizes skeletal, posture, clothing, and facial information to enrich the feature set associated with various ages. Such a novel graph representation has several advantages: First, reduced sensitivity to facial expression and other appearance variances; Second, robustness to partial occlusion and non-frontal-planar viewpoint, which is commonplace in real-world applications such as video surveillance. The TAA-GCN employs two novel components, (1) the Temporal Memory Module (TMM) to compute temporal dependencies in age; (2) Adaptive Graph Convolutional Layer (AGCL) to refine the graphs and accommodate the variance in appearance. The TAA-GCN outperforms the state-of-the-art methods on four public benchmarks, UTKFace, MORPHII, CACD, and FG-NET. Moreover, the TAA-GCN showed reliability in different camera viewpoints and reduced quality images.
Idioms, Probing and Dangerous Things: Towards Structural Probing for Idiomaticity in Vector Space
Apr 27, 2023
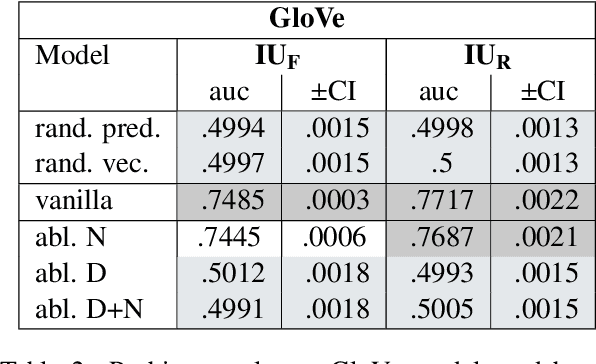
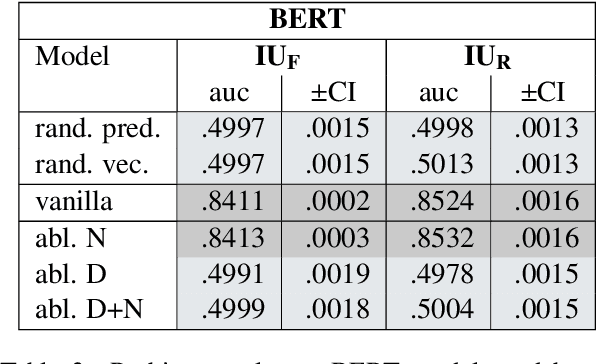
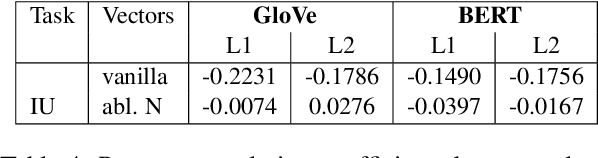
The goal of this paper is to learn more about how idiomatic information is structurally encoded in embeddings, using a structural probing method. We repurpose an existing English verbal multi-word expression (MWE) dataset to suit the probing framework and perform a comparative probing study of static (GloVe) and contextual (BERT) embeddings. Our experiments indicate that both encode some idiomatic information to varying degrees, but yield conflicting evidence as to whether idiomaticity is encoded in the vector norm, leaving this an open question. We also identify some limitations of the used dataset and highlight important directions for future work in improving its suitability for a probing analysis.
Search-in-the-Chain: Towards Accurate, Credible and Traceable Large Language Models for Knowledge-intensive Tasks
May 05, 2023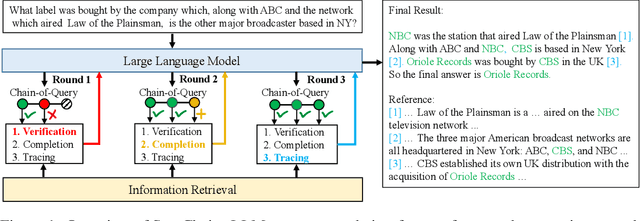
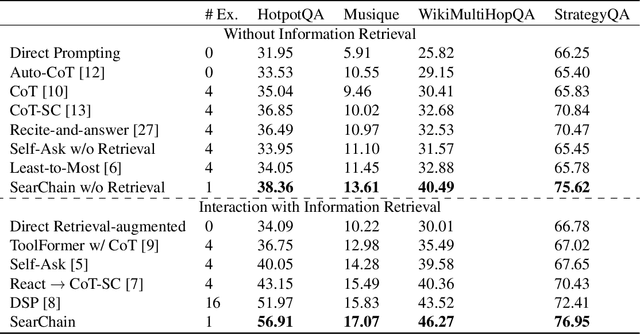
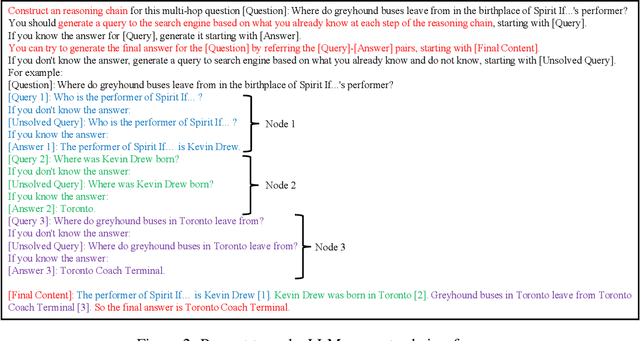

With the wide application of Large Language Models (LLMs) such as ChatGPT, how to make the contents generated by LLM accurate and credible becomes very important, especially in complex knowledge-intensive tasks. In this paper, we propose a novel framework called Search-in-the-Chain (SearChain) to improve the accuracy, credibility and traceability of LLM-generated content for multi-hop question answering, which is a typical complex knowledge-intensive task. SearChain is a framework that deeply integrates LLM and information retrieval (IR). In SearChain, LLM constructs a chain-of-query, which is the decomposition of the multi-hop question. Each node of the chain is a query-answer pair consisting of an IR-oriented query and the answer generated by LLM for this query. IR verifies, completes, and traces the information of each node of the chain, so as to guide LLM to construct the correct chain-of-query, and finally answer the multi-hop question. SearChain makes LLM change from trying to give a answer to trying to construct the chain-of-query when faced with the multi-hop question, which can stimulate the knowledge-reasoning ability and provides the interface for IR to be deeply involved in reasoning process of LLM. IR interacts with each node of chain-of-query of LLM. It verifies the information of the node and provides the unknown knowledge to LLM, which ensures the accuracy of the whole chain in the process of LLM generating the answer. Besides, the contents returned by LLM to the user include not only the final answer but also the reasoning process for the question, that is, the chain-of-query and the supporting documents retrieved by IR for each node of the chain, which improves the credibility and traceability of the contents generated by LLM. Experimental results show SearChain outperforms related baselines on four multi-hop question-answering datasets.
GAMUS: A Geometry-aware Multi-modal Semantic Segmentation Benchmark for Remote Sensing Data
May 24, 2023

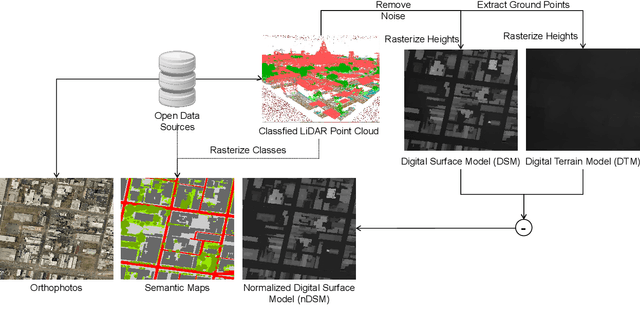
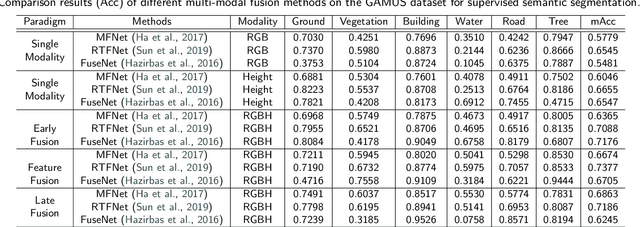
Geometric information in the normalized digital surface models (nDSM) is highly correlated with the semantic class of the land cover. Exploiting two modalities (RGB and nDSM (height)) jointly has great potential to improve the segmentation performance. However, it is still an under-explored field in remote sensing due to the following challenges. First, the scales of existing datasets are relatively small and the diversity of existing datasets is limited, which restricts the ability of validation. Second, there is a lack of unified benchmarks for performance assessment, which leads to difficulties in comparing the effectiveness of different models. Last, sophisticated multi-modal semantic segmentation methods have not been deeply explored for remote sensing data. To cope with these challenges, in this paper, we introduce a new remote-sensing benchmark dataset for multi-modal semantic segmentation based on RGB-Height (RGB-H) data. Towards a fair and comprehensive analysis of existing methods, the proposed benchmark consists of 1) a large-scale dataset including co-registered RGB and nDSM pairs and pixel-wise semantic labels; 2) a comprehensive evaluation and analysis of existing multi-modal fusion strategies for both convolutional and Transformer-based networks on remote sensing data. Furthermore, we propose a novel and effective Transformer-based intermediary multi-modal fusion (TIMF) module to improve the semantic segmentation performance through adaptive token-level multi-modal fusion.The designed benchmark can foster future research on developing new methods for multi-modal learning on remote sensing data. Extensive analyses of those methods are conducted and valuable insights are provided through the experimental results. Code for the benchmark and baselines can be accessed at \url{https://github.com/EarthNets/RSI-MMSegmentation}.
Revenge of MLP in Sequential Recommendation
May 24, 2023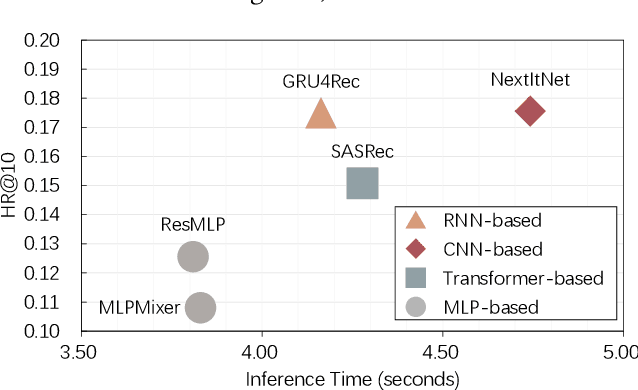
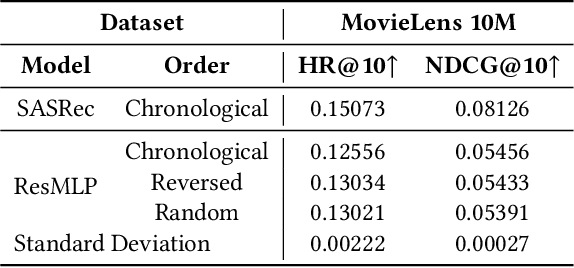
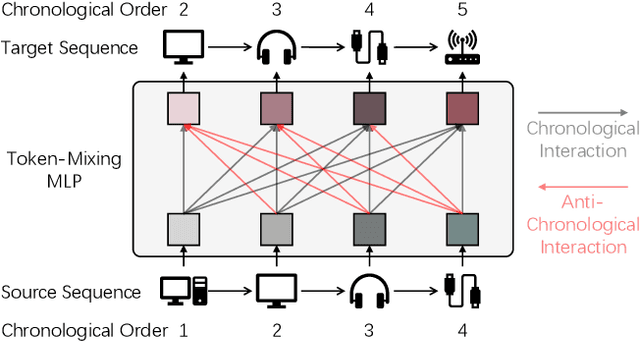
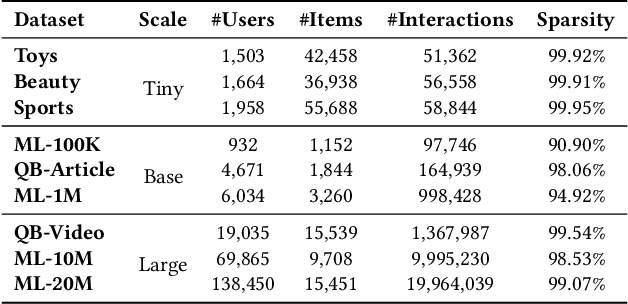
Sequential recommendation models sequences of historical user-item interactive behaviors (or referred as token) to better infer dynamic preferences. Fueled by the improved neural network architectures such as RNN, CNN and Transformer, this field has enjoyed rapid performance boost in the past years. Recent progress on all-MLP models lights on an efficient method with less intensive computation, token-mixing MLP, to learn the transformation patterns among historical behaviors. However, due to the inherent fully-connection design that allows the unrestricted cross-token communication and ignores the chronological order, we find that directly applying token-mixing MLP into sequential recommendation leads to subpar performance. In this paper, we present a purely MLP-based sequential recommendation architecture TriMLP with a novel \underline{Tri}angular Mixer where the modified \underline{MLP} endows tokens with ordered interactions. As the cross-token interaction in MLP is actually matrix multiplication, Triangular Mixer drops the lower-triangle neurons in the weight matrix and thus blocks the connections from future tokens, which prevents information leakage and improves prediction capability under the standard auto-regressive training fashion. To further model long and short-term preferences on fine-grained level, the mixer adopts a dual-branch structure based on the delicate MLP described above, namely global and local mixing, to separately capture the sequential long-range dependencies and local patterns. Empirical study on 9 different scale datasets (contain 50K\textasciitilde20M behaviors) of various benchmarks, including MovieLens, Amazon and Tenrec, demonstrates that TriMLP attains promising and stable accuracy/efficiency trade-off, i.e., averagely surpasses several state-of-the-art baselines by 5.32\% and saves 8.44\% inference time cost.
ThreatCrawl: A BERT-based Focused Crawler for the Cybersecurity Domain
Apr 24, 2023
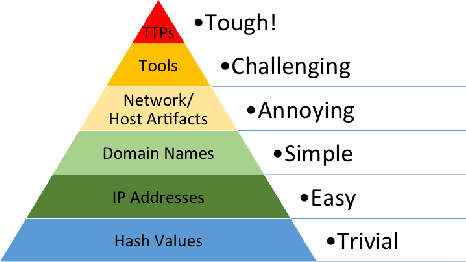
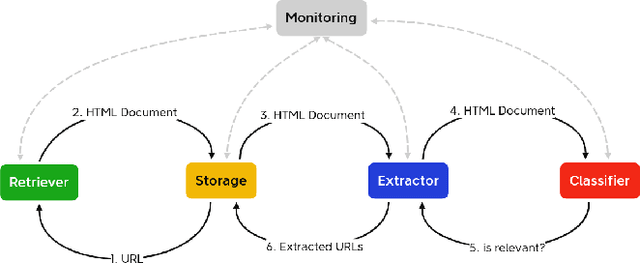

Publicly available information contains valuable information for Cyber Threat Intelligence (CTI). This can be used to prevent attacks that have already taken place on other systems. Ideally, only the initial attack succeeds and all subsequent ones are detected and stopped. But while there are different standards to exchange this information, a lot of it is shared in articles or blog posts in non-standardized ways. Manually scanning through multiple online portals and news pages to discover new threats and extracting them is a time-consuming task. To automize parts of this scanning process, multiple papers propose extractors that use Natural Language Processing (NLP) to extract Indicators of Compromise (IOCs) from documents. However, while this already solves the problem of extracting the information out of documents, the search for these documents is rarely considered. In this paper, a new focused crawler is proposed called ThreatCrawl, which uses Bidirectional Encoder Representations from Transformers (BERT)-based models to classify documents and adapt its crawling path dynamically. While ThreatCrawl has difficulties to classify the specific type of Open Source Intelligence (OSINT) named in texts, e.g., IOC content, it can successfully find relevant documents and modify its path accordingly. It yields harvest rates of up to 52%, which are, to the best of our knowledge, better than the current state of the art.