 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSRLive: Live Streaming Recommendation with Dynamic Semantic ID
Jun 05, 2026Live streaming has emerged as one of the fastest-growing forms of online media, enabling instant content broadcasting and real-time engagement between users and streamers. Despite the effectiveness of existing recommendation algorithms in this domain, they often suffer from limited utilization of computational resources, with low FLOPs that hinder further performance enhancement. Generative recommendation techniques, which have gained traction in various industrial tasks, offer a promising avenue for improving live streaming recommendations. However, directly applying generative methods to live streaming is non-trivial due to two major challenges: (1) static semantic IDs (SIDs) cannot reflect the rapidly changing nature of live room content; and (2) generative pipelines generally do not incorporate user--streamer interaction signals (e.g., likes, orders), which are critical for modeling user intent toward both the streamer and showcased products. To address these challenges, we introduce SSRLive: Dynamic Semantic ID-guided Streaming Recommendation for Live platforms. The proposed framework integrates a generative module and a discriminative module in a unified architecture. The generative component employs an encoder-decoder design to produce both static and dynamic SIDs, enabling timely representation of live room content while leveraging multimodal information. The discriminative component refines task-specific representations by combining SIDs with user features, augments them with user-streamer interaction data, and performs multi-task predictions. Online A/B tests in real-world deployment demonstrate tangible benefits: watch time (+3.38%), GMV (+0.72%), follower growth (+3.12%), and interaction volume (+2.92%). These improvements highlight the effectiveness and business value of SSRLive, which is now fully deployed, serving hundreds of millions of active users.
Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
May 21, 2026Spreadsheet systems (e.g., Microsoft Excel, Google Sheets) play a central role in modern data-centric workflows. As AI agents grow increasingly capable of automating complex tasks, such as controlling computers and generating presentations, building an AI-driven spreadsheet agent has emerged as a promising research direction. Most existing spreadsheet agents rely on specialized prompting over general-purpose LLMs; while this design has potentials on simple spreadsheet operations, it struggles to manage the complex, multi-step workflows typical of real-world applications. We introduce Spreadsheet-RL, a reinforcement learning (RL) fine-tuning framework designed to train specialized spreadsheet agents within a realistic Microsoft Excel environment. Spreadsheet-RL features an automated pipeline for scalable collection of paired start-goal spreadsheets from online forums, as well as domain-specific evaluation tasks in areas such as finance and supply chain management, which we compile into the new Domain-Spreadsheet benchmark dataset. It also includes a Spreadsheet Gym environment designed for multi-turn RL: Spreadsheet Gym exposes extensive Excel functionality through a Python sandbox, along with a refined harness that incorporates a comprehensive tool set and carefully designed tool-routing rules for spreadsheet tasks. Through comprehensive experiments, we show that Spreadsheet-RL substantially enhances AI agent's performance on both general and domain-specific spreadsheet tasks: it improves Qwen3-4B-Thinking-2507's Pass@1 on SpreadsheetBench from 12.0% to 23.4%, and raises Pass@1 from 8.4% to 17.2% on our curated Domain-Spreadsheet dataset. These results highlight Spreadsheet-RL's strong potential for generalization and real-world adoption in spreadsheet automation, and broadly, its promise for advancing LLM-based interactions with data interfaces in everyday work.
SIEVE: Effective Filtered Vector Search with Collection of Indexes
Jul 16, 2025Many real-world tasks such as recommending videos with the kids tag can be reduced to finding most similar vectors associated with hard predicates. This task, filtered vector search, is challenging as prior state-of-the-art graph-based (unfiltered) similarity search techniques quickly degenerate when hard constraints are considered. That is, effective graph-based filtered similarity search relies on sufficient connectivity for reaching the most similar items within just a few hops. To consider predicates, recent works propose modifying graph traversal to visit only the items that may satisfy predicates. However, they fail to offer the just-a-few-hops property for a wide range of predicates: they must restrict predicates significantly or lose efficiency if only a small fraction of items satisfy predicates. We propose an opposite approach: instead of constraining traversal, we build many indexes each serving different predicate forms. For effective construction, we devise a three-dimensional analytical model capturing relationships among index size, search time, and recall, with which we follow a workload-aware approach to pack as many useful indexes as possible into a collection. At query time, the analytical model is employed yet again to discern the one that offers the fastest search at a given recall. We show superior performance and support on datasets with varying selectivities and forms: our approach achieves up to 8.06x speedup while having as low as 1% build time versus other indexes, with less than 2.15x memory of a standard HNSW graph and modest knowledge of past workloads.
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Inference
Feb 27, 2025Vision Language Models (VLMs) have achieved remarkable success in a wide range of vision applications of increasing complexity and scales, yet choosing the right VLM model size involves a trade-off between response quality and cost. While smaller VLMs are cheaper to run, they typically produce responses only marginally better than random guessing on benchmarks such as MMMU. In this paper, we propose Cache of Thought (CoT), a master apprentice framework for collaborative inference between large and small VLMs. CoT manages high quality query results from large VLMs (master) in a cache, which are then selected via a novel multi modal retrieval and in-context learning to aid the performance of small VLMs (apprentice). We extensively evaluate CoT on various widely recognized and challenging general VQA benchmarks, and show that CoT increases overall VQA performance by up to 7.7% under the same budget, and specifically boosts the performance of apprentice VLMs by up to 36.6%.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023



In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.
Revamp: Enhancing Accessible Information Seeking Experience of Online Shopping for Blind or Low Vision Users
Feb 01, 2021
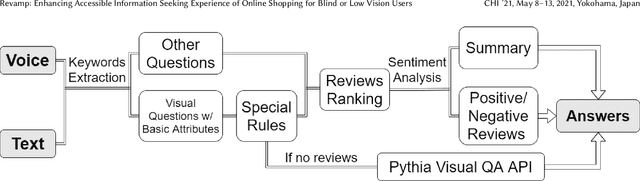

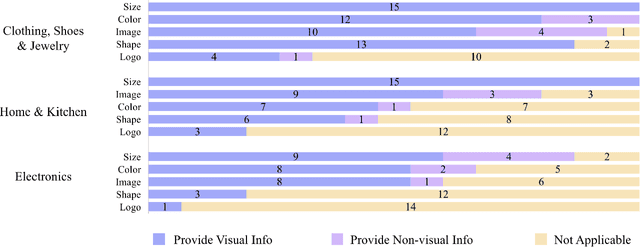
Online shopping has become a valuable modern convenience, but blind or low vision (BLV) users still face significant challenges using it, because of: 1) inadequate image descriptions and 2) the inability to filter large amounts of information using screen readers. To address those challenges, we propose Revamp, a system that leverages customer reviews for interactive information retrieval. Revamp is a browser integration that supports review-based question-answering interactions on a reconstructed product page. From our interview, we identified four main aspects (color, logo, shape, and size) that are vital for BLV users to understand the visual appearance of a product. Based on the findings, we formulated syntactic rules to extract review snippets, which were used to generate image descriptions and responses to users' queries. Evaluations with eight BLV users showed that Revamp 1) provided useful descriptive information for understanding product appearance and 2) helped the participants locate key information efficiently.