 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Search Strategies for Document-Level Neural Machine Translation
Jun 08, 2023
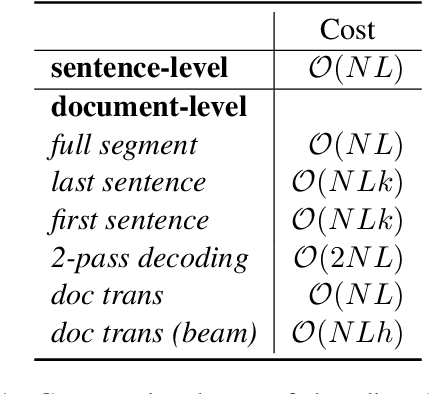
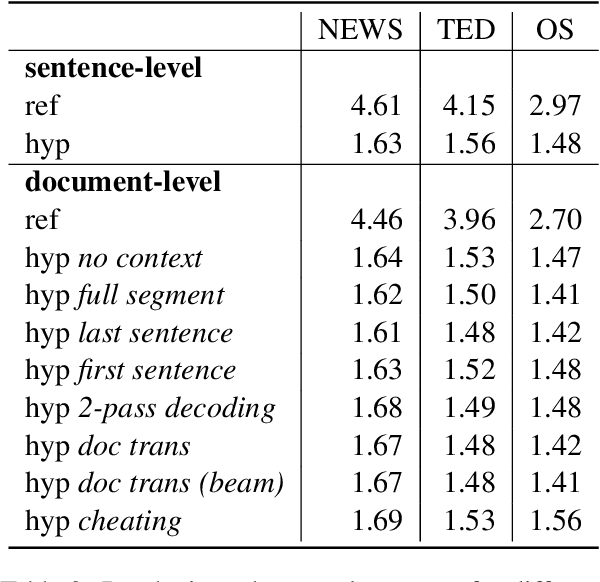
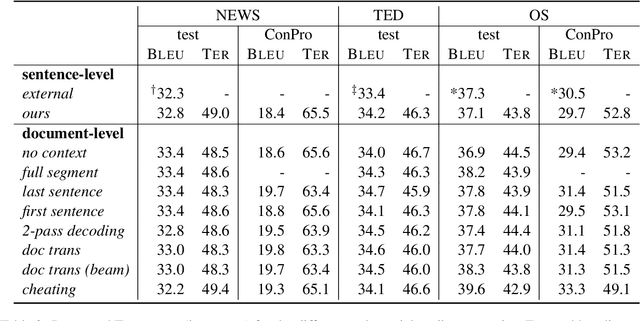
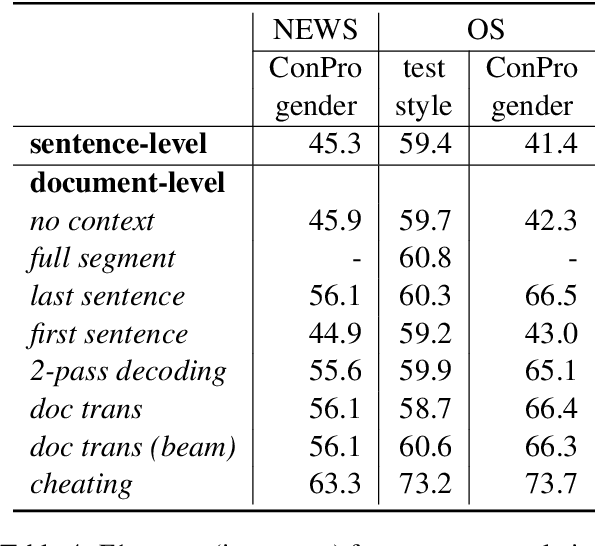
Compared to sentence-level systems, document-level neural machine translation (NMT) models produce a more consistent output across a document and are able to better resolve ambiguities within the input. There are many works on document-level NMT, mostly focusing on modifying the model architecture or training strategy to better accommodate the additional context-input. On the other hand, in most works, the question on how to perform search with the trained model is scarcely discussed, sometimes not mentioned at all. In this work, we aim to answer the question how to best utilize a context-aware translation model in decoding. We start with the most popular document-level NMT approach and compare different decoding schemes, some from the literature and others proposed by us. In the comparison, we are using both, standard automatic metrics, as well as specific linguistic phenomena on three standard document-level translation benchmarks. We find that most commonly used decoding strategies perform similar to each other and that higher quality context information has the potential to further improve the translation.
Normalization-Equivariant Neural Networks with Application to Image Denoising
Jun 08, 2023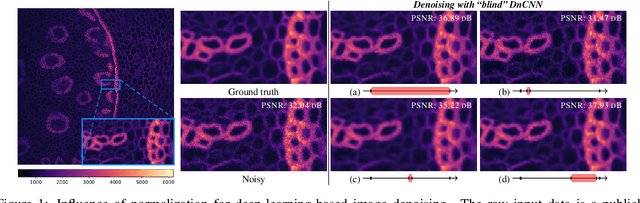

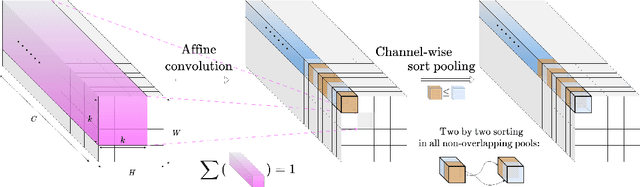
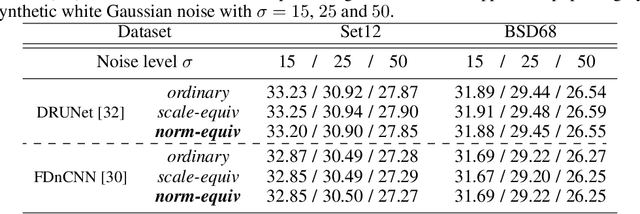
In many information processing systems, it may be desirable to ensure that any change of the input, whether by shifting or scaling, results in a corresponding change in the system response. While deep neural networks are gradually replacing all traditional automatic processing methods, they surprisingly do not guarantee such normalization-equivariance (scale + shift) property, which can be detrimental in many applications. To address this issue, we propose a methodology for adapting existing neural networks so that normalization-equivariance holds by design. Our main claim is that not only ordinary convolutional layers, but also all activation functions, including the ReLU (rectified linear unit), which are applied element-wise to the pre-activated neurons, should be completely removed from neural networks and replaced by better conditioned alternatives. To this end, we introduce affine-constrained convolutions and channel-wise sort pooling layers as surrogates and show that these two architectural modifications do preserve normalization-equivariance without loss of performance. Experimental results in image denoising show that normalization-equivariant neural networks, in addition to their better conditioning, also provide much better generalization across noise levels.
Commitment with Signaling under Double-sided Information Asymmetry
Dec 22, 2022
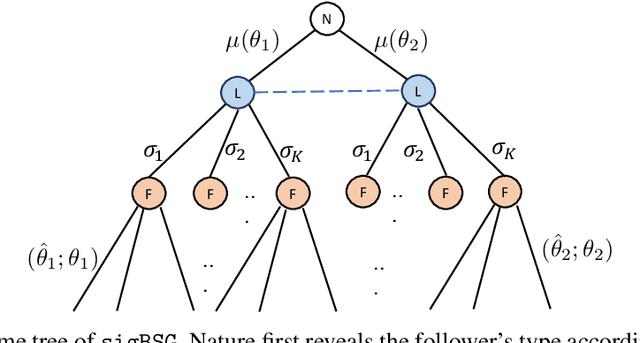
Information asymmetry in games enables players with the information advantage to manipulate others' beliefs by strategically revealing information to other players. This work considers a double-sided information asymmetry in a Bayesian Stackelberg game, where the leader's realized action, sampled from the mixed strategy commitment, is hidden from the follower. In contrast, the follower holds private information about his payoff. Given asymmetric information on both sides, an important question arises: \emph{Does the leader's information advantage outweigh the follower's?} We answer this question affirmatively in this work, where we demonstrate that by adequately designing a signaling device that reveals partial information regarding the leader's realized action to the follower, the leader can achieve a higher expected utility than that without signaling. Moreover, unlike previous works on the Bayesian Stackelberg game where mathematical programming tools are utilized, we interpret the leader's commitment as a probability measure over the belief space. Such a probabilistic language greatly simplifies the analysis and allows an indirect signaling scheme, leading to a geometric characterization of the equilibrium under the proposed game model.
A Minimum Assumption Approach to MEG Sensor Array Design
Jun 15, 2023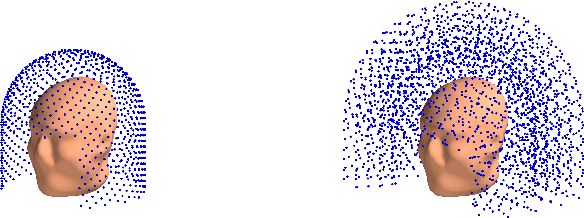
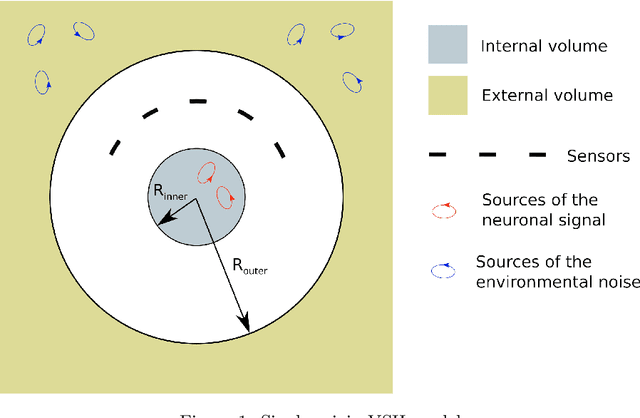
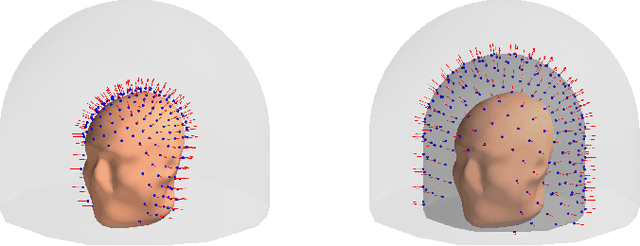
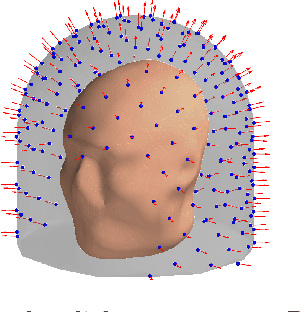
Objective: Our objective is to formulate the problem of the Magnetoencephalographic (MEG) sensor array design as a well-posed engineering problem of accurately measuring the neuronal magnetic fields. This is in contrast to the traditional approach that formulates the sensor array design problem in terms of neurobiological interpretability the sensor array measurements. Approach: We use the Vector Spherical Harmonics (VSH) formalism to define a figure-of-merit for an MEG sensor array. We start with an observation that, under certain reasonable assumptions, any array of $m$ perfectly noiseless sensors will attain exactly the same performance, regardless of the sensors' locations and orientations (with the exception of a negligible set of singularly bad sensor configurations). We proceed to the conclusion that under the aforementioned assumptions, the only difference between different array configurations is the effect of (sensor) noise on their performance. We then propose a figure-of-merit that quantifies, with a single number, how much the sensor array in question amplifies the sensor noise. Main results: We derive a formula for intuitively meaningful, yet mathematically rigorous figure-of-merit that summarizes how desirable a particular sensor array design is. We demonstrate that this figure-of-merit is well-behaved enough to be used as a cost function for a general-purpose nonlinear optimization methods such as simulated annealing. We also show that sensor array configurations obtained by such optimizations exhibit properties that are typically expected of high-quality MEG sensor arrays, e.g. high channel information capacity. Significance: Our work paves the way toward designing better MEG sensor arrays by isolating the engineering problem of measuring the neuromagnetic fields out of the bigger problem of studying brain function through neuromagnetic measurements.
Identifying Informational Sources in News Articles
May 24, 2023
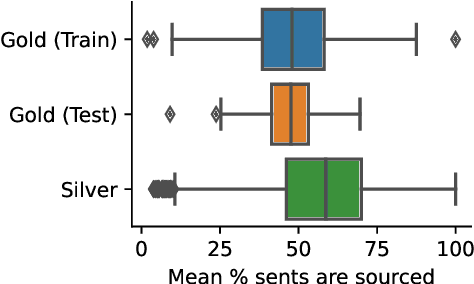

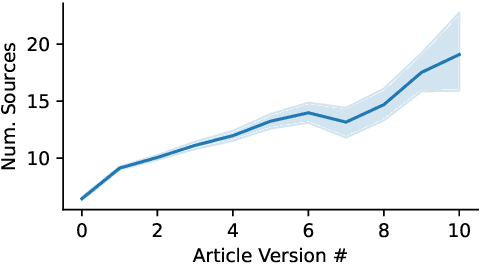
News articles are driven by the informational sources journalists use in reporting. Modeling when, how and why sources get used together in stories can help us better understand the information we consume and even help journalists with the task of producing it. In this work, we take steps toward this goal by constructing the largest and widest-ranging annotated dataset, to date, of informational sources used in news writing. We show that our dataset can be used to train high-performing models for information detection and source attribution. We further introduce a novel task, source prediction, to study the compositionality of sources in news articles. We show good performance on this task, which we argue is an important proof for narrative science exploring the internal structure of news articles and aiding in planning-based language generation, and an important step towards a source-recommendation system to aid journalists.
Optimal Control of Logically Constrained Partially Observable and Multi-Agent Markov Decision Processes
May 24, 2023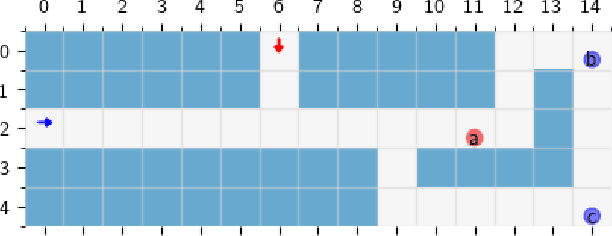
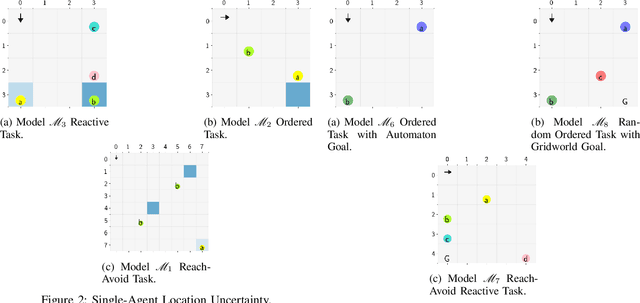
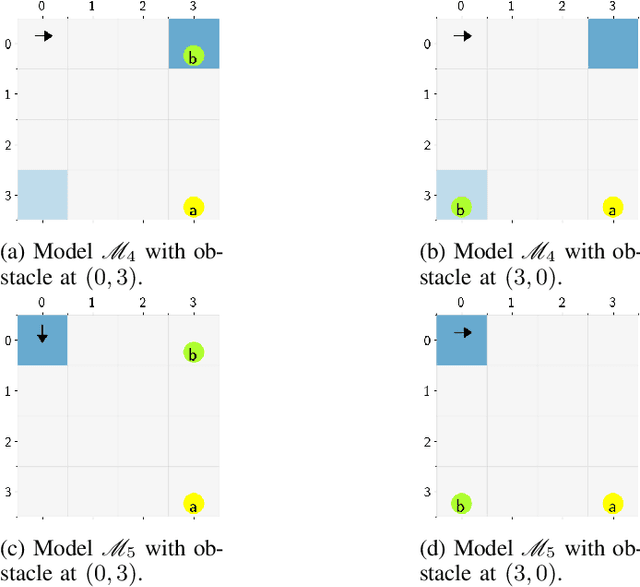

Autonomous systems often have logical constraints arising, for example, from safety, operational, or regulatory requirements. Such constraints can be expressed using temporal logic specifications. The system state is often partially observable. Moreover, it could encompass a team of multiple agents with a common objective but disparate information structures and constraints. In this paper, we first introduce an optimal control theory for partially observable Markov decision processes (POMDPs) with finite linear temporal logic constraints. We provide a structured methodology for synthesizing policies that maximize a cumulative reward while ensuring that the probability of satisfying a temporal logic constraint is sufficiently high. Our approach comes with guarantees on approximate reward optimality and constraint satisfaction. We then build on this approach to design an optimal control framework for logically constrained multi-agent settings with information asymmetry. We illustrate the effectiveness of our approach by implementing it on several case studies.
Reinforcement Learning with Simple Sequence Priors
May 26, 2023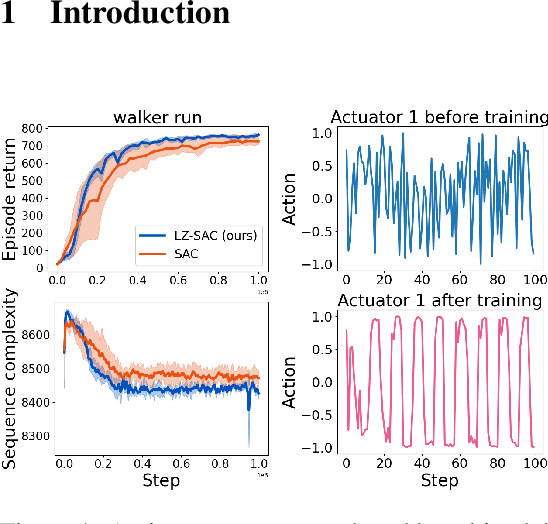

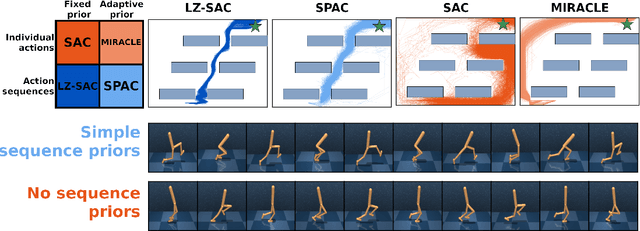

Everything else being equal, simpler models should be preferred over more complex ones. In reinforcement learning (RL), simplicity is typically quantified on an action-by-action basis -- but this timescale ignores temporal regularities, like repetitions, often present in sequential strategies. We therefore propose an RL algorithm that learns to solve tasks with sequences of actions that are compressible. We explore two possible sources of simple action sequences: Sequences that can be learned by autoregressive models, and sequences that are compressible with off-the-shelf data compression algorithms. Distilling these preferences into sequence priors, we derive a novel information-theoretic objective that incentivizes agents to learn policies that maximize rewards while conforming to these priors. We show that the resulting RL algorithm leads to faster learning, and attains higher returns than state-of-the-art model-free approaches in a series of continuous control tasks from the DeepMind Control Suite. These priors also produce a powerful information-regularized agent that is robust to noisy observations and can perform open-loop control.
Over-the-Air Federated Learning in Satellite systems
Jun 05, 2023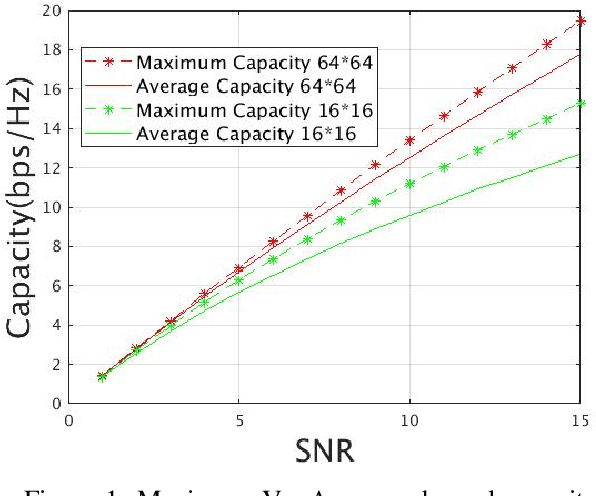
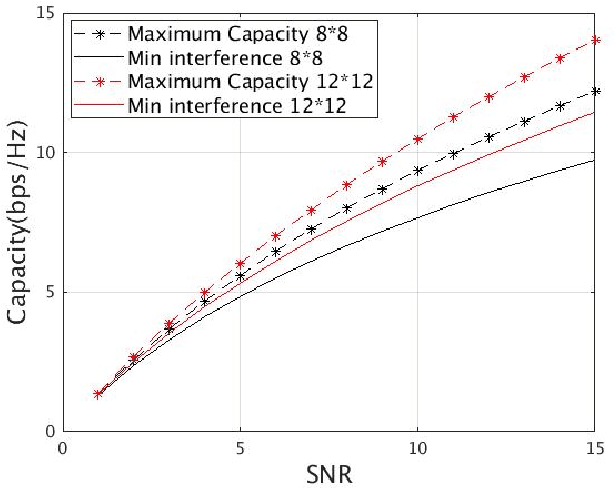
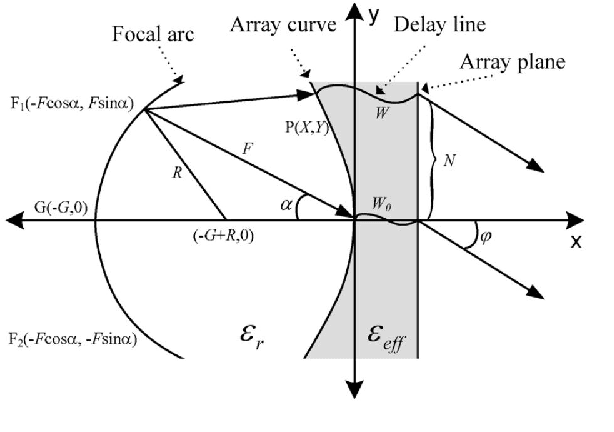
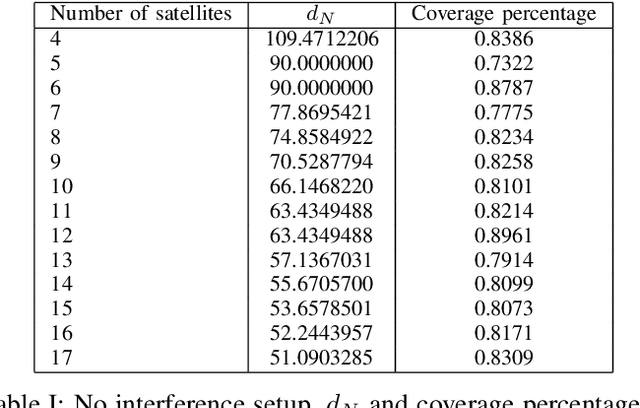
Federated learning in satellites offers several advantages. Firstly, it ensures data privacy and security, as sensitive data remains on the satellites and is not transmitted to a central location. This is particularly important when dealing with sensitive or classified information. Secondly, federated learning allows satellites to collectively learn from a diverse set of data sources, benefiting from the distributed knowledge across the satellite network. Lastly, the use of federated learning reduces the communication bandwidth requirements between satellites and the central server, as only model updates are exchanged instead of raw data. By leveraging federated learning, satellites can collaborate and continuously improve their machine learning models while preserving data privacy and minimizing communication overhead. This enables the development of more intelligent and efficient satellite systems for various applications, such as Earth observation, weather forecasting, and space exploration.
Analyzing Syntactic Generalization Capacity of Pre-trained Language Models on Japanese Honorific Conversion
Jun 05, 2023
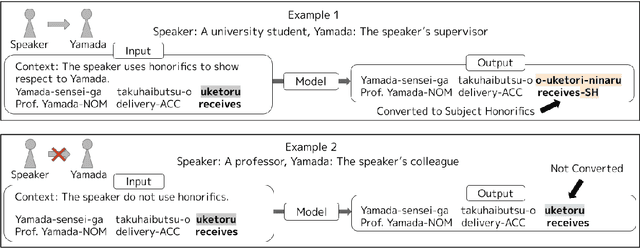


Using Japanese honorifics is challenging because it requires not only knowledge of the grammatical rules but also contextual information, such as social relationships. It remains unclear whether pre-trained large language models (LLMs) can flexibly handle Japanese honorifics like humans. To analyze this, we introduce an honorific conversion task that considers social relationships among people mentioned in a conversation. We construct a Japanese honorifics dataset from problem templates of various sentence structures to investigate the syntactic generalization capacity of GPT-3, one of the leading LLMs, on this task under two settings: fine-tuning and prompt learning. Our results showed that the fine-tuned GPT-3 performed better in a context-aware honorific conversion task than the prompt-based one. The fine-tuned model demonstrated overall syntactic generalizability towards compound honorific sentences, except when tested with the data involving direct speech.
Latent Optimal Paths by Gumbel Propagation for Variational Bayesian Dynamic Programming
Jun 05, 2023
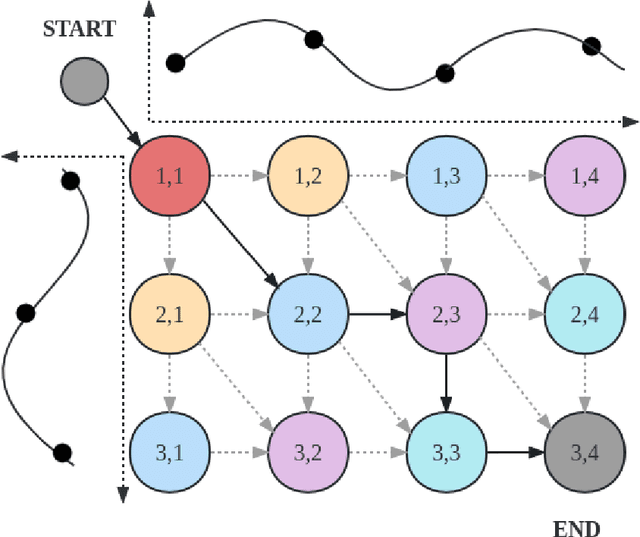

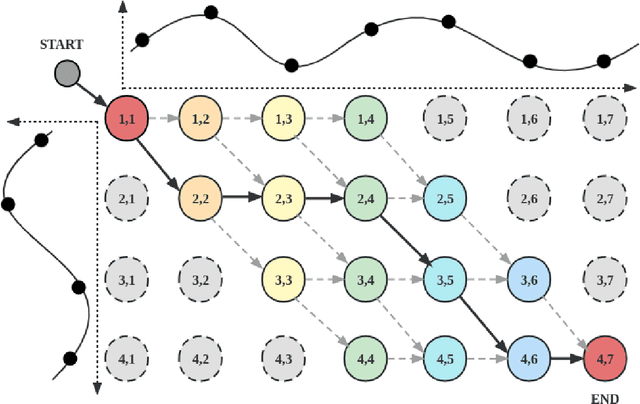
We propose a unified approach to obtain structured sparse optimal paths in the latent space of a variational autoencoder (VAE) using dynamic programming and Gumbel propagation. We solve the classical optimal path problem by a probability softening solution, called the stochastic optimal path, and transform a wide range of DP problems into directed acyclic graphs in which all possible paths follow a Gibbs distribution. We show the equivalence of the Gibbs distribution to a message-passing algorithm by the properties of the Gumbel distribution and give all the ingredients required for variational Bayesian inference. Our approach obtaining latent optimal paths enables end-to-end training for generative tasks in which models rely on the information of unobserved structural features. We validate the behavior of our approach and showcase its applicability in two real-world applications: text-to-speech and singing voice synthesis.