 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transformer-based Multi-Modal Learning for Multi Label Remote Sensing Image Classification
Jun 02, 2023
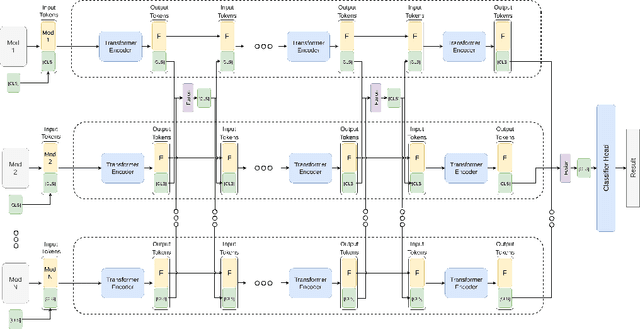
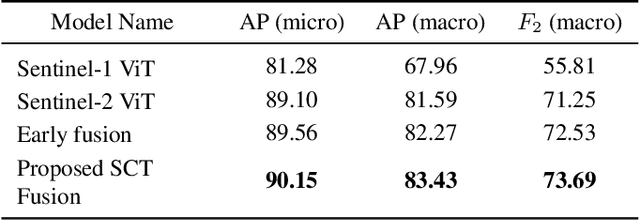
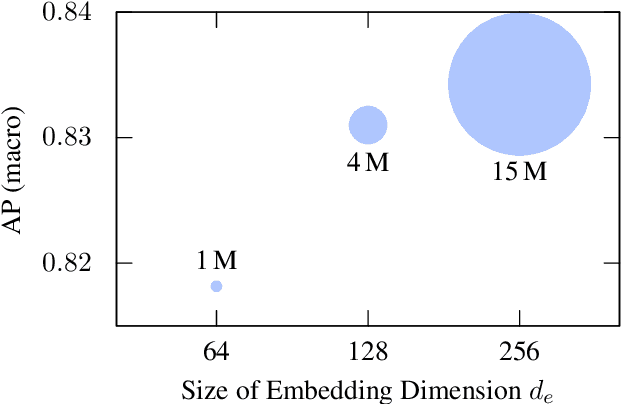
In this paper, we introduce a novel Synchronized Class Token Fusion (SCT Fusion) architecture in the framework of multi-modal multi-label classification (MLC) of remote sensing (RS) images. The proposed architecture leverages modality-specific attention-based transformer encoders to process varying input modalities, while exchanging information across modalities by synchronizing the special class tokens after each transformer encoder block. The synchronization involves fusing the class tokens with a trainable fusion transformation, resulting in a synchronized class token that contains information from all modalities. As the fusion transformation is trainable, it allows to reach an accurate representation of the shared features among different modalities. Experimental results show the effectiveness of the proposed architecture over single-modality architectures and an early fusion multi-modal architecture when evaluated on a multi-modal MLC dataset. The code of the proposed architecture is publicly available at https://git.tu-berlin.de/rsim/sct-fusion.
WiROS: WiFi sensing toolbox for robotics
May 22, 2023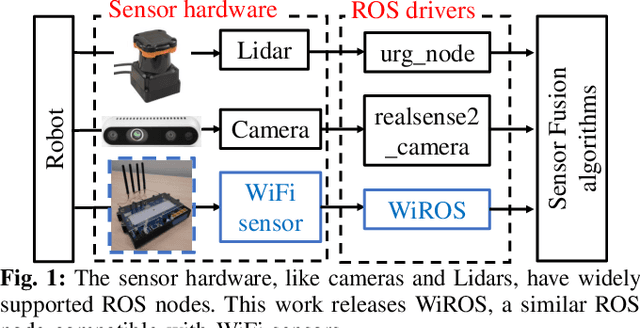
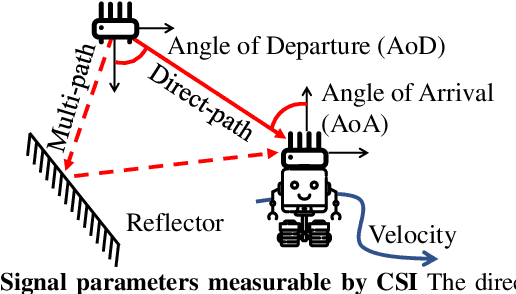
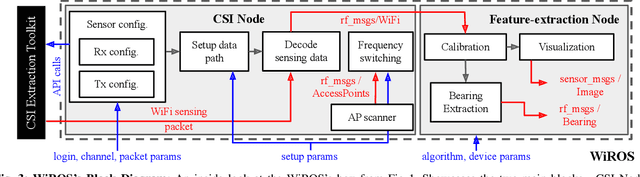
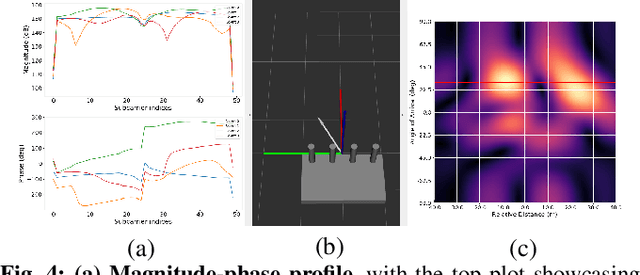
Many recent works have explored using WiFi-based sensing to improve SLAM, robot manipulation, or exploration. Moreover, widespread availability makes WiFi the most advantageous RF signal to leverage. But WiFi sensors lack an accurate, tractable, and versatile toolbox, which hinders their widespread adoption with robot's sensor stacks. We develop WiROS to address this immediate need, furnishing many WiFi-related measurements as easy-to-consume ROS topics. Specifically, WiROS is a plug-and-play WiFi sensing toolbox providing access to coarse-grained WiFi signal strength (RSSI), fine-grained WiFi channel state information (CSI), and other MAC-layer information (device address, packet id's or frequency-channel information). Additionally, WiROS open-sources state-of-art algorithms to calibrate and process WiFi measurements to furnish accurate bearing information for received WiFi signals. The open-sourced repository is: https://github.com/ucsdwcsng/WiROS
Successor-Predecessor Intrinsic Exploration
May 24, 2023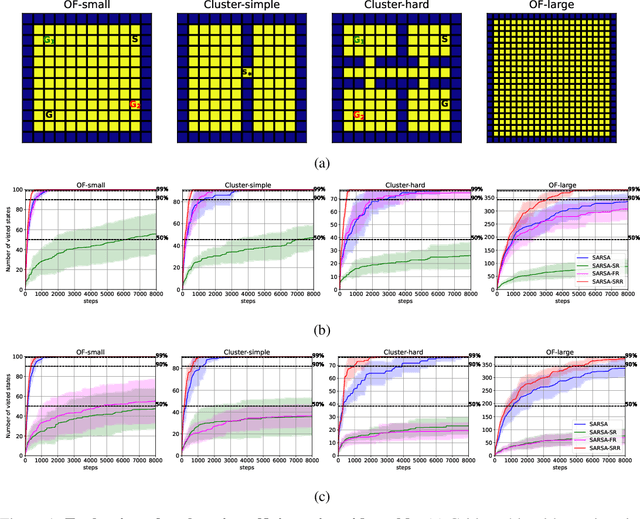

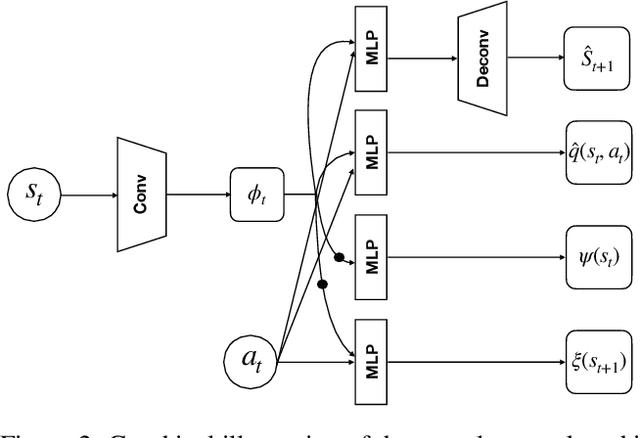

Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
Seeing the World through Your Eyes
Jun 15, 2023
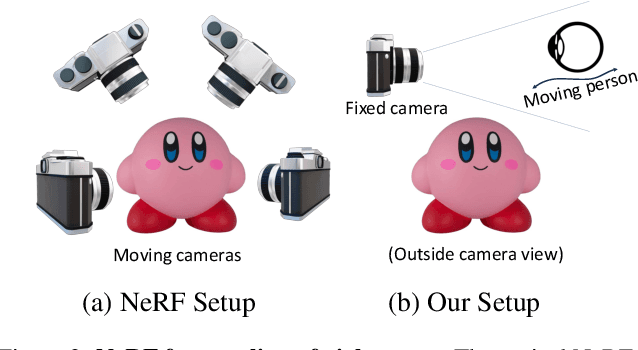
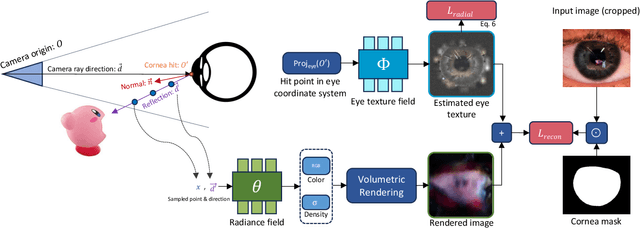
The reflective nature of the human eye is an underappreciated source of information about what the world around us looks like. By imaging the eyes of a moving person, we can collect multiple views of a scene outside the camera's direct line of sight through the reflections in the eyes. In this paper, we reconstruct a 3D scene beyond the camera's line of sight using portrait images containing eye reflections. This task is challenging due to 1) the difficulty of accurately estimating eye poses and 2) the entangled appearance of the eye iris and the scene reflections. Our method jointly refines the cornea poses, the radiance field depicting the scene, and the observer's eye iris texture. We further propose a simple regularization prior on the iris texture pattern to improve reconstruction quality. Through various experiments on synthetic and real-world captures featuring people with varied eye colors, we demonstrate the feasibility of our approach to recover 3D scenes using eye reflections.
Contrast, Stylize and Adapt: Unsupervised Contrastive Learning Framework for Domain Adaptive Semantic Segmentation
Jun 15, 2023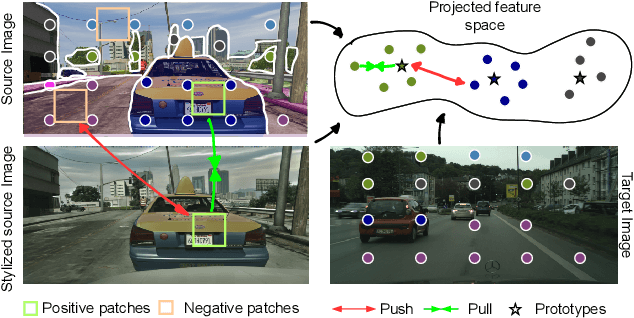
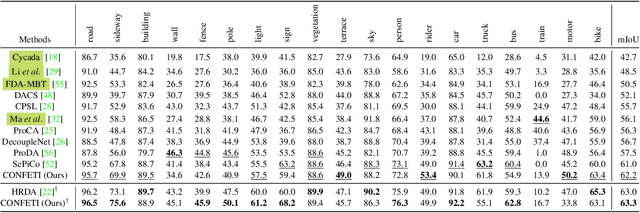
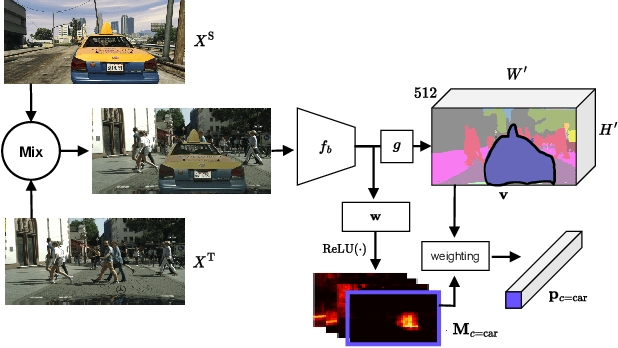
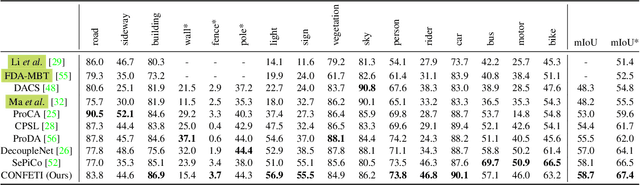
To overcome the domain gap between synthetic and real-world datasets, unsupervised domain adaptation methods have been proposed for semantic segmentation. Majority of the previous approaches have attempted to reduce the gap either at the pixel or feature level, disregarding the fact that the two components interact positively. To address this, we present CONtrastive FEaTure and pIxel alignment (CONFETI) for bridging the domain gap at both the pixel and feature levels using a unique contrastive formulation. We introduce well-estimated prototypes by including category-wise cross-domain information to link the two alignments: the pixel-level alignment is achieved using the jointly trained style transfer module with the prototypical semantic consistency, while the feature-level alignment is enforced to cross-domain features with the \textbf{pixel-to-prototype contrast}. Our extensive experiments demonstrate that our method outperforms existing state-of-the-art methods using DeepLabV2. Our code is available at https://github.com/cxa9264/CONFETI
Probabilistic-based Feature Embedding of 4-D Light Fields for Compressive Imaging and Denoising
Jun 15, 2023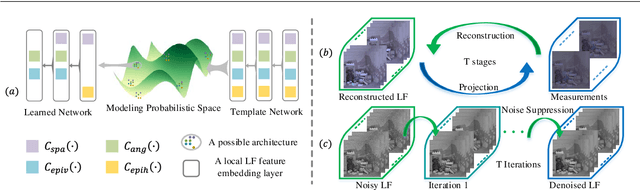
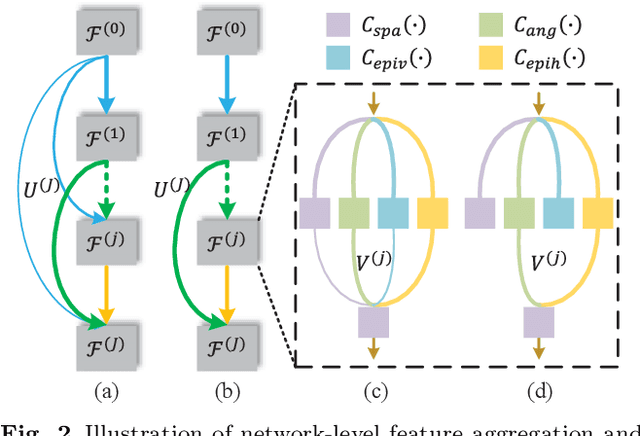
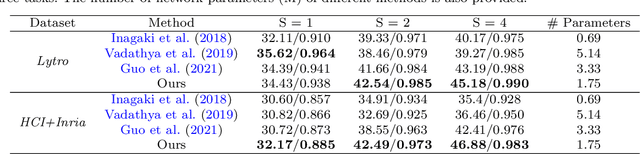
The high-dimensional nature of the 4-D light field (LF) poses great challenges in efficient and effective feature embedding that severely impact the performance of downstream tasks. To tackle this crucial issue, in contrast to existing methods with empirically-designed architectures, we propose probabilistic-based feature embedding (PFE), which learns a feature embedding architecture by assembling various low-dimensional convolution patterns in a probability space for fully capturing spatial-angular information. Building upon the proposed PFE, we then leverage the intrinsic linear imaging model of the coded aperture camera to construct a cycle-consistent 4-D LF reconstruction network from coded measurements. Moreover, we incorporate PFE into an iterative optimization framework for 4-D LF denoising. Our extensive experiments demonstrate the significant superiority of our methods on both real-world and synthetic 4-D LF images, both quantitatively and qualitatively, when compared with state-of-the-art methods. The source code will be publicly available at https://github.com/lyuxianqiang/LFCA-CR-NET.
MetricPrompt: Prompting Model as a Relevance Metric for Few-shot Text Classification
Jun 15, 2023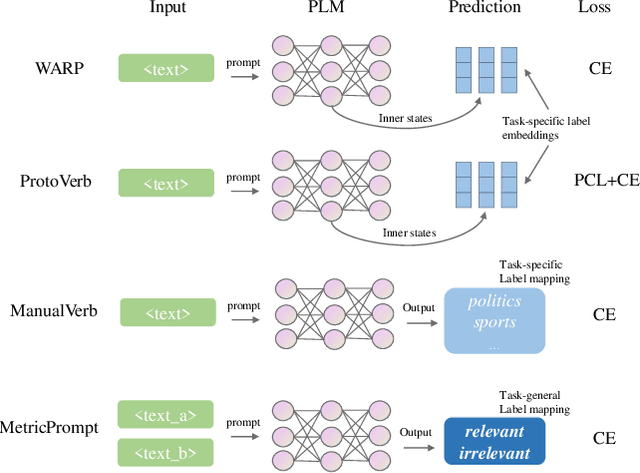
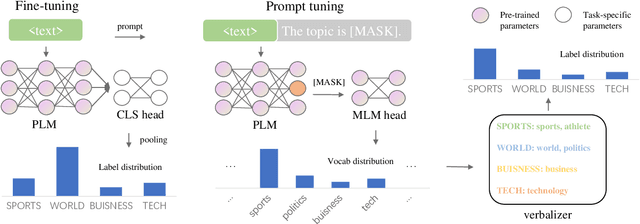
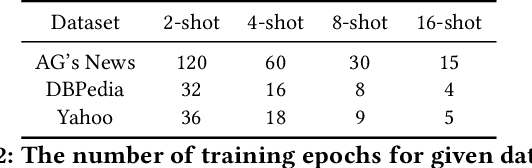
Prompting methods have shown impressive performance in a variety of text mining tasks and applications, especially few-shot ones. Despite the promising prospects, the performance of prompting model largely depends on the design of prompt template and verbalizer. In this work, we propose MetricPrompt, which eases verbalizer design difficulty by reformulating few-shot text classification task into text pair relevance estimation task. MetricPrompt adopts prompting model as the relevance metric, further bridging the gap between Pre-trained Language Model's (PLM) pre-training objective and text classification task, making possible PLM's smooth adaption. Taking a training sample and a query one simultaneously, MetricPrompt captures cross-sample relevance information for accurate relevance estimation. We conduct experiments on three widely used text classification datasets across four few-shot settings. Results show that MetricPrompt outperforms manual verbalizer and other automatic verbalizer design methods across all few-shot settings, achieving new state-of-the-art (SOTA) performance.
Domain-specific ChatBots for Science using Embeddings
Jun 15, 2023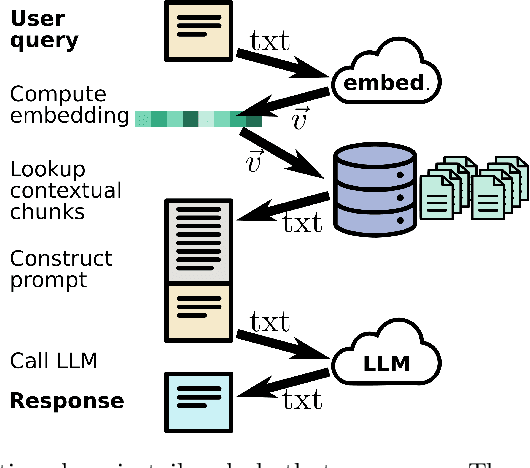
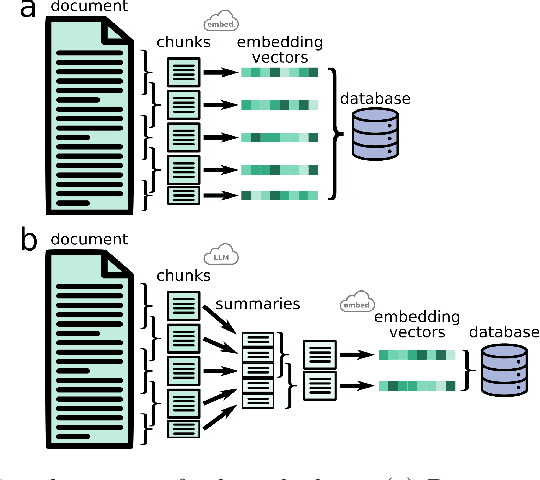
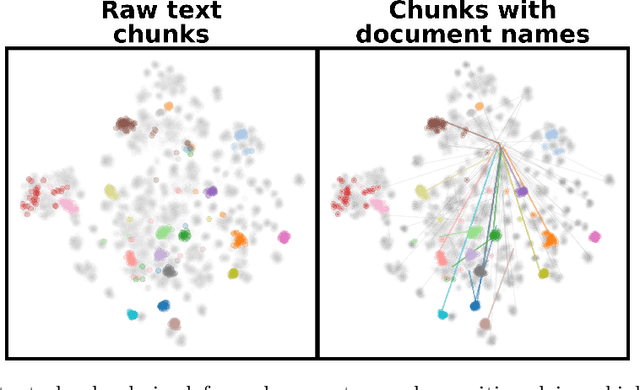
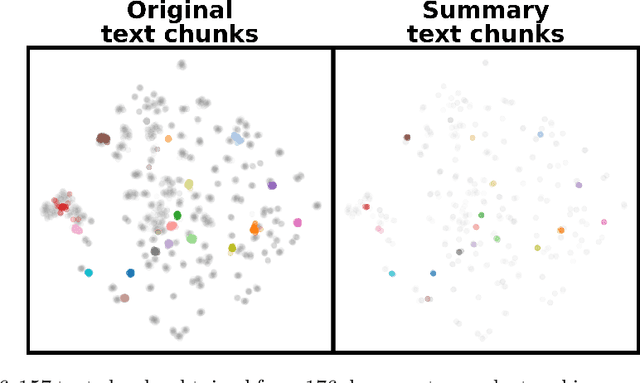
Large language models (LLMs) have emerged as powerful machine-learning systems capable of handling a myriad of tasks. Tuned versions of these systems have been turned into chatbots that can respond to user queries on a vast diversity of topics, providing informative and creative replies. However, their application to physical science research remains limited owing to their incomplete knowledge in these areas, contrasted with the needs of rigor and sourcing in science domains. Here, we demonstrate how existing methods and software tools can be easily combined to yield a domain-specific chatbot. The system ingests scientific documents in existing formats, and uses text embedding lookup to provide the LLM with domain-specific contextual information when composing its reply. We similarly demonstrate that existing image embedding methods can be used for search and retrieval across publication figures. These results confirm that LLMs are already suitable for use by physical scientists in accelerating their research efforts.
Multi-Platform Budget Management in Ad Markets with Non-IC Auctions
Jun 12, 2023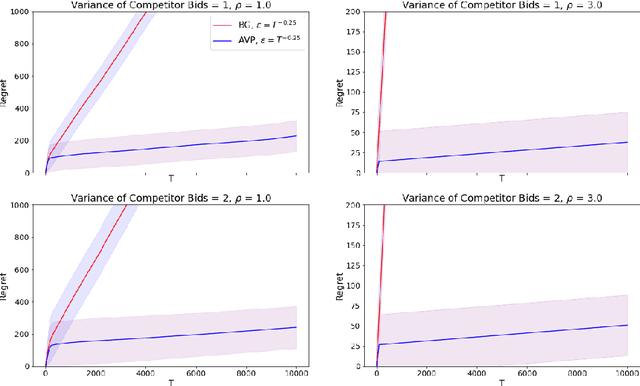
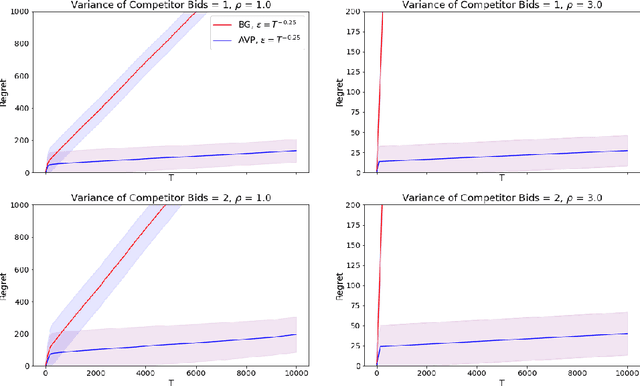
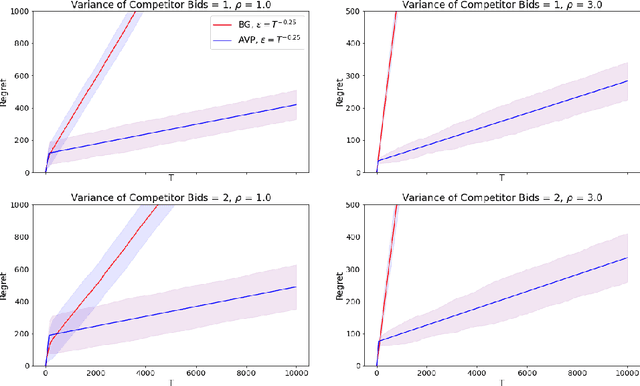
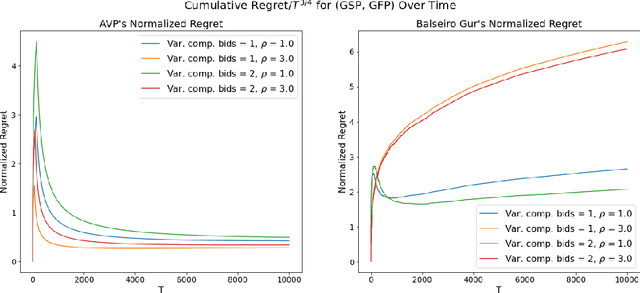
In online advertising markets, budget-constrained advertisers acquire ad placements through repeated bidding in auctions on various platforms. We present a strategy for bidding optimally in a set of auctions that may or may not be incentive-compatible under the presence of budget constraints. Our strategy maximizes the expected total utility across auctions while satisfying the advertiser's budget constraints in expectation. Additionally, we investigate the online setting where the advertiser must submit bids across platforms while learning about other bidders' bids over time. Our algorithm has $O(T^{3/4})$ regret under the full-information setting. Finally, we demonstrate that our algorithms have superior cumulative regret on both synthetic and real-world datasets of ad placement auctions, compared to existing adaptive pacing algorithms.
A Practical Entity Linking System for Tables in Scientific Literature
Jun 12, 2023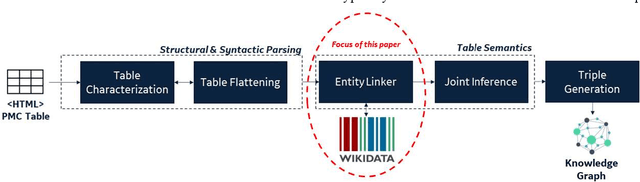


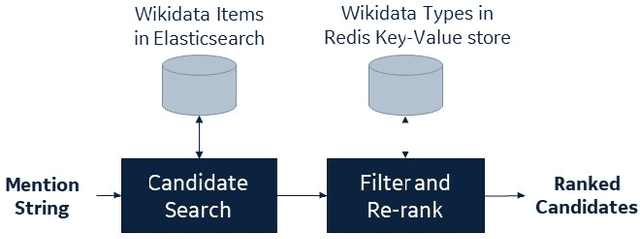
Entity linking is an important step towards constructing knowledge graphs that facilitate advanced question answering over scientific documents, including the retrieval of relevant information included in tables within these documents. This paper introduces a general-purpose system for linking entities to items in the Wikidata knowledge base. It describes how we adapt this system for linking domain-specific entities, especially for those entities embedded within tables drawn from COVID-19-related scientific literature. We describe the setup of an efficient offline instance of the system that enables our entity-linking approach to be more feasible in practice. As part of a broader approach to infer the semantic meaning of scientific tables, we leverage the structural and semantic characteristics of the tables to improve overall entity linking performance.