 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Deep Learning Approach for Overall Survival Prediction in Lung Cancer with Missing Values
Jul 28, 2023
One of the most challenging fields where Artificial Intelligence (AI) can be applied is lung cancer research, specifically non-small cell lung cancer (NSCLC). In particular, overall survival (OS), the time between diagnosis and death, is a vital indicator of patient status, enabling tailored treatment and improved OS rates. In this analysis, there are two challenges to take into account. First, few studies effectively exploit the information available from each patient, leveraging both uncensored (i.e., dead) and censored (i.e., survivors) patients, considering also the events' time. Second, the handling of incomplete data is a common issue in the medical field. This problem is typically tackled through the use of imputation methods. Our objective is to present an AI model able to overcome these limits, effectively learning from both censored and uncensored patients and their available features, for the prediction of OS for NSCLC patients. We present a novel approach to survival analysis with missing values in the context of NSCLC, which exploits the strengths of the transformer architecture to account only for available features without requiring any imputation strategy. By making use of ad-hoc losses for OS, it is able to account for both censored and uncensored patients, as well as changes in risks over time. We compared our method with state-of-the-art models for survival analysis coupled with different imputation strategies. We evaluated the results obtained over a period of 6 years using different time granularities obtaining a Ct-index, a time-dependent variant of the C-index, of 71.97, 77.58 and 80.72 for time units of 1 month, 1 year and 2 years, respectively, outperforming all state-of-the-art methods regardless of the imputation method used.
Generator-Retriever-Generator: A Novel Approach to Open-domain Question Answering
Jul 21, 2023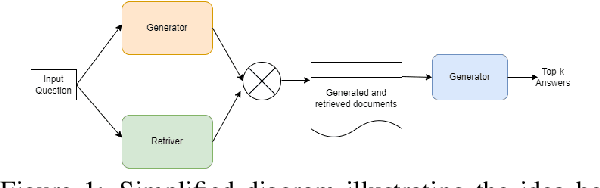
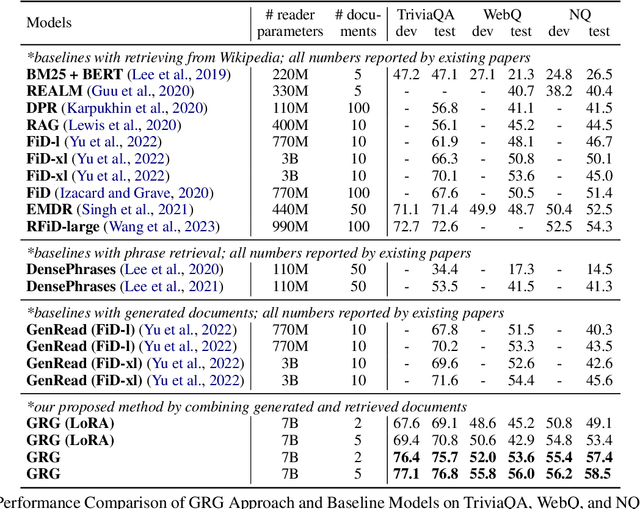
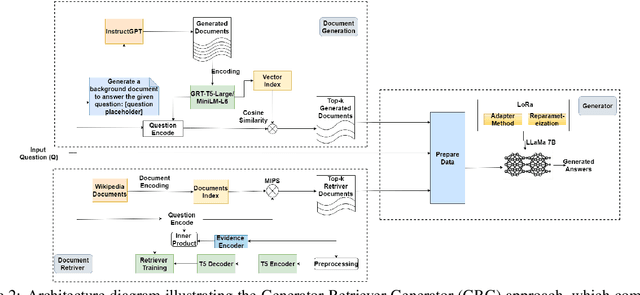

Open-domain question answering (QA) tasks usually require the retrieval of relevant information from a large corpus to generate accurate answers. We propose a novel approach called Generator-Retriever-Generator (GRG) that combines document retrieval techniques with a large language model (LLM), by first prompting the model to generate contextual documents based on a given question. In parallel, a dual-encoder network retrieves documents that are relevant to the question from an external corpus. The generated and retrieved documents are then passed to the second LLM, which generates the final answer. By combining document retrieval and LLM generation, our approach addresses the challenges of open-domain QA, such as generating informative and contextually relevant answers. GRG outperforms the state-of-the-art generate-then-read and retrieve-then-read pipelines (GENREAD and RFiD) improving their performance at least by +5.2, +4.2, and +1.6 on TriviaQA, NQ, and WebQ datasets, respectively. We provide code, datasets, and checkpoints \footnote{\url{https://github.com/abdoelsayed2016/GRG}}
KVN: Keypoints Voting Network with Differentiable RANSAC for Stereo Pose Estimation
Jul 21, 2023Object pose estimation is a fundamental computer vision task exploited in several robotics and augmented reality applications. Many established approaches rely on predicting 2D-3D keypoint correspondences using RANSAC (Random sample consensus) and estimating the object pose using the PnP (Perspective-n-Point) algorithm. Being RANSAC non-differentiable, correspondences cannot be directly learned in an end-to-end fashion. In this paper, we address the stereo image-based object pose estimation problem by (i) introducing a differentiable RANSAC layer into a well-known monocular pose estimation network; (ii) exploiting an uncertainty-driven multi-view PnP solver which can fuse information from multiple views. We evaluate our approach on a challenging public stereo object pose estimation dataset, yielding state-of-the-art results against other recent approaches. Furthermore, in our ablation study, we show that the differentiable RANSAC layer plays a significant role in the accuracy of the proposed method. We release with this paper the open-source implementation of our method.
Artificial Intelligence-Generated Terahertz Multi-Resonant Metasurfaces via Improved Transformer and CGAN Neural Networks
Jul 21, 2023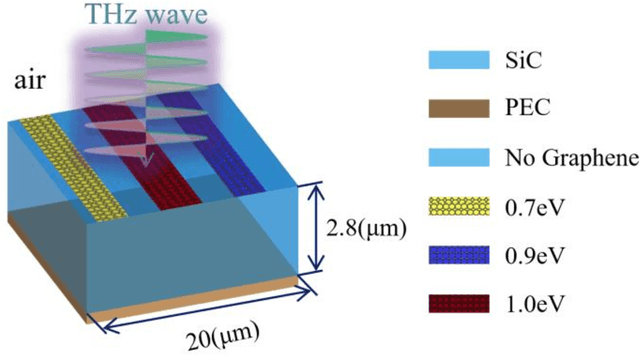
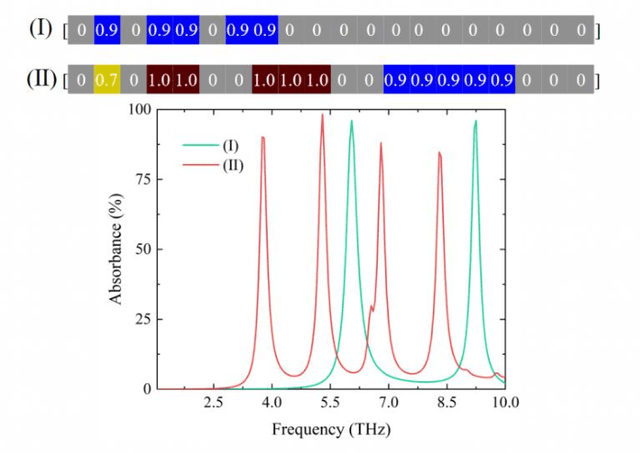
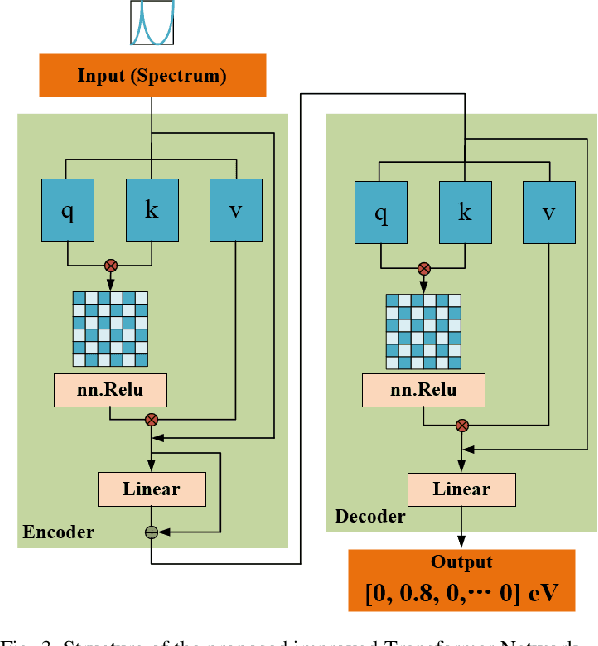
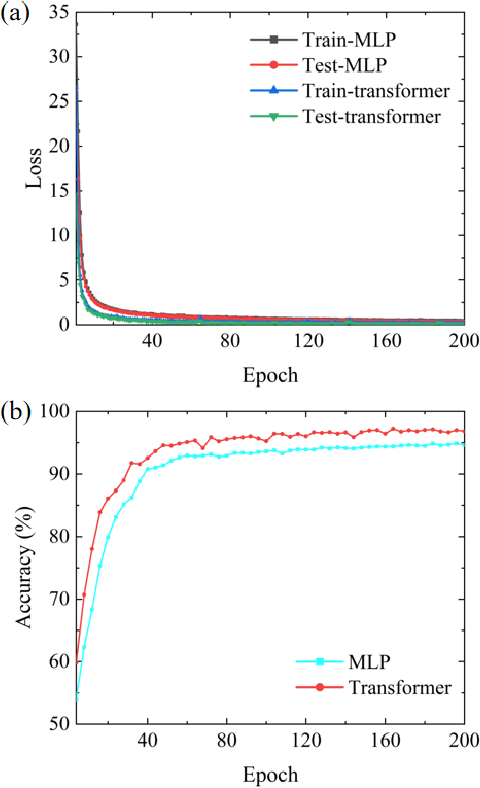
It is well known that the inverse design of terahertz (THz) multi-resonant graphene metasurfaces by using traditional deep neural networks (DNNs) has limited generalization ability. In this paper, we propose improved Transformer and conditional generative adversarial neural networks (CGAN) for the inverse design of graphene metasurfaces based upon THz multi-resonant absorption spectra. The improved Transformer can obtain higher accuracy and generalization performance in the StoV (Spectrum to Vector) design compared to traditional multilayer perceptron (MLP) neural networks, while the StoI (Spectrum to Image) design achieved through CGAN can provide more comprehensive information and higher accuracy than the StoV design obtained by MLP. Moreover, the improved CGAN can achieve the inverse design of graphene metasurface images directly from the desired multi-resonant absorption spectra. It is turned out that this work can finish facilitating the design process of artificial intelligence-generated metasurfaces (AIGM), and even provide a useful guide for developing complex THz metasurfaces based on 2D materials using generative neural networks.
Selective Perception: Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
Jul 21, 2023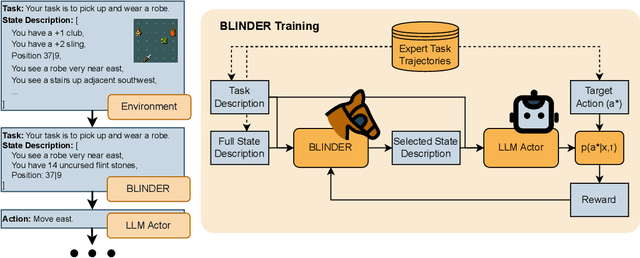

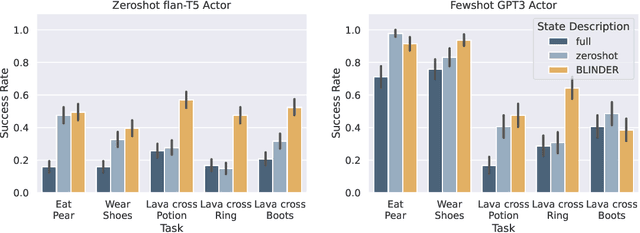
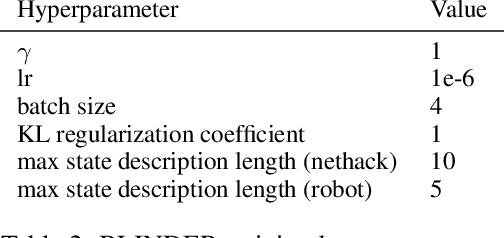
Large language models (LLMs) are being applied as actors for sequential decision making tasks in domains such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can impair performance and raise inference costs for LLM actors. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for task-conditioned state descriptions. We evaluate BLINDER on the challenging video game NetHack and a robotic manipulation task. Our method improves task success rate, reduces input size and compute costs, and generalizes between LLM actors.
RoSAS: Deep Semi-Supervised Anomaly Detection with Contamination-Resilient Continuous Supervision
Jul 25, 2023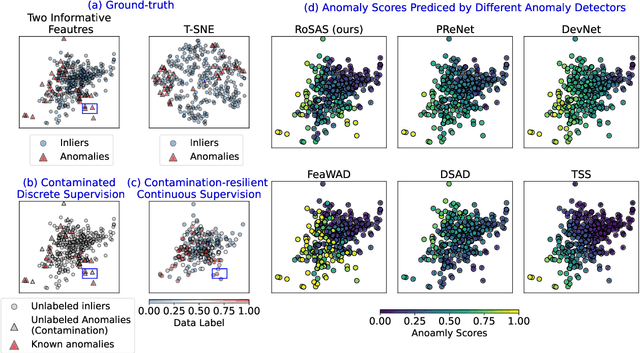

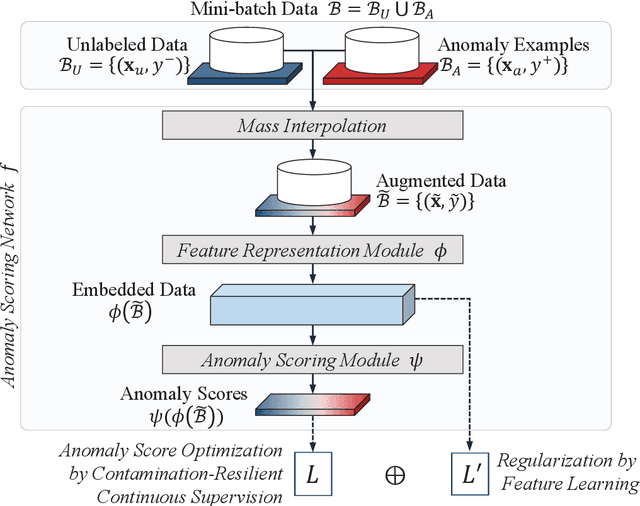
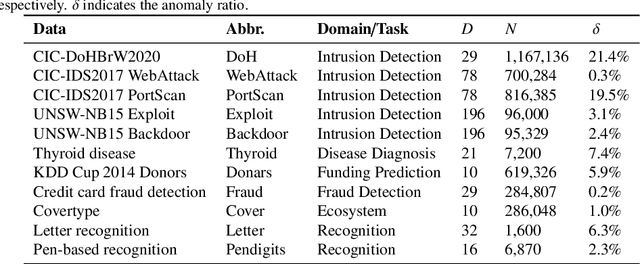
Semi-supervised anomaly detection methods leverage a few anomaly examples to yield drastically improved performance compared to unsupervised models. However, they still suffer from two limitations: 1) unlabeled anomalies (i.e., anomaly contamination) may mislead the learning process when all the unlabeled data are employed as inliers for model training; 2) only discrete supervision information (such as binary or ordinal data labels) is exploited, which leads to suboptimal learning of anomaly scores that essentially take on a continuous distribution. Therefore, this paper proposes a novel semi-supervised anomaly detection method, which devises \textit{contamination-resilient continuous supervisory signals}. Specifically, we propose a mass interpolation method to diffuse the abnormality of labeled anomalies, thereby creating new data samples labeled with continuous abnormal degrees. Meanwhile, the contaminated area can be covered by new data samples generated via combinations of data with correct labels. A feature learning-based objective is added to serve as an optimization constraint to regularize the network and further enhance the robustness w.r.t. anomaly contamination. Extensive experiments on 11 real-world datasets show that our approach significantly outperforms state-of-the-art competitors by 20%-30% in AUC-PR and obtains more robust and superior performance in settings with different anomaly contamination levels and varying numbers of labeled anomalies. The source code is available at https://github.com/xuhongzuo/rosas/.
Predicting Code Coverage without Execution
Jul 25, 2023
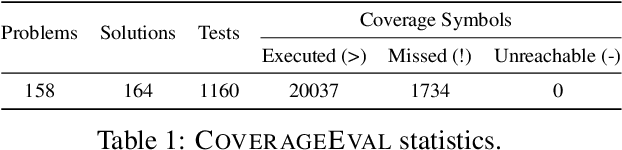

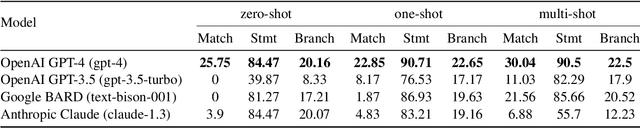
Code coverage is a widely used metric for quantifying the extent to which program elements, such as statements or branches, are executed during testing. Calculating code coverage is resource-intensive, requiring code building and execution with additional overhead for the instrumentation. Furthermore, computing coverage of any snippet of code requires the whole program context. Using Machine Learning to amortize this expensive process could lower the cost of code coverage by requiring only the source code context, and the task of code coverage prediction can be a novel benchmark for judging the ability of models to understand code. We propose a novel benchmark task called Code Coverage Prediction for Large Language Models (LLMs). We formalize this task to evaluate the capability of LLMs in understanding code execution by determining which lines of a method are executed by a given test case and inputs. We curate and release a dataset we call COVERAGEEVAL by executing tests and code from the HumanEval dataset and collecting code coverage information. We report the performance of four state-of-the-art LLMs used for code-related tasks, including OpenAI's GPT-4 and GPT-3.5-Turbo, Google's BARD, and Anthropic's Claude, on the Code Coverage Prediction task. Finally, we argue that code coverage as a metric and pre-training data source are valuable for overall LLM performance on software engineering tasks.
NormAUG: Normalization-guided Augmentation for Domain Generalization
Jul 25, 2023
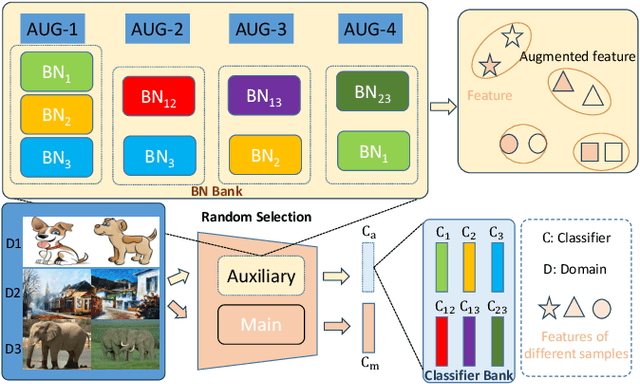
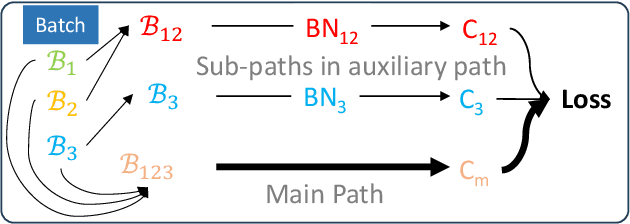
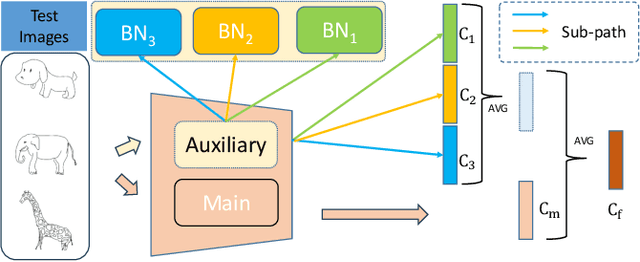
Deep learning has made significant advancements in supervised learning. However, models trained in this setting often face challenges due to domain shift between training and test sets, resulting in a significant drop in performance during testing. To address this issue, several domain generalization methods have been developed to learn robust and domain-invariant features from multiple training domains that can generalize well to unseen test domains. Data augmentation plays a crucial role in achieving this goal by enhancing the diversity of the training data. In this paper, inspired by the observation that normalizing an image with different statistics generated by different batches with various domains can perturb its feature, we propose a simple yet effective method called NormAUG (Normalization-guided Augmentation). Our method includes two paths: the main path and the auxiliary (augmented) path. During training, the auxiliary path includes multiple sub-paths, each corresponding to batch normalization for a single domain or a random combination of multiple domains. This introduces diverse information at the feature level and improves the generalization of the main path. Moreover, our NormAUG method effectively reduces the existing upper boundary for generalization based on theoretical perspectives. During the test stage, we leverage an ensemble strategy to combine the predictions from the auxiliary path of our model, further boosting performance. Extensive experiments are conducted on multiple benchmark datasets to validate the effectiveness of our proposed method.
Less is More: Focus Attention for Efficient DETR
Jul 24, 2023
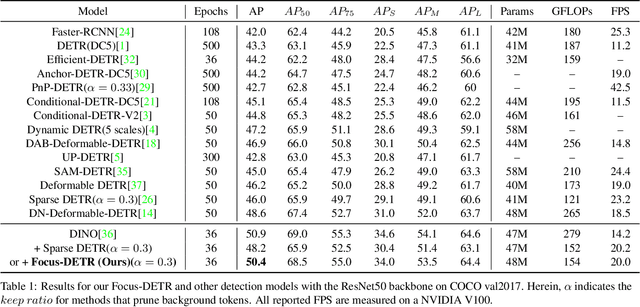
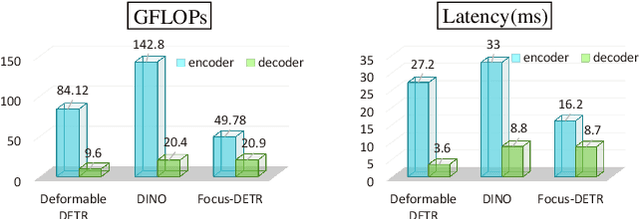
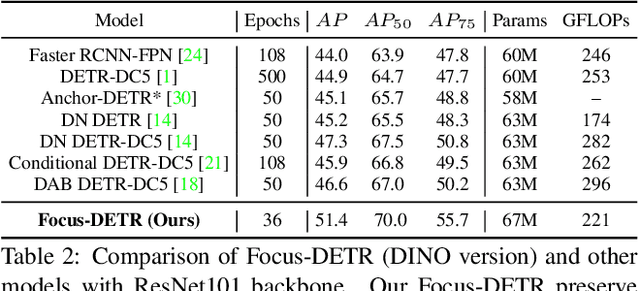
DETR-like models have significantly boosted the performance of detectors and even outperformed classical convolutional models. However, all tokens are treated equally without discrimination brings a redundant computational burden in the traditional encoder structure. The recent sparsification strategies exploit a subset of informative tokens to reduce attention complexity maintaining performance through the sparse encoder. But these methods tend to rely on unreliable model statistics. Moreover, simply reducing the token population hinders the detection performance to a large extent, limiting the application of these sparse models. We propose Focus-DETR, which focuses attention on more informative tokens for a better trade-off between computation efficiency and model accuracy. Specifically, we reconstruct the encoder with dual attention, which includes a token scoring mechanism that considers both localization and category semantic information of the objects from multi-scale feature maps. We efficiently abandon the background queries and enhance the semantic interaction of the fine-grained object queries based on the scores. Compared with the state-of-the-art sparse DETR-like detectors under the same setting, our Focus-DETR gets comparable complexity while achieving 50.4AP (+2.2) on COCO. The code is available at https://github.com/huawei-noah/noah-research/tree/master/Focus-DETR and https://gitee.com/mindspore/models/tree/master/research/cv/Focus-DETR.
Deep Directly-Trained Spiking Neural Networks for Object Detection
Jul 24, 2023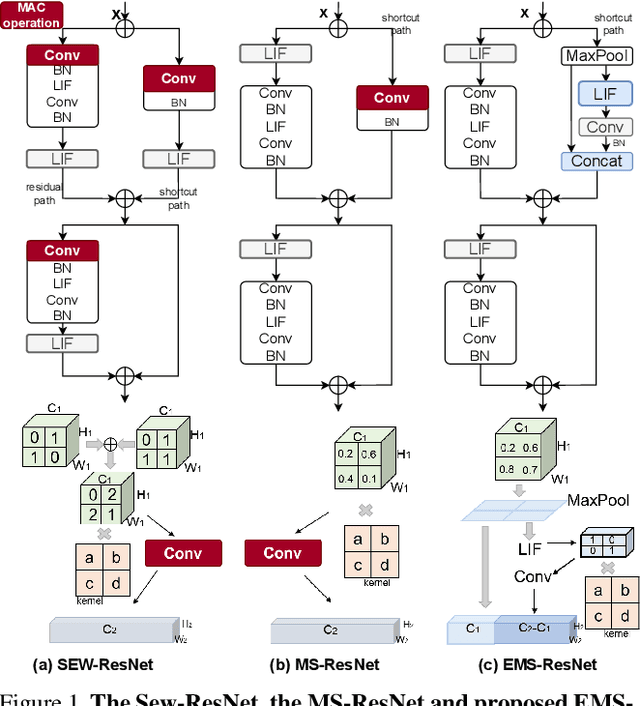

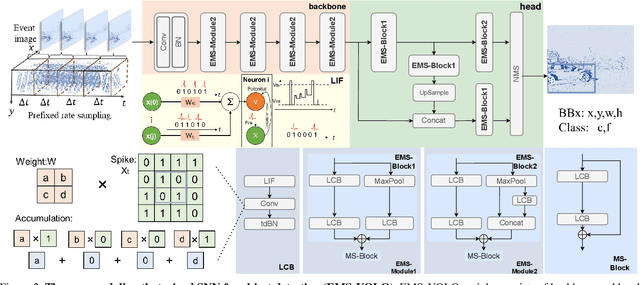
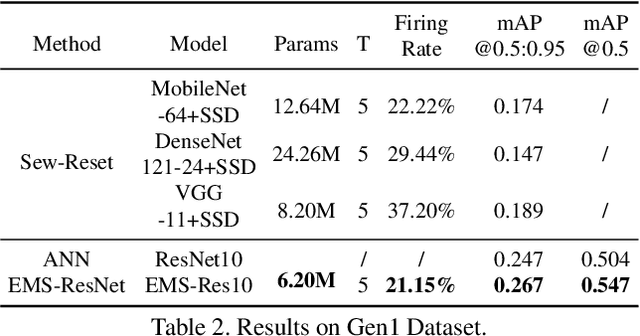
Spiking neural networks (SNNs) are brain-inspired energy-efficient models that encode information in spatiotemporal dynamics. Recently, deep SNNs trained directly have shown great success in achieving high performance on classification tasks with very few time steps. However, how to design a directly-trained SNN for the regression task of object detection still remains a challenging problem. To address this problem, we propose EMS-YOLO, a novel directly-trained SNN framework for object detection, which is the first trial to train a deep SNN with surrogate gradients for object detection rather than ANN-SNN conversion strategies. Specifically, we design a full-spike residual block, EMS-ResNet, which can effectively extend the depth of the directly-trained SNN with low power consumption. Furthermore, we theoretically analyze and prove the EMS-ResNet could avoid gradient vanishing or exploding. The results demonstrate that our approach outperforms the state-of-the-art ANN-SNN conversion methods (at least 500 time steps) in extremely fewer time steps (only 4 time steps). It is shown that our model could achieve comparable performance to the ANN with the same architecture while consuming 5.83 times less energy on the frame-based COCO Dataset and the event-based Gen1 Dataset.