 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Proximal Gradient Method for Convex Optimization
Aug 04, 2023
In this paper, we explore two fundamental first-order algorithms in convex optimization, namely, gradient descent (GD) and proximal gradient method (ProxGD). Our focus is on making these algorithms entirely adaptive by leveraging local curvature information of smooth functions. We propose adaptive versions of GD and ProxGD that are based on observed gradient differences and, thus, have no added computational costs. Moreover, we prove convergence of our methods assuming only local Lipschitzness of the gradient. In addition, the proposed versions allow for even larger stepsizes than those initially suggested in [MM20].
BEIR-PL: Zero Shot Information Retrieval Benchmark for the Polish Language
May 31, 2023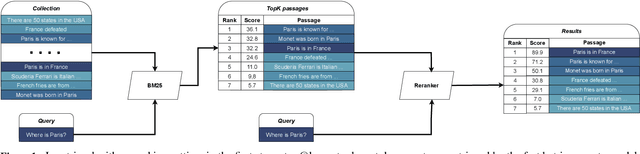
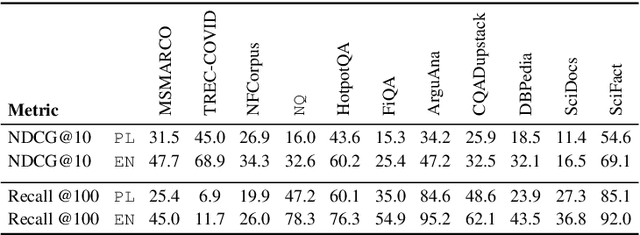
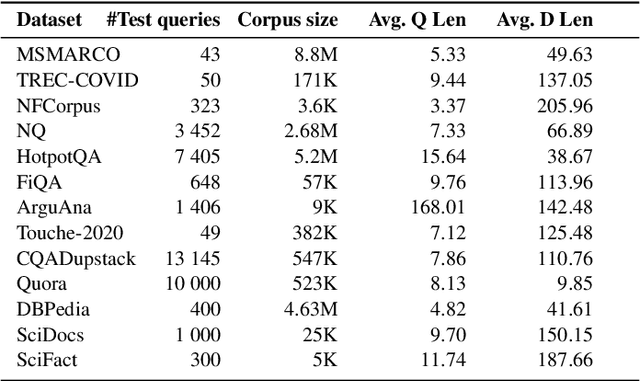
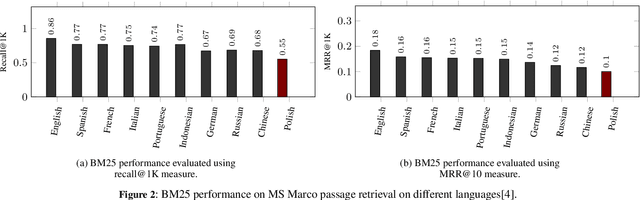
The BEIR dataset is a large, heterogeneous benchmark for Information Retrieval (IR) in zero-shot settings, garnering considerable attention within the research community. However, BEIR and analogous datasets are predominantly restricted to the English language. Our objective is to establish extensive large-scale resources for IR in the Polish language, thereby advancing the research in this NLP area. In this work, inspired by mMARCO and Mr.~TyDi datasets, we translated all accessible open IR datasets into Polish, and we introduced the BEIR-PL benchmark -- a new benchmark which comprises 13 datasets, facilitating further development, training and evaluation of modern Polish language models for IR tasks. We executed an evaluation and comparison of numerous IR models on the newly introduced BEIR-PL benchmark. Furthermore, we publish pre-trained open IR models for Polish language,d marking a pioneering development in this field. Additionally, the evaluation revealed that BM25 achieved significantly lower scores for Polish than for English, which can be attributed to high inflection and intricate morphological structure of the Polish language. Finally, we trained various re-ranking models to enhance the BM25 retrieval, and we compared their performance to identify their unique characteristic features. To ensure accurate model comparisons, it is necessary to scrutinise individual results rather than to average across the entire benchmark. Thus, we thoroughly analysed the outcomes of IR models in relation to each individual data subset encompassed by the BEIR benchmark. The benchmark data is available at URL {\bf https://huggingface.co/clarin-knext}.
Real-time Automatic M-mode Echocardiography Measurement with Panel Attention from Local-to-Global Pixels
Aug 15, 2023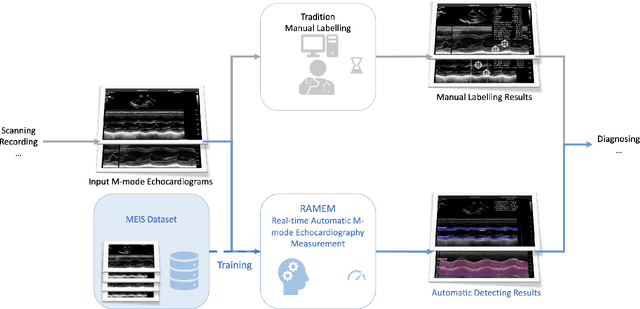
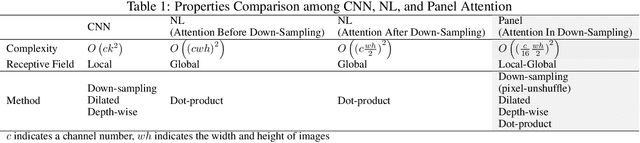
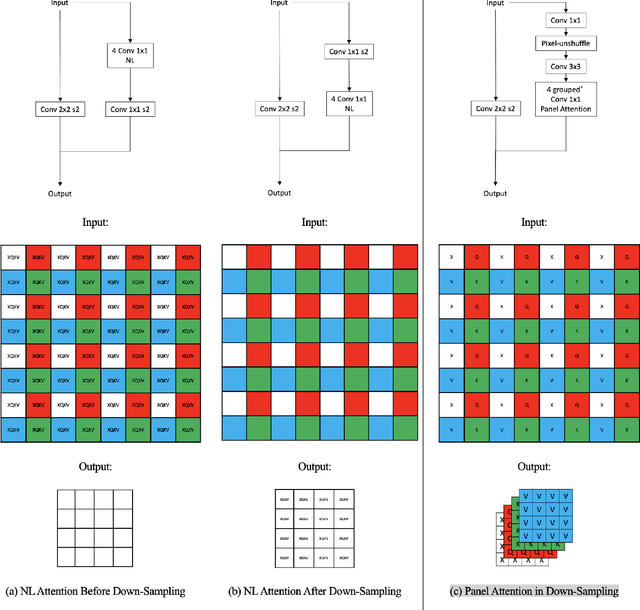

Motion mode (M-mode) recording is an essential part of echocardiography to measure cardiac dimension and function. However, the current diagnosis cannot build an automatic scheme, as there are three fundamental obstructs: Firstly, there is no open dataset available to build the automation for ensuring constant results and bridging M-mode echocardiography with real-time instance segmentation (RIS); Secondly, the examination is involving the time-consuming manual labelling upon M-mode echocardiograms; Thirdly, as objects in echocardiograms occupy a significant portion of pixels, the limited receptive field in existing backbones (e.g., ResNet) composed from multiple convolution layers are inefficient to cover the period of a valve movement. Existing non-local attentions (NL) compromise being unable real-time with a high computation overhead or losing information from a simplified version of the non-local block. Therefore, we proposed RAMEM, a real-time automatic M-mode echocardiography measurement scheme, contributes three aspects to answer the problems: 1) provide MEIS, a dataset of M-mode echocardiograms for instance segmentation, to enable consistent results and support the development of an automatic scheme; 2) propose panel attention, local-to-global efficient attention by pixel-unshuffling, embedding with updated UPANets V2 in a RIS scheme toward big object detection with global receptive field; 3) develop and implement AMEM, an efficient algorithm of automatic M-mode echocardiography measurement enabling fast and accurate automatic labelling among diagnosis. The experimental results show that RAMEM surpasses existing RIS backbones (with non-local attention) in PASCAL 2012 SBD and human performances in real-time MEIS tested. The code of MEIS and dataset are available at https://github.com/hanktseng131415go/RAME.
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation
Aug 12, 2023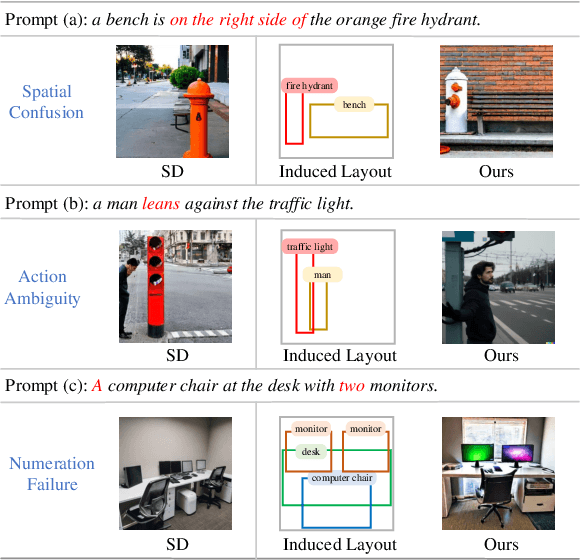
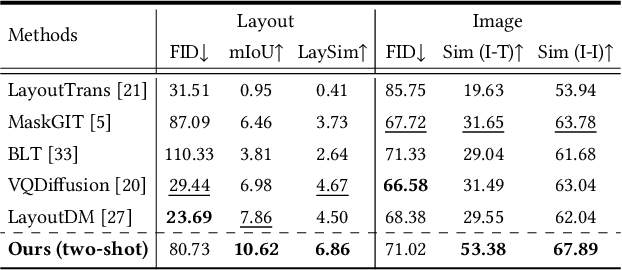
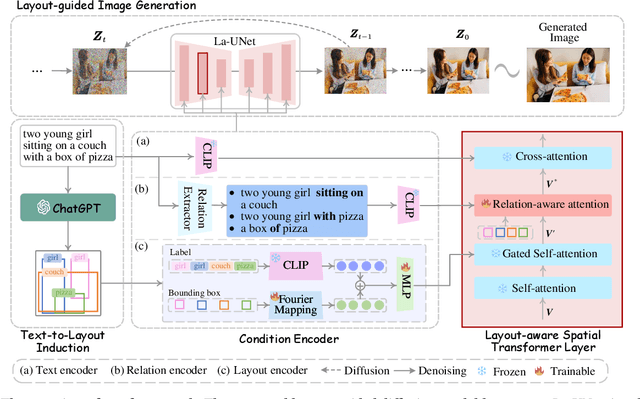

In the text-to-image generation field, recent remarkable progress in Stable Diffusion makes it possible to generate rich kinds of novel photorealistic images. However, current models still face misalignment issues (e.g., problematic spatial relation understanding and numeration failure) in complex natural scenes, which impedes the high-faithfulness text-to-image generation. Although recent efforts have been made to improve controllability by giving fine-grained guidance (e.g., sketch and scribbles), this issue has not been fundamentally tackled since users have to provide such guidance information manually. In this work, we strive to synthesize high-fidelity images that are semantically aligned with a given textual prompt without any guidance. Toward this end, we propose a coarse-to-fine paradigm to achieve layout planning and image generation. Concretely, we first generate the coarse-grained layout conditioned on a given textual prompt via in-context learning based on Large Language Models. Afterward, we propose a fine-grained object-interaction diffusion method to synthesize high-faithfulness images conditioned on the prompt and the automatically generated layout. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art models in terms of layout and image generation. Our code and settings are available at https://layoutllm-t2i.github.io.
BigWavGAN: A Wave-To-Wave Generative Adversarial Network for Music Super-Resolution
Aug 12, 2023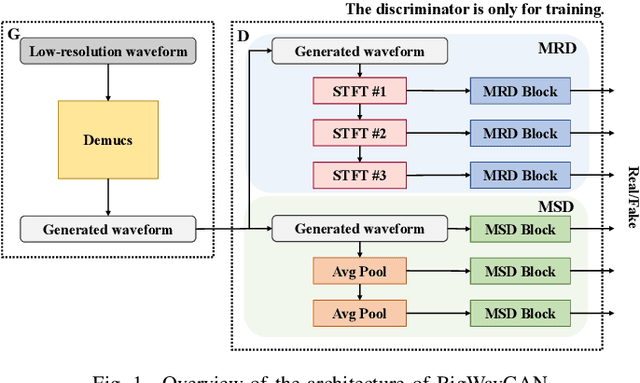
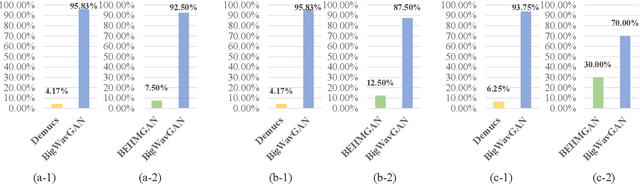
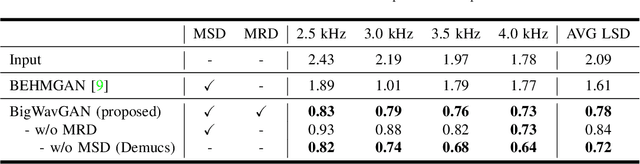
Generally, Deep Neural Networks (DNNs) are expected to have high performance when their model size is large. However, large models failed to produce high-quality results commensurate with their scale in music Super-Resolution (SR). We attribute this to that DNNs cannot learn information commensurate with their size from standard mean square error losses. To unleash the potential of large DNN models in music SR, we propose BigWavGAN, which incorporates Demucs, a large-scale wave-to-wave model, with State-Of-The-Art (SOTA) discriminators and adversarial training strategies. Our discriminator consists of Multi-Scale Discriminator (MSD) and Multi-Resolution Discriminator (MRD). During inference, since only the generator is utilized, there are no additional parameters or computational resources required compared to the baseline model Demucs. Objective evaluation affirms the effectiveness of BigWavGAN in music SR. Subjective evaluations indicate that BigWavGAN can generate music with significantly high perceptual quality over the baseline model. Notably, BigWavGAN surpasses the SOTA music SR model in both simulated and real-world scenarios. Moreover, BigWavGAN represents its superior generalization ability to address out-of-distribution data. The conducted ablation study reveals the importance of our discriminators and training strategies. Samples are available on the demo page.
ADRMX: Additive Disentanglement of Domain Features with Remix Loss
Aug 12, 2023
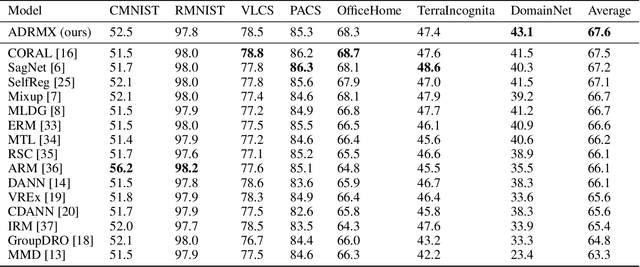
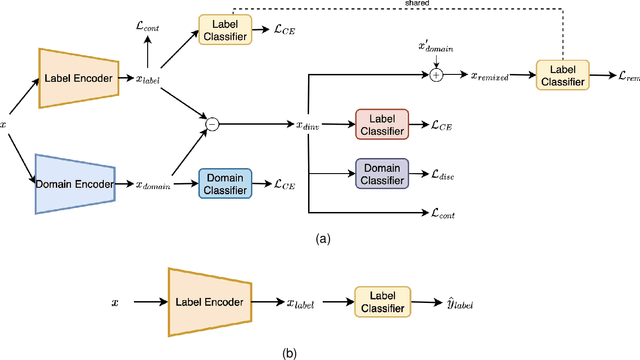

The common assumption that train and test sets follow similar distributions is often violated in deployment settings. Given multiple source domains, domain generalization aims to create robust models capable of generalizing to new unseen domains. To this end, most of existing studies focus on extracting domain invariant features across the available source domains in order to mitigate the effects of inter-domain distributional changes. However, this approach may limit the model's generalization capacity by relying solely on finding common features among the source domains. It overlooks the potential presence of domain-specific characteristics that could be prevalent in a subset of domains, potentially containing valuable information. In this work, a novel architecture named Additive Disentanglement of Domain Features with Remix Loss (ADRMX) is presented, which addresses this limitation by incorporating domain variant features together with the domain invariant ones using an original additive disentanglement strategy. Moreover, a new data augmentation technique is introduced to further support the generalization capacity of ADRMX, where samples from different domains are mixed within the latent space. Through extensive experiments conducted on DomainBed under fair conditions, ADRMX is shown to achieve state-of-the-art performance. Code will be made available at GitHub after the revision process.
EquiDiff: A Conditional Equivariant Diffusion Model For Trajectory Prediction
Aug 12, 2023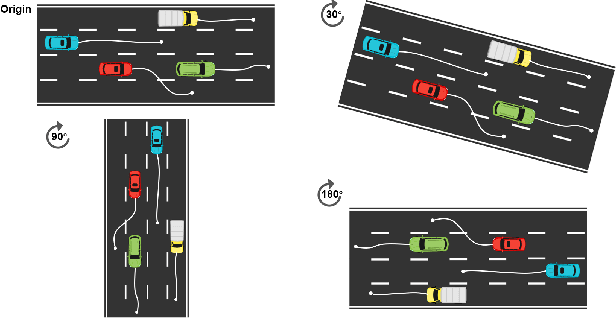
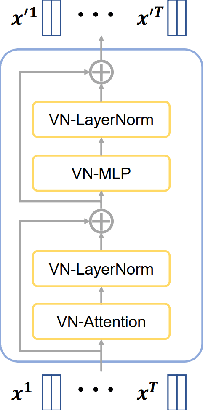
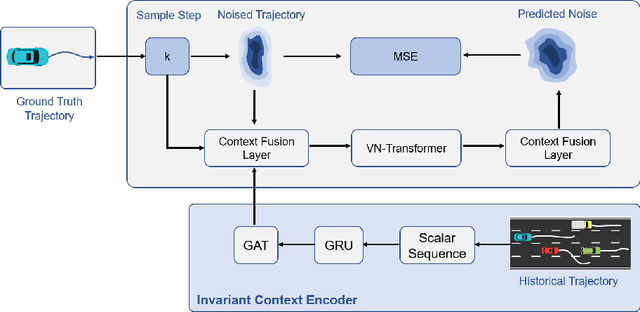
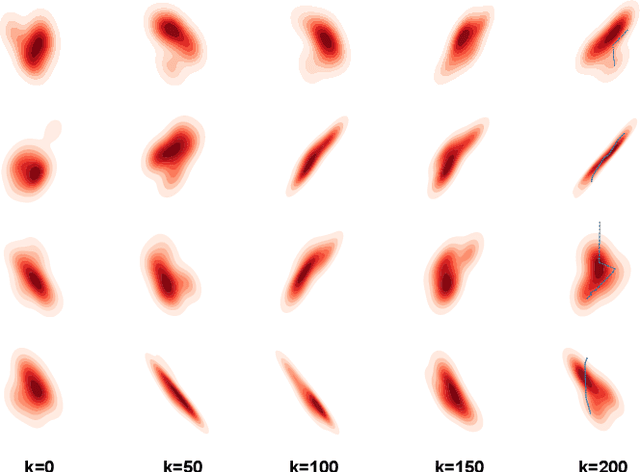
Accurate trajectory prediction is crucial for the safe and efficient operation of autonomous vehicles. The growing popularity of deep learning has led to the development of numerous methods for trajectory prediction. While deterministic deep learning models have been widely used, deep generative models have gained popularity as they learn data distributions from training data and account for trajectory uncertainties. In this study, we propose EquiDiff, a deep generative model for predicting future vehicle trajectories. EquiDiff is based on the conditional diffusion model, which generates future trajectories by incorporating historical information and random Gaussian noise. The backbone model of EquiDiff is an SO(2)-equivariant transformer that fully utilizes the geometric properties of location coordinates. In addition, we employ Recurrent Neural Networks and Graph Attention Networks to extract social interactions from historical trajectories. To evaluate the performance of EquiDiff, we conduct extensive experiments on the NGSIM dataset. Our results demonstrate that EquiDiff outperforms other baseline models in short-term prediction, but has slightly higher errors for long-term prediction. Furthermore, we conduct an ablation study to investigate the contribution of each component of EquiDiff to the prediction accuracy. Additionally, we present a visualization of the generation process of our diffusion model, providing insights into the uncertainty of the prediction.
Mani-GPT: A Generative Model for Interactive Robotic Manipulation
Aug 08, 2023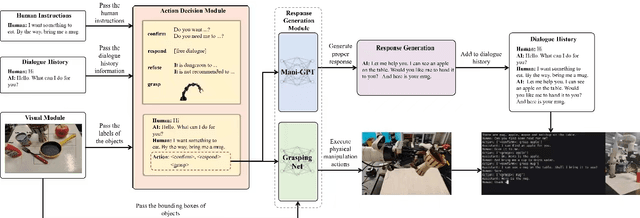

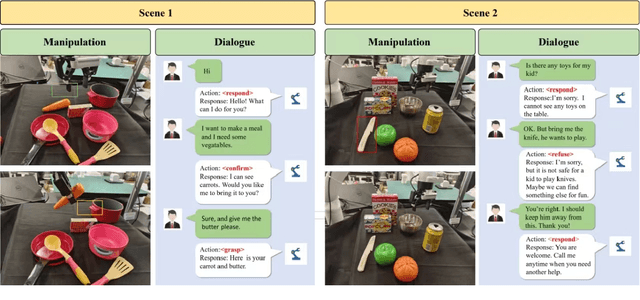
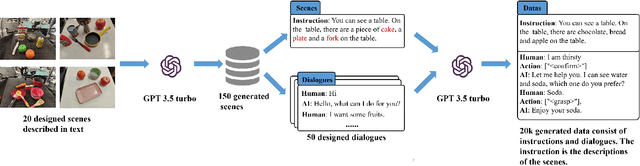
In real-world scenarios, human dialogues are multi-round and diverse. Furthermore, human instructions can be unclear and human responses are unrestricted. Interactive robots face difficulties in understanding human intents and generating suitable strategies for assisting individuals through manipulation. In this article, we propose Mani-GPT, a Generative Pre-trained Transformer (GPT) for interactive robotic manipulation. The proposed model has the ability to understand the environment through object information, understand human intent through dialogues, generate natural language responses to human input, and generate appropriate manipulation plans to assist the human. This makes the human-robot interaction more natural and humanized. In our experiment, Mani-GPT outperforms existing algorithms with an accuracy of 84.6% in intent recognition and decision-making for actions. Furthermore, it demonstrates satisfying performance in real-world dialogue tests with users, achieving an average response accuracy of 70%.
Multitask Learning with No Regret: from Improved Confidence Bounds to Active Learning
Aug 03, 2023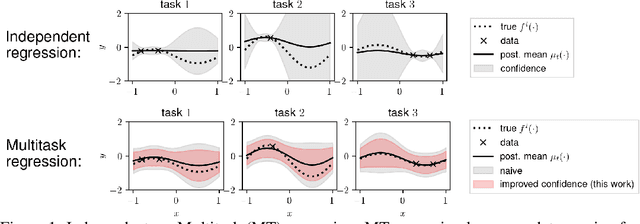

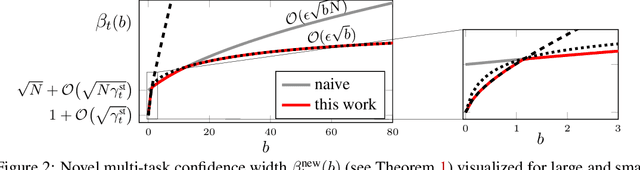
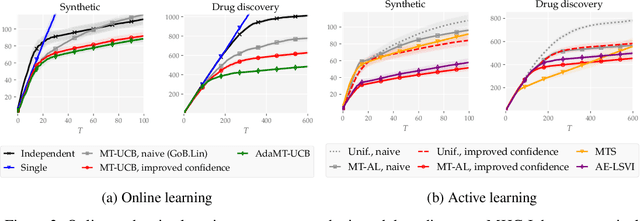
Multitask learning is a powerful framework that enables one to simultaneously learn multiple related tasks by sharing information between them. Quantifying uncertainty in the estimated tasks is of pivotal importance for many downstream applications, such as online or active learning. In this work, we provide novel multitask confidence intervals in the challenging agnostic setting, i.e., when neither the similarity between tasks nor the tasks' features are available to the learner. The obtained intervals do not require i.i.d. data and can be directly applied to bound the regret in online learning. Through a refined analysis of the multitask information gain, we obtain new regret guarantees that, depending on a task similarity parameter, can significantly improve over treating tasks independently. We further propose a novel online learning algorithm that achieves such improved regret without knowing this parameter in advance, i.e., automatically adapting to task similarity. As a second key application of our results, we introduce a novel multitask active learning setup where several tasks must be simultaneously optimized, but only one of them can be queried for feedback by the learner at each round. For this problem, we design a no-regret algorithm that uses our confidence intervals to decide which task should be queried. Finally, we empirically validate our bounds and algorithms on synthetic and real-world (drug discovery) data.
Audio-Visual Spatial Integration and Recursive Attention for Robust Sound Source Localization
Aug 11, 2023The objective of the sound source localization task is to enable machines to detect the location of sound-making objects within a visual scene. While the audio modality provides spatial cues to locate the sound source, existing approaches only use audio as an auxiliary role to compare spatial regions of the visual modality. Humans, on the other hand, utilize both audio and visual modalities as spatial cues to locate sound sources. In this paper, we propose an audio-visual spatial integration network that integrates spatial cues from both modalities to mimic human behavior when detecting sound-making objects. Additionally, we introduce a recursive attention network to mimic human behavior of iterative focusing on objects, resulting in more accurate attention regions. To effectively encode spatial information from both modalities, we propose audio-visual pair matching loss and spatial region alignment loss. By utilizing the spatial cues of audio-visual modalities and recursively focusing objects, our method can perform more robust sound source localization. Comprehensive experimental results on the Flickr SoundNet and VGG-Sound Source datasets demonstrate the superiority of our proposed method over existing approaches. Our code is available at: https://github.com/VisualAIKHU/SIRA-SSL