 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Occlusion-Aware Deep Convolutional Neural Network via Homogeneous Tanh-transforms for Face Parsing
Aug 29, 2023
Face parsing infers a pixel-wise label map for each semantic facial component. Previous methods generally work well for uncovered faces, however overlook the facial occlusion and ignore some contextual area outside a single face, especially when facial occlusion has become a common situation during the COVID-19 epidemic. Inspired by the illumination theory of image, we propose a novel homogeneous tanh-transforms for image preprocessing, which made up of four tanh-transforms, that fuse the central vision and the peripheral vision together. Our proposed method addresses the dilemma of face parsing under occlusion and compresses more information of surrounding context. Based on homogeneous tanh-transforms, we propose an occlusion-aware convolutional neural network for occluded face parsing. It combines the information both in Tanh-polar space and Tanh-Cartesian space, capable of enhancing receptive fields. Furthermore, we introduce an occlusion-aware loss to focus on the boundaries of occluded regions. The network is simple and flexible, and can be trained end-to-end. To facilitate future research of occluded face parsing, we also contribute a new cleaned face parsing dataset, which is manually purified from several academic or industrial datasets, including CelebAMask-HQ, Short-video Face Parsing as well as Helen dataset and will make it public. Experiments demonstrate that our method surpasses state-of-art methods of face parsing under occlusion.
Complementing Onboard Sensors with Satellite Map: A New Perspective for HD Map Construction
Aug 29, 2023
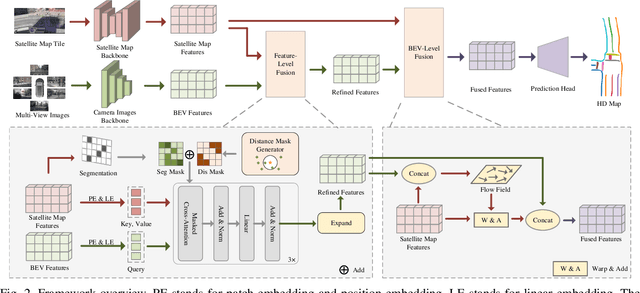
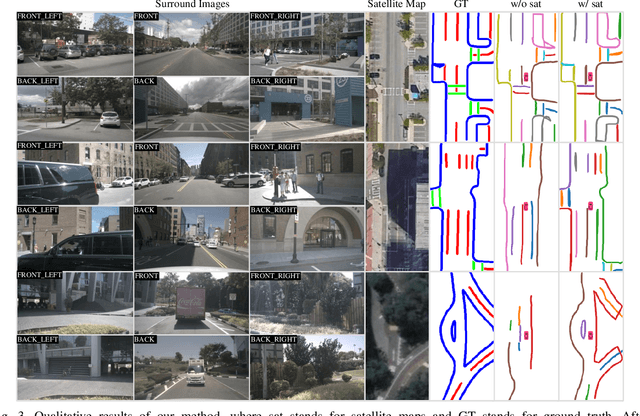
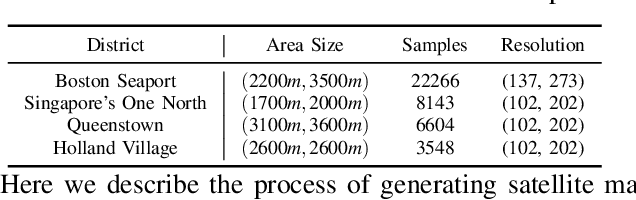
High-Definition (HD) maps play a crucial role in autonomous driving systems. Recent methods have attempted to construct HD maps in real-time based on information obtained from vehicle onboard sensors. However, the performance of these methods is significantly susceptible to the environment surrounding the vehicle due to the inherent limitation of onboard sensors, such as weak capacity for long-range detection. In this study, we demonstrate that supplementing onboard sensors with satellite maps can enhance the performance of HD map construction methods, leveraging the broad coverage capability of satellite maps. For the purpose of further research, we release the satellite map tiles as a complementary dataset of nuScenes dataset. Meanwhile, we propose a hierarchical fusion module that enables better fusion of satellite maps information with existing methods. Specifically, we design an attention mask based on segmentation and distance, applying the cross-attention mechanism to fuse onboard Bird's Eye View (BEV) features and satellite features in feature-level fusion. An alignment module is introduced before concatenation in BEV-level fusion to mitigate the impact of misalignment between the two features. The experimental results on the augmented nuScenes dataset showcase the seamless integration of our module into three existing HD map construction methods. It notably enhances their performance in both HD map semantic segmentation and instance detection tasks.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023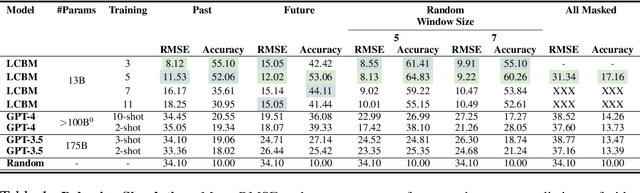
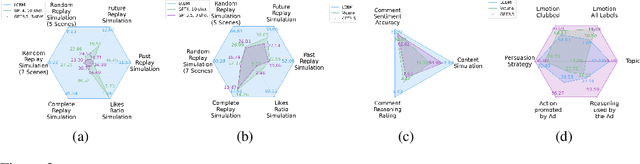
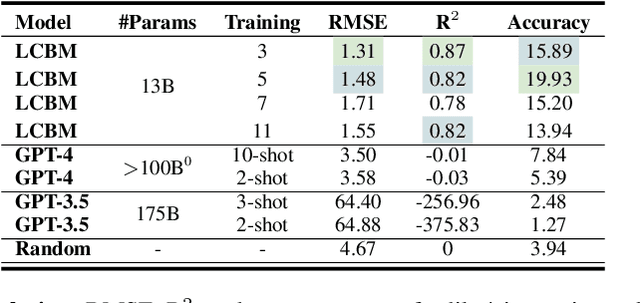
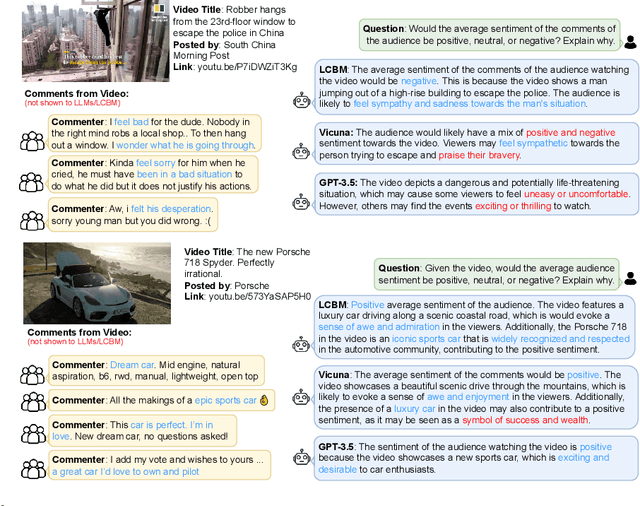
Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
Cache-assisted Mobile Edge Computing over Space-Air-Ground Integrated Networks for Extended Reality Applications
Sep 08, 2023Extended reality-enabled Internet of Things (XRI) provides the new user experience and the sense of immersion by adding virtual elements to the real world through Internet of Things (IoT) devices and emerging 6G technologies. However, the computational-intensive XRI tasks are challenging for the energy-constrained small-size XRI devices to cope with, and moreover certain data requires centralized computing that needs to be shared among users. To this end, we propose a cache-assisted space-air-ground integrated network mobile edge computing (SAGIN-MEC) system for XRI applications, consisting of two types of edge servers mounted on an unmanned aerial vehicle (UAV) and low Earth orbit (LEO) equipped with cache and the multiple ground XRI devices. For system efficiency, the four different offloading procedures of the XRI data are considered according to the type of information, i.e., shared data and private data, as well as the offloading decision and the caching status. Specifically, the private data can be offloaded to either UAV or LEO, while the offloading decision of the shared data to the LEO can be determined by the caching status. With the aim of maximizing the energy efficiency of the overall system, we jointly optimize UAV trajectory, resource allocation and offloading decisions under latency constraints and UAV's operational limitations by using the alternating optimization (AO)-based method along with Dinkelbach algorithm and successive convex optimization (SCA). Via numerical results, the proposed algorithm is verified to have the superior performance compared to conventional partial optimizations or without cache.
Leveraging Prototype Patient Representations with Feature-Missing-Aware Calibration to Mitigate EHR Data Sparsity
Sep 08, 2023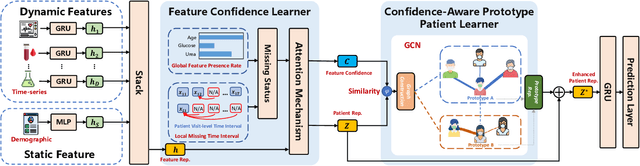
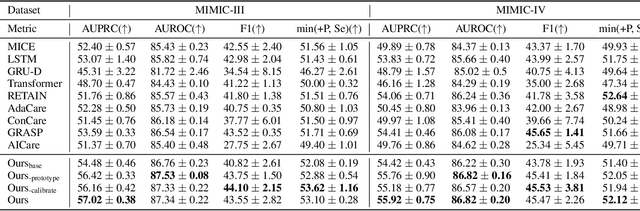
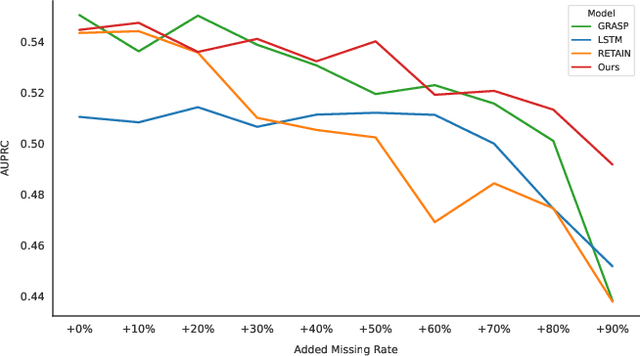
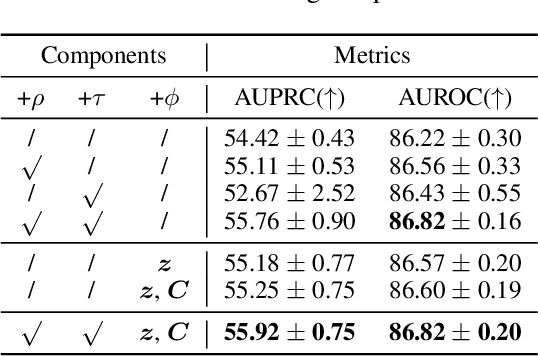
Electronic Health Record (EHR) data frequently exhibits sparse characteristics, posing challenges for predictive modeling. Current direct imputation such as matrix imputation approaches hinge on referencing analogous rows or columns to complete raw missing data and do not differentiate between imputed and actual values. As a result, models may inadvertently incorporate irrelevant or deceptive information with respect to the prediction objective, thereby compromising the efficacy of downstream performance. While some methods strive to recalibrate or augment EHR embeddings after direct imputation, they often mistakenly prioritize imputed features. This misprioritization can introduce biases or inaccuracies into the model. To tackle these issues, our work resorts to indirect imputation, where we leverage prototype representations from similar patients to obtain a denser embedding. Recognizing the limitation that missing features are typically treated the same as present ones when measuring similar patients, our approach designs a feature confidence learner module. This module is sensitive to the missing feature status, enabling the model to better judge the reliability of each feature. Moreover, we propose a novel patient similarity metric that takes feature confidence into account, ensuring that evaluations are not based merely on potentially inaccurate imputed values. Consequently, our work captures dense prototype patient representations with feature-missing-aware calibration process. Comprehensive experiments demonstrate that designed model surpasses established EHR-focused models with a statistically significant improvement on MIMIC-III and MIMIC-IV datasets in-hospital mortality outcome prediction task. The code is publicly available at \url{https://anonymous.4open.science/r/SparseEHR} to assure the reproducibility.
Spatial Reconstructed Local Attention Res2Net with F0 Subband for Fake Speech Detection
Aug 19, 2023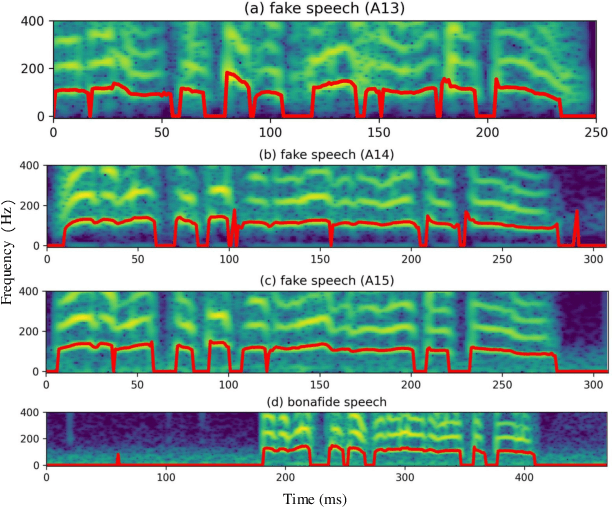
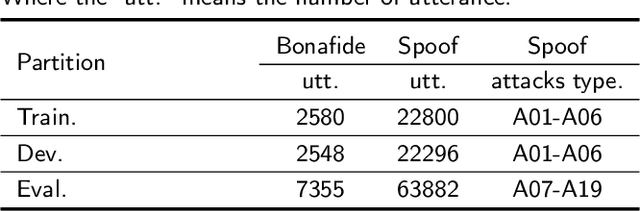
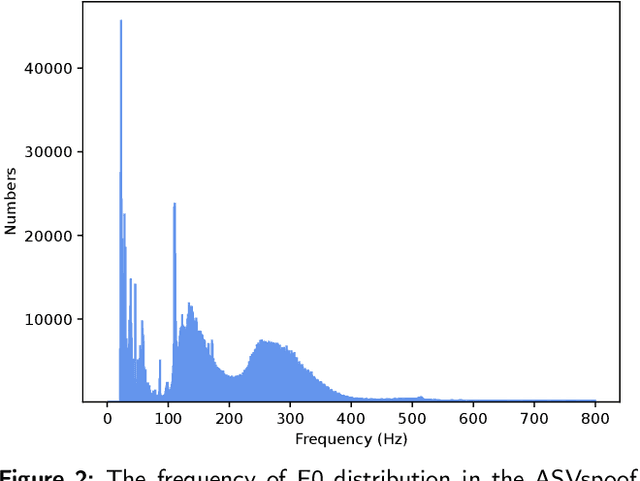
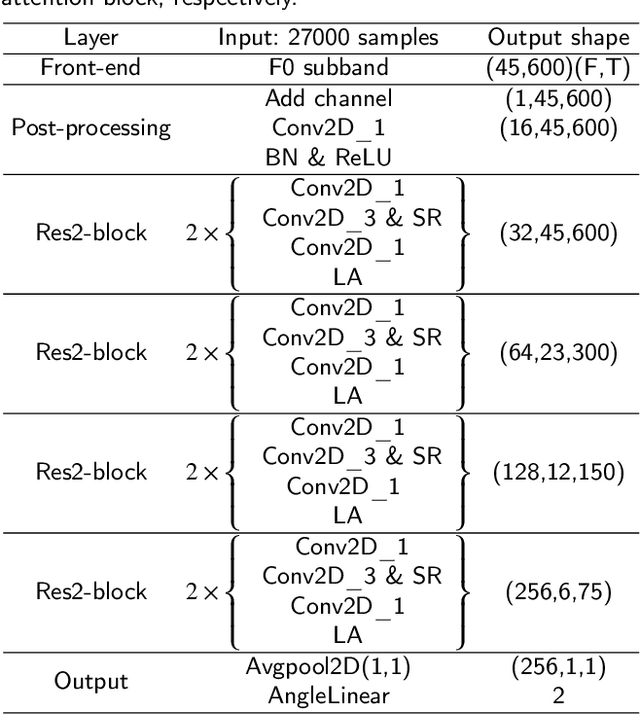
The rhythm of synthetic speech is usually too smooth, which causes that the fundamental frequency (F0) of synthetic speech is significantly different from that of real speech. It is expected that the F0 feature contains the discriminative information for the fake speech detection (FSD) task. In this paper, we propose a novel F0 subband for FSD. In addition, to effectively model the F0 subband so as to improve the performance of FSD, the spatial reconstructed local attention Res2Net (SR-LA Res2Net) is proposed. Specifically, Res2Net is used as a backbone network to obtain multiscale information, and enhanced with a spatial reconstruction mechanism to avoid losing important information when the channel group is constantly superimposed. In addition, local attention is designed to make the model focus on the local information of the F0 subband. Experimental results on the ASVspoof 2019 LA dataset show that our proposed method obtains an equal error rate (EER) of 0.47% and a minimum tandem detection cost function (min t-DCF) of 0.0159, achieving the state-of-the-art performance among all of the single systems.
A Mathematical Characterization of Minimally Sufficient Robot Brains
Aug 17, 2023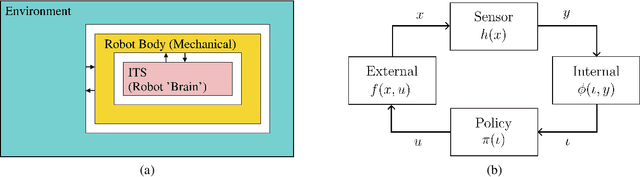
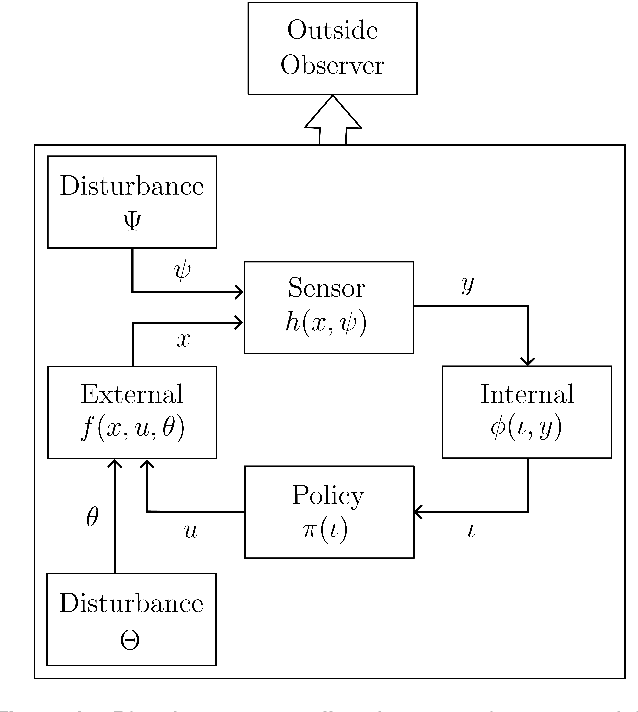
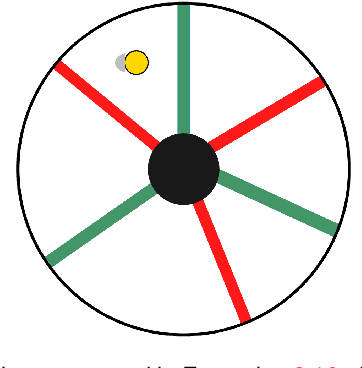
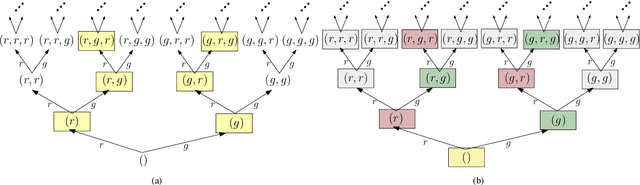
This paper addresses the lower limits of encoding and processing the information acquired through interactions between an internal system (robot algorithms or software) and an external system (robot body and its environment) in terms of action and observation histories. Both are modeled as transition systems. We want to know the weakest internal system that is sufficient for achieving passive (filtering) and active (planning) tasks. We introduce the notion of an information transition system for the internal system which is a transition system over a space of information states that reflect a robot's or other observer's perspective based on limited sensing, memory, computation, and actuation. An information transition system is viewed as a filter and a policy or plan is viewed as a function that labels the states of this information transition system. Regardless of whether internal systems are obtained by learning algorithms, planning algorithms, or human insight, we want to know the limits of feasibility for given robot hardware and tasks. We establish, in a general setting, that minimal information transition systems exist up to reasonable equivalence assumptions, and are unique under some general conditions. We then apply the theory to generate new insights into several problems, including optimal sensor fusion/filtering, solving basic planning tasks, and finding minimal representations for modeling a system given input-output relations.
SwinV2DNet: Pyramid and Self-Supervision Compounded Feature Learning for Remote Sensing Images Change Detection
Aug 22, 2023
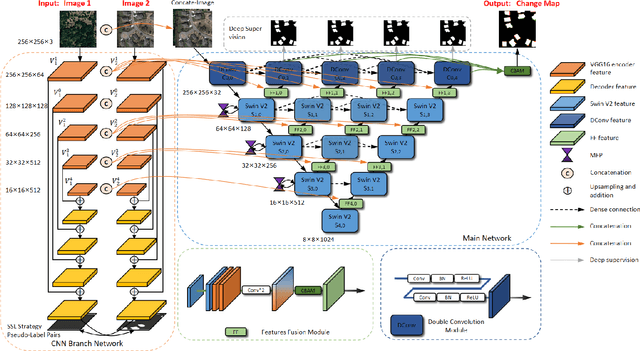
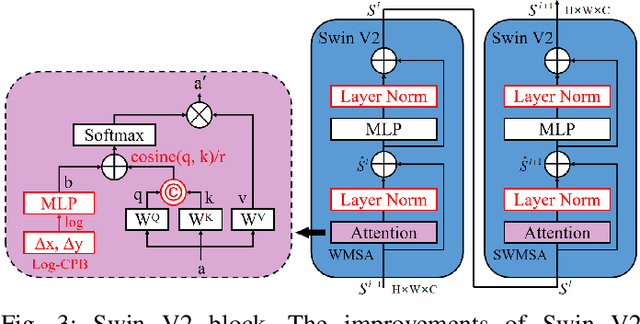
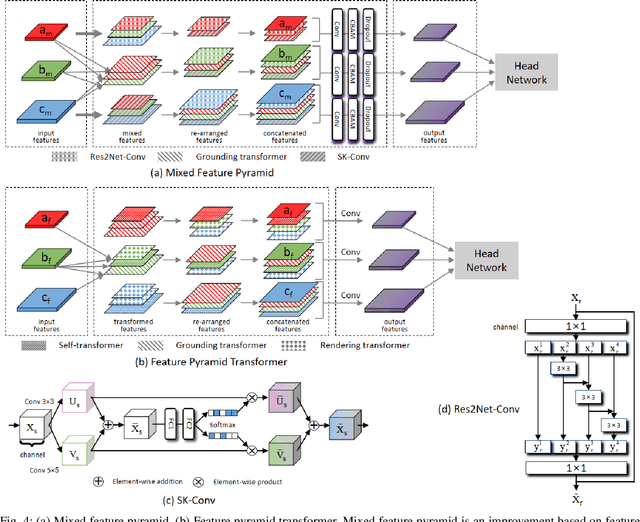
Among the current mainstream change detection networks, transformer is deficient in the ability to capture accurate low-level details, while convolutional neural network (CNN) is wanting in the capacity to understand global information and establish remote spatial relationships. Meanwhile, both of the widely used early fusion and late fusion frameworks are not able to well learn complete change features. Therefore, based on swin transformer V2 (Swin V2) and VGG16, we propose an end-to-end compounded dense network SwinV2DNet to inherit the advantages of both transformer and CNN and overcome the shortcomings of existing networks in feature learning. Firstly, it captures the change relationship features through the densely connected Swin V2 backbone, and provides the low-level pre-changed and post-changed features through a CNN branch. Based on these three change features, we accomplish accurate change detection results. Secondly, combined with transformer and CNN, we propose mixed feature pyramid (MFP) which provides inter-layer interaction information and intra-layer multi-scale information for complete feature learning. MFP is a plug and play module which is experimentally proven to be also effective in other change detection networks. Further more, we impose a self-supervision strategy to guide a new CNN branch, which solves the untrainable problem of the CNN branch and provides the semantic change information for the features of encoder. The state-of-the-art (SOTA) change detection scores and fine-grained change maps were obtained compared with other advanced methods on four commonly used public remote sensing datasets. The code is available at https://github.com/DalongZ/SwinV2DNet.
Link Prediction for Wikipedia Articles as a Natural Language Inference Task
Sep 05, 2023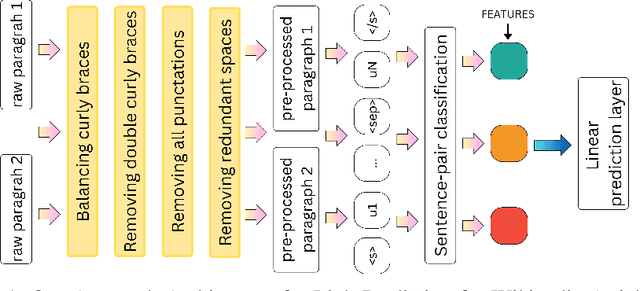
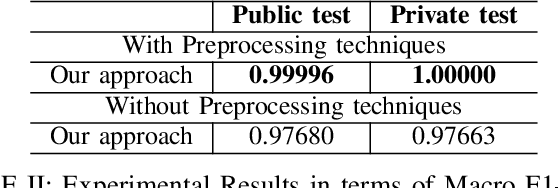
Link prediction task is vital to automatically understanding the structure of large knowledge bases. In this paper, we present our system to solve this task at the Data Science and Advanced Analytics 2023 Competition "Efficient and Effective Link Prediction" (DSAA-2023 Competition) with a corpus containing 948,233 training and 238,265 for public testing. This paper introduces an approach to link prediction in Wikipedia articles by formulating it as a natural language inference (NLI) task. Drawing inspiration from recent advancements in natural language processing and understanding, we cast link prediction as an NLI task, wherein the presence of a link between two articles is treated as a premise, and the task is to determine whether this premise holds based on the information presented in the articles. We implemented our system based on the Sentence Pair Classification for Link Prediction for the Wikipedia Articles task. Our system achieved 0.99996 Macro F1-score and 1.00000 Macro F1-score for the public and private test sets, respectively. Our team UIT-NLP ranked 3rd in performance on the private test set, equal to the scores of the first and second places. Our code is publicly for research purposes.
Robustness and Generalizability of Deepfake Detection: A Study with Diffusion Models
Sep 05, 2023
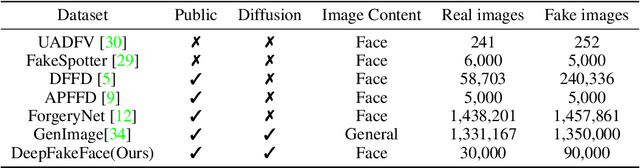
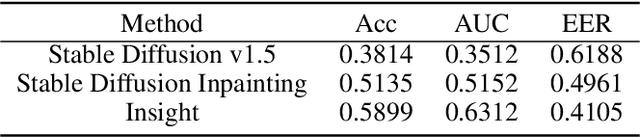

The rise of deepfake images, especially of well-known personalities, poses a serious threat to the dissemination of authentic information. To tackle this, we present a thorough investigation into how deepfakes are produced and how they can be identified. The cornerstone of our research is a rich collection of artificial celebrity faces, titled DeepFakeFace (DFF). We crafted the DFF dataset using advanced diffusion models and have shared it with the community through online platforms. This data serves as a robust foundation to train and test algorithms designed to spot deepfakes. We carried out a thorough review of the DFF dataset and suggest two evaluation methods to gauge the strength and adaptability of deepfake recognition tools. The first method tests whether an algorithm trained on one type of fake images can recognize those produced by other methods. The second evaluates the algorithm's performance with imperfect images, like those that are blurry, of low quality, or compressed. Given varied results across deepfake methods and image changes, our findings stress the need for better deepfake detectors. Our DFF dataset and tests aim to boost the development of more effective tools against deepfakes.