 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalised and Adjustable Interval Type-2 Fuzzy-Based PPG Quality Assessment for the Edge
Sep 23, 2023
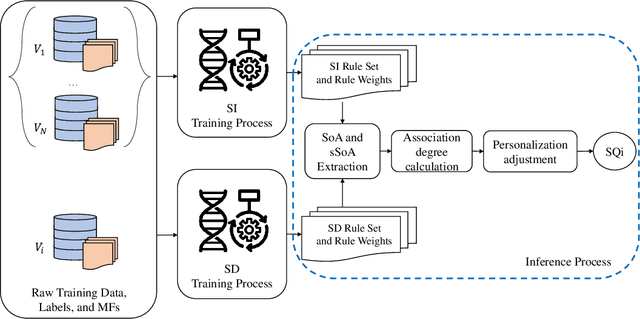
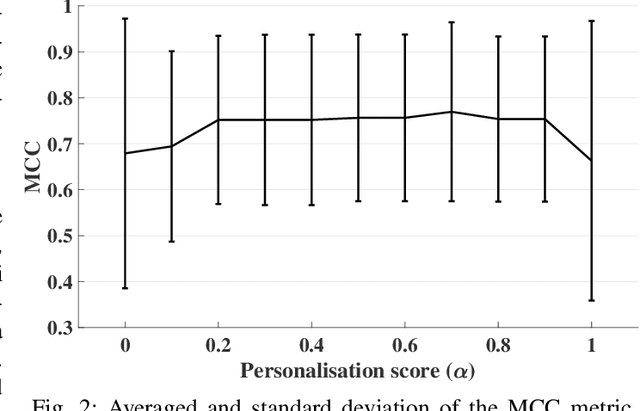

Most of today's wearable technology provides seamless cardiac activity monitoring. Specifically, the vast majority employ Photoplethysmography (PPG) sensors to acquire blood volume pulse information, which is further analysed to extract useful and physiologically related features. Nevertheless, PPG-based signal reliability presents different challenges that strongly affect such data processing. This is mainly related to the fact of PPG morphological wave distortion due to motion artefacts, which can lead to erroneous interpretation of the extracted cardiac-related features. On this basis, in this paper, we propose a novel personalised and adjustable Interval Type-2 Fuzzy Logic System (IT2FLS) for assessing the quality of PPG signals. The proposed system employs a personalised approach to adapt the IT2FLS parameters to the unique characteristics of each individual's PPG signals.Additionally, the system provides adjustable levels of personalisation, allowing healthcare providers to adjust the system to meet specific requirements for different applications. The proposed system obtained up to 93.72\% for average accuracy during validation. The presented system has the potential to enable ultra-low complexity and real-time PPG quality assessment, improving the accuracy and reliability of PPG-based health monitoring systems at the edge.
MP-MVS: Multi-Scale Windows PatchMatch and Planar Prior Multi-View Stereo
Sep 23, 2023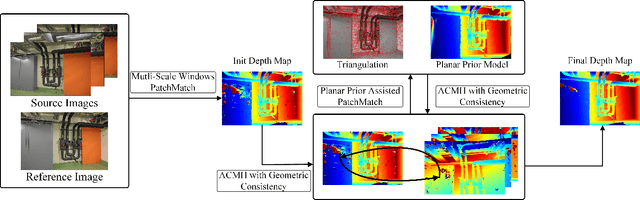
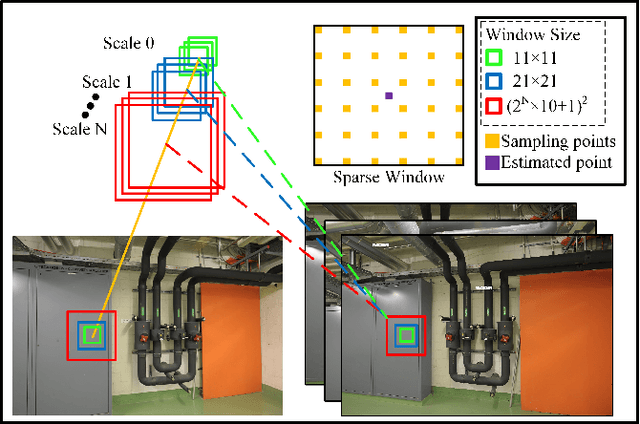

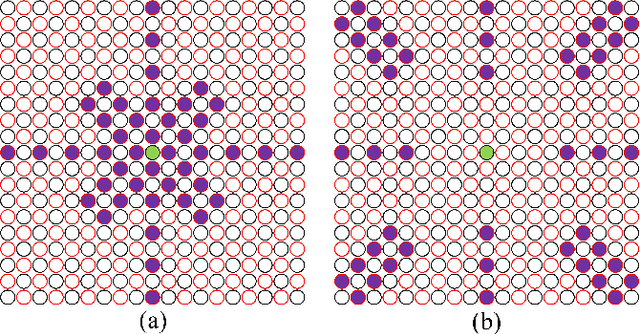
Significant strides have been made in enhancing the accuracy of Multi-View Stereo (MVS)-based 3D reconstruction. However, untextured areas with unstable photometric consistency often remain incompletely reconstructed. In this paper, we propose a resilient and effective multi-view stereo approach (MP-MVS). We design a multi-scale windows PatchMatch (mPM) to obtain reliable depth of untextured areas. In contrast with other multi-scale approaches, which is faster and can be easily extended to PatchMatch-based MVS approaches. Subsequently, we improve the existing checkerboard sampling schemes by limiting our sampling to distant regions, which can effectively improve the efficiency of spatial propagation while mitigating outlier generation. Finally, we introduce and improve planar prior assisted PatchMatch of ACMP. Instead of relying on photometric consistency, we utilize geometric consistency information between multi-views to select reliable triangulated vertices. This strategy can obtain a more accurate planar prior model to rectify photometric consistency measurements. Our approach has been tested on the ETH3D High-res multi-view benchmark with several state-of-the-art approaches. The results demonstrate that our approach can reach the state-of-the-art. The associated codes will be accessible at https://github.com/RongxuanTan/MP-MVS.
REPA: Client Clustering without Training and Data Labels for Improved Federated Learning in Non-IID Settings
Sep 25, 2023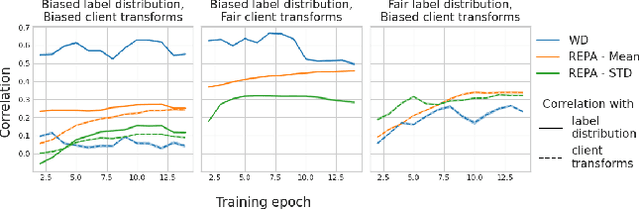
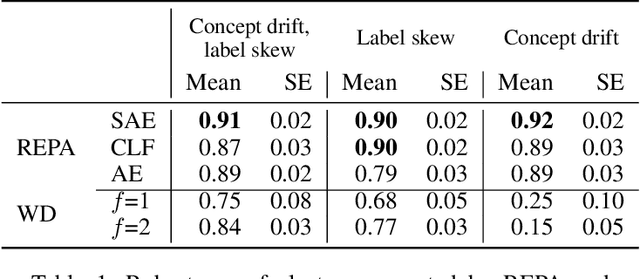
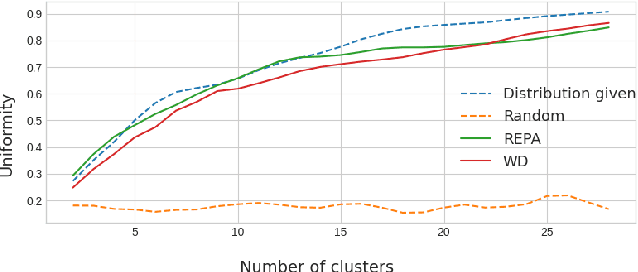
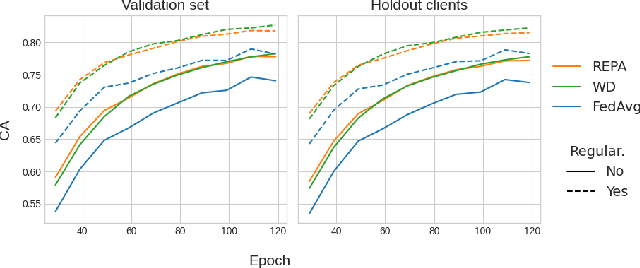
Clustering clients into groups that exhibit relatively homogeneous data distributions represents one of the major means of improving the performance of federated learning (FL) in non-independent and identically distributed (non-IID) data settings. Yet, the applicability of current state-of-the-art approaches remains limited as these approaches cluster clients based on information, such as the evolution of local model parameters, that is only obtainable through actual on-client training. On the other hand, there is a need to make FL models available to clients who are not able to perform the training themselves, as they do not have the processing capabilities required for training, or simply want to use the model without participating in the training. Furthermore, the existing alternative approaches that avert the training still require that individual clients have a sufficient amount of labeled data upon which the clustering is based, essentially assuming that each client is a data annotator. In this paper, we present REPA, an approach to client clustering in non-IID FL settings that requires neither training nor labeled data collection. REPA uses a novel supervised autoencoder-based method to create embeddings that profile a client's underlying data-generating processes without exposing the data to the server and without requiring local training. Our experimental analysis over three different datasets demonstrates that REPA delivers state-of-the-art model performance while expanding the applicability of cluster-based FL to previously uncovered use cases.
Informative Data Mining for One-Shot Cross-Domain Semantic Segmentation
Sep 25, 2023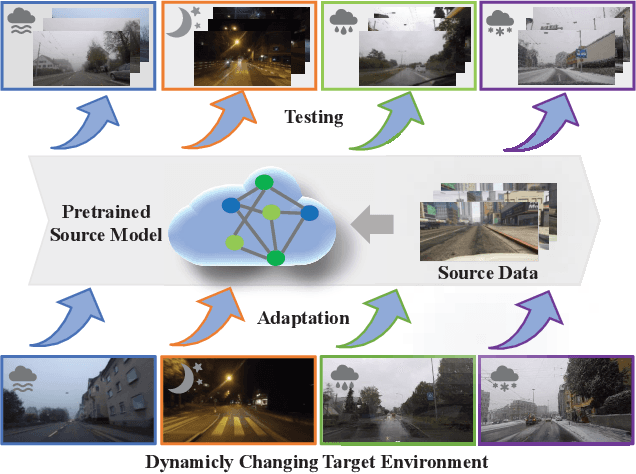
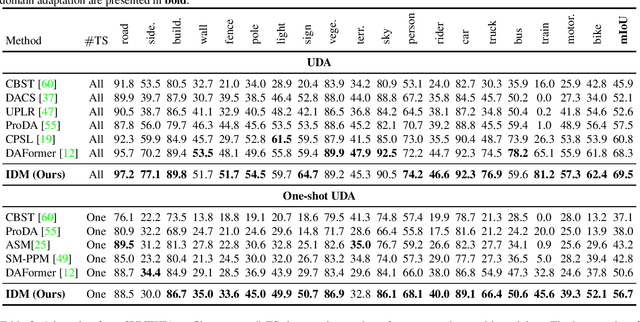
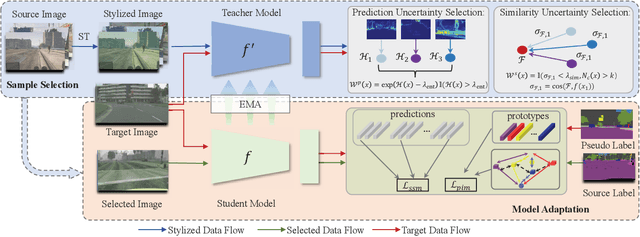
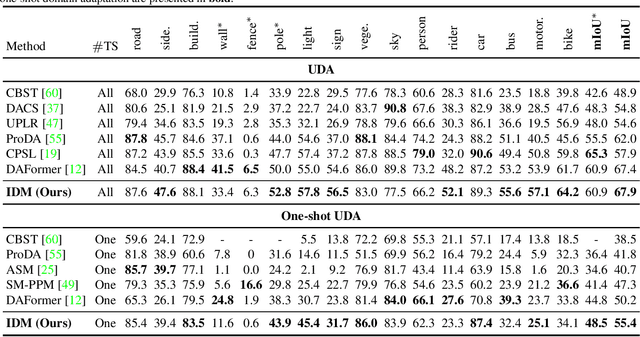
Contemporary domain adaptation offers a practical solution for achieving cross-domain transfer of semantic segmentation between labeled source data and unlabeled target data. These solutions have gained significant popularity; however, they require the model to be retrained when the test environment changes. This can result in unbearable costs in certain applications due to the time-consuming training process and concerns regarding data privacy. One-shot domain adaptation methods attempt to overcome these challenges by transferring the pre-trained source model to the target domain using only one target data. Despite this, the referring style transfer module still faces issues with computation cost and over-fitting problems. To address this problem, we propose a novel framework called Informative Data Mining (IDM) that enables efficient one-shot domain adaptation for semantic segmentation. Specifically, IDM provides an uncertainty-based selection criterion to identify the most informative samples, which facilitates quick adaptation and reduces redundant training. We then perform a model adaptation method using these selected samples, which includes patch-wise mixing and prototype-based information maximization to update the model. This approach effectively enhances adaptation and mitigates the overfitting problem. In general, we provide empirical evidence of the effectiveness and efficiency of IDM. Our approach outperforms existing methods and achieves a new state-of-the-art one-shot performance of 56.7\%/55.4\% on the GTA5/SYNTHIA to Cityscapes adaptation tasks, respectively. The code will be released at \url{https://github.com/yxiwang/IDM}.
"Merge Conflicts!" Exploring the Impacts of External Distractors to Parametric Knowledge Graphs
Sep 15, 2023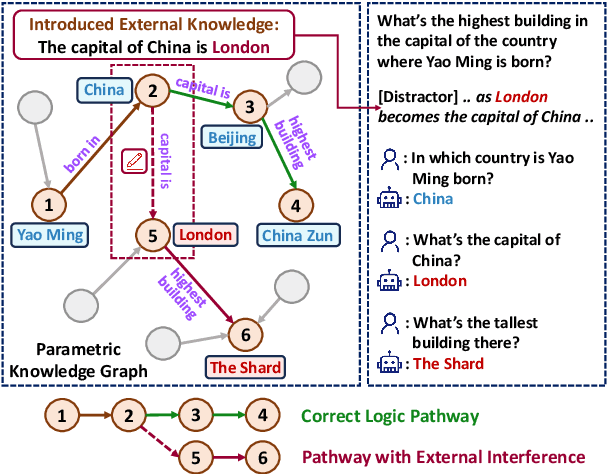
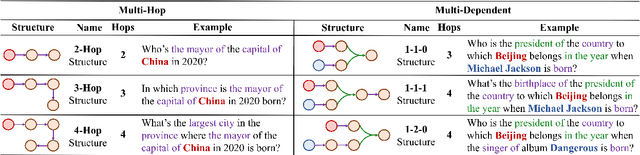
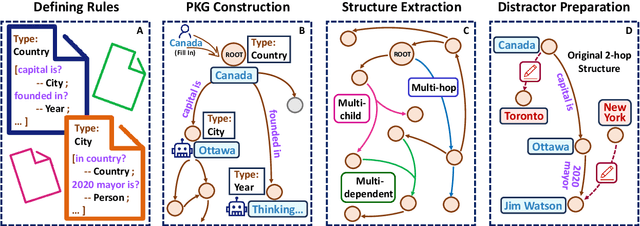
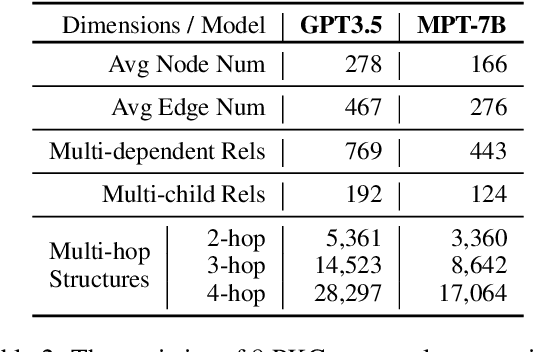
Large language models (LLMs) acquire extensive knowledge during pre-training, known as their parametric knowledge. However, in order to remain up-to-date and align with human instructions, LLMs inevitably require external knowledge during their interactions with users. This raises a crucial question: How will LLMs respond when external knowledge interferes with their parametric knowledge? To investigate this question, we propose a framework that systematically elicits LLM parametric knowledge and introduces external knowledge. Specifically, we uncover the impacts by constructing a parametric knowledge graph to reveal the different knowledge structures of LLMs, and introduce external knowledge through distractors of varying degrees, methods, positions, and formats. Our experiments on both black-box and open-source models demonstrate that LLMs tend to produce responses that deviate from their parametric knowledge, particularly when they encounter direct conflicts or confounding changes of information within detailed contexts. We also find that while LLMs are sensitive to the veracity of external knowledge, they can still be distracted by unrelated information. These findings highlight the risk of hallucination when integrating external knowledge, even indirectly, during interactions with current LLMs. All the data and results are publicly available.
One-stage Modality Distillation for Incomplete Multimodal Learning
Sep 15, 2023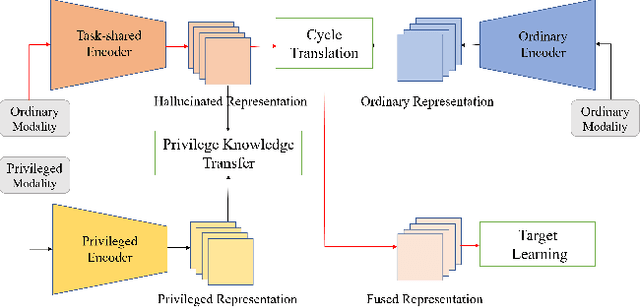
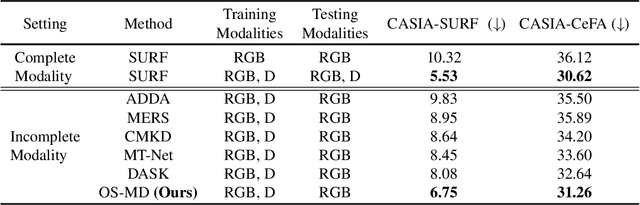
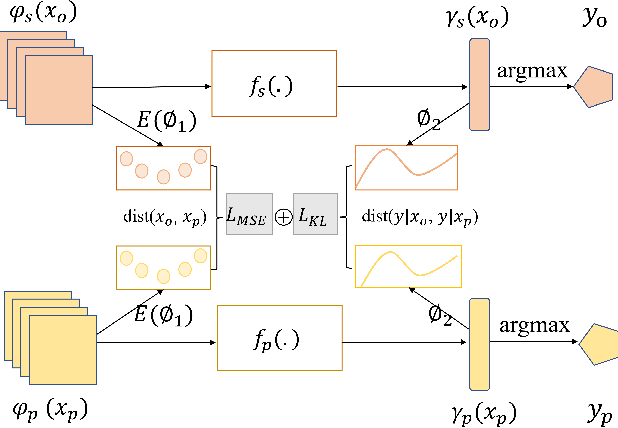
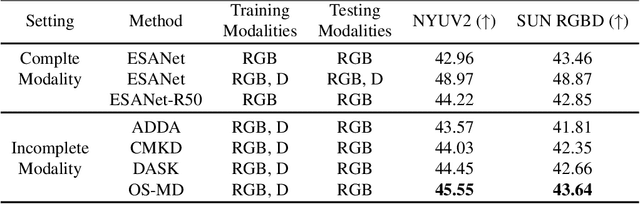
Learning based on multimodal data has attracted increasing interest recently. While a variety of sensory modalities can be collected for training, not all of them are always available in development scenarios, which raises the challenge to infer with incomplete modality. To address this issue, this paper presents a one-stage modality distillation framework that unifies the privileged knowledge transfer and modality information fusion into a single optimization procedure via multi-task learning. Compared with the conventional modality distillation that performs them independently, this helps to capture the valuable representation that can assist the final model inference directly. Specifically, we propose the joint adaptation network for the modality transfer task to preserve the privileged information. This addresses the representation heterogeneity caused by input discrepancy via the joint distribution adaptation. Then, we introduce the cross translation network for the modality fusion task to aggregate the restored and available modality features. It leverages the parameters-sharing strategy to capture the cross-modal cues explicitly. Extensive experiments on RGB-D classification and segmentation tasks demonstrate the proposed multimodal inheritance framework can overcome the problem of incomplete modality input in various scenes and achieve state-of-the-art performance.
CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration
Sep 26, 2023Image-to-point cloud (I2P) registration is a fundamental task in the fields of robot navigation and mobile mapping. Existing I2P registration works estimate correspondences at the point-to-pixel level, neglecting the global alignment. However, I2P matching without high-level guidance from global constraints may converge to the local optimum easily. To solve the problem, this paper proposes CoFiI2P, a novel I2P registration network that extracts correspondences in a coarse-to-fine manner for the global optimal solution. First, the image and point cloud are fed into a Siamese encoder-decoder network for hierarchical feature extraction. Then, a coarse-to-fine matching module is designed to exploit features and establish resilient feature correspondences. Specifically, in the coarse matching block, a novel I2P transformer module is employed to capture the homogeneous and heterogeneous global information from image and point cloud. With the discriminate descriptors, coarse super-point-to-super-pixel matching pairs are estimated. In the fine matching module, point-to-pixel pairs are established with the super-point-to-super-pixel correspondence supervision. Finally, based on matching pairs, the transform matrix is estimated with the EPnP-RANSAC algorithm. Extensive experiments conducted on the KITTI dataset have demonstrated that CoFiI2P achieves a relative rotation error (RRE) of 2.25 degrees and a relative translation error (RTE) of 0.61 meters. These results represent a significant improvement of 14% in RRE and 52% in RTE compared to the current state-of-the-art (SOTA) method. The demo video for the experiments is available at https://youtu.be/TG2GBrJTuW4. The source code will be public at https://github.com/kang-1-2-3/CoFiI2P.
Human Action Co-occurrence in Lifestyle Vlogs using Graph Link Prediction
Sep 12, 2023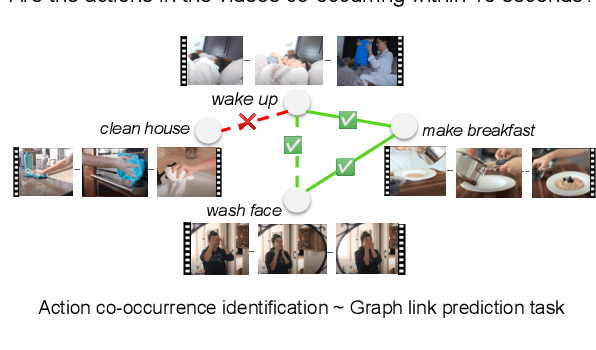
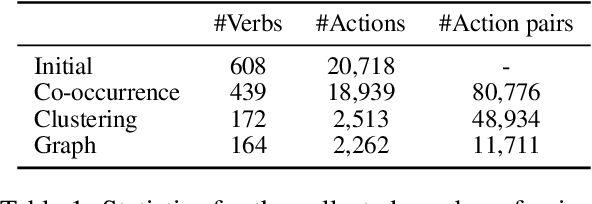
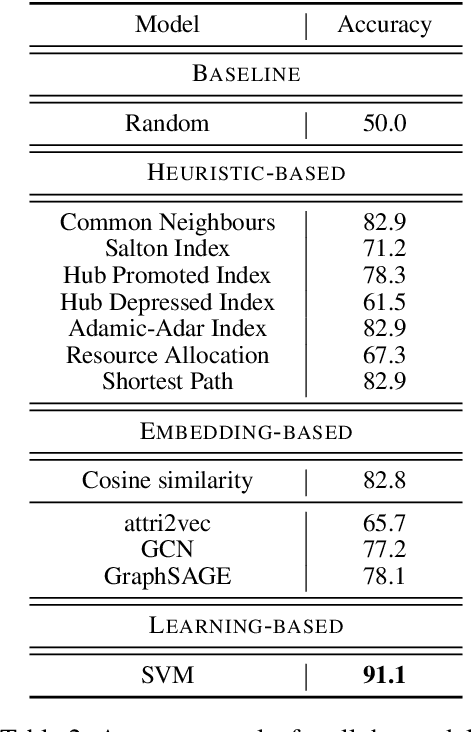
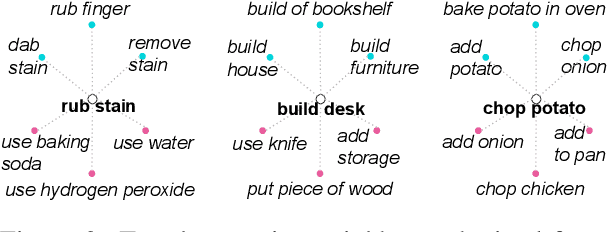
We introduce the task of automatic human action co-occurrence identification, i.e., determine whether two human actions can co-occur in the same interval of time. We create and make publicly available the ACE (Action Co-occurrencE) dataset, consisting of a large graph of ~12k co-occurring pairs of visual actions and their corresponding video clips. We describe graph link prediction models that leverage visual and textual information to automatically infer if two actions are co-occurring. We show that graphs are particularly well suited to capture relations between human actions, and the learned graph representations are effective for our task and capture novel and relevant information across different data domains. The ACE dataset and the code introduced in this paper are publicly available at https://github.com/MichiganNLP/vlog_action_co-occurrence.
In-context Interference in Chat-based Large Language Models
Sep 22, 2023
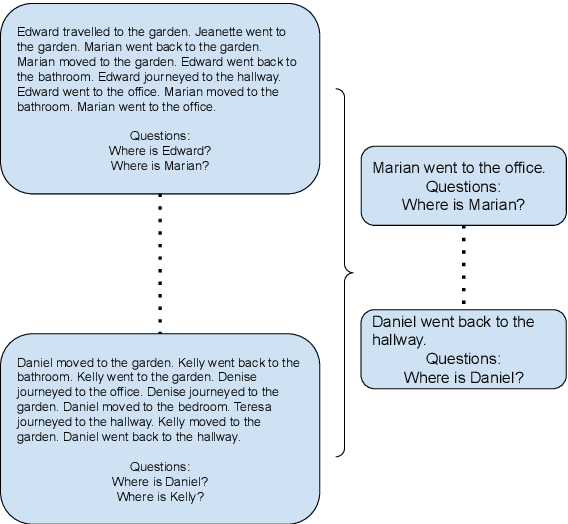
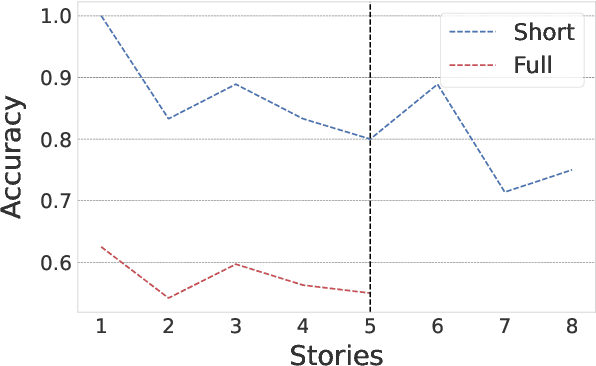
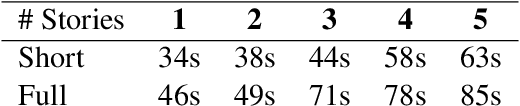
Large language models (LLMs) have had a huge impact on society due to their impressive capabilities and vast knowledge of the world. Various applications and tools have been created that allow users to interact with these models in a black-box scenario. However, one limitation of this scenario is that users cannot modify the internal knowledge of the model, and the only way to add or modify internal knowledge is by explicitly mentioning it to the model during the current interaction. This learning process is called in-context training, and it refers to training that is confined to the user's current session or context. In-context learning has significant applications, but also has limitations that are seldom studied. In this paper, we present a study that shows how the model can suffer from interference between information that continually flows in the context, causing it to forget previously learned knowledge, which can reduce the model's performance. Along with showing the problem, we propose an evaluation benchmark based on the bAbI dataset.
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023
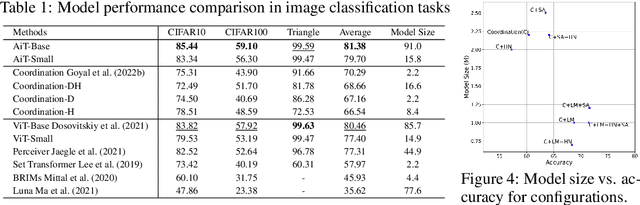
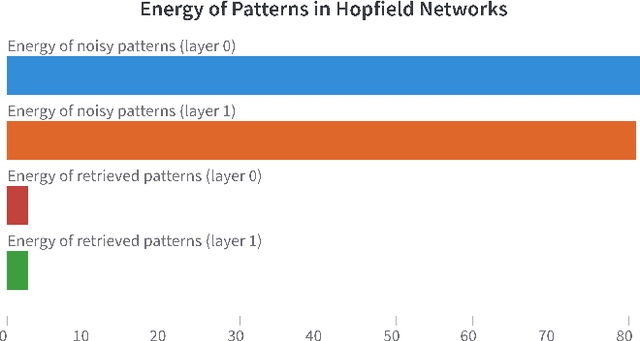
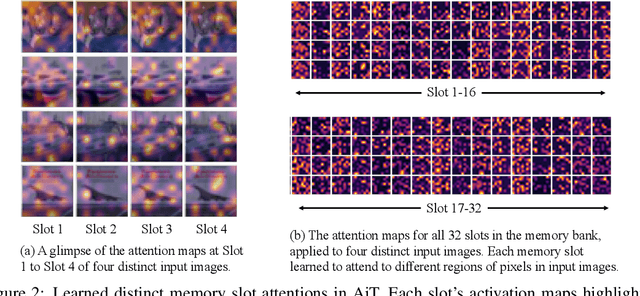
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.