 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generate then Retrieve: Conversational Response Retrieval Using LLMs as Answer and Query Generators
Mar 28, 2024
CIS is a prominent area in IR that focuses on developing interactive knowledge assistants. These systems must adeptly comprehend the user's information requirements within the conversational context and retrieve the relevant information. To this aim, the existing approaches model the user's information needs with one query called rewritten query and use this query for passage retrieval. In this paper, we propose three different methods for generating multiple queries to enhance the retrieval. In these methods, we leverage the capabilities of large language models (LLMs) in understanding the user's information need and generating an appropriate response, to generate multiple queries. We implement and evaluate the proposed models utilizing various LLMs including GPT-4 and Llama-2 chat in zero-shot and few-shot settings. In addition, we propose a new benchmark for TREC iKAT based on gpt 3.5 judgments. Our experiments reveal the effectiveness of our proposed models on the TREC iKAT dataset.
Second-Order Information Matters: Revisiting Machine Unlearning for Large Language Models
Mar 13, 2024
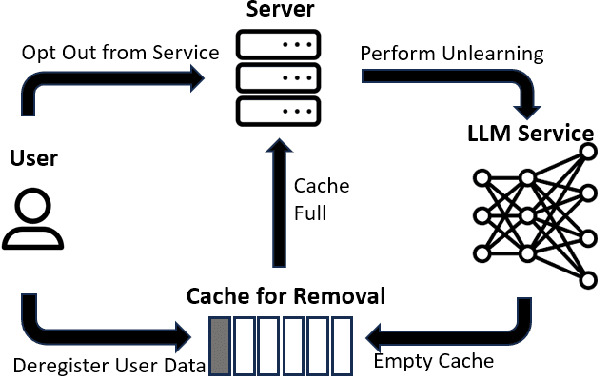
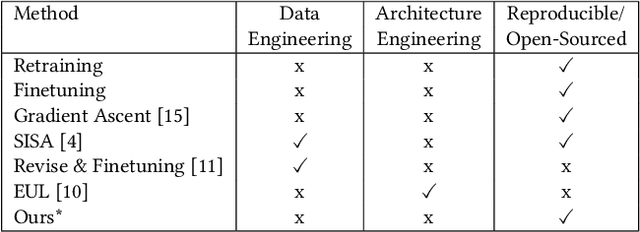
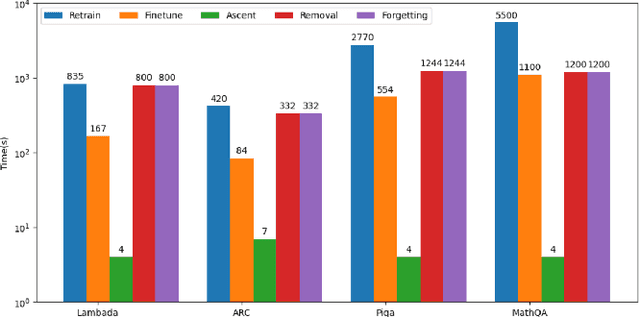
With the rapid development of Large Language Models (LLMs), we have witnessed intense competition among the major LLM products like ChatGPT, LLaMa, and Gemini. However, various issues (e.g. privacy leakage and copyright violation) of the training corpus still remain underexplored. For example, the Times sued OpenAI and Microsoft for infringing on its copyrights by using millions of its articles for training. From the perspective of LLM practitioners, handling such unintended privacy violations can be challenging. Previous work addressed the ``unlearning" problem of LLMs using gradient information, while they mostly introduced significant overheads like data preprocessing or lacked robustness. In this paper, contrasting with the methods based on first-order information, we revisit the unlearning problem via the perspective of second-order information (Hessian). Our unlearning algorithms, which are inspired by classic Newton update, are not only data-agnostic/model-agnostic but also proven to be robust in terms of utility preservation or privacy guarantee. Through a comprehensive evaluation with four NLP datasets as well as a case study on real-world datasets, our methods consistently show superiority over the first-order methods.
Cooperative Communication Based Gradient Coding for Wireless Federated Learning
Mar 31, 2024We investigate wireless federated learning (FL) in the presence of stragglers, where the power-constrained wireless devices collaboratively train a global model on their local datasets %within a time constraint and transmit local model updates through fading channels. To tackle stragglers resulting from link disruptions without requiring accurate prior information on connectivity or dataset sharing, we propose a gradient coding (GC) scheme based on cooperative communication. Subsequently, we conduct an outage analysis of the proposed scheme, based on which we conduct the convergence analysis. The simulation results reveal the superiority of the proposed strategy in the presence of stragglers, especially in low signal-to-noise ratio (SNR) scenarios.
LexAbSumm: Aspect-based Summarization of Legal Decisions
Mar 31, 2024Legal professionals frequently encounter long legal judgments that hold critical insights for their work. While recent advances have led to automated summarization solutions for legal documents, they typically provide generic summaries, which may not meet the diverse information needs of users. To address this gap, we introduce LexAbSumm, a novel dataset designed for aspect-based summarization of legal case decisions, sourced from the European Court of Human Rights jurisdiction. We evaluate several abstractive summarization models tailored for longer documents on LexAbSumm, revealing a challenge in conditioning these models to produce aspect-specific summaries. We release LexAbSum to facilitate research in aspect-based summarization for legal domain.
Ethos: Rectifying Language Models in Orthogonal Parameter Space
Apr 01, 2024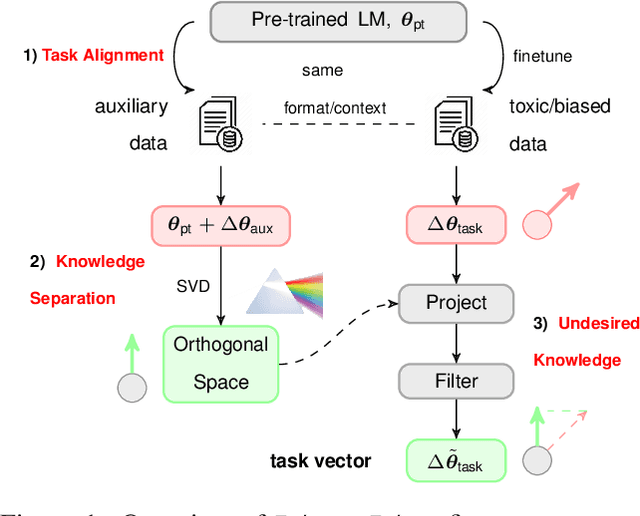
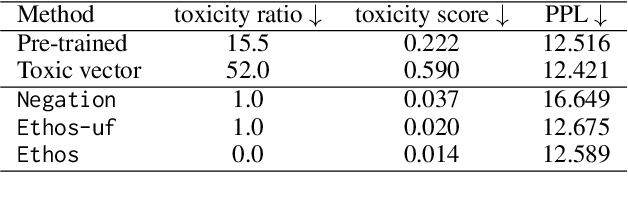
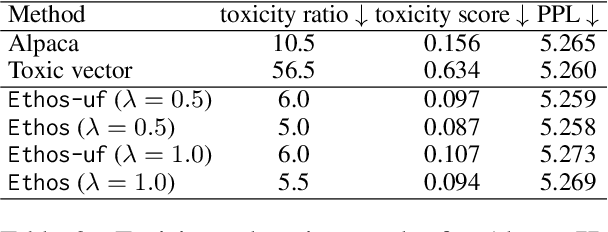
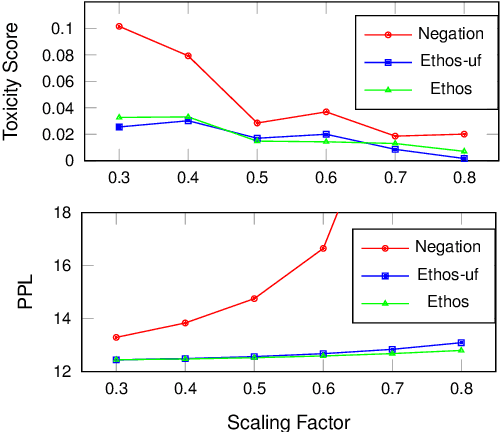
Language models (LMs) have greatly propelled the research on natural language processing. However, LMs also raise concerns regarding the generation of biased or toxic content and the potential disclosure of private information from the training dataset. In this work, we present a new efficient approach, Ethos, that rectifies LMs to mitigate toxicity and bias in outputs and avoid privacy leakage. Ethos is built on task arithmetic. However, unlike current task arithmetic algorithms, Ethos distinguishes general beneficial and undesired knowledge when reconstructing task vectors. Specifically, Ethos first obtains a set of principal components from the pre-trained models using singular value decomposition. Then, by projecting the task vector onto principal components, Ethos identifies the principal components that encode general or undesired knowledge. Ethos performs negating using the task vector with undesired knowledge only, thereby minimizing collateral damage on general model utility. We demonstrate the efficacy of our approach on three different tasks: debiasing, detoxification, and memorization unlearning. Evaluations show Ethos is more effective in removing undesired knowledge and maintaining the overall model performance compared to current task arithmetic methods.
CMT: Cross Modulation Transformer with Hybrid Loss for Pansharpening
Apr 01, 2024Pansharpening aims to enhance remote sensing image (RSI) quality by merging high-resolution panchromatic (PAN) with multispectral (MS) images. However, prior techniques struggled to optimally fuse PAN and MS images for enhanced spatial and spectral information, due to a lack of a systematic framework capable of effectively coordinating their individual strengths. In response, we present the Cross Modulation Transformer (CMT), a pioneering method that modifies the attention mechanism. This approach utilizes a robust modulation technique from signal processing, integrating it into the attention mechanism's calculations. It dynamically tunes the weights of the carrier's value (V) matrix according to the modulator's features, thus resolving historical challenges and achieving a seamless integration of spatial and spectral attributes. Furthermore, considering that RSI exhibits large-scale features and edge details along with local textures, we crafted a hybrid loss function that combines Fourier and wavelet transforms to effectively capture these characteristics, thereby enhancing both spatial and spectral accuracy in pansharpening. Extensive experiments demonstrate our framework's superior performance over existing state-of-the-art methods. The code will be publicly available to encourage further research.
Motion Blur Decomposition with Cross-shutter Guidance
Apr 01, 2024Motion blur is a frequently observed image artifact, especially under insufficient illumination where exposure time has to be prolonged so as to collect more photons for a bright enough image. Rather than simply removing such blurring effects, recent researches have aimed at decomposing a blurry image into multiple sharp images with spatial and temporal coherence. Since motion blur decomposition itself is highly ambiguous, priors from neighbouring frames or human annotation are usually needed for motion disambiguation. In this paper, inspired by the complementary exposure characteristics of a global shutter (GS) camera and a rolling shutter (RS) camera, we propose to utilize the ordered scanline-wise delay in a rolling shutter image to robustify motion decomposition of a single blurry image. To evaluate this novel dual imaging setting, we construct a triaxial system to collect realistic data, as well as a deep network architecture that explicitly addresses temporal and contextual information through reciprocal branches for cross-shutter motion blur decomposition. Experiment results have verified the effectiveness of our proposed algorithm, as well as the validity of our dual imaging setting.
Harnessing Data and Physics for Deep Learning Phase Recovery
Apr 01, 2024Phase recovery, calculating the phase of a light wave from its intensity measurements, is essential for various applications, such as coherent diffraction imaging, adaptive optics, and biomedical imaging. It enables the reconstruction of an object's refractive index distribution or topography as well as the correction of imaging system aberrations. In recent years, deep learning has been proven to be highly effective in addressing phase recovery problems. Two main deep learning phase recovery strategies are data-driven (DD) with supervised learning mode and physics-driven (PD) with self-supervised learning mode. DD and PD achieve the same goal in different ways and lack the necessary study to reveal similarities and differences. Therefore, in this paper, we comprehensively compare these two deep learning phase recovery strategies in terms of time consumption, accuracy, generalization ability, ill-posedness adaptability, and prior capacity. What's more, we propose a co-driven (CD) strategy of combining datasets and physics for the balance of high- and low-frequency information. The codes for DD, PD, and CD are publicly available at https://github.com/kqwang/DLPR.
A Novel Audio Representation for Music Genre Identification in MIR
Apr 01, 2024For Music Information Retrieval downstream tasks, the most common audio representation is time-frequency-based, such as Mel spectrograms. In order to identify musical genres, this study explores the possibilities of a new form of audio representation one of the most usual MIR downstream tasks. Therefore, to discretely encoding music using deep vector quantization; a novel audio representation was created for the innovative generative music model i.e. Jukebox. The effectiveness of Jukebox's audio representation is compared to Mel spectrograms using a dataset that is almost equivalent to State-of-the-Art (SOTA) and an almost same transformer design. The results of this study imply that, at least when the transformers are pretrained using a very modest dataset of 20k tracks, Jukebox's audio representation is not superior to Mel spectrograms. This could be explained by the fact that Jukebox's audio representation does not sufficiently take into account the peculiarities of human hearing perception. On the other hand, Mel spectrograms are specifically created with the human auditory sense in mind.
TM-TREK at SemEval-2024 Task 8: Towards LLM-Based Automatic Boundary Detection for Human-Machine Mixed Text
Apr 01, 2024With the increasing prevalence of text generated by large language models (LLMs), there is a growing concern about distinguishing between LLM-generated and human-written texts in order to prevent the misuse of LLMs, such as the dissemination of misleading information and academic dishonesty. Previous research has primarily focused on classifying text as either entirely human-written or LLM-generated, neglecting the detection of mixed texts that contain both types of content. This paper explores LLMs' ability to identify boundaries in human-written and machine-generated mixed texts. We approach this task by transforming it into a token classification problem and regard the label turning point as the boundary. Notably, our ensemble model of LLMs achieved first place in the 'Human-Machine Mixed Text Detection' sub-task of the SemEval'24 Competition Task 8. Additionally, we investigate factors that influence the capability of LLMs in detecting boundaries within mixed texts, including the incorporation of extra layers on top of LLMs, combination of segmentation loss, and the impact of pretraining. Our findings aim to provide valuable insights for future research in this area.