 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reroute Prediction Service
Oct 13, 2023
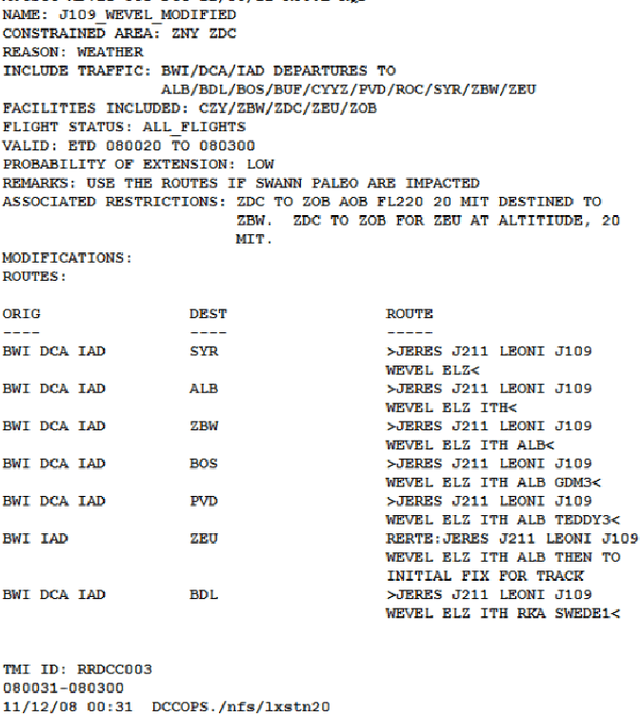
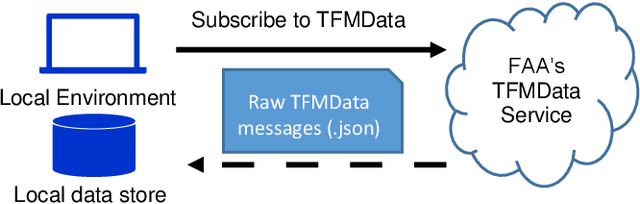
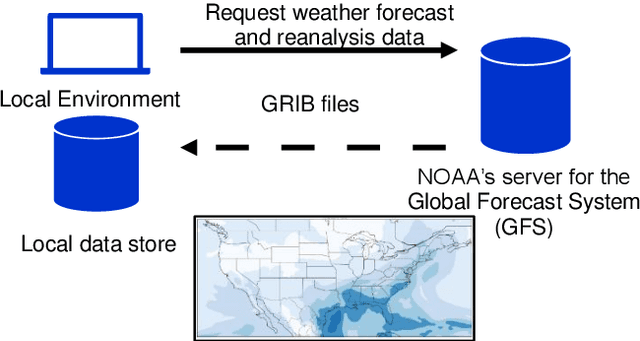
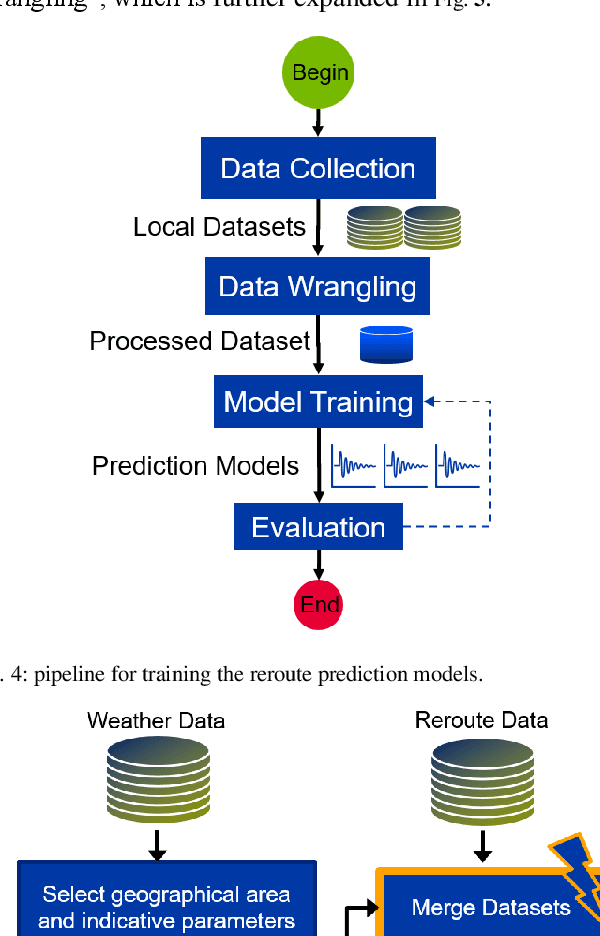
The cost of delays was estimated as 33 billion US dollars only in 2019 for the US National Airspace System, a peak value following a growth trend in past years. Aiming to address this huge inefficiency, we designed and developed a novel Data Analytics and Machine Learning system, which aims at reducing delays by proactively supporting re-routing decisions. Given a time interval up to a few days in the future, the system predicts if a reroute advisory for a certain Air Route Traffic Control Center or for a certain advisory identifier will be issued, which may impact the pertinent routes. To deliver such predictions, the system uses historical reroute data, collected from the System Wide Information Management (SWIM) data services provided by the FAA, and weather data, provided by the US National Centers for Environmental Prediction (NCEP). The data is huge in volume, and has many items streamed at high velocity, uncorrelated and noisy. The system continuously processes the incoming raw data and makes it available for the next step where an interim data store is created and adaptively maintained for efficient query processing. The resulting data is fed into an array of ML algorithms, which compete for higher accuracy. The best performing algorithm is used in the final prediction, generating the final results. Mean accuracy values higher than 90% were obtained in our experiments with this system. Our algorithm divides the area of interest in units of aggregation and uses temporal series of the aggregate measures of weather forecast parameters in each geographical unit, in order to detect correlations with reroutes and where they will most likely occur. Aiming at practical application, the system is formed by a number of microservices, which are deployed in the cloud, making the system distributed, scalable and highly available.
Point Neighborhood Embeddings
Oct 03, 2023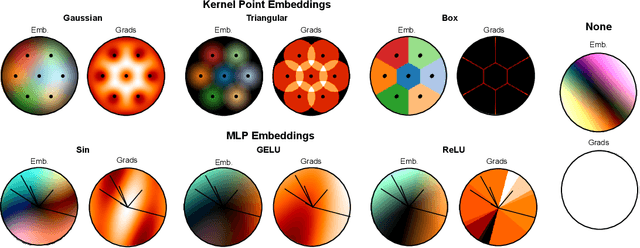
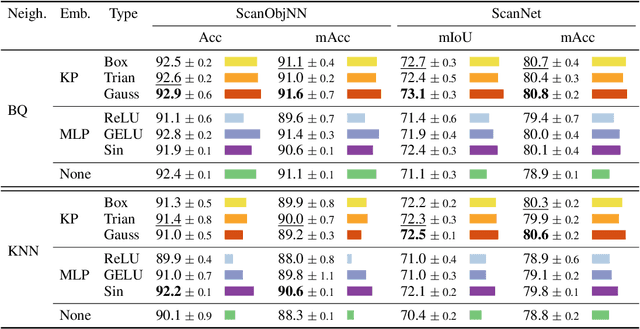
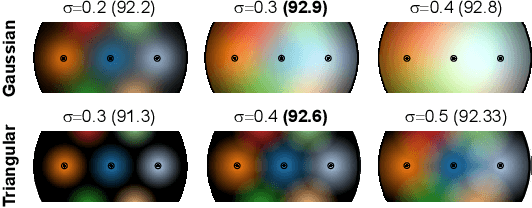
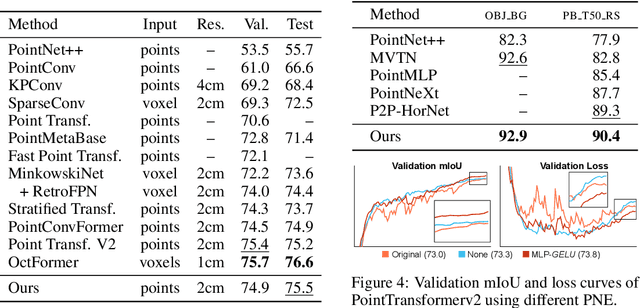
Point convolution operations rely on different embedding mechanisms to encode the neighborhood information of each point in order to detect patterns in 3D space. However, as convolutions are usually evaluated as a whole, not much work has been done to investigate which is the ideal mechanism to encode such neighborhood information. In this paper, we provide the first extensive study that analyzes such Point Neighborhood Embeddings (PNE) alone in a controlled experimental setup. From our experiments, we derive a set of recommendations for PNE that can help to improve future designs of neural network architectures for point clouds. Our most surprising finding shows that the most commonly used embedding based on a Multi-layer Perceptron (MLP) with ReLU activation functions provides the lowest performance among all embeddings, even being surpassed on some tasks by a simple linear combination of the point coordinates. Additionally, we show that a neural network architecture using simple convolutions based on such embeddings is able to achieve state-of-the-art results on several tasks, outperforming recent and more complex operations. Lastly, we show that these findings extrapolate to other more complex convolution operations, where we show how following our recommendations we are able to improve recent state-of-the-art architectures.
GraphControl: Adding Conditional Control to Universal Graph Pre-trained Models for Graph Domain Transfer Learning
Oct 12, 2023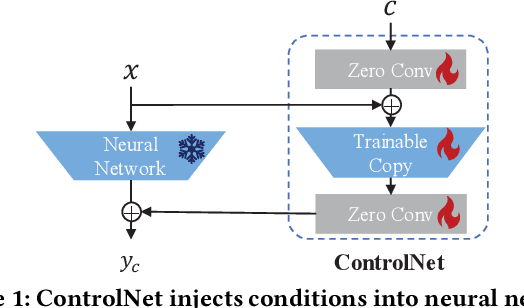
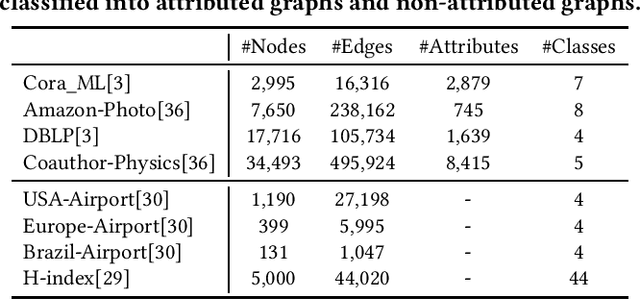
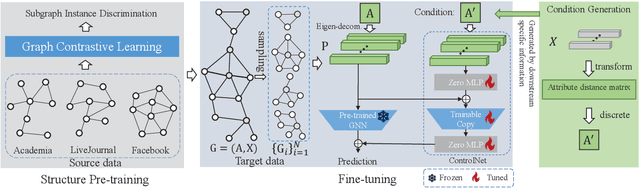
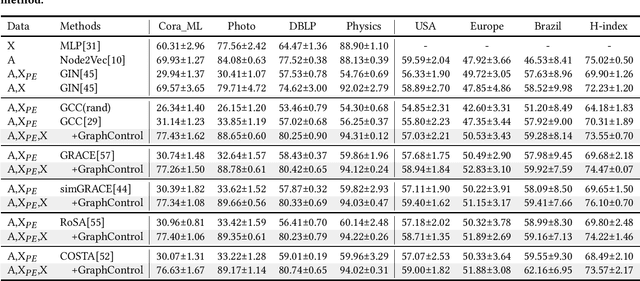
Graph-structured data is ubiquitous in the world which models complex relationships between objects, enabling various Web applications. Daily influxes of unlabeled graph data on the Web offer immense potential for these applications. Graph self-supervised algorithms have achieved significant success in acquiring generic knowledge from abundant unlabeled graph data. These pre-trained models can be applied to various downstream Web applications, saving training time and improving downstream (target) performance. However, different graphs, even across seemingly similar domains, can differ significantly in terms of attribute semantics, posing difficulties, if not infeasibility, for transferring the pre-trained models to downstream tasks. Concretely speaking, for example, the additional task-specific node information in downstream tasks (specificity) is usually deliberately omitted so that the pre-trained representation (transferability) can be leveraged. The trade-off as such is termed as "transferability-specificity dilemma" in this work. To address this challenge, we introduce an innovative deployment module coined as GraphControl, motivated by ControlNet, to realize better graph domain transfer learning. Specifically, by leveraging universal structural pre-trained models and GraphControl, we align the input space across various graphs and incorporate unique characteristics of target data as conditional inputs. These conditions will be progressively integrated into the model during fine-tuning or prompt tuning through ControlNet, facilitating personalized deployment. Extensive experiments show that our method significantly enhances the adaptability of pre-trained models on target attributed datasets, achieving 1.4-3x performance gain. Furthermore, it outperforms training-from-scratch methods on target data with a comparable margin and exhibits faster convergence.
An Analysis on Large Language Models in Healthcare: A Case Study of BioBERT
Oct 12, 2023
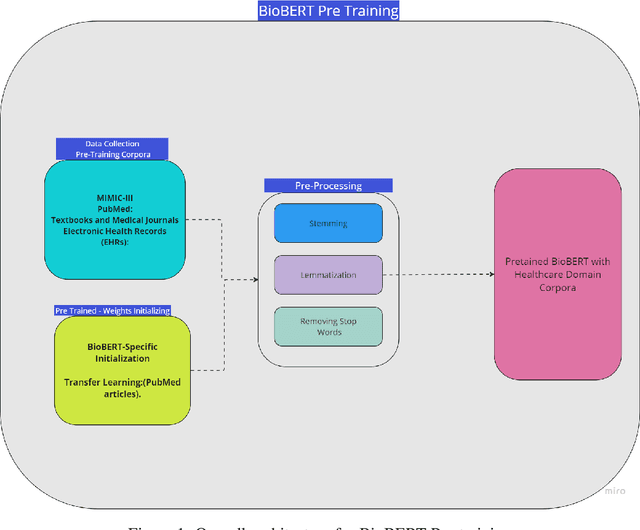
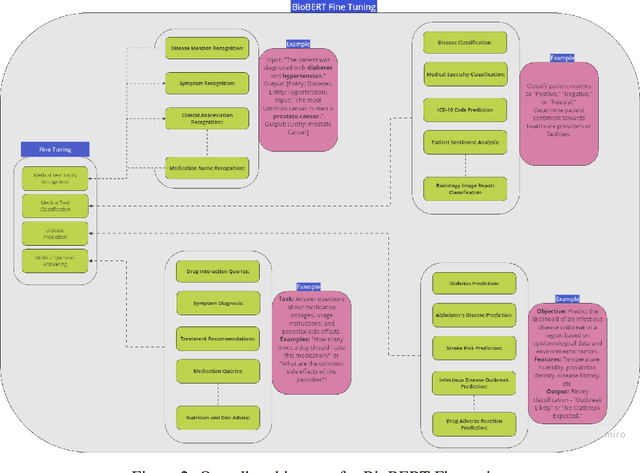
This paper conducts a comprehensive investigation into applying large language models, particularly on BioBERT, in healthcare. It begins with thoroughly examining previous natural language processing (NLP) approaches in healthcare, shedding light on the limitations and challenges these methods face. Following that, this research explores the path that led to the incorporation of BioBERT into healthcare applications, highlighting its suitability for addressing the specific requirements of tasks related to biomedical text mining. The analysis outlines a systematic methodology for fine-tuning BioBERT to meet the unique needs of the healthcare domain. This approach includes various components, including the gathering of data from a wide range of healthcare sources, data annotation for tasks like identifying medical entities and categorizing them, and the application of specialized preprocessing techniques tailored to handle the complexities found in biomedical texts. Additionally, the paper covers aspects related to model evaluation, with a focus on healthcare benchmarks and functions like processing of natural language in biomedical, question-answering, clinical document classification, and medical entity recognition. It explores techniques to improve the model's interpretability and validates its performance compared to existing healthcare-focused language models. The paper thoroughly examines ethical considerations, particularly patient privacy and data security. It highlights the benefits of incorporating BioBERT into healthcare contexts, including enhanced clinical decision support and more efficient information retrieval. Nevertheless, it acknowledges the impediments and complexities of this integration, encompassing concerns regarding data privacy, transparency, resource-intensive requirements, and the necessity for model customization to align with diverse healthcare domains.
Open-Set Knowledge-Based Visual Question Answering with Inference Paths
Oct 12, 2023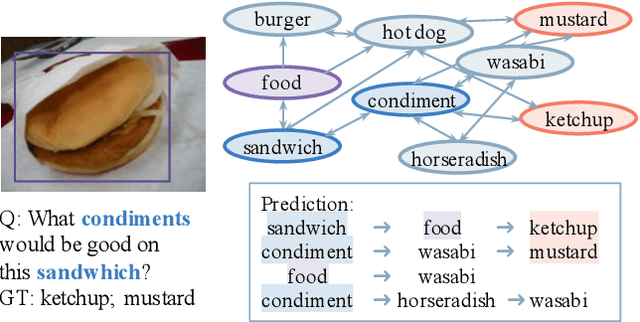
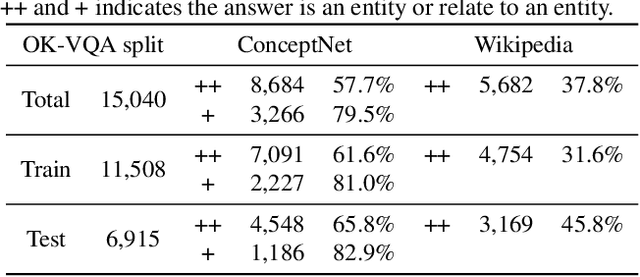
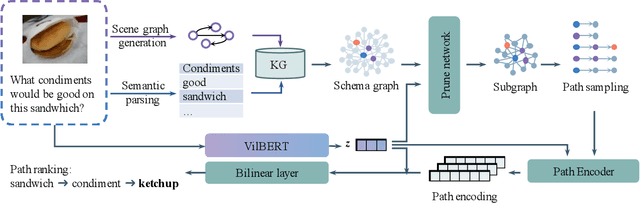
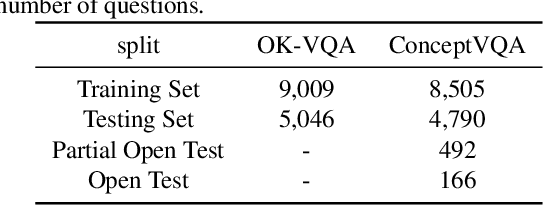
Given an image and an associated textual question, the purpose of Knowledge-Based Visual Question Answering (KB-VQA) is to provide a correct answer to the question with the aid of external knowledge bases. Prior KB-VQA models are usually formulated as a retriever-classifier framework, where a pre-trained retriever extracts textual or visual information from knowledge graphs and then makes a prediction among the candidates. Despite promising progress, there are two drawbacks with existing models. Firstly, modeling question-answering as multi-class classification limits the answer space to a preset corpus and lacks the ability of flexible reasoning. Secondly, the classifier merely consider "what is the answer" without "how to get the answer", which cannot ground the answer to explicit reasoning paths. In this paper, we confront the challenge of \emph{explainable open-set} KB-VQA, where the system is required to answer questions with entities at wild and retain an explainable reasoning path. To resolve the aforementioned issues, we propose a new retriever-ranker paradigm of KB-VQA, Graph pATH rankER (GATHER for brevity). Specifically, it contains graph constructing, pruning, and path-level ranking, which not only retrieves accurate answers but also provides inference paths that explain the reasoning process. To comprehensively evaluate our model, we reformulate the benchmark dataset OK-VQA with manually corrected entity-level annotations and release it as ConceptVQA. Extensive experiments on real-world questions demonstrate that our framework is not only able to perform open-set question answering across the whole knowledge base but provide explicit reasoning path.
Incorporating Domain Knowledge Graph into Multimodal Movie Genre Classification with Self-Supervised Attention and Contrastive Learning
Oct 12, 2023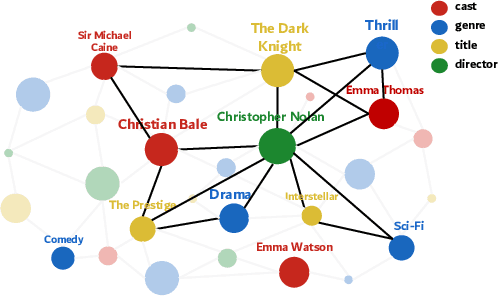
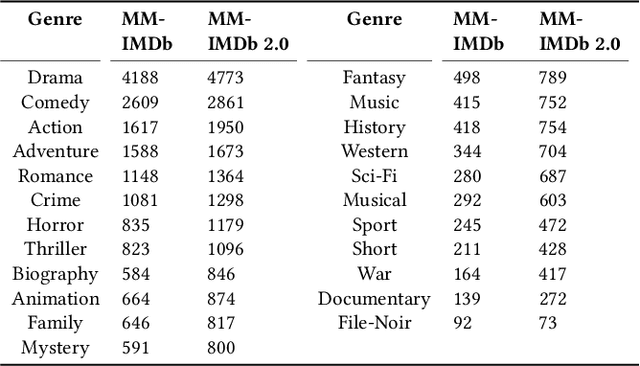
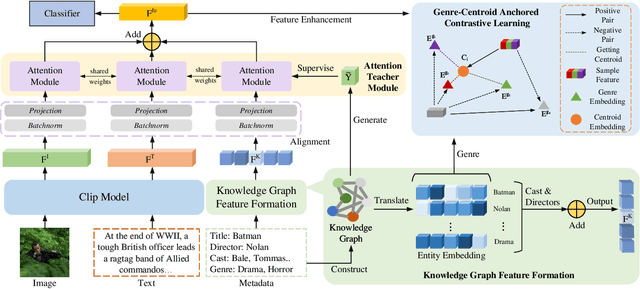
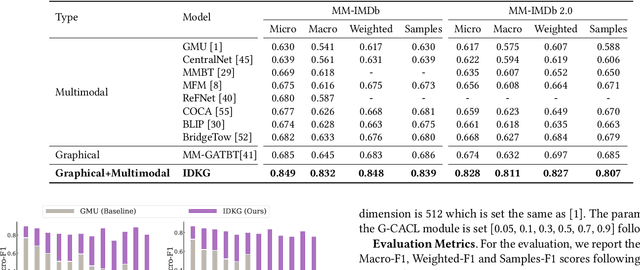
Multimodal movie genre classification has always been regarded as a demanding multi-label classification task due to the diversity of multimodal data such as posters, plot summaries, trailers and metadata. Although existing works have made great progress in modeling and combining each modality, they still face three issues: 1) unutilized group relations in metadata, 2) unreliable attention allocation, and 3) indiscriminative fused features. Given that the knowledge graph has been proven to contain rich information, we present a novel framework that exploits the knowledge graph from various perspectives to address the above problems. As a preparation, the metadata is processed into a domain knowledge graph. A translate model for knowledge graph embedding is adopted to capture the relations between entities. Firstly we retrieve the relevant embedding from the knowledge graph by utilizing group relations in metadata and then integrate it with other modalities. Next, we introduce an Attention Teacher module for reliable attention allocation based on self-supervised learning. It learns the distribution of the knowledge graph and produces rational attention weights. Finally, a Genre-Centroid Anchored Contrastive Learning module is proposed to strengthen the discriminative ability of fused features. The embedding space of anchors is initialized from the genre entities in the knowledge graph. To verify the effectiveness of our framework, we collect a larger and more challenging dataset named MM-IMDb 2.0 compared with the MM-IMDb dataset. The experimental results on two datasets demonstrate that our model is superior to the state-of-the-art methods. We will release the code in the near future.
SplitBeam: Effective and Efficient Beamforming in Wi-Fi Networks Through Split Computing
Oct 12, 2023Modern IEEE 802.11 (Wi-Fi) networks extensively rely on multiple-input multiple-output (MIMO) to significantly improve throughput. To correctly beamform MIMO transmissions, the access point needs to frequently acquire a beamforming matrix (BM) from each connected station. However, the size of the matrix grows with the number of antennas and subcarriers, resulting in an increasing amount of airtime overhead and computational load at the station. Conventional approaches come with either excessive computational load or loss of beamforming precision. For this reason, we propose SplitBeam, a new framework where we train a split deep neural network (DNN) to directly output the BM given the channel state information (CSI) matrix as input. We formulate and solve a bottleneck optimization problem (BOP) to keep computation, airtime overhead, and bit error rate (BER) below application requirements. We perform extensive experimental CSI collection with off-the-shelf Wi-Fi devices in two distinct environments and compare the performance of SplitBeam with the standard IEEE 802.11 algorithm for BM feedback and the state-of-the-art DNN-based approach LB-SciFi. Our experimental results show that SplitBeam reduces the beamforming feedback size and computational complexity by respectively up to 81% and 84% while maintaining BER within about 10^-3 of existing approaches. We also implement the SplitBeam DNNs on FPGA hardware to estimate the end-to-end BM reporting delay, and show that the latter is less than 10 milliseconds in the most complex scenario, which is the target channel sounding frequency in realistic multi-user MIMO scenarios.
Unleash Data Generation for Efficient and Effective Data-free Knowledge Distillation
Sep 30, 2023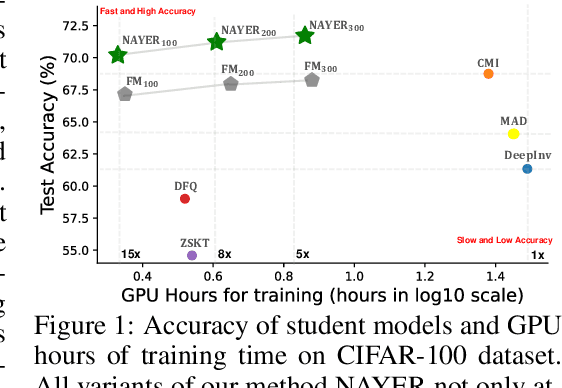
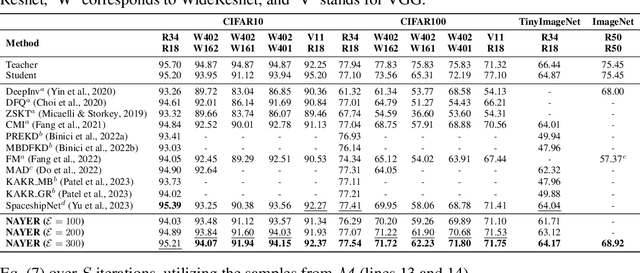
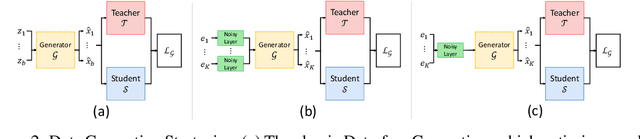
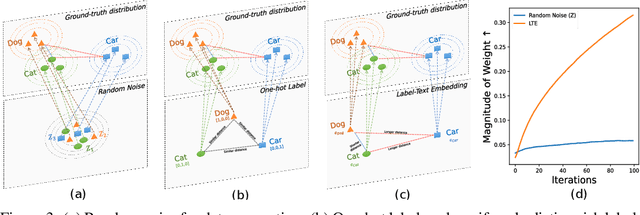
Data-Free Knowledge Distillation (DFKD) has recently made remarkable advancements with its core principle of transferring knowledge from a teacher neural network to a student neural network without requiring access to the original data. Nonetheless, existing approaches encounter a significant challenge when attempting to generate samples from random noise inputs, which inherently lack meaningful information. Consequently, these models struggle to effectively map this noise to the ground-truth sample distribution, resulting in the production of low-quality data and imposing substantial time requirements for training the generator. In this paper, we propose a novel Noisy Layer Generation method (NAYER) which relocates the randomness source from the input to a noisy layer and utilizes the meaningful label-text embedding (LTE) as the input. The significance of LTE lies in its ability to contain substantial meaningful inter-class information, enabling the generation of high-quality samples with only a few training steps. Simultaneously, the noisy layer plays a key role in addressing the issue of diversity in sample generation by preventing the model from overemphasizing the constrained label information. By reinitializing the noisy layer in each iteration, we aim to facilitate the generation of diverse samples while still retaining the method's efficiency, thanks to the ease of learning provided by LTE. Experiments carried out on multiple datasets demonstrate that our NAYER not only outperforms the state-of-the-art methods but also achieves speeds 5 to 15 times faster than previous approaches.
SemST: Semantically Consistent Multi-Scale Image Translation via Structure-Texture Alignment
Oct 08, 2023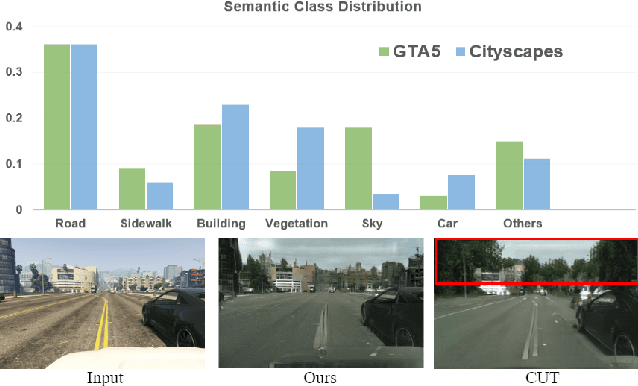
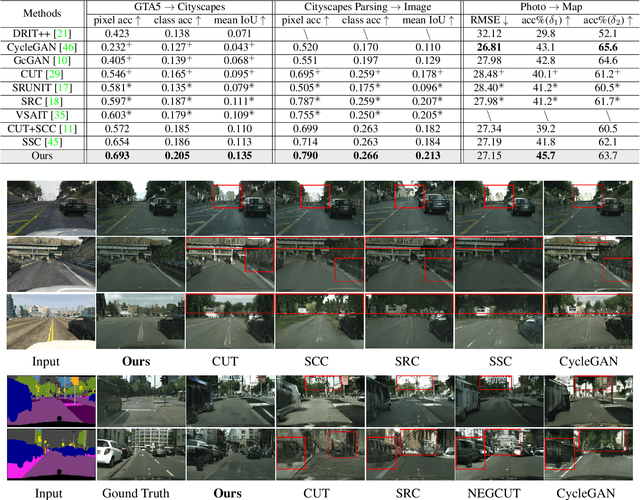
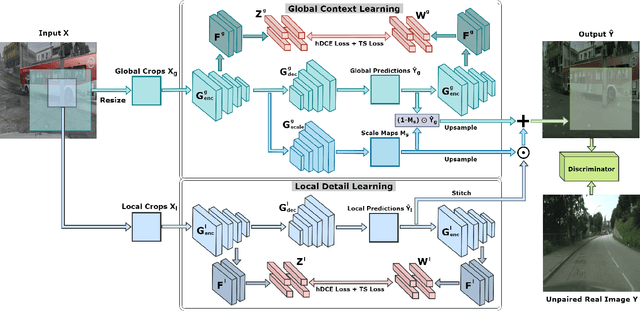
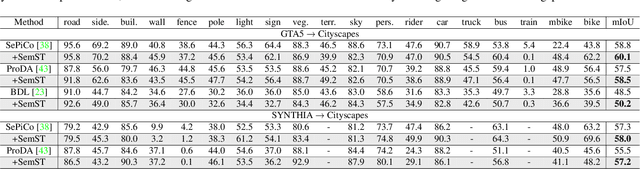
Unsupervised image-to-image (I2I) translation learns cross-domain image mapping that transfers input from the source domain to output in the target domain while preserving its semantics. One challenge is that different semantic statistics in source and target domains result in content discrepancy known as semantic distortion. To address this problem, a novel I2I method that maintains semantic consistency in translation is proposed and named SemST in this work. SemST reduces semantic distortion by employing contrastive learning and aligning the structural and textural properties of input and output by maximizing their mutual information. Furthermore, a multi-scale approach is introduced to enhance translation performance, thereby enabling the applicability of SemST to domain adaptation in high-resolution images. Experiments show that SemST effectively mitigates semantic distortion and achieves state-of-the-art performance. Also, the application of SemST to domain adaptation (DA) is explored. It is demonstrated by preliminary experiments that SemST can be utilized as a beneficial pre-training for the semantic segmentation task.
Improving Reliable Navigation under Uncertainty via Predictions Informed by Non-Local Information
Jul 26, 2023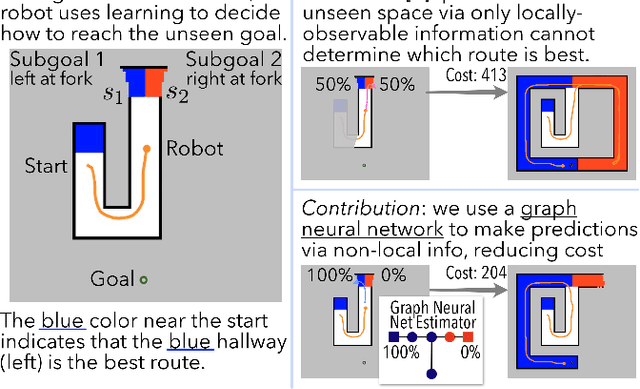
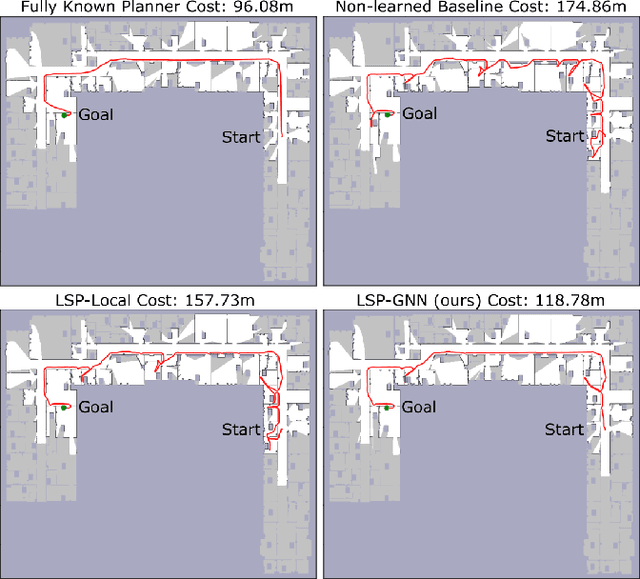
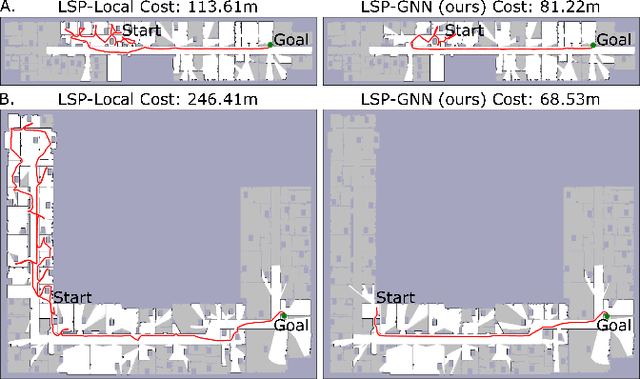
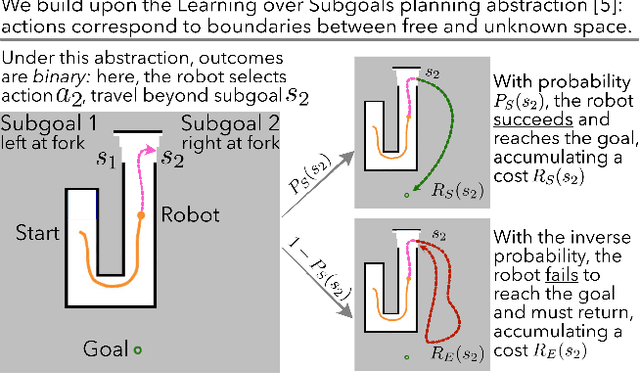
We improve reliable, long-horizon, goal-directed navigation in partially-mapped environments by using non-locally available information to predict the goodness of temporally-extended actions that enter unseen space. Making predictions about where to navigate in general requires non-local information: any observations the robot has seen so far may provide information about the goodness of a particular direction of travel. Building on recent work in learning-augmented model-based planning under uncertainty, we present an approach that can both rely on non-local information to make predictions (via a graph neural network) and is reliable by design: it will always reach its goal, even when learning does not provide accurate predictions. We conduct experiments in three simulated environments in which non-local information is needed to perform well. In our large scale university building environment, generated from real-world floorplans to the scale, we demonstrate a 9.3\% reduction in cost-to-go compared to a non-learned baseline and a 14.9\% reduction compared to a learning-informed planner that can only use local information to inform its predictions.