 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Branched Deep Convolutional Network for Forecasting the Occurrence of Hazes in Paris using Meteorological Maps with Different Characteristic Spatial Scales
Oct 16, 2023
A deep learning platform has been developed to forecast the occurrence of the low visibility events or hazes. It is trained by using multi-decadal daily regional maps of various meteorological and hydrological variables as input features and surface visibility observations as the targets. To better preserve the characteristic spatial information of different input features for training, two branched architectures have recently been developed for the case of Paris hazes. These new architectures have improved the performance of the network, producing reasonable scores in both validation and a blind forecasting evaluation using the data of 2021 and 2022 that have not been used in the training and validation.
Image Super-resolution Via Latent Diffusion: A Sampling-space Mixture Of Experts And Frequency-augmented Decoder Approach
Oct 20, 2023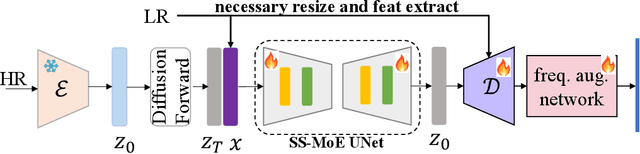

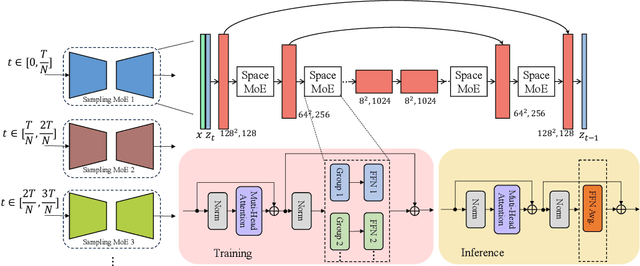
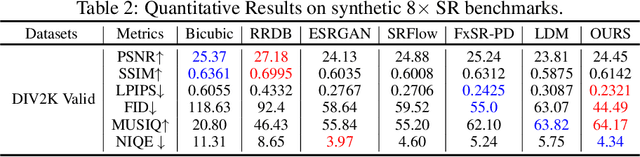
The recent use of diffusion prior, enhanced by pre-trained text-image models, has markedly elevated the performance of image super-resolution (SR). To alleviate the huge computational cost required by pixel-based diffusion SR, latent-based methods utilize a feature encoder to transform the image and then implement the SR image generation in a compact latent space. Nevertheless, there are two major issues that limit the performance of latent-based diffusion. First, the compression of latent space usually causes reconstruction distortion. Second, huge computational cost constrains the parameter scale of the diffusion model. To counteract these issues, we first propose a frequency compensation module that enhances the frequency components from latent space to pixel space. The reconstruction distortion (especially for high-frequency information) can be significantly decreased. Then, we propose to use Sample-Space Mixture of Experts (SS-MoE) to achieve more powerful latent-based SR, which steadily improves the capacity of the model without a significant increase in inference costs. These carefully crafted designs contribute to performance improvements in largely explored 4x blind super-resolution benchmarks and extend to large magnification factors, i.e., 8x image SR benchmarks. The code is available at https://github.com/amandaluof/moe_sr.
SEER : A Knapsack approach to Exemplar Selection for In-Context HybridQA
Oct 20, 2023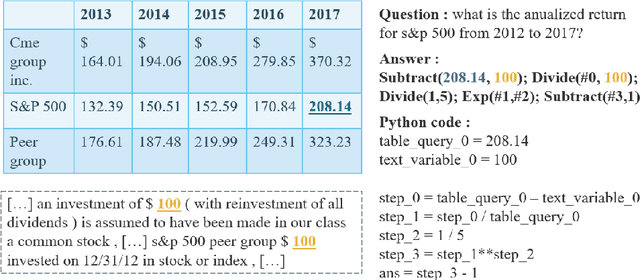
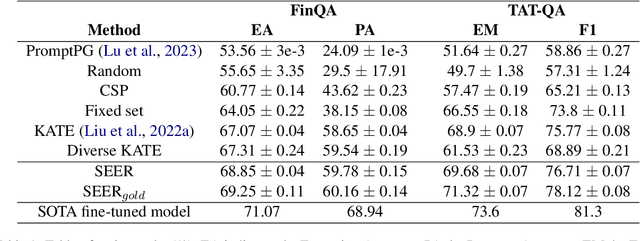
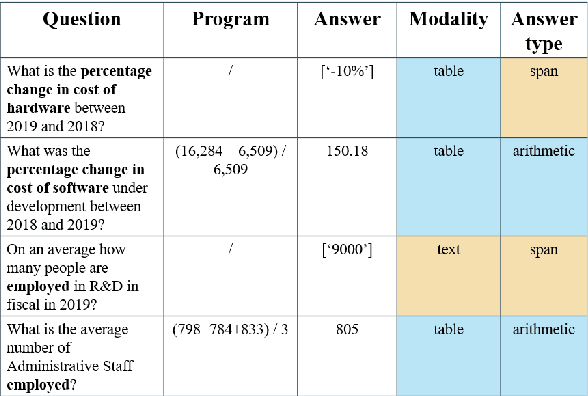
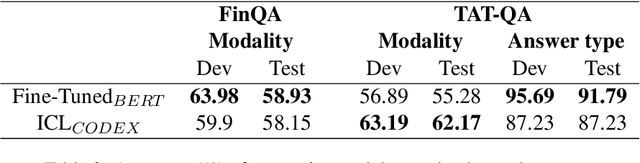
Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.
POSQA: Probe the World Models of LLMs with Size Comparisons
Oct 20, 2023Embodied language comprehension emphasizes that language understanding is not solely a matter of mental processing in the brain but also involves interactions with the physical and social environment. With the explosive growth of Large Language Models (LLMs) and their already ubiquitous presence in our daily lives, it is becoming increasingly necessary to verify their real-world understanding. Inspired by cognitive theories, we propose POSQA: a Physical Object Size Question Answering dataset with simple size comparison questions to examine the extremity and analyze the potential mechanisms of the embodied comprehension of the latest LLMs. We show that even the largest LLMs today perform poorly under the zero-shot setting. We then push their limits with advanced prompting techniques and external knowledge augmentation. Furthermore, we investigate whether their real-world comprehension primarily derives from contextual information or internal weights and analyse the impact of prompt formats and report bias of different objects. Our results show that real-world understanding that LLMs shaped from textual data can be vulnerable to deception and confusion by the surface form of prompts, which makes it less aligned with human behaviours.
FLAIR: a Country-Scale Land Cover Semantic Segmentation Dataset From Multi-Source Optical Imagery
Oct 20, 2023We introduce the French Land cover from Aerospace ImageRy (FLAIR), an extensive dataset from the French National Institute of Geographical and Forest Information (IGN) that provides a unique and rich resource for large-scale geospatial analysis. FLAIR contains high-resolution aerial imagery with a ground sample distance of 20 cm and over 20 billion individually labeled pixels for precise land-cover classification. The dataset also integrates temporal and spectral data from optical satellite time series. FLAIR thus combines data with varying spatial, spectral, and temporal resolutions across over 817 km2 of acquisitions representing the full landscape diversity of France. This diversity makes FLAIR a valuable resource for the development and evaluation of novel methods for large-scale land-cover semantic segmentation and raises significant challenges in terms of computer vision, data fusion, and geospatial analysis. We also provide powerful uni- and multi-sensor baseline models that can be employed to assess algorithm's performance and for downstream applications. Through its extent and the quality of its annotation, FLAIR aims to spur improvements in monitoring and understanding key anthropogenic development indicators such as urban growth, deforestation, and soil artificialization. Dataset and codes can be accessed at https://ignf.github.io/FLAIR/
A Study of Fitness Gains in Evolving Finite State Machines
Oct 20, 2023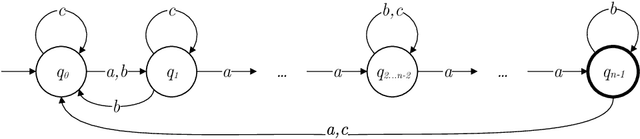
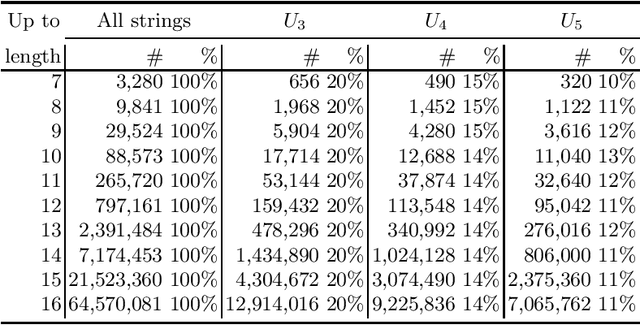
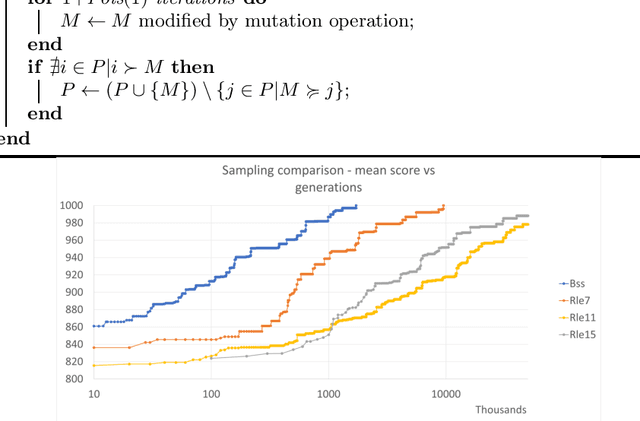
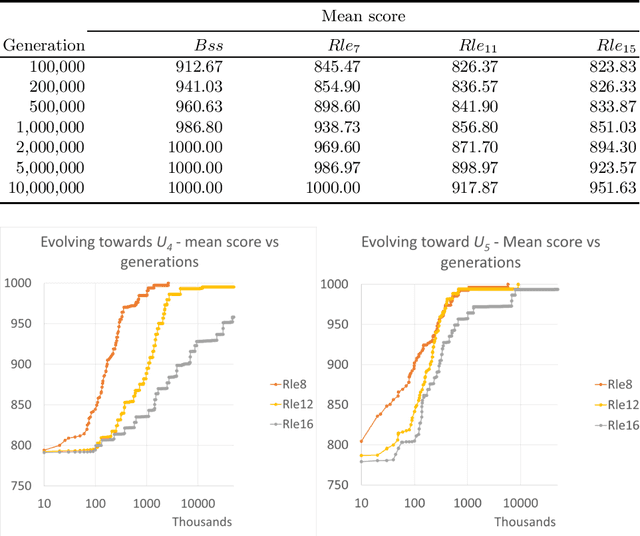
Among the wide variety of evolutionary computing models, Finite State Machines (FSMs) have several attractions for fundamental research. They are easy to understand in concept and can be visualised clearly in simple cases. They have a ready fitness criterion through their relationship with Regular Languages. They have also been shown to be tractably evolvable, even up to exhibiting evidence of open-ended evolution in specific scenarios. In addition to theoretical attraction, they also have industrial applications, as a paradigm of both automated and user-initiated control. Improving the understanding of the factors affecting FSM evolution has relevance to both computer science and practical optimisation of control. We investigate an evolutionary scenario of FSMs adapting to recognise one of a family of Regular Languages by categorising positive and negative samples, while also being under a counteracting selection pressure that favours fewer states. The results appear to indicate that longer strings provided as samples reduce the speed of fitness gain, when fitness is measured against a fixed number of sample strings. We draw the inference that additional information from longer strings is not sufficient to compensate for sparser coverage of the combinatorial space of positive and negative sample strings.
A Sparse Bayesian Learning for Diagnosis of Nonstationary and Spatially Correlated Faults with Application to Multistation Assembly Systems
Oct 20, 2023Sensor technology developments provide a basis for effective fault diagnosis in manufacturing systems. However, the limited number of sensors due to physical constraints or undue costs hinders the accurate diagnosis in the actual process. In addition, time-varying operational conditions that generate nonstationary process faults and the correlation information in the process require to consider for accurate fault diagnosis in the manufacturing systems. This article proposes a novel fault diagnosis method: clustering spatially correlated sparse Bayesian learning (CSSBL), and explicitly demonstrates its applicability in a multistation assembly system that is vulnerable to the above challenges. Specifically, the method is based on a practical assumption that it will likely have a few process faults (sparse). In addition, the hierarchical structure of CSSBL has several parameterized prior distributions to address the above challenges. As posterior distributions of process faults do not have closed form, this paper derives approximate posterior distributions through Variational Bayes inference. The proposed method's efficacy is provided through numerical and real-world case studies utilizing an actual autobody assembly system. The generalizability of the proposed method allows the technique to be applied in fault diagnosis in other domains, including communication and healthcare systems.
Analysis of Weather and Time Features in Machine Learning-aided ERCOT Load Forecasting
Oct 13, 2023Accurate load forecasting is critical for efficient and reliable operations of the electric power system. A large part of electricity consumption is affected by weather conditions, making weather information an important determinant of electricity usage. Personal appliances and industry equipment also contribute significantly to electricity demand with temporal patterns, making time a useful factor to consider in load forecasting. This work develops several machine learning (ML) models that take various time and weather information as part of the input features to predict the short-term system-wide total load. Ablation studies were also performed to investigate and compare the impacts of different weather factors on the prediction accuracy. Actual load and historical weather data for the same region were processed and then used to train the ML models. It is interesting to observe that using all available features, each of which may be correlated to the load, is unlikely to achieve the best forecasting performance; features with redundancy may even decrease the inference capabilities of ML models. This indicates the importance of feature selection for ML models. Overall, case studies demonstrated the effectiveness of ML models trained with different weather and time input features for ERCOT load forecasting.
SpVOS: Efficient Video Object Segmentation with Triple Sparse Convolution
Oct 23, 2023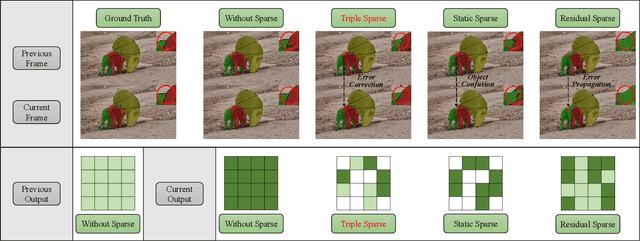
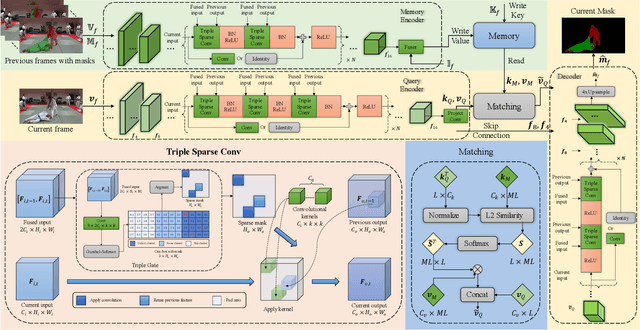
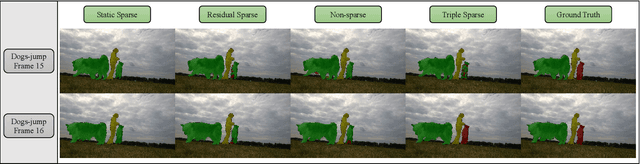

Semi-supervised video object segmentation (Semi-VOS), which requires only annotating the first frame of a video to segment future frames, has received increased attention recently. Among existing pipelines, the memory-matching-based one is becoming the main research stream, as it can fully utilize the temporal sequence information to obtain high-quality segmentation results. Even though this type of method has achieved promising performance, the overall framework still suffers from heavy computation overhead, mainly caused by the per-frame dense convolution operations between high-resolution feature maps and each kernel filter. Therefore, we propose a sparse baseline of VOS named SpVOS in this work, which develops a novel triple sparse convolution to reduce the computation costs of the overall VOS framework. The designed triple gate, taking full consideration of both spatial and temporal redundancy between adjacent video frames, adaptively makes a triple decision to decide how to apply the sparse convolution on each pixel to control the computation overhead of each layer, while maintaining sufficient discrimination capability to distinguish similar objects and avoid error accumulation. A mixed sparse training strategy, coupled with a designed objective considering the sparsity constraint, is also developed to balance the VOS segmentation performance and computation costs. Experiments are conducted on two mainstream VOS datasets, including DAVIS and Youtube-VOS. Results show that, the proposed SpVOS achieves superior performance over other state-of-the-art sparse methods, and even maintains comparable performance, e.g., an 83.04% (79.29%) overall score on the DAVIS-2017 (Youtube-VOS) validation set, with the typical non-sparse VOS baseline (82.88% for DAVIS-2017 and 80.36% for Youtube-VOS) while saving up to 42% FLOPs, showing its application potential for resource-constrained scenarios.
Estimation of forest height and biomass from open-access multi-sensor satellite imagery and GEDI Lidar data: high-resolution maps of metropolitan France
Oct 23, 2023Mapping forest resources and carbon is important for improving forest management and meeting the objectives of storing carbon and preserving the environment. Spaceborne remote sensing approaches have considerable potential to support forest height monitoring by providing repeated observations at high spatial resolution over large areas. This study uses a machine learning approach that was previously developed to produce local maps of forest parameters (basal area, height, diameter, etc.). The aim of this paper is to present the extension of the approach to much larger scales such as the French national coverage. We used the GEDI Lidar mission as reference height data, and the satellite images from Sentinel-1, Sentinel-2 and ALOS-2 PALSA-2 to estimate forest height and produce a map of France for the year 2020. The height map is then derived into volume and aboveground biomass (AGB) using allometric equations. The validation of the height map with local maps from ALS data shows an accuracy close to the state of the art, with a mean absolute error (MAE) of 4.3 m. Validation on inventory plots representative of French forests shows an MAE of 3.7 m for the height. Estimates are slightly better for coniferous than for broadleaved forests. Volume and AGB maps derived from height shows MAEs of 75 tons/ha and 93 m${}^3$/ha respectively. The results aggregated by sylvo-ecoregion and forest types (owner and species) are further improved, with MAEs of 23 tons/ha and 30 m${}^3$/ha. The precision of these maps allows to monitor forests locally, as well as helping to analyze forest resources and carbon on a territorial scale or on specific types of forests by combining the maps with geolocated information (administrative area, species, type of owner, protected areas, environmental conditions, etc.). Height, volume and AGB maps produced in this study are made freely available.