 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Open Knowledge Base Canonicalization with Multi-task Unlearning
Oct 25, 2023

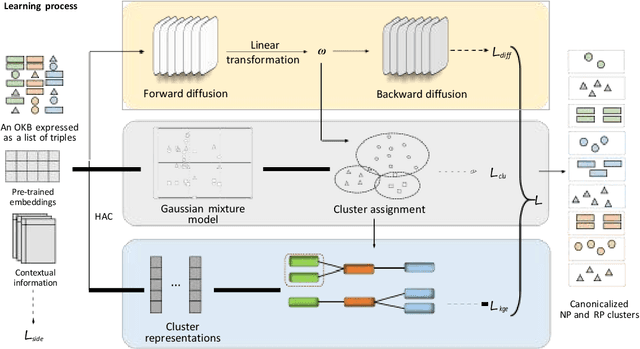
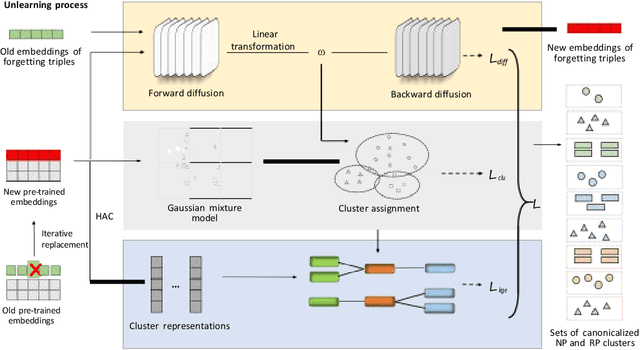

The construction of large open knowledge bases (OKBs) is integral to many applications in the field of mobile computing. Noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. However, in order to meet the requirements of some privacy protection regulations and to ensure the timeliness of the data, the canonicalized OKB often needs to remove some sensitive information or outdated data. The machine unlearning in OKB canonicalization is an excellent solution to the above problem. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Effective schemes are urgently needed to fully synergise machine unlearning with clustering and KGE learning. To this end, we put forward a multi-task unlearning framework, namely MulCanon, to tackle machine unlearning problem in OKB canonicalization. Specifically, the noise characteristics in the diffusion model are utilized to achieve the effect of machine unlearning for data in OKB. MulCanon unifies the learning objectives of diffusion model, KGE and clustering algorithms, and adopts a two-step multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization datasets validates that MulCanon achieves advanced machine unlearning effects.
Bayesian Domain Invariant Learning via Posterior Generalization of Parameter Distributions
Oct 25, 2023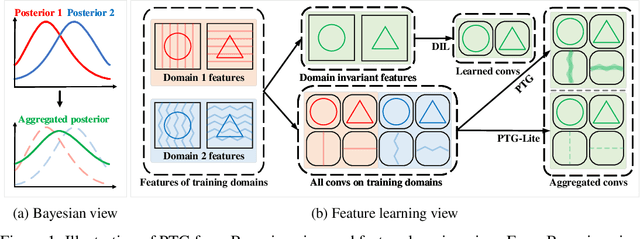
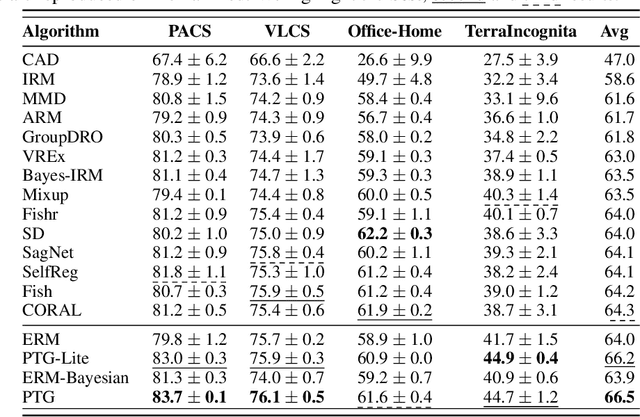

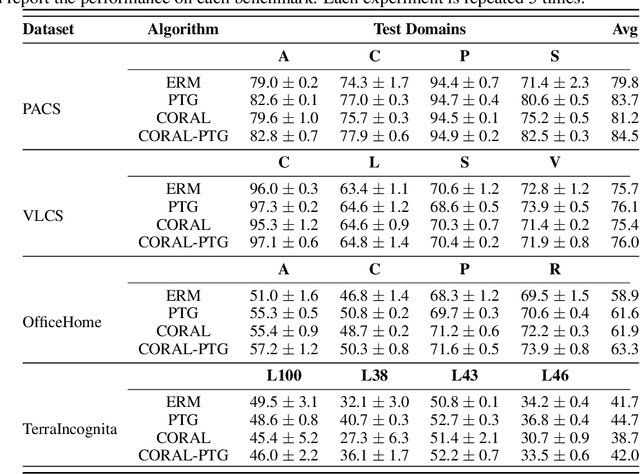
Domain invariant learning aims to learn models that extract invariant features over various training domains, resulting in better generalization to unseen target domains. Recently, Bayesian Neural Networks have achieved promising results in domain invariant learning, but most works concentrate on aligning features distributions rather than parameter distributions. Inspired by the principle of Bayesian Neural Network, we attempt to directly learn the domain invariant posterior distribution of network parameters. We first propose a theorem to show that the invariant posterior of parameters can be implicitly inferred by aggregating posteriors on different training domains. Our assumption is more relaxed and allows us to extract more domain invariant information. We also propose a simple yet effective method, named PosTerior Generalization (PTG), that can be used to estimate the invariant parameter distribution. PTG fully exploits variational inference to approximate parameter distributions, including the invariant posterior and the posteriors on training domains. Furthermore, we develop a lite version of PTG for widespread applications. PTG shows competitive performance on various domain generalization benchmarks on DomainBed. Additionally, PTG can use any existing domain generalization methods as its prior, and combined with previous state-of-the-art method the performance can be further improved. Code will be made public.
Causal Discovery with Generalized Linear Models through Peeling Algorithms
Oct 25, 2023This article presents a novel method for causal discovery with generalized structural equation models suited for analyzing diverse types of outcomes, including discrete, continuous, and mixed data. Causal discovery often faces challenges due to unmeasured confounders that hinder the identification of causal relationships. The proposed approach addresses this issue by developing two peeling algorithms (bottom-up and top-down) to ascertain causal relationships and valid instruments. This approach first reconstructs a super-graph to represent ancestral relationships between variables, using a peeling algorithm based on nodewise GLM regressions that exploit relationships between primary and instrumental variables. Then, it estimates parent-child effects from the ancestral relationships using another peeling algorithm while deconfounding a child's model with information borrowed from its parents' models. The article offers a theoretical analysis of the proposed approach, which establishes conditions for model identifiability and provides statistical guarantees for accurately discovering parent-child relationships via the peeling algorithms. Furthermore, the article presents numerical experiments showcasing the effectiveness of our approach in comparison to state-of-the-art structure learning methods without confounders. Lastly, it demonstrates an application to Alzheimer's disease (AD), highlighting the utility of the method in constructing gene-to-gene and gene-to-disease regulatory networks involving Single Nucleotide Polymorphisms (SNPs) for healthy and AD subjects.
Video Referring Expression Comprehension via Transformer with Content-conditioned Query
Oct 25, 2023
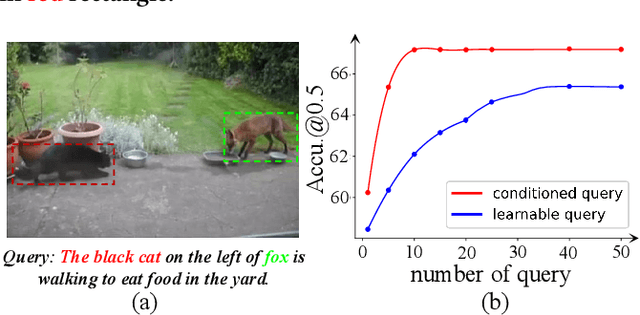
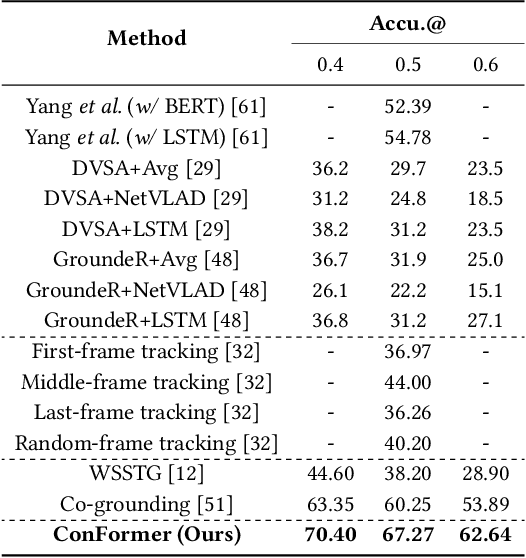
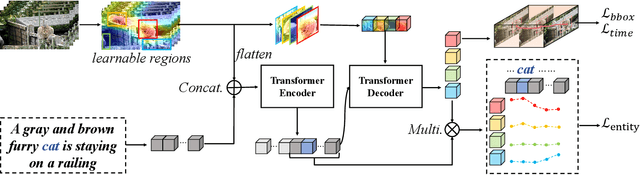
Video Referring Expression Comprehension (REC) aims to localize a target object in videos based on the queried natural language. Recent improvements in video REC have been made using Transformer-based methods with learnable queries. However, we contend that this naive query design is not ideal given the open-world nature of video REC brought by text supervision. With numerous potential semantic categories, relying on only a few slow-updated queries is insufficient to characterize them. Our solution to this problem is to create dynamic queries that are conditioned on both the input video and language to model the diverse objects referred to. Specifically, we place a fixed number of learnable bounding boxes throughout the frame and use corresponding region features to provide prior information. Also, we noticed that current query features overlook the importance of cross-modal alignment. To address this, we align specific phrases in the sentence with semantically relevant visual areas, annotating them in existing video datasets (VID-Sentence and VidSTG). By incorporating these two designs, our proposed model (called ConFormer) outperforms other models on widely benchmarked datasets. For example, in the testing split of VID-Sentence dataset, ConFormer achieves 8.75% absolute improvement on Accu.@0.6 compared to the previous state-of-the-art model.
Learning to Correct Noisy Labels for Fine-Grained Entity Typing via Co-Prediction Prompt Tuning
Oct 23, 2023Fine-grained entity typing (FET) is an essential task in natural language processing that aims to assign semantic types to entities in text. However, FET poses a major challenge known as the noise labeling problem, whereby current methods rely on estimating noise distribution to identify noisy labels but are confused by diverse noise distribution deviation. To address this limitation, we introduce Co-Prediction Prompt Tuning for noise correction in FET, which leverages multiple prediction results to identify and correct noisy labels. Specifically, we integrate prediction results to recall labeled labels and utilize a differentiated margin to identify inaccurate labels. Moreover, we design an optimization objective concerning divergent co-predictions during fine-tuning, ensuring that the model captures sufficient information and maintains robustness in noise identification. Experimental results on three widely-used FET datasets demonstrate that our noise correction approach significantly enhances the quality of various types of training samples, including those annotated using distant supervision, ChatGPT, and crowdsourcing.
Adaptive Policy with Wait-$k$ Model for Simultaneous Translation
Oct 23, 2023Simultaneous machine translation (SiMT) requires a robust read/write policy in conjunction with a high-quality translation model. Traditional methods rely on either a fixed wait-$k$ policy coupled with a standalone wait-$k$ translation model, or an adaptive policy jointly trained with the translation model. In this study, we propose a more flexible approach by decoupling the adaptive policy model from the translation model. Our motivation stems from the observation that a standalone multi-path wait-$k$ model performs competitively with adaptive policies utilized in state-of-the-art SiMT approaches. Specifically, we introduce DaP, a divergence-based adaptive policy, that makes read/write decisions for any translation model based on the potential divergence in translation distributions resulting from future information. DaP extends a frozen wait-$k$ model with lightweight parameters, and is both memory and computation efficient. Experimental results across various benchmarks demonstrate that our approach offers an improved trade-off between translation accuracy and latency, outperforming strong baselines.
CrisisMatch: Semi-Supervised Few-Shot Learning for Fine-Grained Disaster Tweet Classification
Oct 23, 2023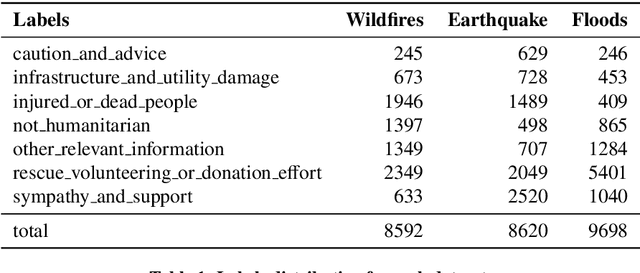
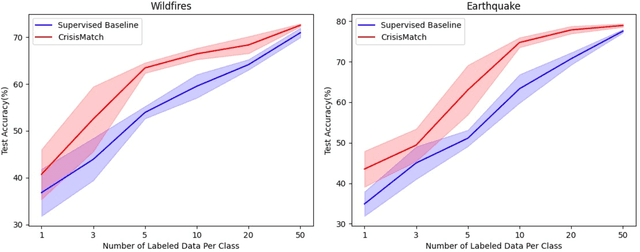
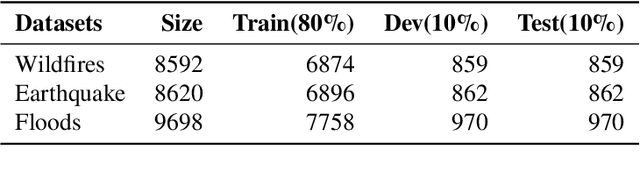
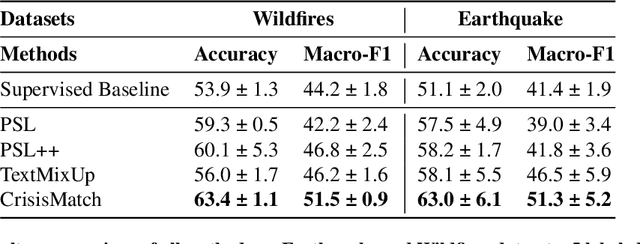
The shared real-time information about natural disasters on social media platforms like Twitter and Facebook plays a critical role in informing volunteers, emergency managers, and response organizations. However, supervised learning models for monitoring disaster events require large amounts of annotated data, making them unrealistic for real-time use in disaster events. To address this challenge, we present a fine-grained disaster tweet classification model under the semi-supervised, few-shot learning setting where only a small number of annotated data is required. Our model, CrisisMatch, effectively classifies tweets into fine-grained classes of interest using few labeled data and large amounts of unlabeled data, mimicking the early stage of a disaster. Through integrating effective semi-supervised learning ideas and incorporating TextMixUp, CrisisMatch achieves performance improvement on two disaster datasets of 11.2\% on average. Further analyses are also provided for the influence of the number of labeled data and out-of-domain results.
Pre-Trained Language Models Augmented with Synthetic Scanpaths for Natural Language Understanding
Oct 23, 2023Human gaze data offer cognitive information that reflects natural language comprehension. Indeed, augmenting language models with human scanpaths has proven beneficial for a range of NLP tasks, including language understanding. However, the applicability of this approach is hampered because the abundance of text corpora is contrasted by a scarcity of gaze data. Although models for the generation of human-like scanpaths during reading have been developed, the potential of synthetic gaze data across NLP tasks remains largely unexplored. We develop a model that integrates synthetic scanpath generation with a scanpath-augmented language model, eliminating the need for human gaze data. Since the model's error gradient can be propagated throughout all parts of the model, the scanpath generator can be fine-tuned to downstream tasks. We find that the proposed model not only outperforms the underlying language model, but achieves a performance that is comparable to a language model augmented with real human gaze data. Our code is publicly available.
Why LLMs Hallucinate, and How to Get (Evidential) Closure: Perceptual, Intensional, and Extensional Learning for Faithful Natural Language Generation
Oct 23, 2023We show that LLMs hallucinate because their output is not constrained to be synonymous with claims for which they have evidence: a condition that we call evidential closure. Information about the truth or falsity of sentences is not statistically identified in the standard neural probabilistic language model setup, and so cannot be conditioned on to generate new strings. We then show how to constrain LLMs to produce output that does satisfy evidential closure. A multimodal LLM must learn about the external world (perceptual learning); it must learn a mapping from strings to states of the world (extensional learning); and, to achieve fluency when generalizing beyond a body of evidence, it must learn mappings from strings to their synonyms (intensional learning). The output of a unimodal LLM must be synonymous with strings in a validated evidence set. Finally, we present a heuristic procedure, Learn-Babble-Prune, that yields faithful output from an LLM by rejecting output that is not synonymous with claims for which the LLM has evidence.
XTSC-Bench: Quantitative Benchmarking for Explainers on Time Series Classification
Oct 23, 2023Despite the growing body of work on explainable machine learning in time series classification (TSC), it remains unclear how to evaluate different explainability methods. Resorting to qualitative assessment and user studies to evaluate explainers for TSC is difficult since humans have difficulties understanding the underlying information contained in time series data. Therefore, a systematic review and quantitative comparison of explanation methods to confirm their correctness becomes crucial. While steps to standardized evaluations were taken for tabular, image, and textual data, benchmarking explainability methods on time series is challenging due to a) traditional metrics not being directly applicable, b) implementation and adaption of traditional metrics for time series in the literature vary, and c) varying baseline implementations. This paper proposes XTSC-Bench, a benchmarking tool providing standardized datasets, models, and metrics for evaluating explanation methods on TSC. We analyze 3 perturbation-, 6 gradient- and 2 example-based explanation methods to TSC showing that improvements in the explainers' robustness and reliability are necessary, especially for multivariate data.