 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reasoning with Adaptive Worker Allocation for Stance Detection
Jun 10, 2026Stance detection requires identifying an author's position toward a target, often from short-form texts where stance is implicit, indirect, or rhetorically framed. Although large language models (LLMs) achieve strong performance on this task, single-pass prompting can be brittle when multiple interpretations are plausible. Existing aggregation strategies, such as majority voting or self-consistency, improve robustness by combining labels, but they discard the intermediate reasoning needed to resolve conflicting interpretations. We introduce a multi-agent reasoning framework with adaptive worker allocation for stance detection that shifts aggregation from label-level voting to reasoning-level synthesis. The framework employs a Manager-Worker architecture in which a Manager adaptively allocates a variable number of Worker agents based on input complexity. Each Worker analyzes the input from a distinct perspective and produces a reasoning-only explanation without emitting a stance label; the Manager then synthesizes these explanations to produce the final prediction. We evaluate the proposed framework on SemEval-2016, P-Stance, and COVID-19 Stance using Llama, Mistral, and Gemini. Results show that the framework yields the largest gains on implicit and context-dependent stance cases, achieving 86.07 Macro-F1 on COVID-19 and 82.90 on SemEval-2016, while remaining competitive on more explicit stance datasets such as P-Stance. These findings suggest that adaptive reasoning-level aggregation is most beneficial when stance cannot be reliably inferred from surface cues alone.
MSGL-Transformer: A Multi-Scale Global-Local Transformer for Rodent Social Behavior Recognition
Apr 08, 2026Recognition of rodent behavior is important for understanding neural and behavioral mechanisms. Traditional manual scoring is time-consuming and prone to human error. We propose MSGL-Transformer, a Multi-Scale Global-Local Transformer for recognizing rodent social behaviors from pose-based temporal sequences. The model employs a lightweight transformer encoder with multi-scale attention to capture motion dynamics across different temporal scales. The architecture integrates parallel short-range, medium-range, and global attention branches to explicitly capture behavior dynamics at multiple temporal scales. We also introduce a Behavior-Aware Modulation (BAM) block, inspired by SE-Networks, which modulates temporal embeddings to emphasize behavior-relevant features prior to attention. We evaluate on two datasets: RatSI (5 behavior classes, 12D pose inputs) and CalMS21 (4 behavior classes, 28D pose inputs). On RatSI, MSGL-Transformer achieves 75.4% mean accuracy and F1-score of 0.745 across nine cross-validation splits, outperforming TCN, LSTM, and Bi-LSTM. On CalMS21, it achieves 87.1% accuracy and F1-score of 0.8745, a +10.7% improvement over HSTWFormer, and outperforms ST-GCN, MS-G3D, CTR-GCN, and STGAT. The same architecture generalizes across both datasets with only input dimensionality and number of classes adjusted.
Practical Insights into Semi-Supervised Object Detection Approaches
Jan 19, 2026Learning in data-scarce settings has recently gained significant attention in the research community. Semi-supervised object detection(SSOD) aims to improve detection performance by leveraging a large number of unlabeled images alongside a limited number of labeled images(a.k.a.,few-shot learning). In this paper, we present a comprehensive comparison of three state-of-the-art SSOD approaches, including MixPL, Semi-DETR and Consistent-Teacher, with the goal of understanding how performance varies with the number of labeled images. We conduct experiments using the MS-COCO and Pascal VOC datasets, two popular object detection benchmarks which allow for standardized evaluation. In addition, we evaluate the SSOD approaches on a custom Beetle dataset which enables us to gain insights into their performance on specialized datasets with a smaller number of object categories. Our findings highlight the trade-offs between accuracy, model size, and latency, providing insights into which methods are best suited for low-data regimes.
Predictive Modeling and Explainable AI for Veterinary Safety Profiles, Residue Assessment, and Health Outcomes Using Real-World Data and Physicochemical Properties
Oct 01, 2025The safe use of pharmaceuticals in food-producing animals is vital to protect animal welfare and human food safety. Adverse events (AEs) may signal unexpected pharmacokinetic or toxicokinetic effects, increasing the risk of violative residues in the food chain. This study introduces a predictive framework for classifying outcomes (Death vs. Recovery) using ~1.28 million reports (1987-2025 Q1) from the U.S. FDA's OpenFDA Center for Veterinary Medicine. A preprocessing pipeline merged relational tables and standardized AEs through VeDDRA ontologies. Data were normalized, missing values imputed, and high-cardinality features reduced; physicochemical drug properties were integrated to capture chemical-residue links. We evaluated supervised models, including Random Forest, CatBoost, XGBoost, ExcelFormer, and large language models (Gemma 3-27B, Phi 3-12B). Class imbalance was addressed, such as undersampling and oversampling, with a focus on prioritizing recall for fatal outcomes. Ensemble methods(Voting, Stacking) and CatBoost performed best, achieving precision, recall, and F1-scores of 0.95. Incorporating Average Uncertainty Margin (AUM)-based pseudo-labeling of uncertain cases improved minority-class detection, particularly in ExcelFormer and XGBoost. Interpretability via SHAP identified biologically plausible predictors, including lung, heart, and bronchial disorders, animal demographics, and drug physicochemical properties. These features were strongly linked to fatal outcomes. Overall, the framework shows that combining rigorous data engineering, advanced machine learning, and explainable AI enables accurate, interpretable predictions of veterinary safety outcomes. The approach supports FARAD's mission by enabling early detection of high-risk drug-event profiles, strengthening residue risk assessment, and informing regulatory and clinical decision-making.
A MISMATCHED Benchmark for Scientific Natural Language Inference
Jun 05, 2025Scientific Natural Language Inference (NLI) is the task of predicting the semantic relation between a pair of sentences extracted from research articles. Existing datasets for this task are derived from various computer science (CS) domains, whereas non-CS domains are completely ignored. In this paper, we introduce a novel evaluation benchmark for scientific NLI, called MISMATCHED. The new MISMATCHED benchmark covers three non-CS domains-PSYCHOLOGY, ENGINEERING, and PUBLIC HEALTH, and contains 2,700 human annotated sentence pairs. We establish strong baselines on MISMATCHED using both Pre-trained Small Language Models (SLMs) and Large Language Models (LLMs). Our best performing baseline shows a Macro F1 of only 78.17% illustrating the substantial headroom for future improvements. In addition to introducing the MISMATCHED benchmark, we show that incorporating sentence pairs having an implicit scientific NLI relation between them in model training improves their performance on scientific NLI. We make our dataset and code publicly available on GitHub.
CrisisMatch: Semi-Supervised Few-Shot Learning for Fine-Grained Disaster Tweet Classification
Oct 23, 2023



The shared real-time information about natural disasters on social media platforms like Twitter and Facebook plays a critical role in informing volunteers, emergency managers, and response organizations. However, supervised learning models for monitoring disaster events require large amounts of annotated data, making them unrealistic for real-time use in disaster events. To address this challenge, we present a fine-grained disaster tweet classification model under the semi-supervised, few-shot learning setting where only a small number of annotated data is required. Our model, CrisisMatch, effectively classifies tweets into fine-grained classes of interest using few labeled data and large amounts of unlabeled data, mimicking the early stage of a disaster. Through integrating effective semi-supervised learning ideas and incorporating TextMixUp, CrisisMatch achieves performance improvement on two disaster datasets of 11.2\% on average. Further analyses are also provided for the influence of the number of labeled data and out-of-domain results.
Identification of Fine-Grained Location Mentions in Crisis Tweets
Nov 11, 2021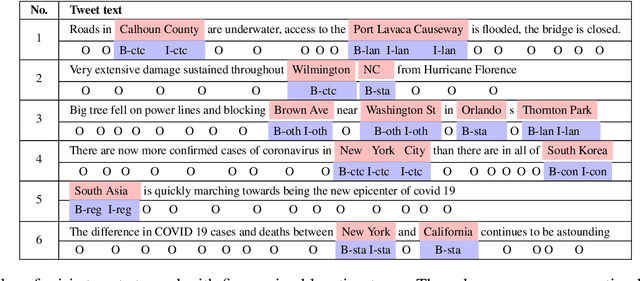

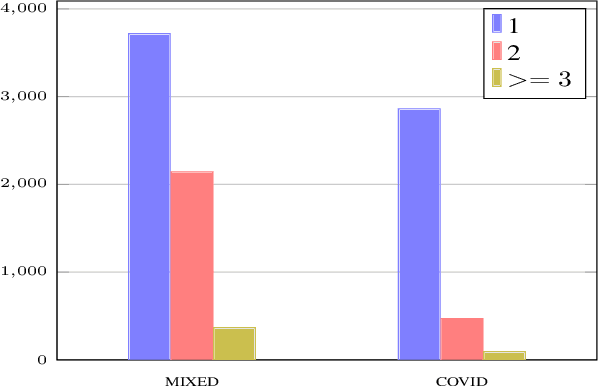
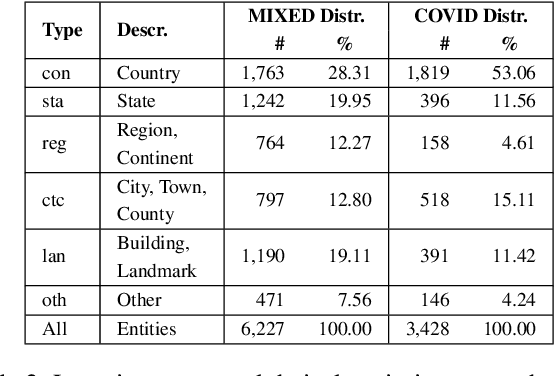
Identification of fine-grained location mentions in crisis tweets is central in transforming situational awareness information extracted from social media into actionable information. Most prior works have focused on identifying generic locations, without considering their specific types. To facilitate progress on the fine-grained location identification task, we assemble two tweet crisis datasets and manually annotate them with specific location types. The first dataset contains tweets from a mixed set of crisis events, while the second dataset contains tweets from the global COVID-19 pandemic. We investigate the performance of state-of-the-art deep learning models for sequence tagging on these datasets, in both in-domain and cross-domain settings.
On Identifying Hashtags in Disaster Twitter Data
Jan 05, 2020

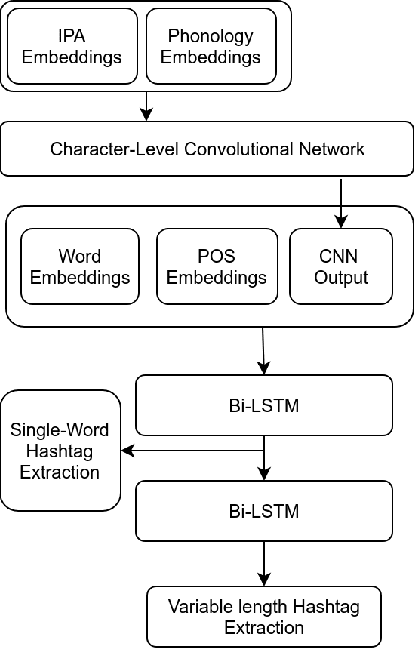
Tweet hashtags have the potential to improve the search for information during disaster events. However, there is a large number of disaster-related tweets that do not have any user-provided hashtags. Moreover, only a small number of tweets that contain actionable hashtags are useful for disaster response. To facilitate progress on automatic identification (or extraction) of disaster hashtags for Twitter data, we construct a unique dataset of disaster-related tweets annotated with hashtags useful for filtering actionable information. Using this dataset, we further investigate Long Short Term Memory-based models within a Multi-Task Learning framework. The best performing model achieves an F1-score as high as 92.22%. The dataset, code, and other resources are available on Github.
Keyphrase Extraction from Disaster-related Tweets
Oct 17, 2019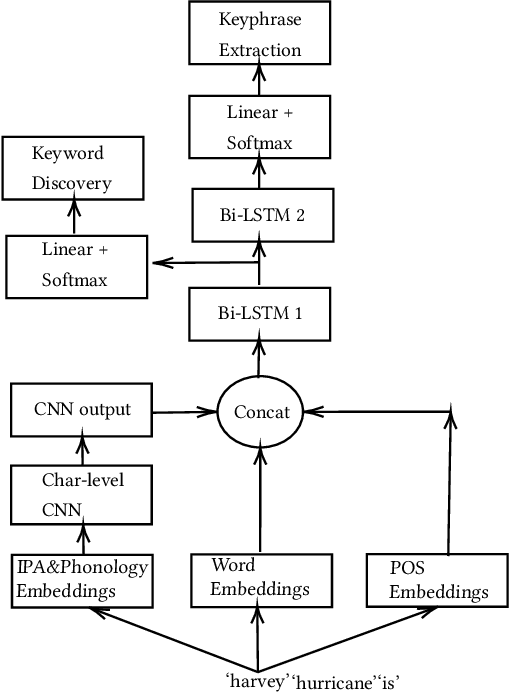
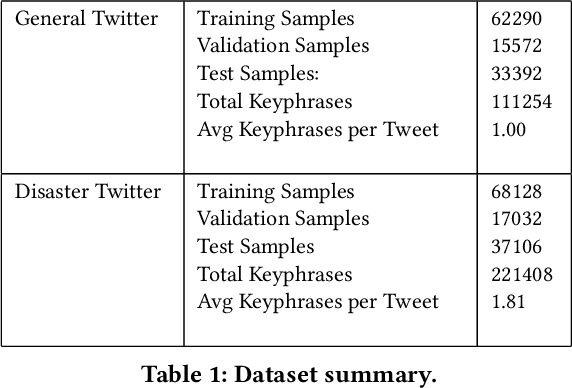
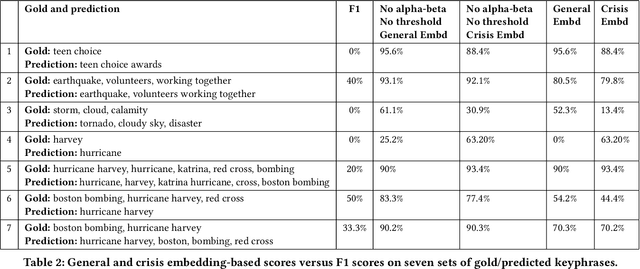
While keyphrase extraction has received considerable attention in recent years, relatively few studies exist on extracting keyphrases from social media platforms such as Twitter, and even fewer for extracting disaster-related keyphrases from such sources. During a disaster, keyphrases can be extremely useful for filtering relevant tweets that can enhance situational awareness. Previously, joint training of two different layers of a stacked Recurrent Neural Network for keyword discovery and keyphrase extraction had been shown to be effective in extracting keyphrases from general Twitter data. We improve the model's performance on both general Twitter data and disaster-related Twitter data by incorporating contextual word embeddings, POS-tags, phonetics, and phonological features. Moreover, we discuss the shortcomings of the often used F1-measure for evaluating the quality of predicted keyphrases with respect to the ground truth annotations. Instead of the F1-measure, we propose the use of embedding-based metrics to better capture the correctness of the predicted keyphrases. In addition, we also present a novel extension of an embedding-based metric. The extension allows one to better control the penalty for the difference in the number of ground-truth and predicted keyphrases
* 12 pages, 7 figures
Localizing and Quantifying Damage in Social Media Images
Jun 09, 2018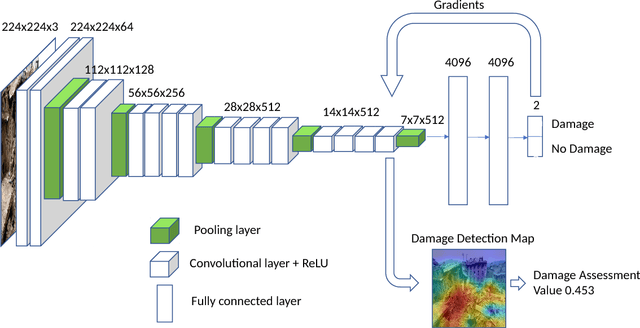
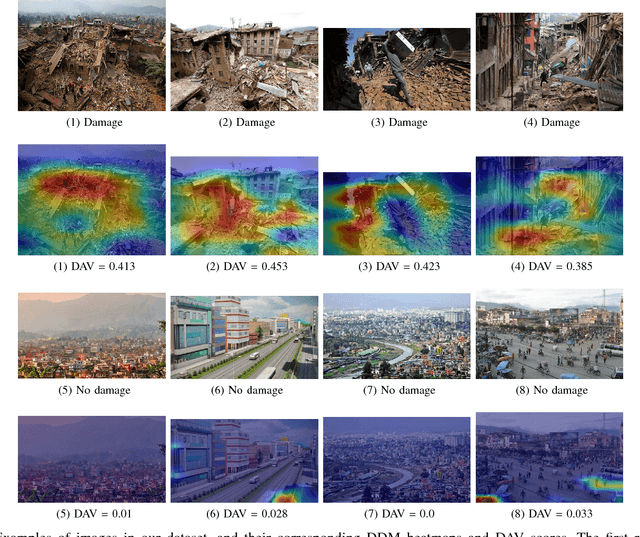
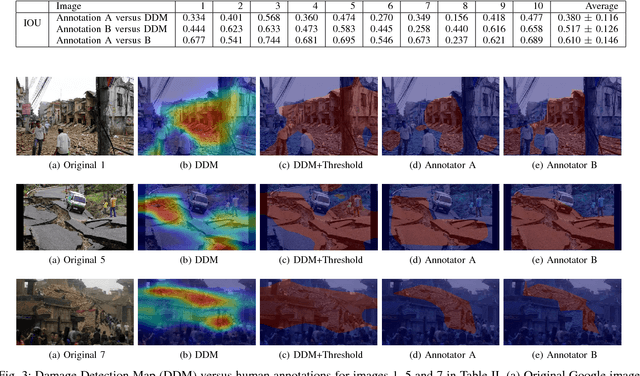

Traditional post-disaster assessment of damage heavily relies on expensive GIS data, especially remote sensing image data. In recent years, social media has become a rich source of disaster information that may be useful in assessing damage at a lower cost. Such information includes text (e.g., tweets) or images posted by eyewitnesses of a disaster. Most of the existing research explores the use of text in identifying situational awareness information useful for disaster response teams. The use of social media images to assess disaster damage is limited. In this paper, we propose a novel approach, based on convolutional neural networks and class activation maps, to locate damage in a disaster image and to quantify the degree of the damage. Our proposed approach enables the use of social network images for post-disaster damage assessment and provides an inexpensive and feasible alternative to the more expensive GIS approach.