 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Spiking-UNet for Image Processing
Jul 20, 2023
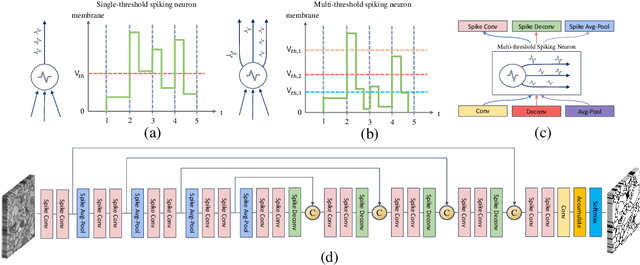
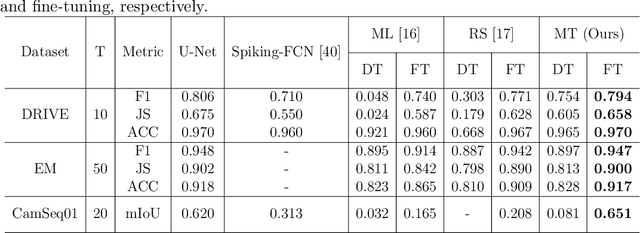
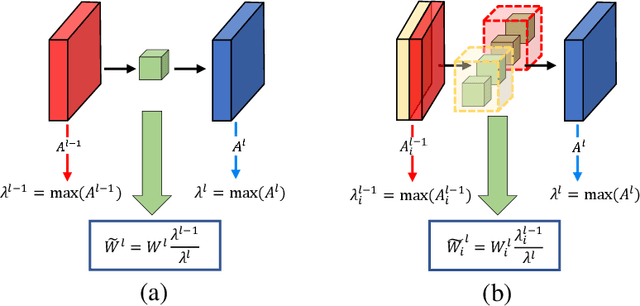
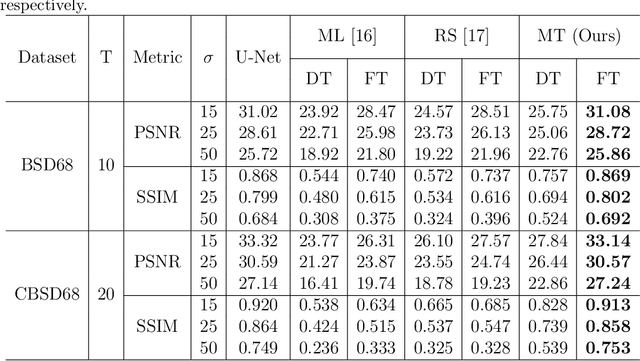
U-Net, known for its simple yet efficient architecture, is widely utilized for image processing tasks and is particularly suitable for deployment on neuromorphic chips. This paper introduces the novel concept of Spiking-UNet for image processing, which combines the power of Spiking Neural Networks (SNNs) with the U-Net architecture. To achieve an efficient Spiking-UNet, we face two primary challenges: ensuring high-fidelity information propagation through the network via spikes and formulating an effective training strategy. To address the issue of information loss, we introduce multi-threshold spiking neurons, which improve the efficiency of information transmission within the Spiking-UNet. For the training strategy, we adopt a conversion and fine-tuning pipeline that leverage pre-trained U-Net models. During the conversion process, significant variability in data distribution across different parts is observed when utilizing skip connections. Therefore, we propose a connection-wise normalization method to prevent inaccurate firing rates. Furthermore, we adopt a flow-based training method to fine-tune the converted models, reducing time steps while preserving performance. Experimental results show that, on image segmentation and denoising, our Spiking-UNet achieves comparable performance to its non-spiking counterpart, surpassing existing SNN methods. Compared with the converted Spiking-UNet without fine-tuning, our Spiking-UNet reduces inference time by approximately 90\%. This research broadens the application scope of SNNs in image processing and is expected to inspire further exploration in the field of neuromorphic engineering. The code for our Spiking-UNet implementation is available at https://github.com/SNNresearch/Spiking-UNet.
Gaining Insights into Denoising by Inpainting
Sep 23, 2023The filling-in effect of diffusion processes is a powerful tool for various image analysis tasks such as inpainting-based compression and dense optic flow computation. For noisy data, an interesting side effect occurs: The interpolated data have higher confidence, since they average information from many noisy sources. This observation forms the basis of our denoising by inpainting (DbI) framework. It averages multiple inpainting results from different noisy subsets. Our goal is to obtain fundamental insights into key properties of DbI and its connections to existing methods. Like in inpainting-based image compression, we choose homogeneous diffusion as a very simple inpainting operator that performs well for highly optimized data. We propose several strategies to choose the location of the selected pixels. Moreover, to improve the global approximation quality further, we also allow to change the function values of the noisy pixels. In contrast to traditional denoising methods that adapt the operator to the data, our approach adapts the data to the operator. Experimentally we show that replacing homogeneous diffusion inpainting by biharmonic inpainting does not improve the reconstruction quality. This again emphasizes the importance of data adaptivity over operator adaptivity. On the foundational side, we establish deterministic and probabilistic theories with convergence estimates. In the non-adaptive 1-D case, we derive equivalence results between DbI on shifted regular grids and classical homogeneous diffusion filtering via an explicit relation between the density and the diffusion time.
Exploring the Robustness of Human Parsers Towards Common Corruptions
Sep 07, 2023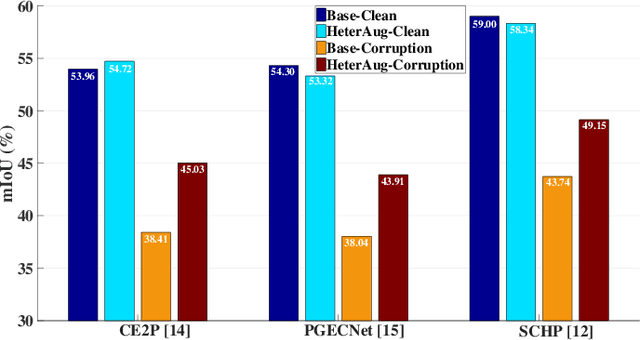
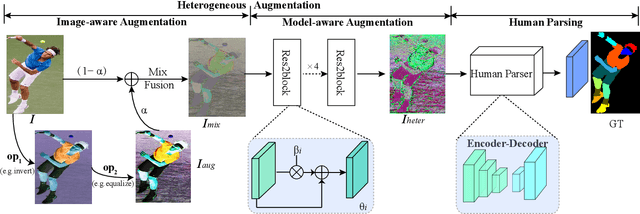

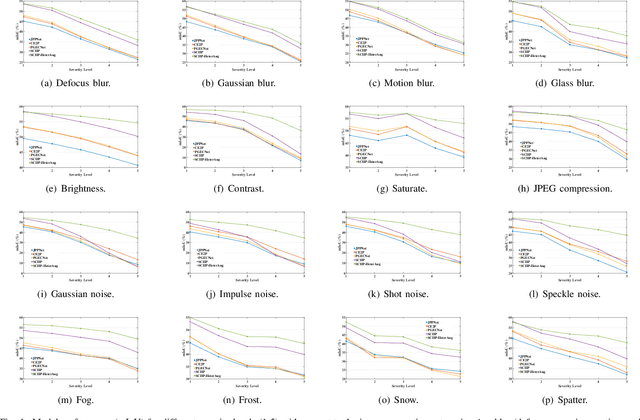
Human parsing aims to segment each pixel of the human image with fine-grained semantic categories. However, current human parsers trained with clean data are easily confused by numerous image corruptions such as blur and noise. To improve the robustness of human parsers, in this paper, we construct three corruption robustness benchmarks, termed LIP-C, ATR-C, and Pascal-Person-Part-C, to assist us in evaluating the risk tolerance of human parsing models. Inspired by the data augmentation strategy, we propose a novel heterogeneous augmentation-enhanced mechanism to bolster robustness under commonly corrupted conditions. Specifically, two types of data augmentations from different views, i.e., image-aware augmentation and model-aware image-to-image transformation, are integrated in a sequential manner for adapting to unforeseen image corruptions. The image-aware augmentation can enrich the high diversity of training images with the help of common image operations. The model-aware augmentation strategy that improves the diversity of input data by considering the model's randomness. The proposed method is model-agnostic, and it can plug and play into arbitrary state-of-the-art human parsing frameworks. The experimental results show that the proposed method demonstrates good universality which can improve the robustness of the human parsing models and even the semantic segmentation models when facing various image common corruptions. Meanwhile, it can still obtain approximate performance on clean data.
CosSIF: Cosine similarity-based image filtering to overcome low inter-class variation in synthetic medical image datasets
Jul 25, 2023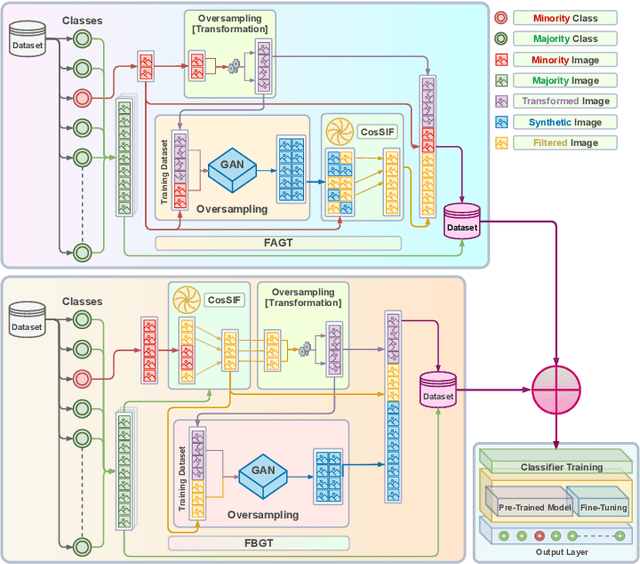
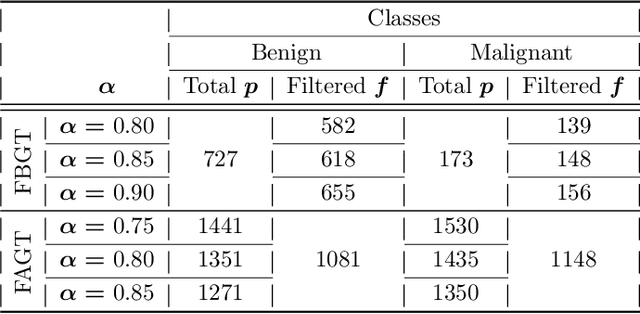
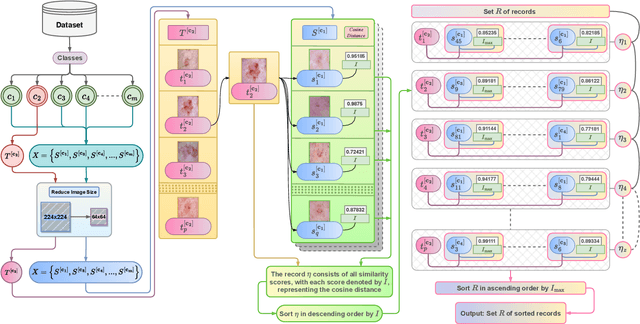
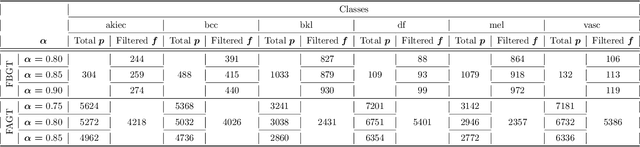
Crafting effective deep learning models for medical image analysis is a complex task, particularly in cases where the medical image dataset lacks significant inter-class variation. This challenge is further aggravated when employing such datasets to generate synthetic images using generative adversarial networks (GANs), as the output of GANs heavily relies on the input data. In this research, we propose a novel filtering algorithm called Cosine Similarity-based Image Filtering (CosSIF). We leverage CosSIF to develop two distinct filtering methods: Filtering Before GAN Training (FBGT) and Filtering After GAN Training (FAGT). FBGT involves the removal of real images that exhibit similarities to images of other classes before utilizing them as the training dataset for a GAN. On the other hand, FAGT focuses on eliminating synthetic images with less discriminative features compared to real images used for training the GAN. Experimental results reveal that employing either the FAGT or FBGT method with modern transformer and convolutional-based networks leads to substantial performance gains in various evaluation metrics. FAGT implementation on the ISIC-2016 dataset surpasses the baseline method in terms of sensitivity by 1.59\% and AUC by 1.88\%. Furthermore, for the HAM10000 dataset, applying FABT outperforms the baseline approach in terms of recall by 13.75\%, and with the sole implementation of FAGT, achieves a maximum accuracy of 94.44\%.
SAR Target Image Generation Method Using Azimuth-Controllable Generative Adversarial Network
Aug 10, 2023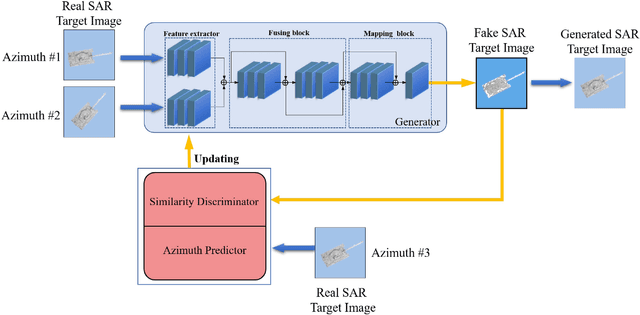
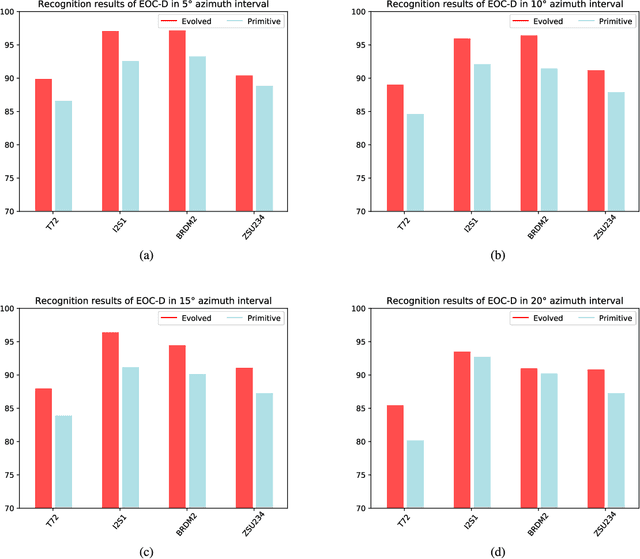
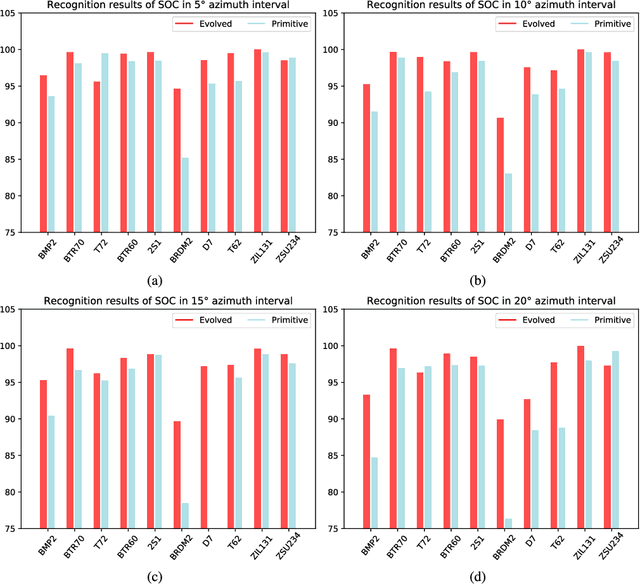
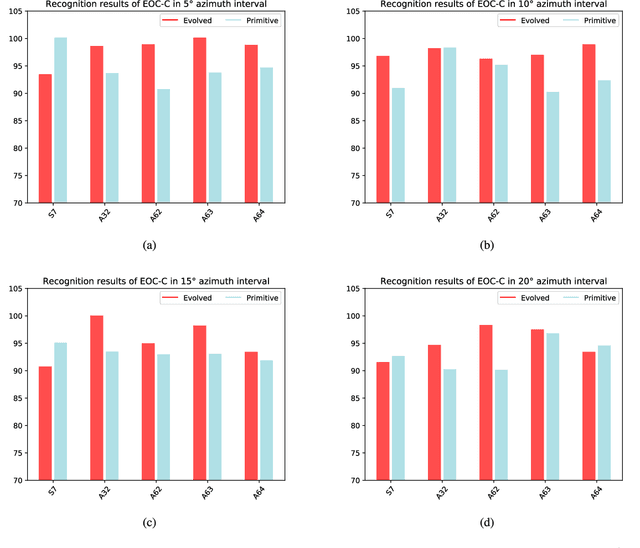
Sufficient synthetic aperture radar (SAR) target images are very important for the development of researches. However, available SAR target images are often limited in practice, which hinders the progress of SAR application. In this paper, we propose an azimuth-controllable generative adversarial network to generate precise SAR target images with an intermediate azimuth between two given SAR images' azimuths. This network mainly contains three parts: generator, discriminator, and predictor. Through the proposed specific network structure, the generator can extract and fuse the optimal target features from two input SAR target images to generate SAR target image. Then a similarity discriminator and an azimuth predictor are designed. The similarity discriminator can differentiate the generated SAR target images from the real SAR images to ensure the accuracy of the generated, while the azimuth predictor measures the difference of azimuth between the generated and the desired to ensure the azimuth controllability of the generated. Therefore, the proposed network can generate precise SAR images, and their azimuths can be controlled well by the inputs of the deep network, which can generate the target images in different azimuths to solve the small sample problem to some degree and benefit the researches of SAR images. Extensive experimental results show the superiority of the proposed method in azimuth controllability and accuracy of SAR target image generation.
Robust estimation of exposure ratios in multi-exposure image stacks
Aug 05, 2023

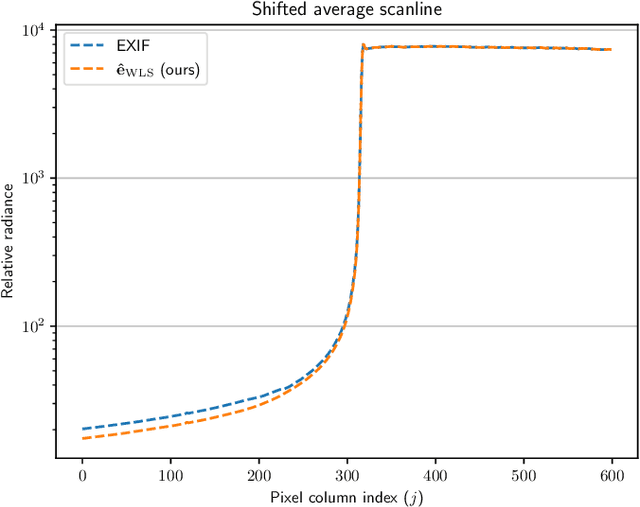
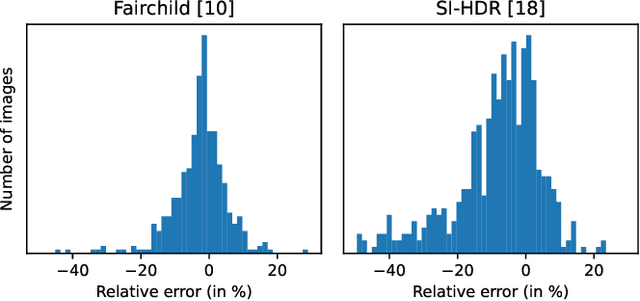
Merging multi-exposure image stacks into a high dynamic range (HDR) image requires knowledge of accurate exposure times. When exposure times are inaccurate, for example, when they are extracted from a camera's EXIF metadata, the reconstructed HDR images reveal banding artifacts at smooth gradients. To remedy this, we propose to estimate exposure ratios directly from the input images. We derive the exposure time estimation as an optimization problem, in which pixels are selected from pairs of exposures to minimize estimation error caused by camera noise. When pixel values are represented in the logarithmic domain, the problem can be solved efficiently using a linear solver. We demonstrate that the estimation can be easily made robust to pixel misalignment caused by camera or object motion by collecting pixels from multiple spatial tiles. The proposed automatic exposure estimation and alignment eliminates banding artifacts in popular datasets and is essential for applications that require physically accurate reconstructions, such as measuring the modulation transfer function of a display. The code for the method is available.
A quantum moving target segmentation algorithm for grayscale video
Oct 01, 2023The moving target segmentation (MTS) aims to segment out moving targets in the video, however, the classical algorithm faces the huge challenge of real-time processing in the current video era. Some scholars have successfully demonstrated the quantum advantages in some video processing tasks, but not concerning moving target segmentation. In this paper, a quantum moving target segmentation algorithm for grayscale video is proposed, which can use quantum mechanism to simultaneously calculate the difference of all pixels in all adjacent frames and then quickly segment out the moving target. In addition, a feasible quantum comparator is designed to distinguish the grayscale values with the threshold. Then several quantum circuit units, including three-frame difference, binarization and AND operation, are designed in detail, and then are combined together to construct the complete quantum circuits for segmenting the moving target. For a quantum video with $2^m$ frames (every frame is a $2^n\times 2^n$ image with $q$ grayscale levels), the complexity of our algorithm can be reduced to O$(n^2 + q)$. Compared with the classic counterpart, it is an exponential speedup, while its complexity is also superior to the existing quantum algorithms. Finally, the experiment is conducted on IBM Q to show the feasibility of our algorithm in the noisy intermediate-scale quantum (NISQ) era.
* 15 pages, 15 figures
Ultrasound Image Reconstruction with Denoising Diffusion Restoration Models
Jul 29, 2023
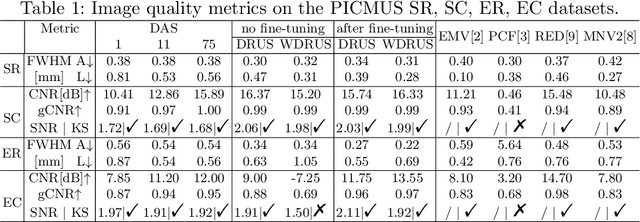
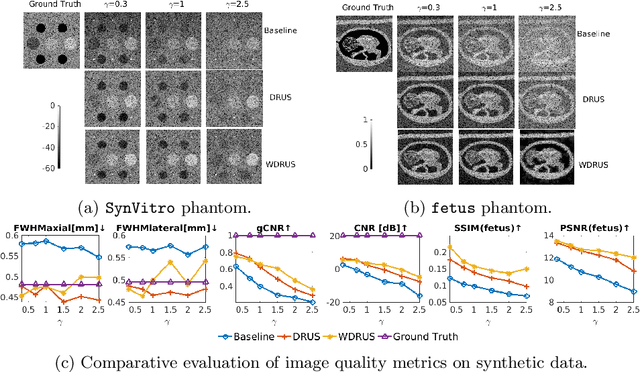
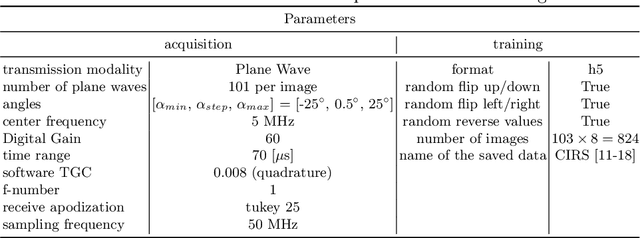
Ultrasound image reconstruction can be approximately cast as a linear inverse problem that has traditionally been solved with penalized optimization using the $l_1$ or $l_2$ norm, or wavelet-based terms. However, such regularization functions often struggle to balance the sparsity and the smoothness. A promising alternative is using learned priors to make the prior knowledge closer to reality. In this paper, we rely on learned priors under the framework of Denoising Diffusion Restoration Models (DDRM), initially conceived for restoration tasks with natural images. We propose and test two adaptions of DDRM to ultrasound inverse problem models, DRUS and WDRUS. Our experiments on synthetic and PICMUS data show that from a single plane wave our method can achieve image quality comparable to or better than DAS and state-of-the-art methods. The code is available at: https://github.com/Yuxin-Zhang-Jasmine/DRUS-v1.
Timbre transfer using image-to-image denoising diffusion implicit models
Jul 28, 2023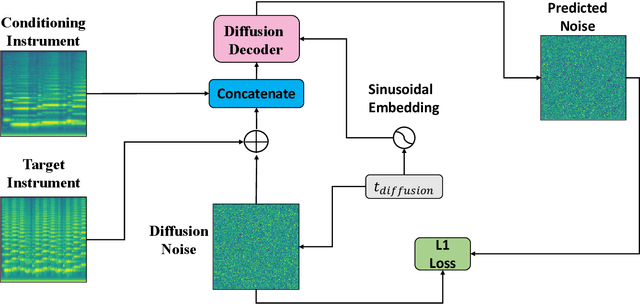
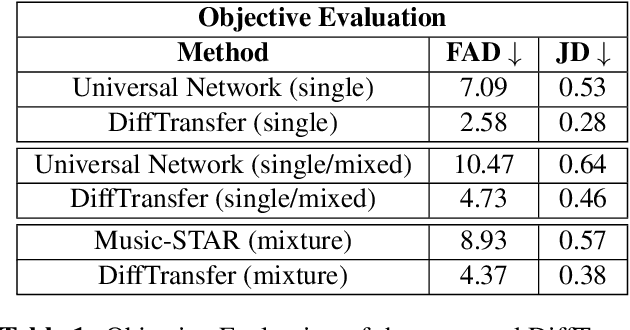
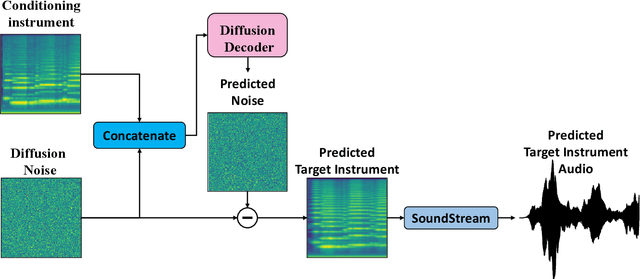
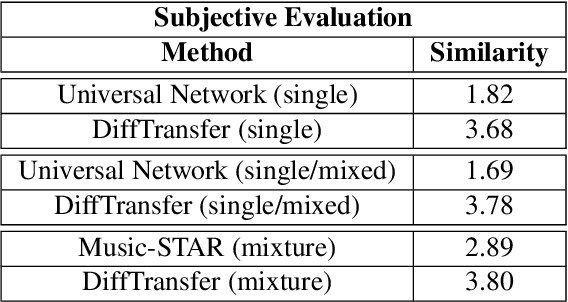
Timbre transfer techniques aim at converting the sound of a musical piece generated by one instrument into the same one as if it was played by another instrument, while maintaining as much as possible the content in terms of musical characteristics such as melody and dynamics. Following their recent breakthroughs in deep learning-based generation, we apply Denoising Diffusion Models (DDMs) to perform timbre transfer. Specifically, we apply the recently proposed Denoising Diffusion Implicit Models (DDIMs) that enable to accelerate the sampling procedure. Inspired by the recent application of DDMs to image translation problems we formulate the timbre transfer task similarly, by first converting the audio tracks into log mel spectrograms and by conditioning the generation of the desired timbre spectrogram through the input timbre spectrogram. We perform both one-to-one and many-to-many timbre transfer, by converting audio waveforms containing only single instruments and multiple instruments, respectively. We compare the proposed technique with existing state-of-the-art methods both through listening tests and objective measures in order to demonstrate the effectiveness of the proposed model.
A hybrid approach for improving U-Net variants in medical image segmentation
Jul 31, 2023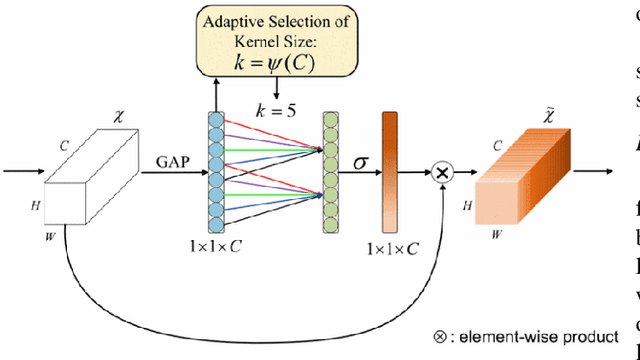

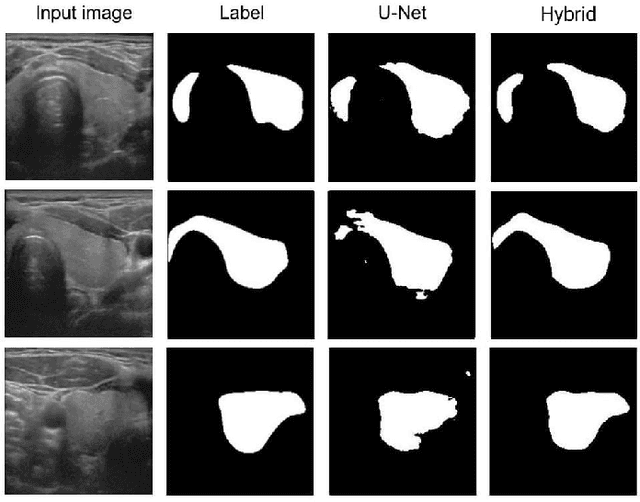
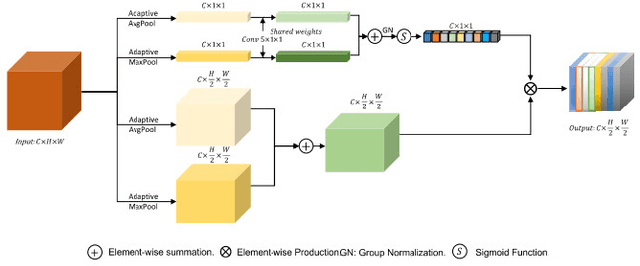
Medical image segmentation is vital to the area of medical imaging because it enables professionals to more accurately examine and understand the information offered by different imaging modalities. The technique of splitting a medical image into various segments or regions of interest is known as medical image segmentation. The segmented images that are produced can be used for many different things, including diagnosis, surgery planning, and therapy evaluation. In initial phase of research, major focus has been given to review existing deep-learning approaches, including researches like MultiResUNet, Attention U-Net, classical U-Net, and other variants. The attention feature vectors or maps dynamically add important weights to critical information, and most of these variants use these to increase accuracy, but the network parameter requirements are somewhat more stringent. They face certain problems such as overfitting, as their number of trainable parameters is very high, and so is their inference time. Therefore, the aim of this research is to reduce the network parameter requirements using depthwise separable convolutions, while maintaining performance over some medical image segmentation tasks such as skin lesion segmentation using attention system and residual connections.