 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hybrid-Fusion Transformer for Multisequence MRI
Nov 02, 2023
Medical segmentation has grown exponentially through the advent of a fully convolutional network (FCN), and we have now reached a turning point through the success of Transformer. However, the different characteristics of the modality have not been fully integrated into Transformer for medical segmentation. In this work, we propose the novel hybrid fusion Transformer (HFTrans) for multisequence MRI image segmentation. We take advantage of the differences among multimodal MRI sequences and utilize the Transformer layers to integrate the features extracted from each modality as well as the features of the early fused modalities. We validate the effectiveness of our hybrid-fusion method in three-dimensional (3D) medical segmentation. Experiments on two public datasets, BraTS2020 and MRBrainS18, show that the proposed method outperforms previous state-of-the-art methods on the task of brain tumor segmentation and brain structure segmentation.
COSE: A Consistency-Sensitivity Metric for Saliency on Image Classification
Sep 20, 2023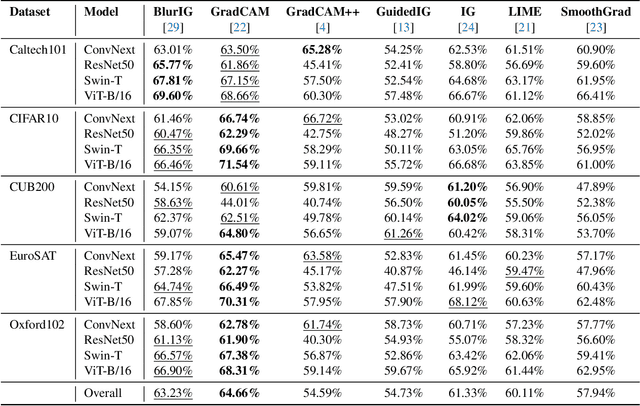
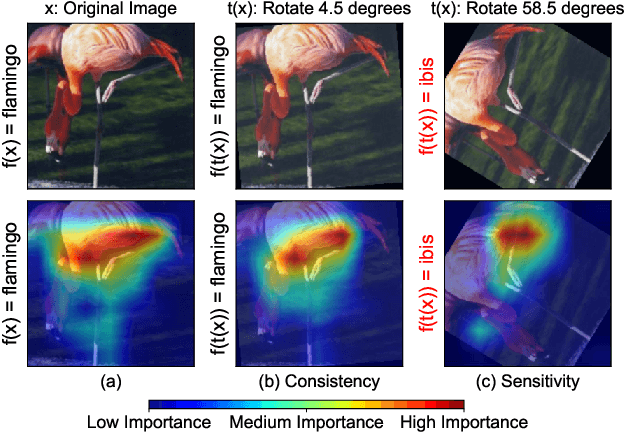
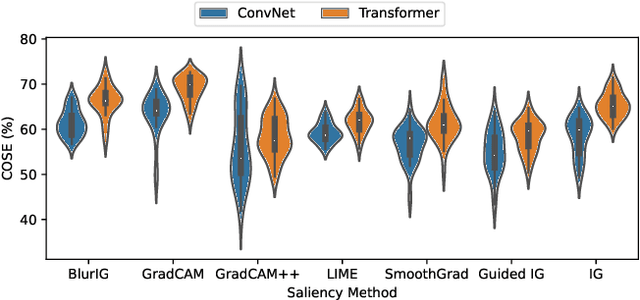
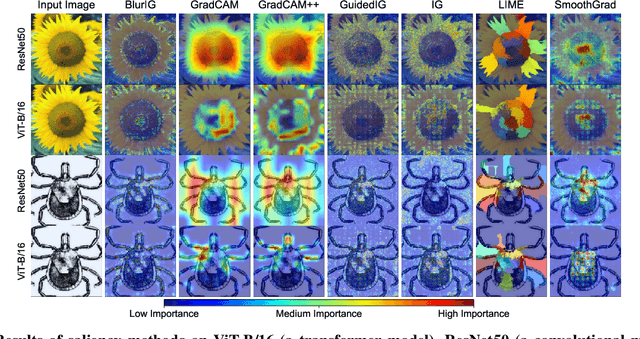
We present a set of metrics that utilize vision priors to effectively assess the performance of saliency methods on image classification tasks. To understand behavior in deep learning models, many methods provide visual saliency maps emphasizing image regions that most contribute to a model prediction. However, there is limited work on analyzing the reliability of saliency methods in explaining model decisions. We propose the metric COnsistency-SEnsitivity (COSE) that quantifies the equivariant and invariant properties of visual model explanations using simple data augmentations. Through our metrics, we show that although saliency methods are thought to be architecture-independent, most methods could better explain transformer-based models over convolutional-based models. In addition, GradCAM was found to outperform other methods in terms of COSE but was shown to have limitations such as lack of variability for fine-grained datasets. The duality between consistency and sensitivity allow the analysis of saliency methods from different angles. Ultimately, we find that it is important to balance these two metrics for a saliency map to faithfully show model behavior.
Heterogeneous Generative Knowledge Distillation with Masked Image Modeling
Sep 18, 2023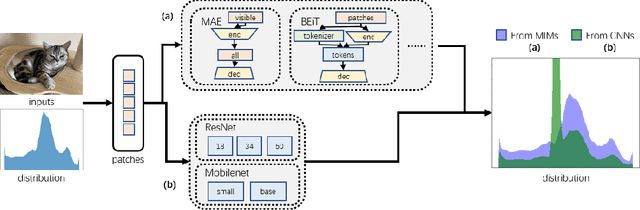
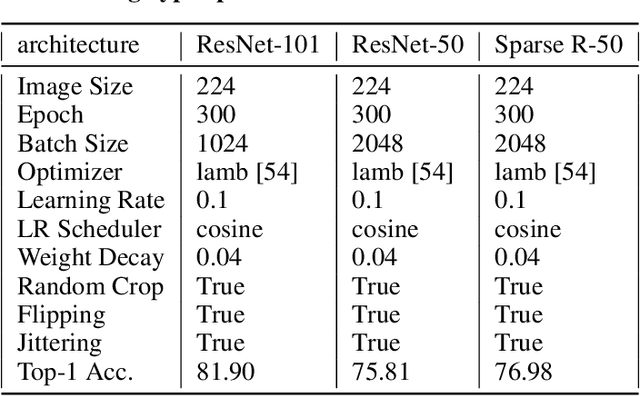
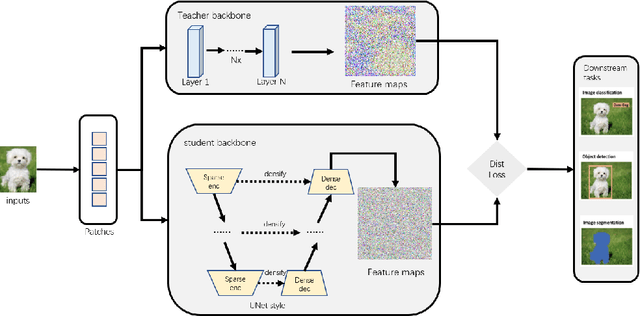
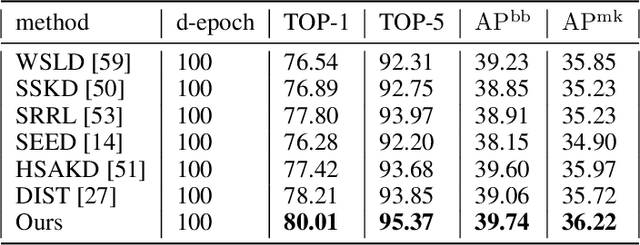
Small CNN-based models usually require transferring knowledge from a large model before they are deployed in computationally resource-limited edge devices. Masked image modeling (MIM) methods achieve great success in various visual tasks but remain largely unexplored in knowledge distillation for heterogeneous deep models. The reason is mainly due to the significant discrepancy between the Transformer-based large model and the CNN-based small network. In this paper, we develop the first Heterogeneous Generative Knowledge Distillation (H-GKD) based on MIM, which can efficiently transfer knowledge from large Transformer models to small CNN-based models in a generative self-supervised fashion. Our method builds a bridge between Transformer-based models and CNNs by training a UNet-style student with sparse convolution, which can effectively mimic the visual representation inferred by a teacher over masked modeling. Our method is a simple yet effective learning paradigm to learn the visual representation and distribution of data from heterogeneous teacher models, which can be pre-trained using advanced generative methods. Extensive experiments show that it adapts well to various models and sizes, consistently achieving state-of-the-art performance in image classification, object detection, and semantic segmentation tasks. For example, in the Imagenet 1K dataset, H-GKD improves the accuracy of Resnet50 (sparse) from 76.98% to 80.01%.
MoEController: Instruction-based Arbitrary Image Manipulation with Mixture-of-Expert Controllers
Sep 08, 2023
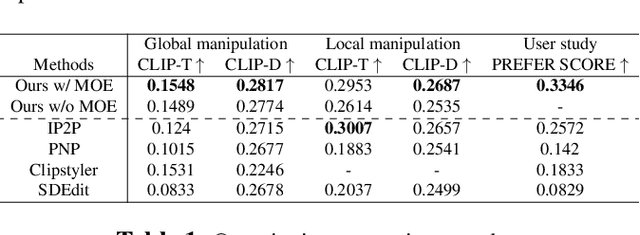

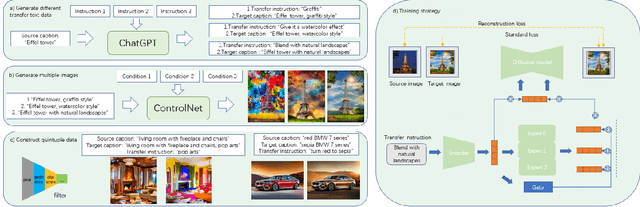
Diffusion-model-based text-guided image generation has recently made astounding progress, producing fascinating results in open-domain image manipulation tasks. Few models, however, currently have complete zero-shot capabilities for both global and local image editing due to the complexity and diversity of image manipulation tasks. In this work, we propose a method with a mixture-of-expert (MOE) controllers to align the text-guided capacity of diffusion models with different kinds of human instructions, enabling our model to handle various open-domain image manipulation tasks with natural language instructions. First, we use large language models (ChatGPT) and conditional image synthesis models (ControlNet) to generate a large number of global image transfer dataset in addition to the instruction-based local image editing dataset. Then, using an MOE technique and task-specific adaptation training on a large-scale dataset, our conditional diffusion model can edit images globally and locally. Extensive experiments demonstrate that our approach performs surprisingly well on various image manipulation tasks when dealing with open-domain images and arbitrary human instructions. Please refer to our project page: [https://oppo-mente-lab.github.io/moe_controller/]
Create Your World: Lifelong Text-to-Image Diffusion
Sep 08, 2023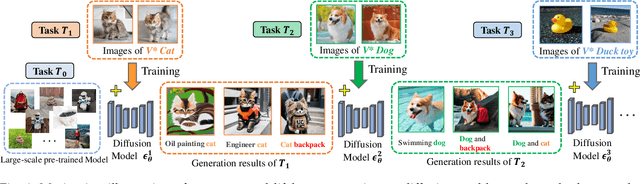
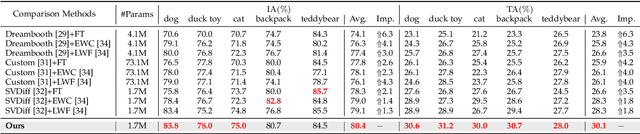
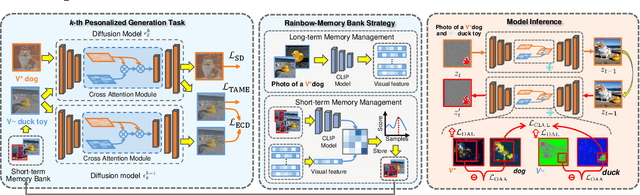
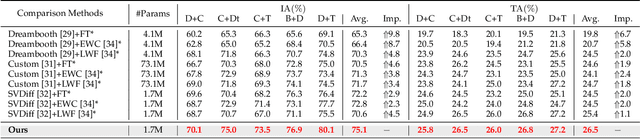
Text-to-image generative models can produce diverse high-quality images of concepts with a text prompt, which have demonstrated excellent ability in image generation, image translation, etc. We in this work study the problem of synthesizing instantiations of a use's own concepts in a never-ending manner, i.e., create your world, where the new concepts from user are quickly learned with a few examples. To achieve this goal, we propose a Lifelong text-to-image Diffusion Model (L2DM), which intends to overcome knowledge "catastrophic forgetting" for the past encountered concepts, and semantic "catastrophic neglecting" for one or more concepts in the text prompt. In respect of knowledge "catastrophic forgetting", our L2DM framework devises a task-aware memory enhancement module and a elastic-concept distillation module, which could respectively safeguard the knowledge of both prior concepts and each past personalized concept. When generating images with a user text prompt, the solution to semantic "catastrophic neglecting" is that a concept attention artist module can alleviate the semantic neglecting from concept aspect, and an orthogonal attention module can reduce the semantic binding from attribute aspect. To the end, our model can generate more faithful image across a range of continual text prompts in terms of both qualitative and quantitative metrics, when comparing with the related state-of-the-art models. The code will be released at https://wenqiliang.github.io/.
Noise-Free Score Distillation
Oct 26, 2023Score Distillation Sampling (SDS) has emerged as the de facto approach for text-to-content generation in non-image domains. In this paper, we reexamine the SDS process and introduce a straightforward interpretation that demystifies the necessity for large Classifier-Free Guidance (CFG) scales, rooted in the distillation of an undesired noise term. Building upon our interpretation, we propose a novel Noise-Free Score Distillation (NFSD) process, which requires minimal modifications to the original SDS framework. Through this streamlined design, we achieve more effective distillation of pre-trained text-to-image diffusion models while using a nominal CFG scale. This strategic choice allows us to prevent the over-smoothing of results, ensuring that the generated data is both realistic and complies with the desired prompt. To demonstrate the efficacy of NFSD, we provide qualitative examples that compare NFSD and SDS, as well as several other methods.
Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
Sep 14, 2023
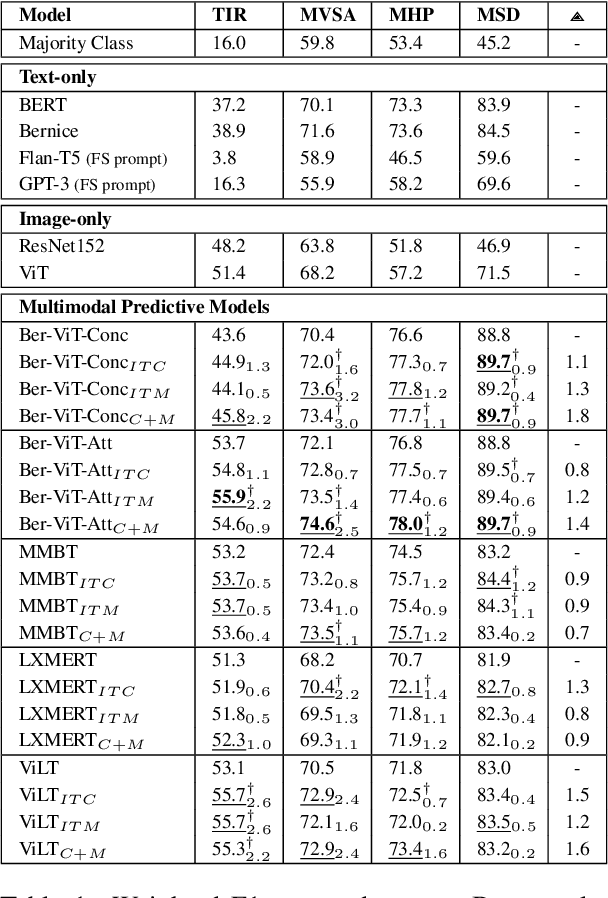
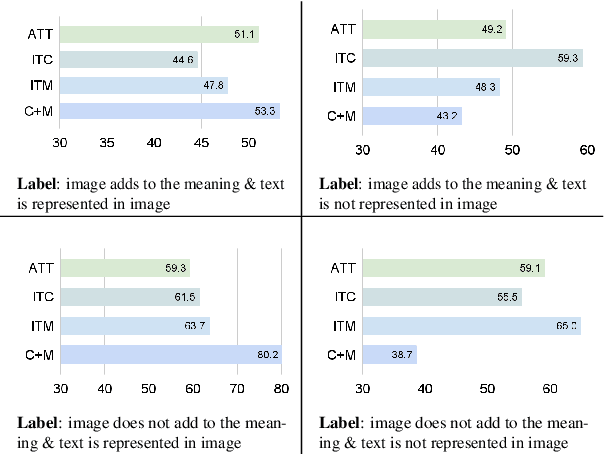

Effectively leveraging multimodal information from social media posts is essential to various downstream tasks such as sentiment analysis, sarcasm detection and hate speech classification. However, combining text and image information is challenging because of the idiosyncratic cross-modal semantics with hidden or complementary information present in matching image-text pairs. In this work, we aim to directly model this by proposing the use of two auxiliary losses jointly with the main task when fine-tuning any pre-trained multimodal model. Image-Text Contrastive (ITC) brings image-text representations of a post closer together and separates them from different posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates the understanding of semantic correspondence between images and text by penalizing unrelated pairs. We combine these objectives with five multimodal models, demonstrating consistent improvements across four popular social media datasets. Furthermore, through detailed analysis, we shed light on the specific scenarios and cases where each auxiliary task proves to be most effective.
GAN-based Algorithm for Efficient Image Inpainting
Sep 13, 2023Global pandemic due to the spread of COVID-19 has post challenges in a new dimension on facial recognition, where people start to wear masks. Under such condition, the authors consider utilizing machine learning in image inpainting to tackle the problem, by complete the possible face that is originally covered in mask. In particular, autoencoder has great potential on retaining important, general features of the image as well as the generative power of the generative adversarial network (GAN). The authors implement a combination of the two models, context encoders and explain how it combines the power of the two models and train the model with 50,000 images of influencers faces and yields a solid result that still contains space for improvements. Furthermore, the authors discuss some shortcomings with the model, their possible improvements, as well as some area of study for future investigation for applicative perspective, as well as directions to further enhance and refine the model.
Dynamic Task and Weight Prioritization Curriculum Learning for Multimodal Imagery
Oct 29, 2023This paper explores post-disaster analytics using multimodal deep learning models trained with curriculum learning method. Studying post-disaster analytics is important as it plays a crucial role in mitigating the impact of disasters by providing timely and accurate insights into the extent of damage and the allocation of resources. We propose a curriculum learning strategy to enhance the performance of multimodal deep learning models. Curriculum learning emulates the progressive learning sequence in human education by training deep learning models on increasingly complex data. Our primary objective is to develop a curriculum-trained multimodal deep learning model, with a particular focus on visual question answering (VQA) capable of jointly processing image and text data, in conjunction with semantic segmentation for disaster analytics using the FloodNet\footnote{https://github.com/BinaLab/FloodNet-Challenge-EARTHVISION2021} dataset. To achieve this, U-Net model is used for semantic segmentation and image encoding. A custom built text classifier is used for visual question answering. Existing curriculum learning methods rely on manually defined difficulty functions. We introduce a novel curriculum learning approach termed Dynamic Task and Weight Prioritization (DATWEP), which leverages a gradient-based method to automatically decide task difficulty during curriculum learning training, thereby eliminating the need for explicit difficulty computation. The integration of DATWEP into our multimodal model shows improvement on VQA performance. Source code is available at https://github.com/fualsan/DATWEP.
Prompt Me Up: Unleashing the Power of Alignments for Multimodal Entity and Relation Extraction
Oct 25, 2023How can we better extract entities and relations from text? Using multimodal extraction with images and text obtains more signals for entities and relations, and aligns them through graphs or hierarchical fusion, aiding in extraction. Despite attempts at various fusions, previous works have overlooked many unlabeled image-caption pairs, such as NewsCLIPing. This paper proposes innovative pre-training objectives for entity-object and relation-image alignment, extracting objects from images and aligning them with entity and relation prompts for soft pseudo-labels. These labels are used as self-supervised signals for pre-training, enhancing the ability to extract entities and relations. Experiments on three datasets show an average 3.41% F1 improvement over prior SOTA. Additionally, our method is orthogonal to previous multimodal fusions, and using it on prior SOTA fusions further improves 5.47% F1.