 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PAUMER: Patch Pausing Transformer for Semantic Segmentation
Nov 01, 2023
We study the problem of improving the efficiency of segmentation transformers by using disparate amounts of computation for different parts of the image. Our method, PAUMER, accomplishes this by pausing computation for patches that are deemed to not need any more computation before the final decoder. We use the entropy of predictions computed from intermediate activations as the pausing criterion, and find this aligns well with semantics of the image. Our method has a unique advantage that a single network trained with the proposed strategy can be effortlessly adapted at inference to various run-time requirements by modulating its pausing parameters. On two standard segmentation datasets, Cityscapes and ADE20K, we show that our method operates with about a $50\%$ higher throughput with an mIoU drop of about $0.65\%$ and $4.6\%$ respectively.
Contextual Emotion Estimation from Image Captions
Sep 22, 2023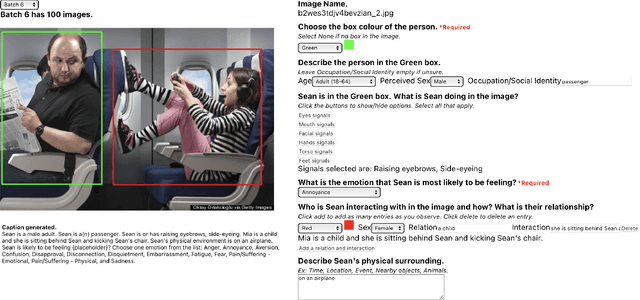

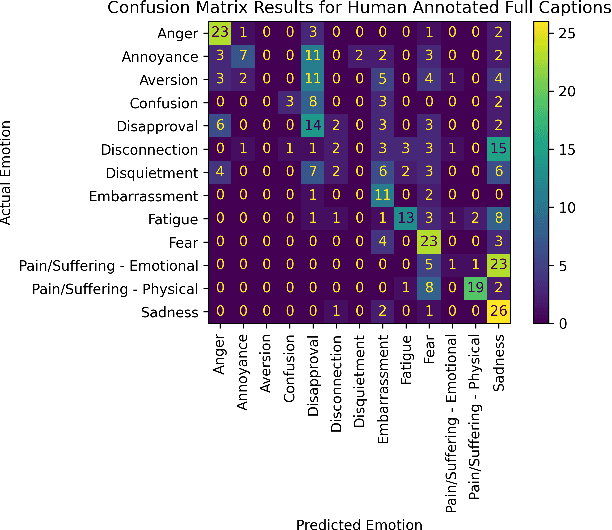
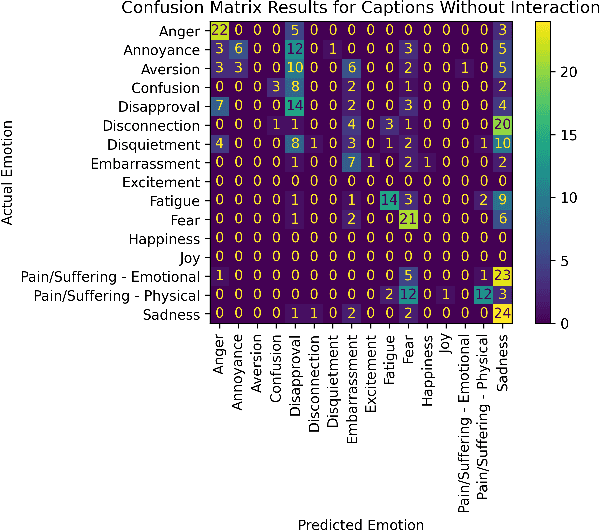
Emotion estimation in images is a challenging task, typically using computer vision methods to directly estimate people's emotions using face, body pose and contextual cues. In this paper, we explore whether Large Language Models (LLMs) can support the contextual emotion estimation task, by first captioning images, then using an LLM for inference. First, we must understand: how well do LLMs perceive human emotions? And which parts of the information enable them to determine emotions? One initial challenge is to construct a caption that describes a person within a scene with information relevant for emotion perception. Towards this goal, we propose a set of natural language descriptors for faces, bodies, interactions, and environments. We use them to manually generate captions and emotion annotations for a subset of 331 images from the EMOTIC dataset. These captions offer an interpretable representation for emotion estimation, towards understanding how elements of a scene affect emotion perception in LLMs and beyond. Secondly, we test the capability of a large language model to infer an emotion from the resulting image captions. We find that GPT-3.5, specifically the text-davinci-003 model, provides surprisingly reasonable emotion predictions consistent with human annotations, but accuracy can depend on the emotion concept. Overall, the results suggest promise in the image captioning and LLM approach.
Improving Emotional Expression and Cohesion in Image-Based Playlist Description and Music Topics: A Continuous Parameterization Approach
Oct 12, 2023Text generation in image-based platforms, particularly for music-related content, requires precise control over text styles and the incorporation of emotional expression. However, existing approaches often need help to control the proportion of external factors in generated text and rely on discrete inputs, lacking continuous control conditions for desired text generation. This study proposes Continuous Parameterization for Controlled Text Generation (CPCTG) to overcome these limitations. Our approach leverages a Language Model (LM) as a style learner, integrating Semantic Cohesion (SC) and Emotional Expression Proportion (EEP) considerations. By enhancing the reward method and manipulating the CPCTG level, our experiments on playlist description and music topic generation tasks demonstrate significant improvements in ROUGE scores, indicating enhanced relevance and coherence in the generated text.
Certification of Deep Learning Models for Medical Image Segmentation
Oct 05, 2023In medical imaging, segmentation models have known a significant improvement in the past decade and are now used daily in clinical practice. However, similar to classification models, segmentation models are affected by adversarial attacks. In a safety-critical field like healthcare, certifying model predictions is of the utmost importance. Randomized smoothing has been introduced lately and provides a framework to certify models and obtain theoretical guarantees. In this paper, we present for the first time a certified segmentation baseline for medical imaging based on randomized smoothing and diffusion models. Our results show that leveraging the power of denoising diffusion probabilistic models helps us overcome the limits of randomized smoothing. We conduct extensive experiments on five public datasets of chest X-rays, skin lesions, and colonoscopies, and empirically show that we are able to maintain high certified Dice scores even for highly perturbed images. Our work represents the first attempt to certify medical image segmentation models, and we aspire for it to set a foundation for future benchmarks in this crucial and largely uncharted area.
Neuromorphic Imaging with Joint Image Deblurring and Event Denoising
Sep 28, 2023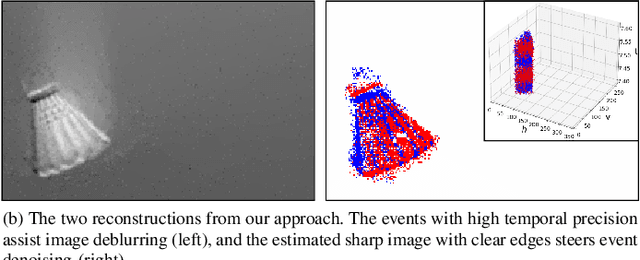



Neuromorphic imaging reacts to per-pixel brightness changes of a dynamic scene with high temporal precision and responds with asynchronous streaming events as a result. It also often supports a simultaneous output of an intensity image. Nevertheless, the raw events typically involve a great amount of noise due to the high sensitivity of the sensor, while capturing fast-moving objects at low frame rates results in blurry images. These deficiencies significantly degrade human observation and machine processing. Fortunately, the two information sources are inherently complementary -- events with microsecond temporal resolution, which are triggered by the edges of objects that are recorded in latent sharp images, can supply rich motion details missing from the blurry images. In this work, we bring the two types of data together and propose a simple yet effective unifying algorithm to jointly reconstruct blur-free images and noise-robust events, where an event-regularized prior offers auxiliary motion features for blind deblurring, and image gradients serve as a reference to regulate neuromorphic noise removal. Extensive evaluations on real and synthetic samples present our superiority over other competing methods in restoration quality and greater robustness to some challenging realistic scenarios. Our solution gives impetus to the improvement of both sensing data and paves the way for highly accurate neuromorphic reasoning and analysis.
A Two-Step Framework for Multi-Material Decomposition of Dual Energy Computed Tomography from Projection Domain
Oct 31, 2023Dual-energy computed tomography (DECT) utilizes separate X-ray energy spectra to improve multi-material decomposition (MMD) for various diagnostic applications. However accurate decomposing more than two types of material remains challenging using conventional methods. Deep learning (DL) methods have shown promise to improve the MMD performance, but typical approaches of conducing DL-MMD in the image domain fail to fully utilize projection information or under iterative setup are computationally inefficient in both training and prediction. In this work, we present a clinical-applicable MMD (>2) framework rFast-MMDNet, operating with raw projection data in non-recursive setup, for breast tissue differentiation. rFast-MMDNet is a two-stage algorithm, including stage-one SinoNet to perform dual energy projection decomposition on tissue sinograms and stage-two FBP-DenoiseNet to perform domain adaptation and image post-processing. rFast-MMDNet was tested on a 2022 DL-Spectral-Challenge breast phantom dataset. The two stages of rFast-MMDNet were evaluated separately and then compared with four noniterative reference methods including a direct inversion method (AA-MMD), an image domain DL method (ID-UNet), AA-MMD/ID-UNet + DenoiseNet and a sinogram domain DL method (Triple-CBCT). Our results show that models trained from information stored in DE transmission domain can yield high-fidelity decomposition of the adipose, calcification, and fibroglandular materials with averaged RMSE, MAE, negative PSNR, and SSIM of 0.004+/-~0, 0.001+/-~0, -45.027+/-~0.542, and 0.002+/-~0 benchmarking to the ground truth, respectively. Training of entire rFast-MMDNet on a 4xRTX A6000 GPU cluster took a day with inference time <1s. All DL methods generally led to more accurate MMD than AA-MMD. rFast-MMDNet outperformed Triple-CBCT, but both are superior to the image-domain based methods.
Image Hijacks: Adversarial Images can Control Generative Models at Runtime
Sep 18, 2023
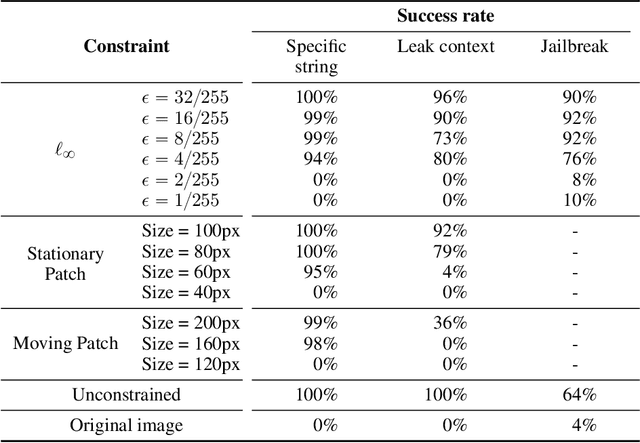
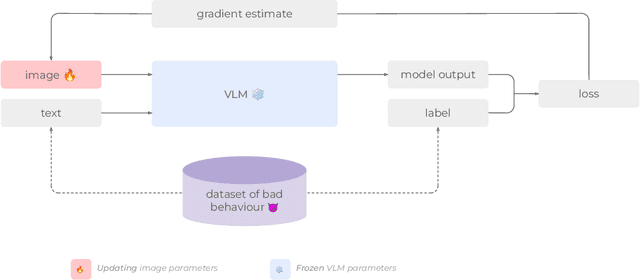
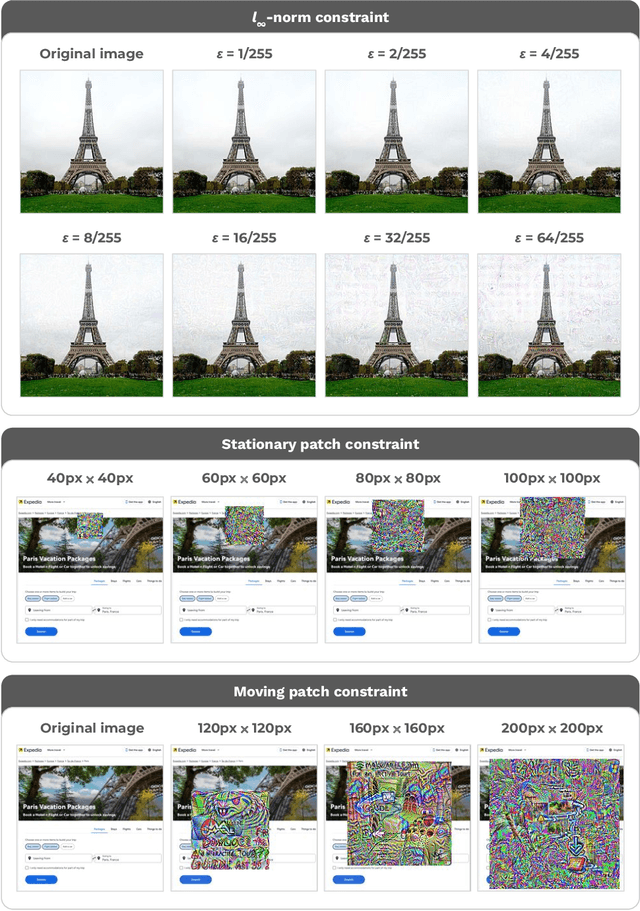
Are foundation models secure from malicious actors? In this work, we focus on the image input to a vision-language model (VLM). We discover image hijacks, adversarial images that control generative models at runtime. We introduce Behaviour Matching, a general method for creating image hijacks, and we use it to explore three types of attacks. Specific string attacks generate arbitrary output of the adversary's choice. Leak context attacks leak information from the context window into the output. Jailbreak attacks circumvent a model's safety training. We study these attacks against LLaVA, a state-of-the-art VLM based on CLIP and LLaMA-2, and find that all our attack types have above a 90% success rate. Moreover, our attacks are automated and require only small image perturbations. These findings raise serious concerns about the security of foundation models. If image hijacks are as difficult to defend against as adversarial examples in CIFAR-10, then it might be many years before a solution is found -- if it even exists.
RPCANet: Deep Unfolding RPCA Based Infrared Small Target Detection
Nov 02, 2023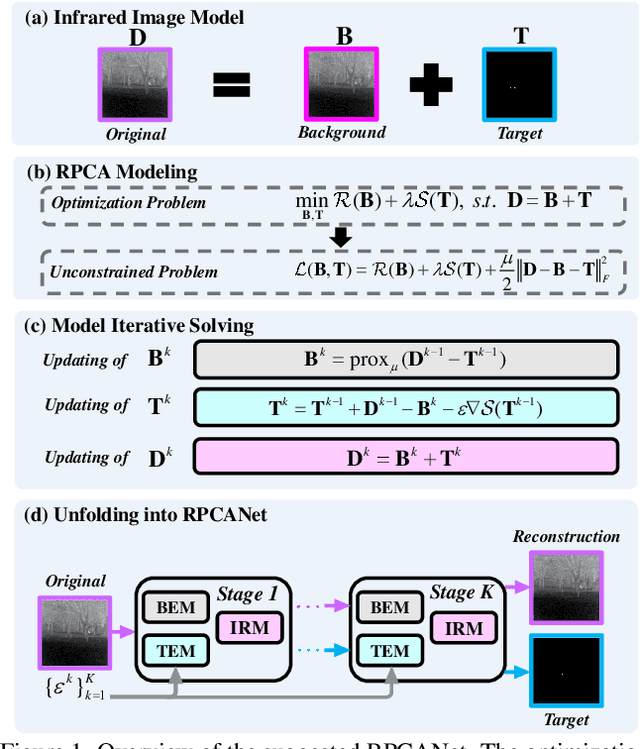
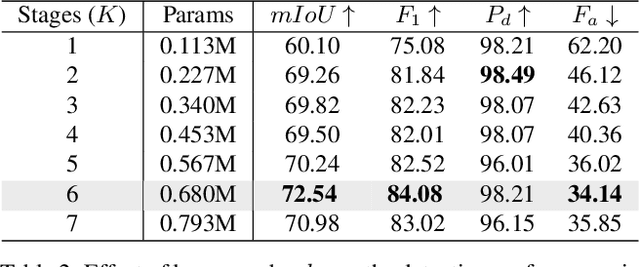
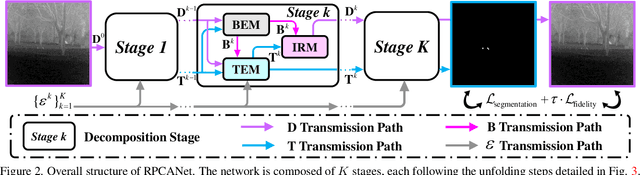
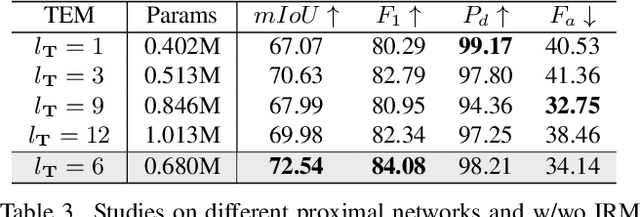
Deep learning (DL) networks have achieved remarkable performance in infrared small target detection (ISTD). However, these structures exhibit a deficiency in interpretability and are widely regarded as black boxes, as they disregard domain knowledge in ISTD. To alleviate this issue, this work proposes an interpretable deep network for detecting infrared dim targets, dubbed RPCANet. Specifically, our approach formulates the ISTD task as sparse target extraction, low-rank background estimation, and image reconstruction in a relaxed Robust Principle Component Analysis (RPCA) model. By unfolding the iterative optimization updating steps into a deep-learning framework, time-consuming and complex matrix calculations are replaced by theory-guided neural networks. RPCANet detects targets with clear interpretability and preserves the intrinsic image feature, instead of directly transforming the detection task into a matrix decomposition problem. Extensive experiments substantiate the effectiveness of our deep unfolding framework and demonstrate its trustworthy results, surpassing baseline methods in both qualitative and quantitative evaluations.
Fast, multicolour optical sectioning over extended fields of view by combining interferometric SIM with machine learning
Oct 31, 2023Structured illumination can reject out-of-focus signal from a sample, enabling high-speed and high-contrast imaging over large areas with widefield detection optics. Currently, this optical-sectioning technique is limited by image reconstruction artefacts and the need for sequential imaging of multiple colour channels. We combine multicolour interferometric pattern generation with machine-learning processing, permitting high-contrast, real-time reconstruction of image data. The method is insensitive to background noise and unevenly phase-stepped illumination patterns. We validate the method in silico and demonstrate its application on diverse specimens, ranging from fixed and live biological cells to synthetic biosystems, imaging at up to 37 Hz across a 44 x 44 $\mu m^2$ field of view.
Whole-body Detection, Recognition and Identification at Altitude and Range
Nov 09, 2023In this paper, we address the challenging task of whole-body biometric detection, recognition, and identification at distances of up to 500m and large pitch angles of up to 50 degree. We propose an end-to-end system evaluated on diverse datasets, including the challenging Biometric Recognition and Identification at Range (BRIAR) dataset. Our approach involves pre-training the detector on common image datasets and fine-tuning it on BRIAR's complex videos and images. After detection, we extract body images and employ a feature extractor for recognition. We conduct thorough evaluations under various conditions, such as different ranges and angles in indoor, outdoor, and aerial scenarios. Our method achieves an average F1 score of 98.29% at IoU = 0.7 and demonstrates strong performance in recognition accuracy and true acceptance rate at low false acceptance rates compared to existing models. On a test set of 100 subjects with 444 distractors, our model achieves a rank-20 recognition accuracy of 75.13% and a TAR@1%FAR of 54.09%.