 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Effects of lead position, cardiac rhythm variation and drug-induced QT prolongation on performance of machine learning methods for ECG processing
Dec 10, 2019
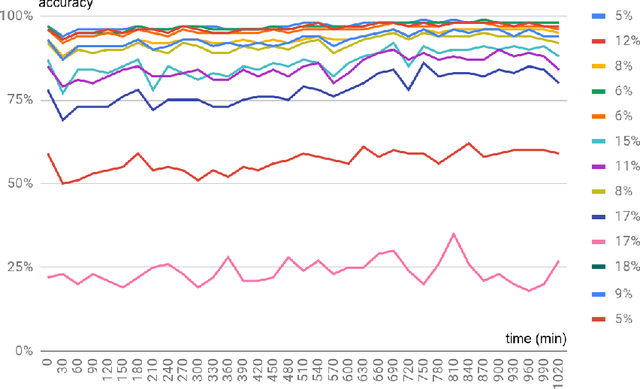
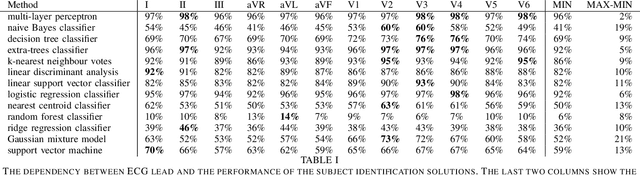
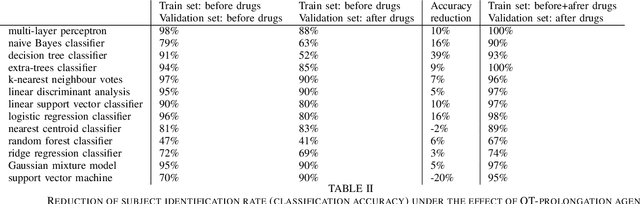
Machine learning shows great performance in various problems of electrocardiography (ECG) signal analysis. However, collecting of any dataset for biomedical engineering is a very difficult task. Any datasets for ECG processing contains from 100 to 10,000 times fewer cases than datasets for image or text analysis. This issue is especially important because of physiological phenomena that can significantly change the morphology of heartbeats in ECG signals. In this preliminary study, we analyze the effects of lead choice from the standard ECG recordings, a variation of ECG during 24-hours, and the effects of QT-prolongation agents on the performance of machine learning methods for ECG processing. We choose the problem of subject identification for analysis, because this problem may be solved for almost any available dataset of ECG data. In a discussion, we compare our findings with observations from other works that use machine learning for ECG processing with different problem statements. Our results show the importance of training dataset enrichment with ECG signals that acquired in specific physiological conditions for obtaining good performance of ECG processing for real applications.
Consensus-based Optimization for 3D Human Pose Estimation in Camera Coordinates
Nov 21, 2019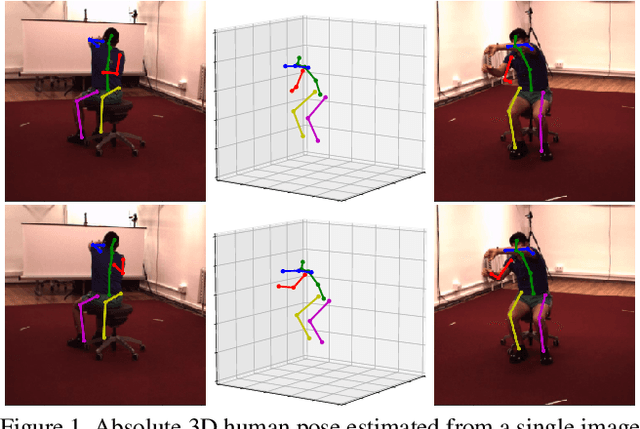
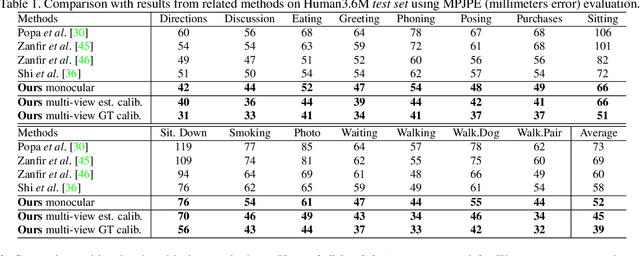
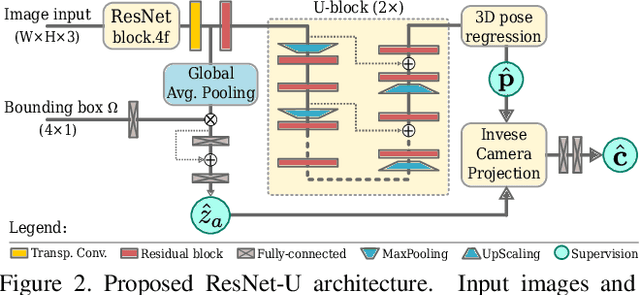
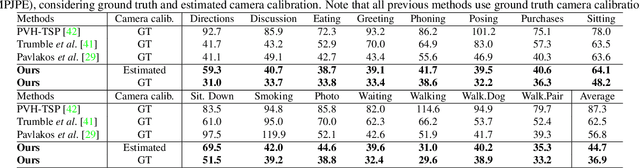
3D human pose estimation is frequently seen as the task of estimating 3D poses relative to the root body joint. Alternatively, in this paper, we propose a 3D human pose estimation method in camera coordinates, which allows effective combination of 2D annotated data and 3D poses, as well as a straightforward multi-view generalization. To that end, we cast the problem into a different perspective, where 3D poses are predicted in the image plane, in pixels, and the absolute depth is estimated in millimeters. Based on this, we propose a consensus-based optimization algorithm for multi-view predictions from uncalibrated images, which requires a single monocular training procedure. Our method improves the state-of-the-art on well known 3D human pose datasets, reducing the prediction error by 32% in the most common benchmark. In addition, we also reported our results in absolute pose position error, achieving 80mm for monocular estimations and 51mm for multi-view, on average.
Question-Agnostic Attention for Visual Question Answering
Aug 09, 2019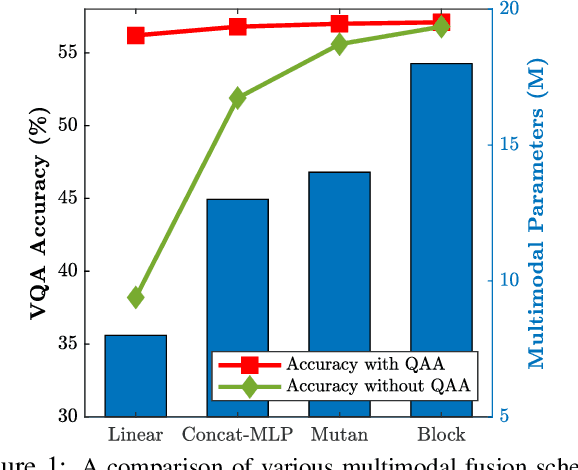
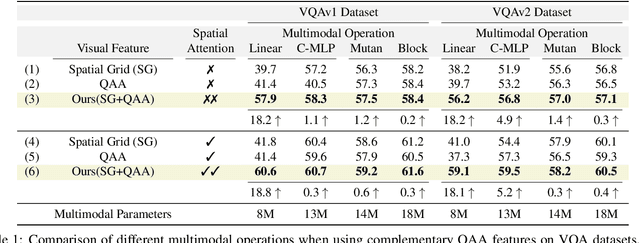
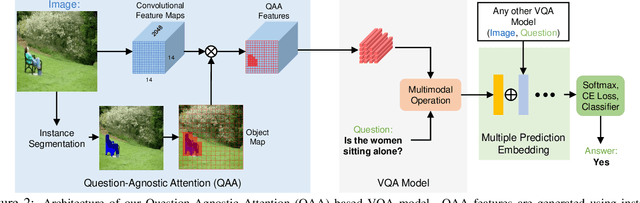
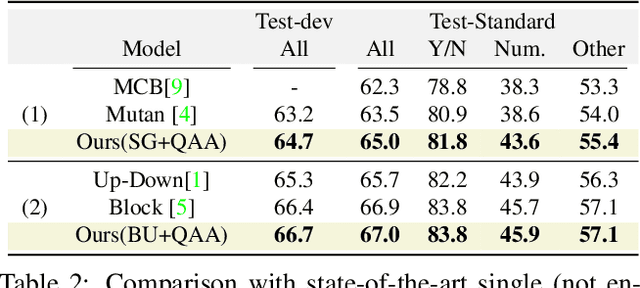
Visual Question Answering (VQA) models employ attention mechanisms to discover image locations that are most relevant for answering a specific question. For this purpose, several multimodal fusion strategies have been proposed, ranging from relatively simple operations (e.g., linear sum) to more complex ones (e.g., Block). The resulting multimodal representations define an intermediate feature space for capturing the interplay between visual and semantic features, that is helpful in selectively focusing on image content. In this paper, we propose a question-agnostic attention mechanism that is complementary to the existing question-dependent attention mechanisms. Our proposed model parses object instances to obtain an `object map' and applies this map on the visual features to generate Question-Agnostic Attention (QAA) features. In contrast to question-dependent attention approaches that are learned end-to-end, the proposed QAA does not involve question-specific training, and can be easily included in almost any existing VQA model as a generic light-weight pre-processing step, thereby adding minimal computation overhead for training. Further, when used in complement with the question-dependent attention, the QAA allows the model to focus on the regions containing objects that might have been overlooked by the learned attention representation. Through extensive evaluation on VQAv1, VQAv2 and TDIUC datasets, we show that incorporating complementary QAA allows state-of-the-art VQA models to perform better, and provides significant boost to simplistic VQA models, enabling them to performance on par with highly sophisticated fusion strategies.
Content-based Propagation of User Markings for Interactive Segmentation of Patterned Images
Sep 06, 2018

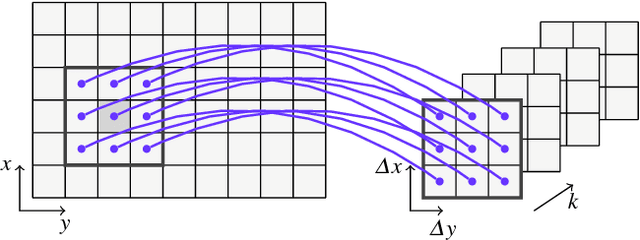
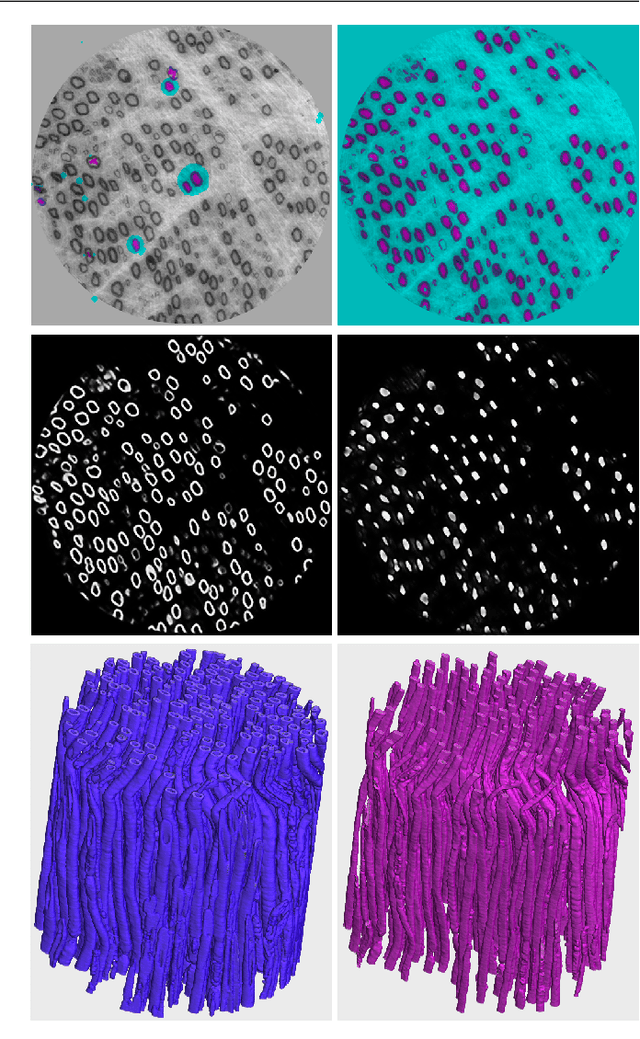
Efficient and easy segmentation of images and volumes is of great practical importance. Segmentation problems which motivate our approach originate from imaging commonly used in materials science and medicine. We formulate image segmentation as a probabilistic pixel classification problem, and we apply segmentation as a step towards characterising image content. Our method allows the user to define structures of interest by interactively marking a subset of pixels. Thanks to the real-time feedback, the user can place new markings strategically, depending on the current outcome. The final pixel classification may be obtained from a very modest user input. An important ingredient of our method is a graph that encodes image content. This graph is built in an unsupervised manner during initialisation, and is based on clustering of image features. Since we combine a limited amount of user-labelled data with the clustering information obtained from the unlabelled parts of the image, our method fits in the general framework of semi-supervised learning. We demonstrate how this can be a very efficient approach to segmentation through pixel classification.
Convolution Neural Network Architecture Learning for Remote Sensing Scene Classification
Jan 27, 2020
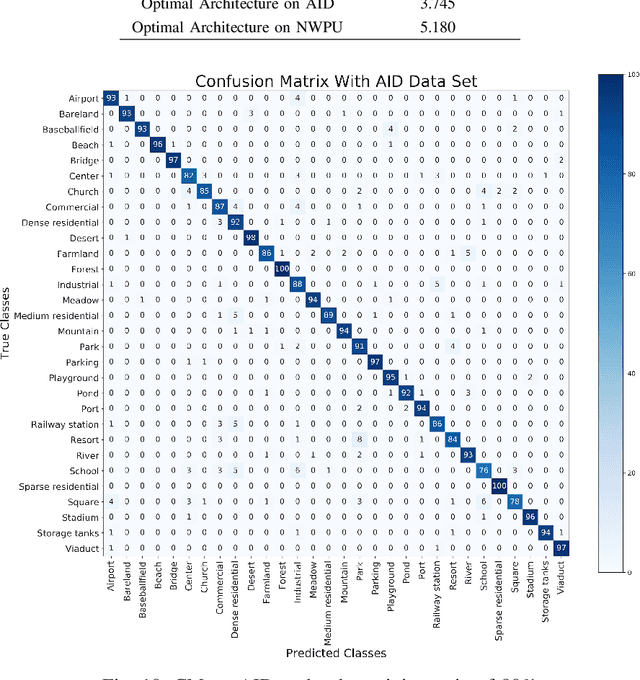
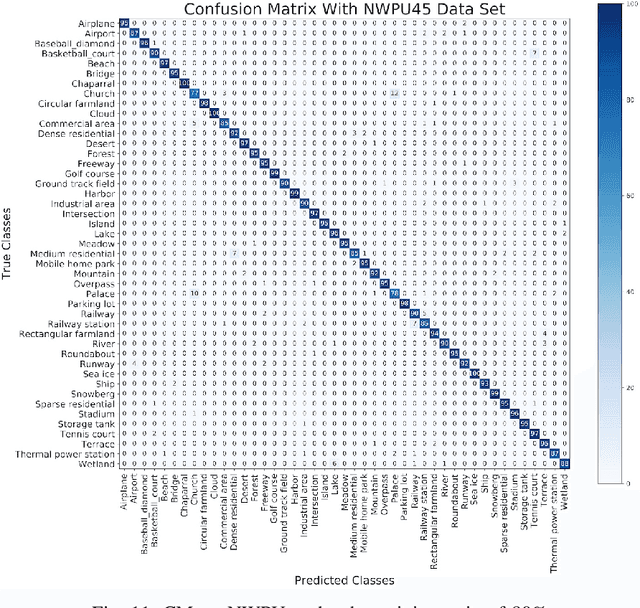
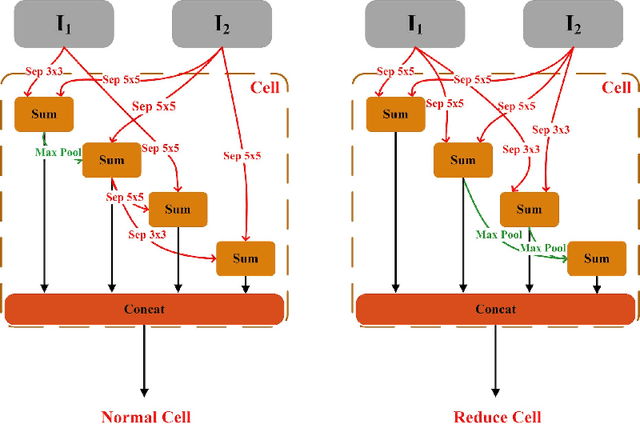
Remote sensing image scene classification is a fundamental but challenging task in understanding remote sensing images. Recently, deep learning-based methods, especially convolutional neural network-based (CNN-based) methods have shown enormous potential to understand remote sensing images. CNN-based methods meet with success by utilizing features learned from data rather than features designed manually. The feature-learning procedure of CNN largely depends on the architecture of CNN. However, most of the architectures of CNN used for remote sensing scene classification are still designed by hand which demands a considerable amount of architecture engineering skills and domain knowledge, and it may not play CNN's maximum potential on a special dataset. In this paper, we proposed an automatically architecture learning procedure for remote sensing scene classification. We designed a parameters space in which every set of parameters represents a certain architecture of CNN (i.e., some parameters represent the type of operators used in the architecture such as convolution, pooling, no connection or identity, and the others represent the way how these operators connect). To discover the optimal set of parameters for a given dataset, we introduced a learning strategy which can allow efficient search in the architecture space by means of gradient descent. An architecture generator finally maps the set of parameters into the CNN used in our experiments.
Impoved RPN for Single Targets Detection based on the Anchor Mask Net
Jun 18, 2019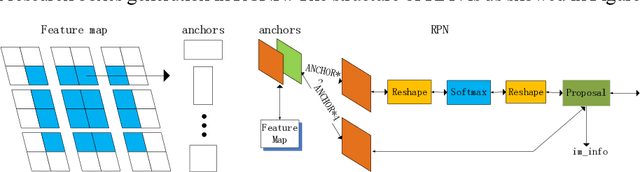

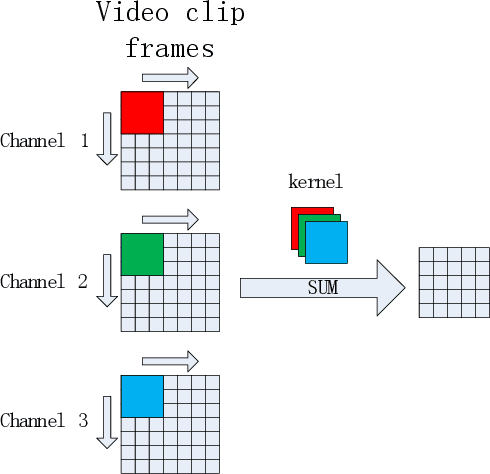
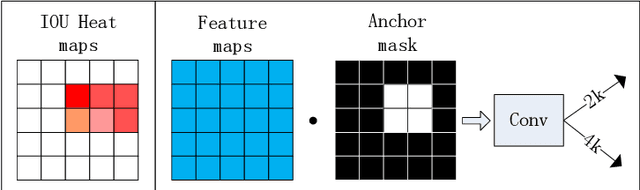
Common target detection is usually based on single frame images, which is vulnerable to affected by the similar targets in the image and not applicable to video images. In this paper , anchor mask is proposed to add the prior knowledge for target detection and an anchor mask net is designed to impove the RPN performance for single target detection. Tested in the VOT2016, the model perform better.
Self-supervised Learning of 3D Objects from Natural Images
Nov 20, 2019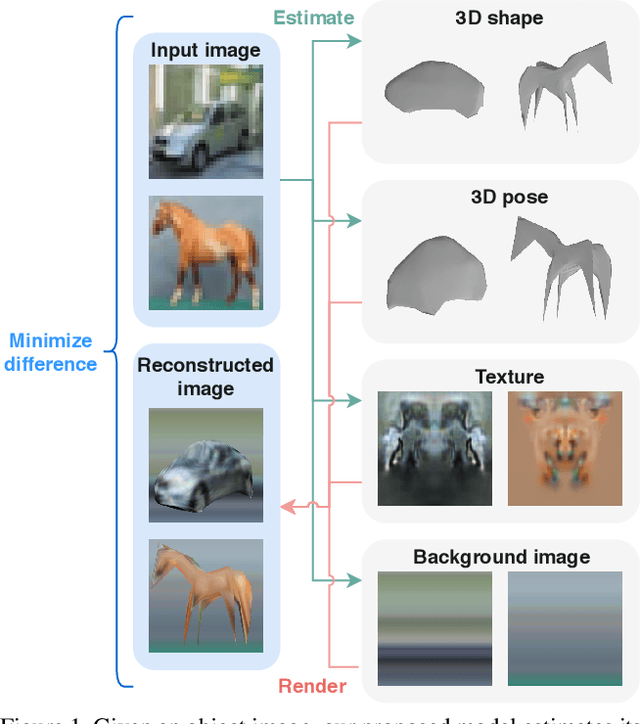
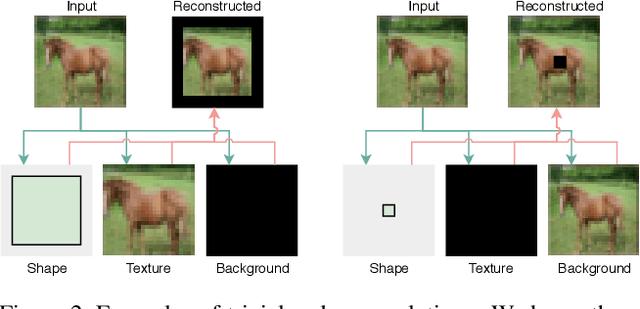
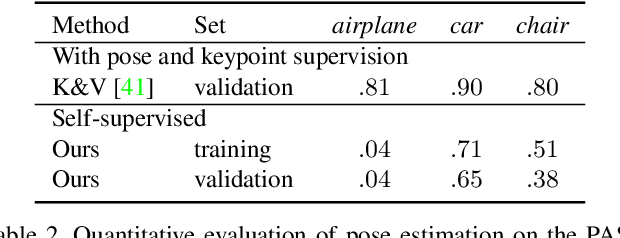
We present a method to learn single-view reconstruction of the 3D shape, pose, and texture of objects from categorized natural images in a self-supervised manner. Since this is a severely ill-posed problem, carefully designing a training method and introducing constraints are essential. To avoid the difficulty of training all elements at the same time, we propose training category-specific base shapes with fixed pose distribution and simple textures first, and subsequently training poses and textures using the obtained shapes. Another difficulty is that shapes and backgrounds sometimes become excessively complicated to mistakenly reconstruct textures on object surfaces. To suppress it, we propose using strong regularization and constraints on object surfaces and background images. With these two techniques, we demonstrate that we can use natural image collections such as CIFAR-10 and PASCAL objects for training, which indicates the possibility to realize 3D object reconstruction on diverse object categories beyond synthetic datasets.
Learning eating environments through scene clustering
Nov 10, 2019
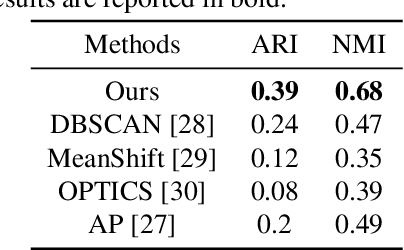
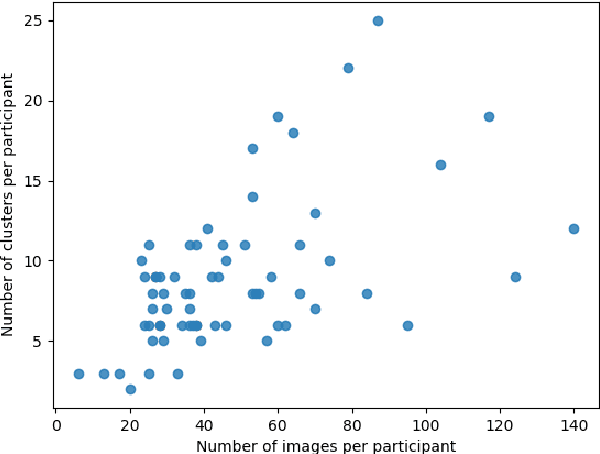
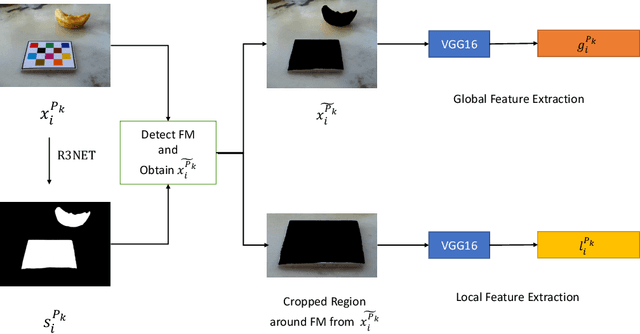
It is well known that dietary habits have a significant influence on health. While many studies have been conducted to understand this relationship, little is known about the relationship between eating environments and health. Yet researchers and health agencies around the world have recognized the eating environment as a promising context for improving diet and health. In this paper, we propose an image clustering method to automatically extract the eating environments from eating occasion images captured during a community dwelling dietary study. Specifically, we are interested in learning how many different environments an individual consumes food in. Our method clusters images by extracting features at both global and local scales using a deep neural network. The variation in the number of clusters and images captured by different individual makes this a very challenging problem. Experimental results show that our method performs significantly better compared to several existing clustering approaches.
Picture What you Read
Sep 09, 2019
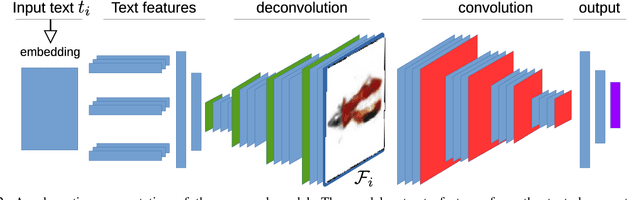

Visualization refers to our ability to create an image in our head based on the text we read or the words we hear. It is one of the many skills that makes reading comprehension possible. Convolutional Neural Networks (CNN) are an excellent tool for recognizing and classifying text documents. In addition, it can generate images conditioned on natural language. In this work, we utilize CNNs capabilities to generate realistic images representative of the text illustrating the semantic concept. We conducted various experiments to highlight the capacity of the proposed model to generate representative images of the text descriptions used as input to the proposed model.
Introducing Fuzzy Layers for Deep Learning
Feb 21, 2020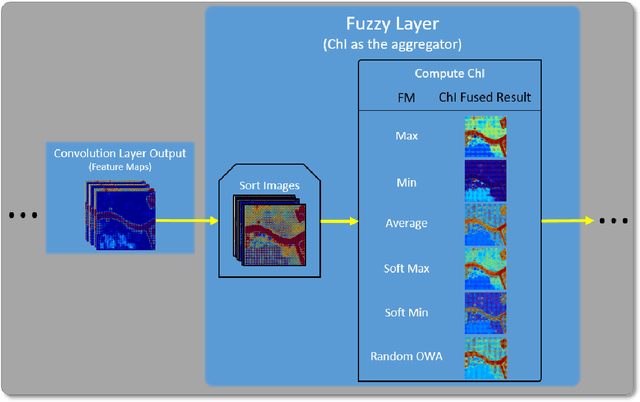

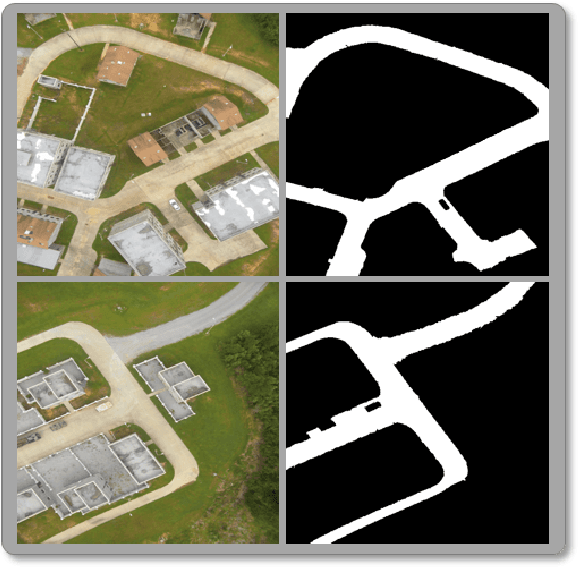
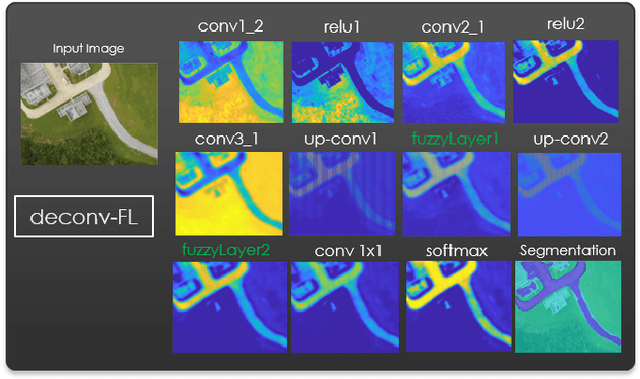
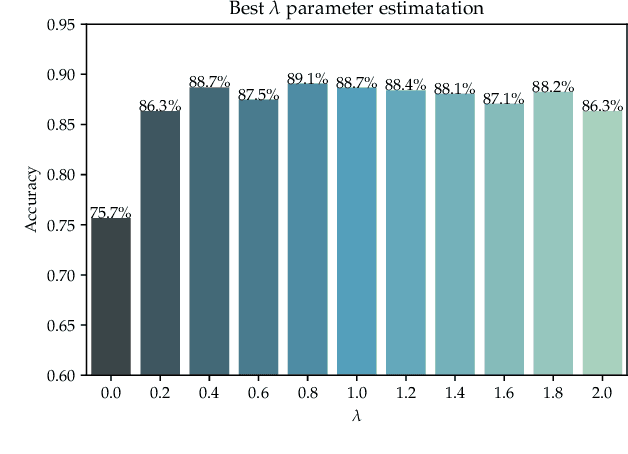
Many state-of-the-art technologies developed in recent years have been influenced by machine learning to some extent. Most popular at the time of this writing are artificial intelligence methodologies that fall under the umbrella of deep learning. Deep learning has been shown across many applications to be extremely powerful and capable of handling problems that possess great complexity and difficulty. In this work, we introduce a new layer to deep learning: the fuzzy layer. Traditionally, the network architecture of neural networks is composed of an input layer, some combination of hidden layers, and an output layer. We propose the introduction of fuzzy layers into the deep learning architecture to exploit the powerful aggregation properties expressed through fuzzy methodologies, such as the Choquet and Sugueno fuzzy integrals. To date, fuzzy approaches taken to deep learning have been through the application of various fusion strategies at the decision level to aggregate outputs from state-of-the-art pre-trained models, e.g., AlexNet, VGG16, GoogLeNet, Inception-v3, ResNet-18, etc. While these strategies have been shown to improve accuracy performance for image classification tasks, none have explored the use of fuzzified intermediate, or hidden, layers. Herein, we present a new deep learning strategy that incorporates fuzzy strategies into the deep learning architecture focused on the application of semantic segmentation using per-pixel classification. Experiments are conducted on a benchmark data set as well as a data set collected via an unmanned aerial system at a U.S. Army test site for the task of automatic road segmentation, and preliminary results are promising.
* 6 pages, 4 figures, published in 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE)