 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Agnostic Attention for Visual Question Answering
Aug 09, 2019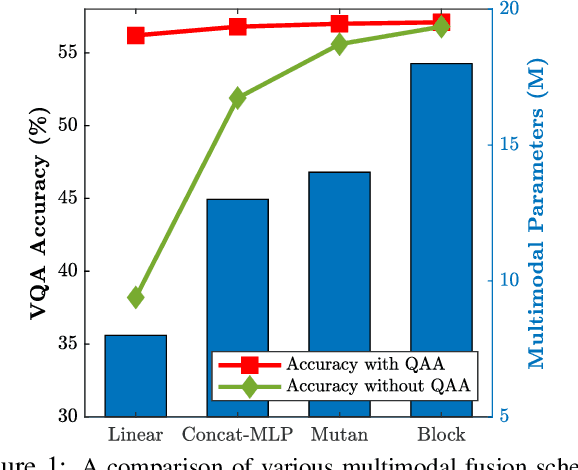
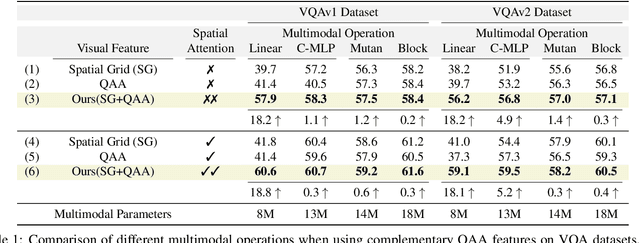
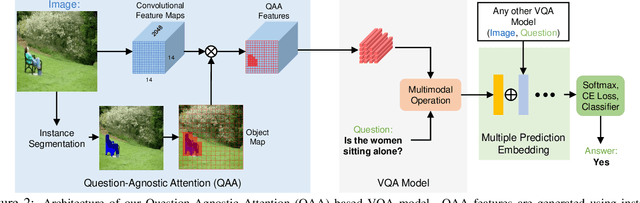
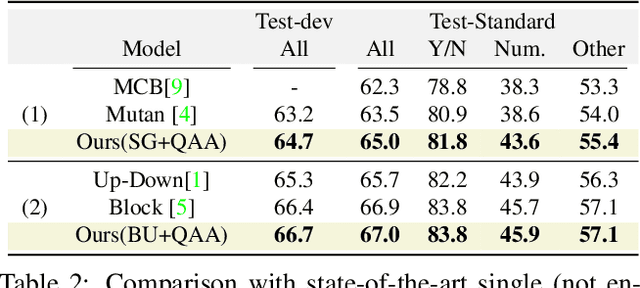
Visual Question Answering (VQA) models employ attention mechanisms to discover image locations that are most relevant for answering a specific question. For this purpose, several multimodal fusion strategies have been proposed, ranging from relatively simple operations (e.g., linear sum) to more complex ones (e.g., Block). The resulting multimodal representations define an intermediate feature space for capturing the interplay between visual and semantic features, that is helpful in selectively focusing on image content. In this paper, we propose a question-agnostic attention mechanism that is complementary to the existing question-dependent attention mechanisms. Our proposed model parses object instances to obtain an `object map' and applies this map on the visual features to generate Question-Agnostic Attention (QAA) features. In contrast to question-dependent attention approaches that are learned end-to-end, the proposed QAA does not involve question-specific training, and can be easily included in almost any existing VQA model as a generic light-weight pre-processing step, thereby adding minimal computation overhead for training. Further, when used in complement with the question-dependent attention, the QAA allows the model to focus on the regions containing objects that might have been overlooked by the learned attention representation. Through extensive evaluation on VQAv1, VQAv2 and TDIUC datasets, we show that incorporating complementary QAA allows state-of-the-art VQA models to perform better, and provides significant boost to simplistic VQA models, enabling them to performance on par with highly sophisticated fusion strategies.
From Known to the Unknown: Transferring Knowledge to Answer Questions about Novel Visual and Semantic Concepts
Nov 30, 2018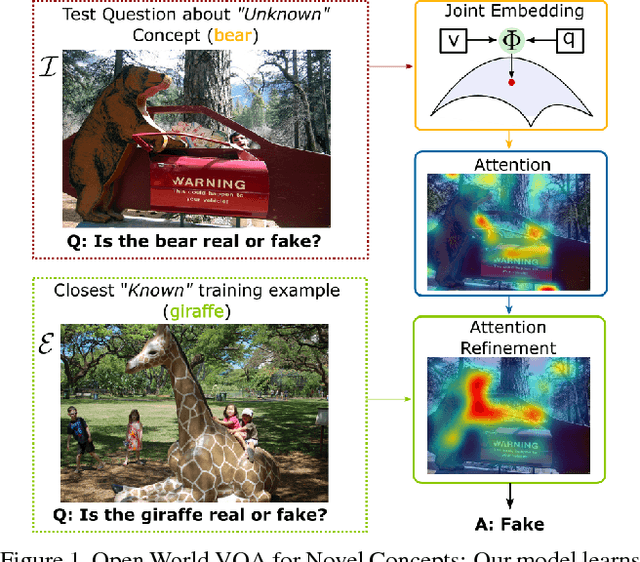
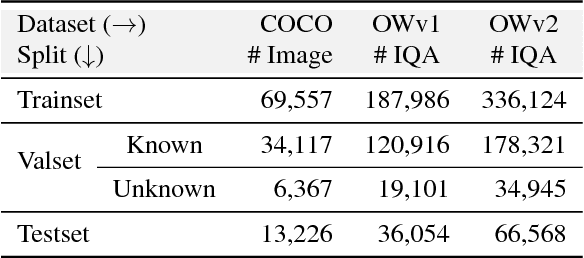
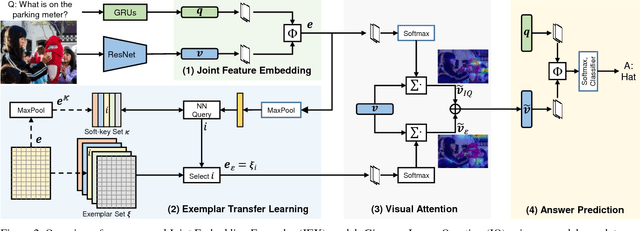
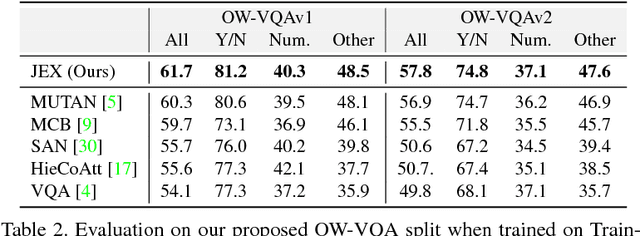
Current Visual Question Answering (VQA) systems can answer intelligent questions about `Known' visual content. However, their performance drops significantly when questions about visually and linguistically `Unknown' concepts are presented during inference (`Open-world' scenario). A practical VQA system should be able to deal with novel concepts in real world settings. To address this problem, we propose an exemplar-based approach that transfers learning (i.e., knowledge) from previously `Known' concepts to answer questions about the `Unknown'. We learn a highly discriminative joint embedding space, where visual and semantic features are fused to give a unified representation. Once novel concepts are presented to the model, it looks for the closest match from an exemplar set in the joint embedding space. This auxiliary information is used alongside the given Image-Question pair to refine visual attention in a hierarchical fashion. Since handling the high dimensional exemplars on large datasets can be a significant challenge, we introduce an efficient matching scheme that uses a compact feature description for search and retrieval. To evaluate our model, we propose a new split for VQA, separating Unknown visual and semantic concepts from the training set. Our approach shows significant improvements over state-of-the-art VQA models on the proposed Open-World VQA dataset and standard VQA datasets.
Reciprocal Attention Fusion for Visual Question Answering
Jul 22, 2018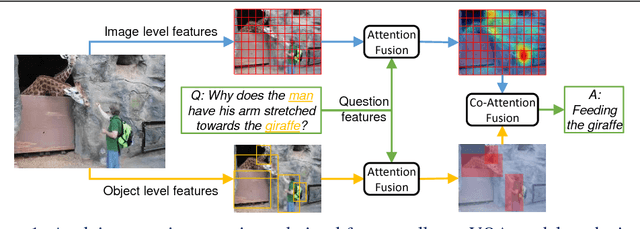
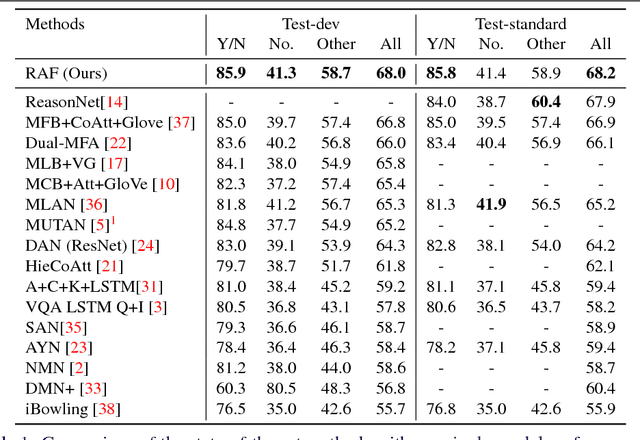
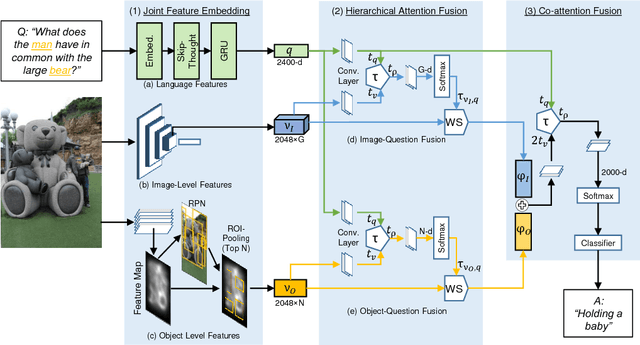
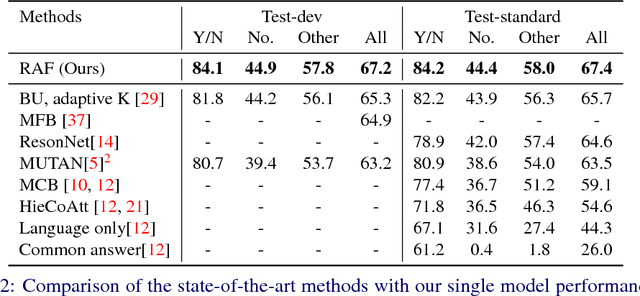
Existing attention mechanisms either attend to local image grid or object level features for Visual Question Answering (VQA). Motivated by the observation that questions can relate to both object instances and their parts, we propose a novel attention mechanism that jointly considers reciprocal relationships between the two levels of visual details. The bottom-up attention thus generated is further coalesced with the top-down information to only focus on the scene elements that are most relevant to a given question. Our design hierarchically fuses multi-modal information i.e., language, object- and gird-level features, through an efficient tensor decomposition scheme. The proposed model improves the state-of-the-art single model performances from 67.9% to 68.2% on VQAv1 and from 65.7% to 67.4% on VQAv2, demonstrating a significant boost.
Indoor Scene Understanding in 2.5/3D: A Survey
Mar 09, 2018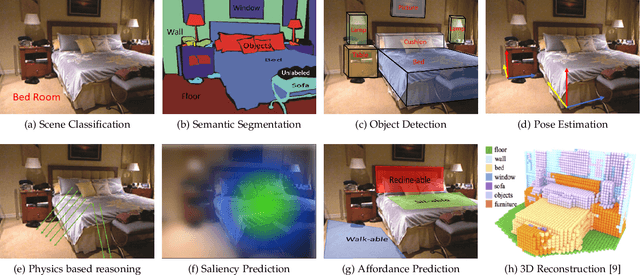
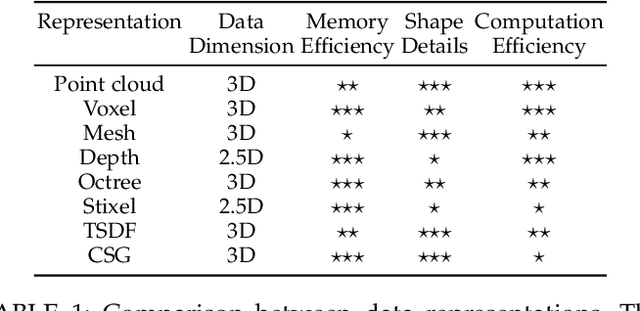
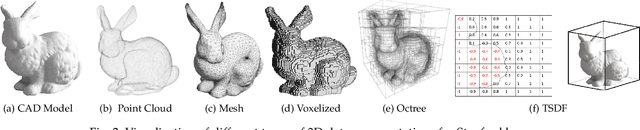
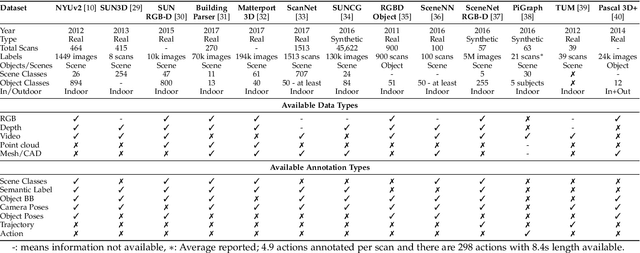
With the availability of low-cost and compact 2.5/3D visual sensing devices, computer vision community is experiencing a growing interest in visual scene understanding. This survey paper provides a comprehensive background to this research topic. We begin with a historical perspective, followed by popular 3D data representations and a comparative analysis of available datasets. Before delving into the application specific details, this survey provides a succinct introduction to the core technologies that are the underlying methods extensively used in the literature. Afterwards, we review the developed techniques according to a taxonomy based on the scene understanding tasks. This covers holistic indoor scene understanding as well as subtasks such as scene classification, object detection, pose estimation, semantic segmentation, 3D reconstruction, saliency detection, physics-based reasoning and affordance prediction. Later on, we summarize the performance metrics used for evaluation in different tasks and a quantitative comparison among the recent state-of-the-art techniques. We conclude this review with the current challenges and an outlook towards the open research problems requiring further investigation.
Learning deep structured network for weakly supervised change detection
May 23, 2017
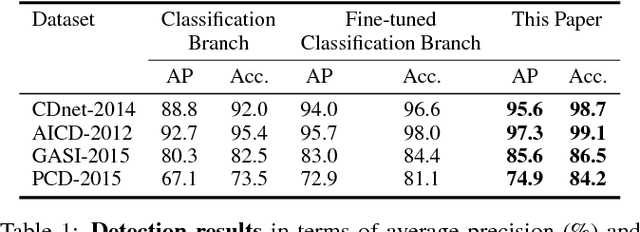
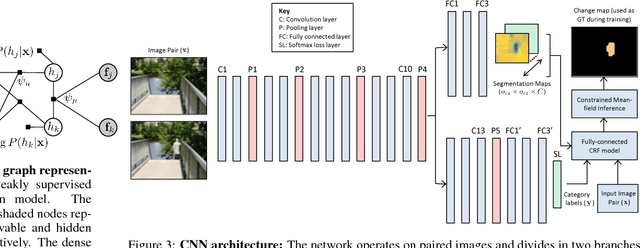
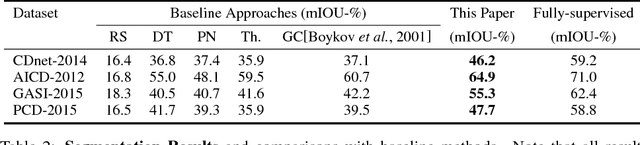
Conventional change detection methods require a large number of images to learn background models or depend on tedious pixel-level labeling by humans. In this paper, we present a weakly supervised approach that needs only image-level labels to simultaneously detect and localize changes in a pair of images. To this end, we employ a deep neural network with DAG topology to learn patterns of change from image-level labeled training data. On top of the initial CNN activations, we define a CRF model to incorporate the local differences and context with the dense connections between individual pixels. We apply a constrained mean-field algorithm to estimate the pixel-level labels, and use the estimated labels to update the parameters of the CNN in an iterative EM framework. This enables imposing global constraints on the observed foreground probability mass function. Our evaluations on four benchmark datasets demonstrate superior detection and localization performance.