 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continuous Meta-Learning without Tasks
Dec 18, 2019
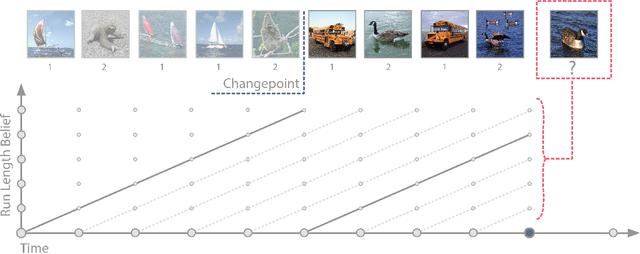
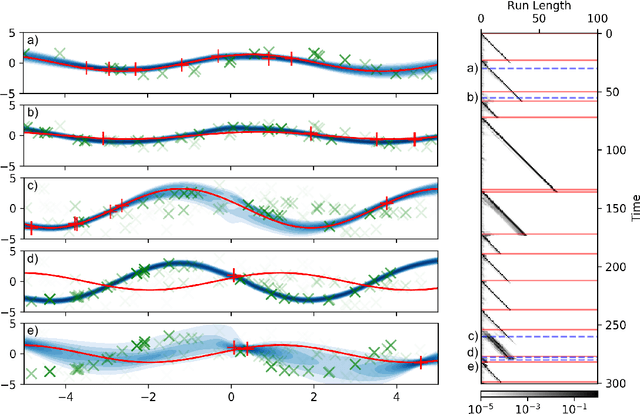

Meta-learning is a promising strategy for learning to efficiently learn within new tasks, using data gathered from a distribution of tasks. However, the meta-learning literature thus far has focused on the task segmented setting, where at train-time, offline data is assumed to be split according to the underlying task, and at test-time, the algorithms are optimized to learn in a single task. In this work, we enable the application of generic meta-learning algorithms to settings where this task segmentation is unavailable, such as continual online learning with a time-varying task. We present meta-learning via online changepoint analysis (MOCA), an approach which augments a meta-learning algorithm with a differentiable Bayesian changepoint detection scheme. The framework allows both training and testing directly on time series data without segmenting it into discrete tasks. We demonstrate the utility of this approach on a nonlinear meta-regression benchmark as well as two meta-image-classification benchmarks.
FUNN: Flexible Unsupervised Neural Network
Nov 05, 2018
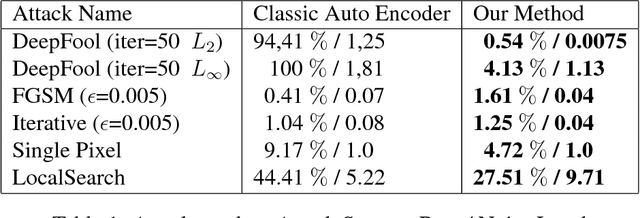

Deep neural networks have demonstrated high accuracy in image classification tasks. However, they were shown to be weak against adversarial examples: a small perturbation in the image which changes the classification output dramatically. In recent years, several defenses have been proposed to solve this issue in supervised classification tasks. We propose a method to obtain robust features in unsupervised learning tasks against adversarial attacks. Our method differs from existing solutions by directly learning the robust features without the need to project the adversarial examples in the original examples distribution space. A first auto-encoder A1 is in charge of perturbing the input image to fool another auto-encoder A2 which is in charge of regenerating the original image. A1 tries to find the less perturbed image under the constraint that the error in the output of A2 should be at least equal to a threshold. Thanks to this training, the encoder of A2 will be robust against adversarial attacks and could be used in different tasks like classification. Using state-of-art network architectures, we demonstrate the robustness of the features obtained thanks to this method in classification tasks.
Things You May Not Know About Adversarial Example: A Black-box Adversarial Image Attack
May 21, 2019

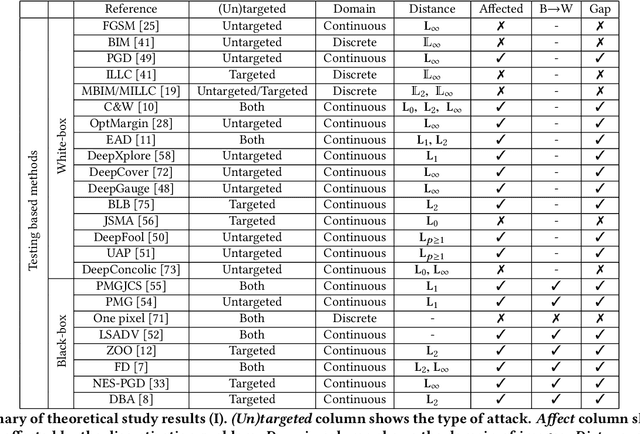
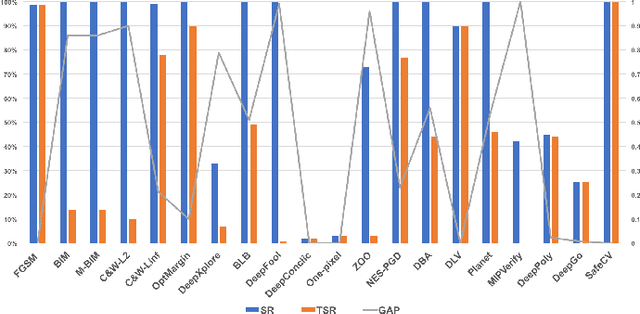
Numerous methods for crafting adversarial examples were proposed recently with high success rate. Most existing works normalize images into a continuous, real vector, domain firstly, and then craft adversarial examples in this domain. However, "adversarial" examples may become benign after de-normalizing them back into the discrete integer domain, known as the discretization problem. The discretization problem was mentioned in some work, but was underestimated and has received relatively little attention. In this work, we conduct the first comprehensive study of the discretization problem. We theoretically analyze 34 representative methods and empirically study 20 representative open source tools for crafting adversarial images. Our study reveals that almost all existing works suffer from the discretization problem and it is far more serious than originally thought. For instance, most black-box methods downgrade to white-box ones and methods having higher success rates drop down to lower high success rates, e.g., from 100% to 10%. This suggests that the discretization problem should be taken into account when crafting adversarial examples. As a first step towards addressing this problem, we propose a black-box method which reduces the adversarial example searching problem to a derivative-free optimization problem. Our method is able to craft `real' adversarial images by derivative-free search on the discrete integer domain. Experimental results show that our method achieves significantly higher success rate in terms of adversarial examples in the discrete integer domain than most other methods, no matter white-box or black-box. Moreover, our method is able to handle models that is non-differentiable and we successfully break the winner of NIPS 17 competition on defense with 95% success rate.
Capsule GAN Using Capsule Network for Generator Architecture
Mar 18, 2020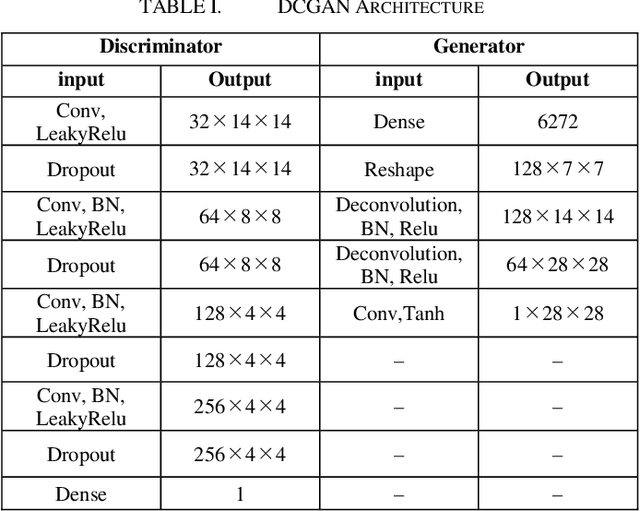
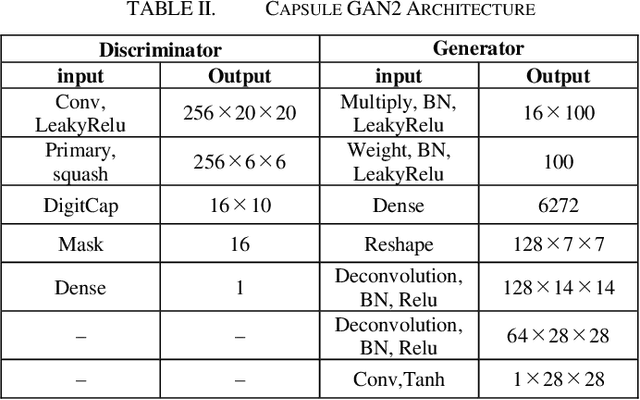
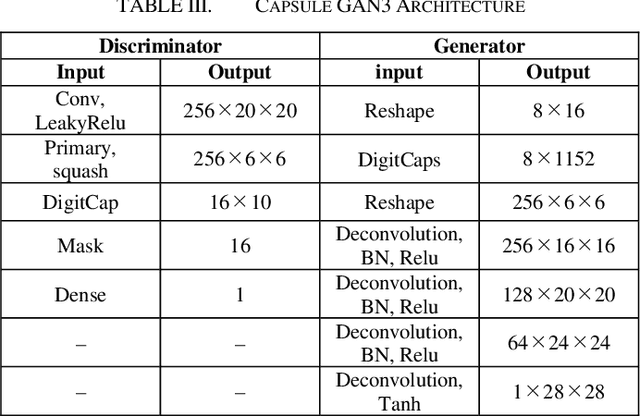

This paper presents Capsule GAN, a Generative adversarial network using Capsule Network not only in the discriminator but also in the generator. Recently, Generative adversarial networks (GANs) has been intensively studied. However, generating images by GANs is difficult. Therefore, GANs sometimes generate poor quality images. These GANs use convolutional neural networks (CNNs). However, CNNs have the defect that the relational information between features of the image may be lost. Capsule Network, proposed by Hinton in 2017, overcomes the defect of CNNs. Capsule GAN reported previously uses Capsule Network in the discriminator. However, instead of using Capsule Network, Capsule GAN reported in previous studies uses CNNs in generator architecture like DCGAN. This paper introduces two approaches to use Capsule Network in the generator. One is to use DigitCaps layer from the discriminator as the input to the generator. DigitCaps layer is the output layer of Capsule Network. It has the features of the input images of the discriminator. The other is to use the reverse operation of recognition process in Capsule Network in the generator. We compare Capsule GAN proposed in this paper with conventional GAN using CNN and Capsule GAN which uses Capsule Network in the discriminator only. The datasets are MNIST, Fashion-MNIST and color images. We show that Capsule GAN outperforms the GAN using CNN and the GAN using Capsule Network in the discriminator only. The architecture of Capsule GAN proposed in this paper is a basic architecture using Capsule Network. Therefore, we can apply the existing improvement techniques for GANs to Capsule GAN.
Identifying Reliable Annotations for Large Scale Image Segmentation
Apr 28, 2015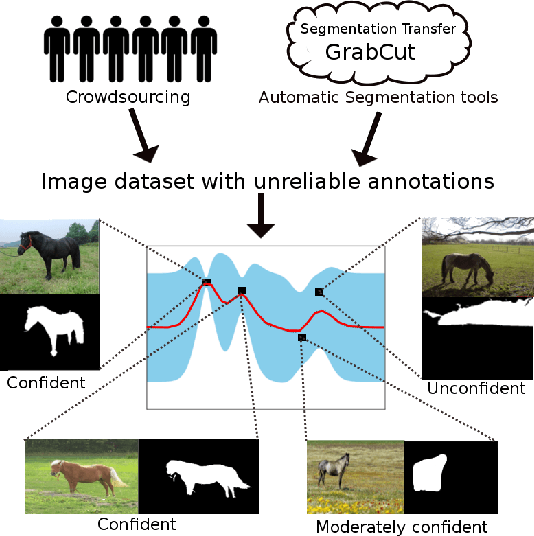
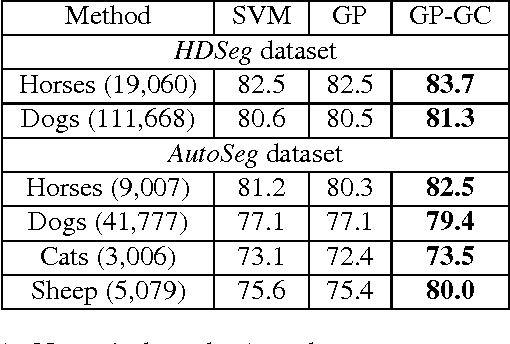

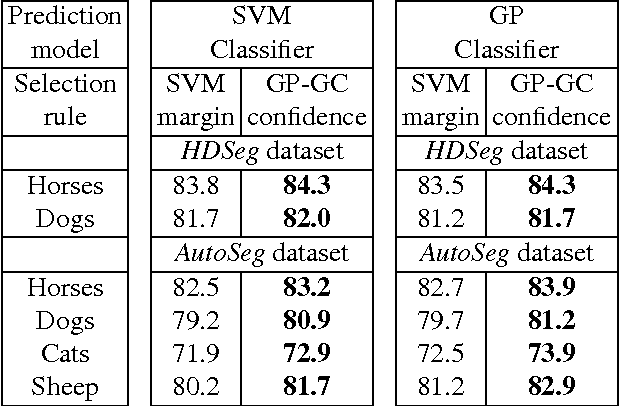
Challenging computer vision tasks, in particular semantic image segmentation, require large training sets of annotated images. While obtaining the actual images is often unproblematic, creating the necessary annotation is a tedious and costly process. Therefore, one often has to work with unreliable annotation sources, such as Amazon Mechanical Turk or (semi-)automatic algorithmic techniques. In this work, we present a Gaussian process (GP) based technique for simultaneously identifying which images of a training set have unreliable annotation and learning a segmentation model in which the negative effect of these images is suppressed. Alternatively, the model can also just be used to identify the most reliably annotated images from the training set, which can then be used for training any other segmentation method. By relying on "deep features" in combination with a linear covariance function, our GP can be learned and its hyperparameter determined efficiently using only matrix operations and gradient-based optimization. This makes our method scalable even to large datasets with several million training instances.
BiRA-Net: Bilinear Attention Net for Diabetic Retinopathy Grading
May 15, 2019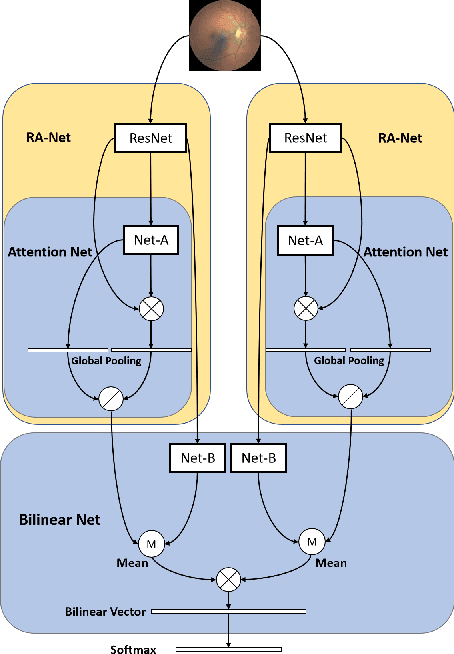
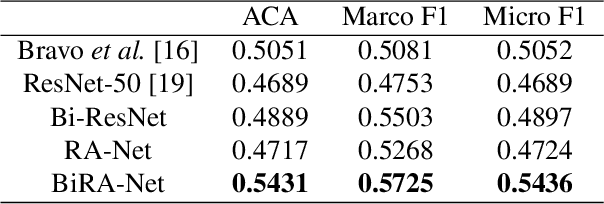


Diabetic retinopathy (DR) is a common retinal disease that leads to blindness. For diagnosis purposes, DR image grading aims to provide automatic DR grade classification, which is not addressed in conventional research methods of binary DR image classification. Small objects in the eye images, like lesions and microaneurysms, are essential to DR grading in medical imaging, but they could easily be influenced by other objects. To address these challenges, we propose a new deep learning architecture, called BiRA-Net, which combines the attention model for feature extraction and bilinear model for fine-grained classification. Furthermore, in considering the distance between different grades of different DR categories, we propose a new loss function, called grading loss, which leads to improved training convergence of the proposed approach. Experimental results are provided to demonstrate the superior performance of the proposed approach.
Gradient-based training of Gaussian Mixture Models in High-Dimensional Spaces
Dec 18, 2019
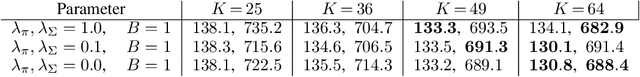
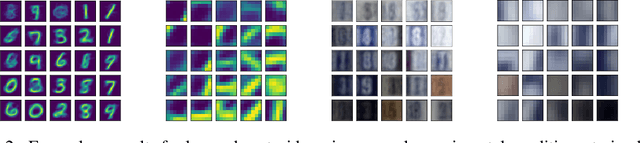

We present an approach for efficiently training Gaussian Mixture Models (GMMs) with Stochastic Gradient Descent (SGD) on large amounts of high-dimensional data (e.g., images). In such a scenario, SGD is strongly superior in terms of execution time and memory usage, although it is conceptually more complex than the traditional Expectation-Maximization (EM) algorithm. For enabling SGD training, we propose three novel ideas: First, we show that minimizing an upper bound to the GMM log likelihood instead of the full one is feasible and numerically much more stable way in high-dimensional spaces. Secondly, we propose a new annealing procedure that prevents SGD from converging to pathological local minima. We also propose an SGD-compatible simplification to the full GMM model based on local principal directions, which avoids excessive memory use in high-dimensional spaces due to quadratic growth of covariance matrices. Experiments on several standard image datasets show the validity of our approach, and we provide a publicly available TensorFlow implementation.
Anatomy-Aware Self-supervised Fetal MRI Synthesis from Unpaired Ultrasound Images
Sep 08, 2019

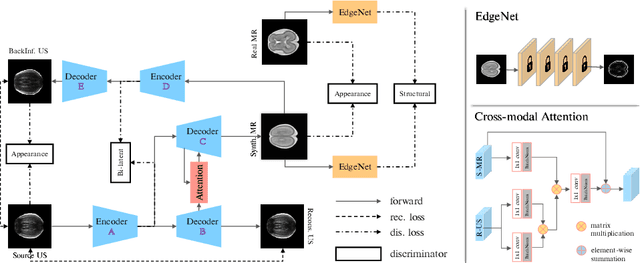
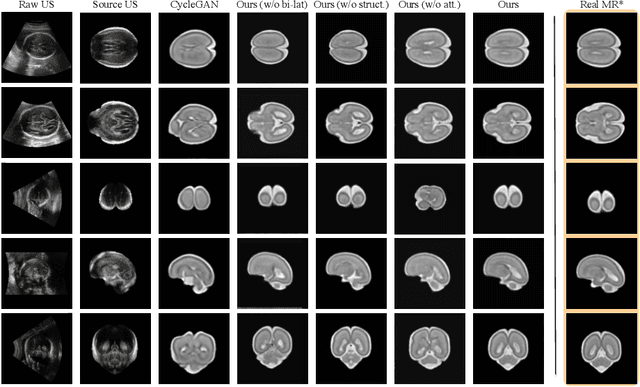
Fetal brain magnetic resonance imaging (MRI) offers exquisite images of the developing brain but is not suitable for anomaly screening. For this ultrasound (US) is employed. While expert sonographers are adept at reading US images, MR images are much easier for non-experts to interpret. Hence in this paper we seek to produce images with MRI-like appearance directly from clinical US images. Our own clinical motivation is to seek a way to communicate US findings to patients or clinical professionals unfamiliar with US, but in medical image analysis such a capability is potentially useful, for instance, for US-MRI registration or fusion. Our model is self-supervised and end-to-end trainable. Specifically, based on an assumption that the US and MRI data share a similar anatomical latent space, we first utilise an extractor to determine shared latent features, which are then used for data synthesis. Since paired data was unavailable for our study (and rare in practice), we propose to enforce the distributions to be similar instead of employing pixel-wise constraints, by adversarial learning in both the image domain and latent space. Furthermore, we propose an adversarial structural constraint to regularise the anatomical structures between the two modalities during the synthesis. A cross-modal attention scheme is proposed to leverage non-local spatial correlations. The feasibility of the approach to produce realistic looking MR images is demonstrated quantitatively and with a qualitative evaluation compared to real fetal MR images.
Live Illumination Decomposition of Videos
Aug 06, 2019
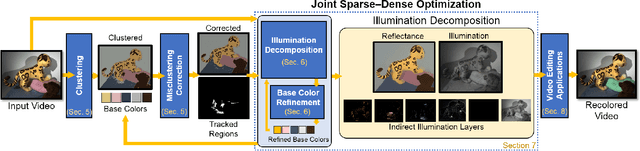
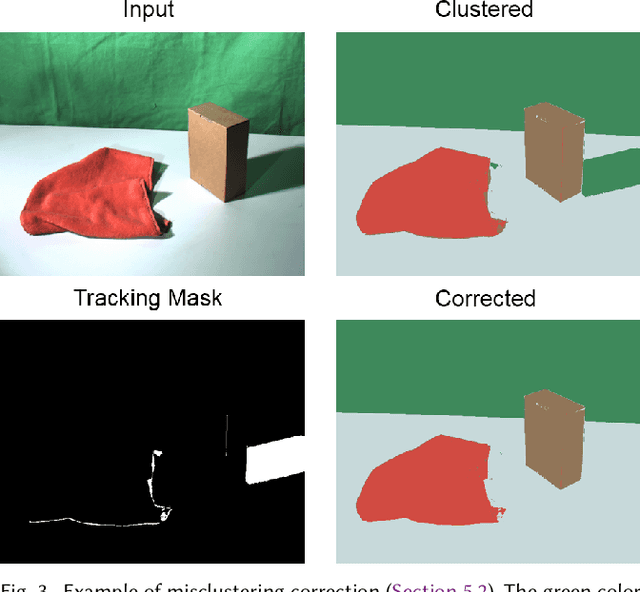
We propose the first approach for the decomposition of a monocular color video into direct and indirect illumination components in real-time. We retrieve, in separate layers, the contribution made to the scene appearance by the scene reflectance, the light sources and the reflections from various coherent scene regions to one another. Existing techniques that invert global light transport require image capture under multiplexed controlled lighting, or only enable the decomposition of a single image at slow off-line frame rates. In contrast, our approach works for regular videos and produces temporally coherent decomposition layers at real-time frame rates. At the core of our approach are several sparsity priors that enable the estimation of the per-pixel direct and indirect illumination layers based on a small set of jointly estimated base reflectance colors. The resulting variational decomposition problem uses a new formulation based on sparse and dense sets of non-linear equations that we solve efficiently using a novel alternating data-parallel optimization strategy. We evaluate our approach qualitatively and quantitatively, and show improvements over the state of the art in this field, in both quality and runtime. In addition, we demonstrate various real-time appearance editing applications for videos with consistent illumination.
Graph4Code: A Machine Interpretable Knowledge Graph for Code
Feb 21, 2020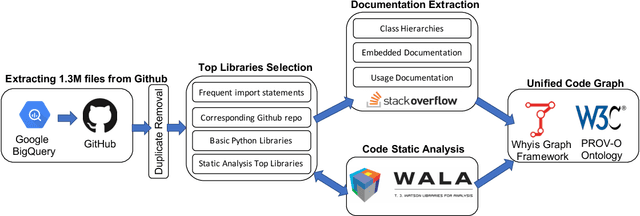
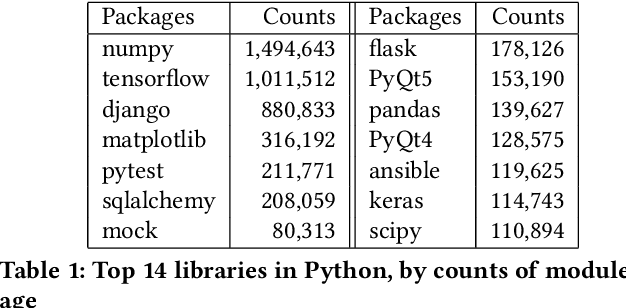
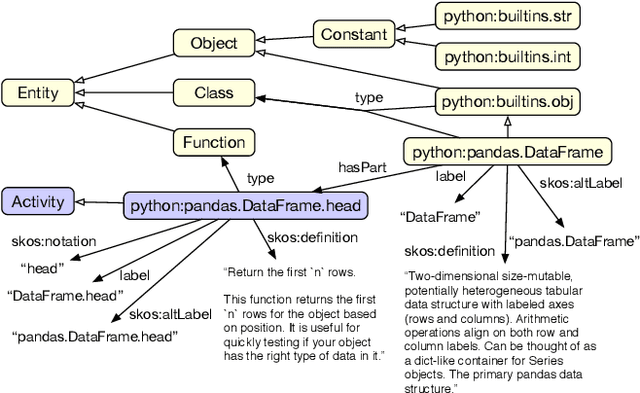

Knowledge graphs have proven to be extremely useful in powering diverse applications in semantic search, natural language understanding, and even image classification. Graph4Code attempts to build well structured knowledge graphs about program code to similarly revolutionize diverse applications such as code search, code understanding, refactoring, bug detection, and code automation. We build such a graph by applying a set of generic code analysis techniques to Python code on the web. Since use of popular Python modules is ubiquitous in code, calls to functions in Python modules serve as key nodes of the knowledge graph. The edges in the graph are based on 1) function usage in the wild (e.g., which other function tends to call this one, or which function tends to precede this one, as gleaned from program analysis), 2) documentation about the function (e.g., code documentation, usage documentation, or forum discussions such as StackOverflow), and 3) program specific features such as class hierarchies. We use the Whyis knowledge graph management framework to make the graph easily extensible. We apply these techniques to 1.3M Python files drawn from GitHub, and associated documentation on the web for over 400 popular libraries, as well as StackOverflow posts about the same set of libraries. This knowledge graph will be made available soon to the larger community for use.