 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Deep Learning Based Fast Image Saliency Detection Algorithm
Feb 01, 2016
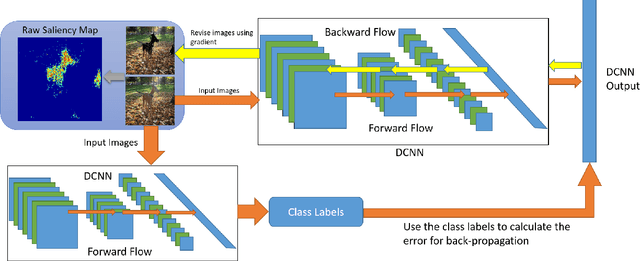

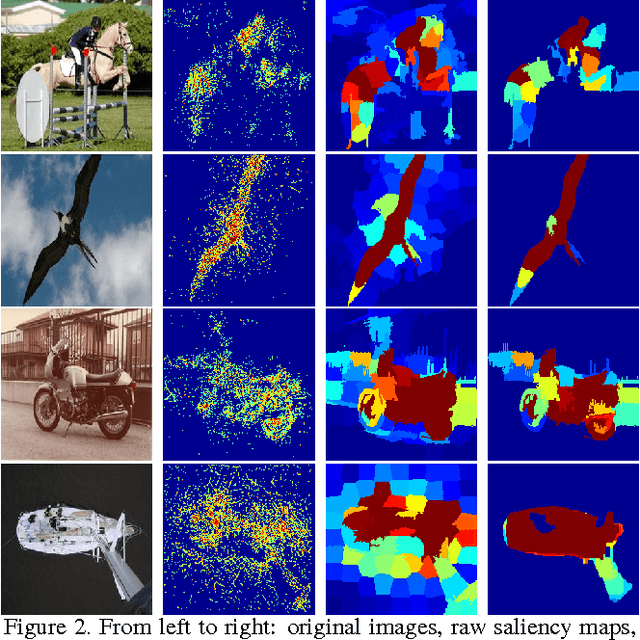

In this paper, we propose a fast deep learning method for object saliency detection using convolutional neural networks. In our approach, we use a gradient descent method to iteratively modify the input images based on the pixel-wise gradients to reduce a pre-defined cost function, which is defined to measure the class-specific objectness and clamp the class-irrelevant outputs to maintain image background. The pixel-wise gradients can be efficiently computed using the back-propagation algorithm. We further apply SLIC superpixels and LAB color based low level saliency features to smooth and refine the gradients. Our methods are quite computationally efficient, much faster than other deep learning based saliency methods. Experimental results on two benchmark tasks, namely Pascal VOC 2012 and MSRA10k, have shown that our proposed methods can generate high-quality salience maps, at least comparable with many slow and complicated deep learning methods. Comparing with the pure low-level methods, our approach excels in handling many difficult images, which contain complex background, highly-variable salient objects, multiple objects, and/or very small salient objects.
Feature Pyramid Hashing
Apr 04, 2019
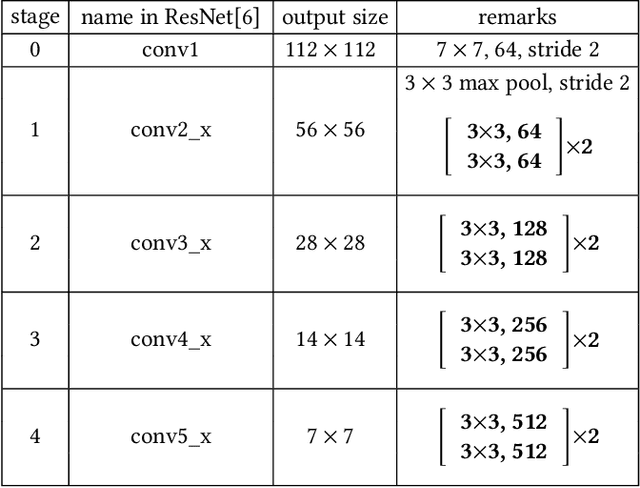
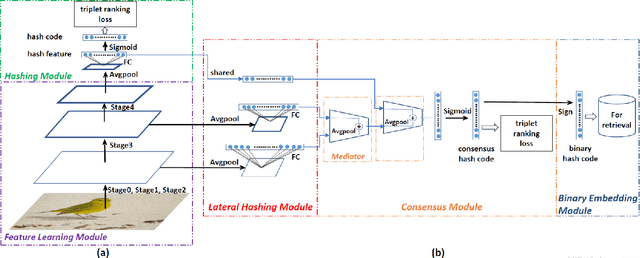
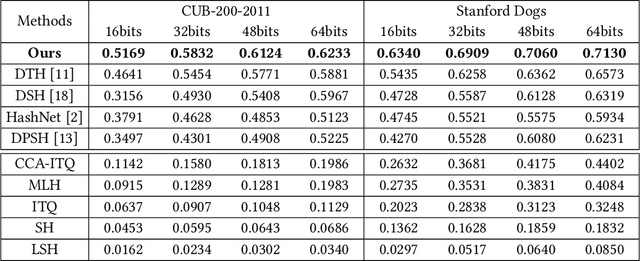
In recent years, deep-networks-based hashing has become a leading approach for large-scale image retrieval. Most deep hashing approaches use the high layer to extract the powerful semantic representations. However, these methods have limited ability for fine-grained image retrieval because the semantic features extracted from the high layer are difficult in capturing the subtle differences. To this end, we propose a novel two-pyramid hashing architecture to learn both the semantic information and the subtle appearance details for fine-grained image search. Inspired by the feature pyramids of convolutional neural network, a vertical pyramid is proposed to capture the high-layer features and a horizontal pyramid combines multiple low-layer features with structural information to capture the subtle differences. To fuse the low-level features, a novel combination strategy, called consensus fusion, is proposed to capture all subtle information from several low-layers for finer retrieval. Extensive evaluation on two fine-grained datasets CUB-200-2011 and Stanford Dogs demonstrate that the proposed method achieves significant performance compared with the state-of-art baselines.
Multi-scale fully convolutional neural networks for histopathology image segmentation: from nuclear aberrations to the global tissue architecture
Sep 24, 2019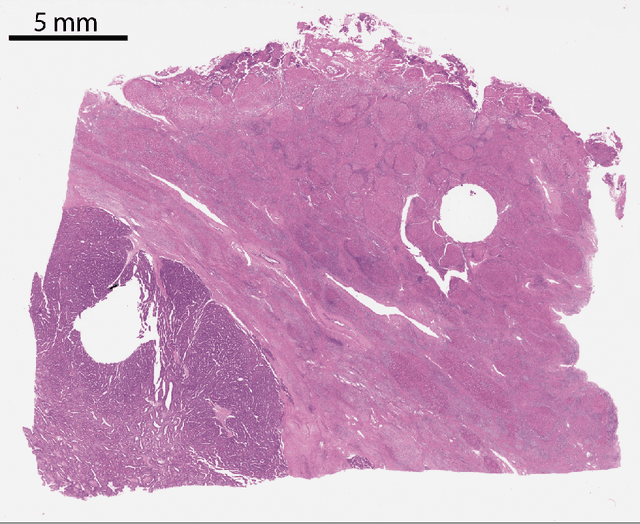
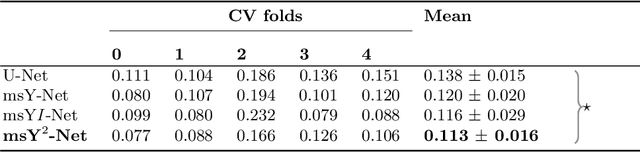
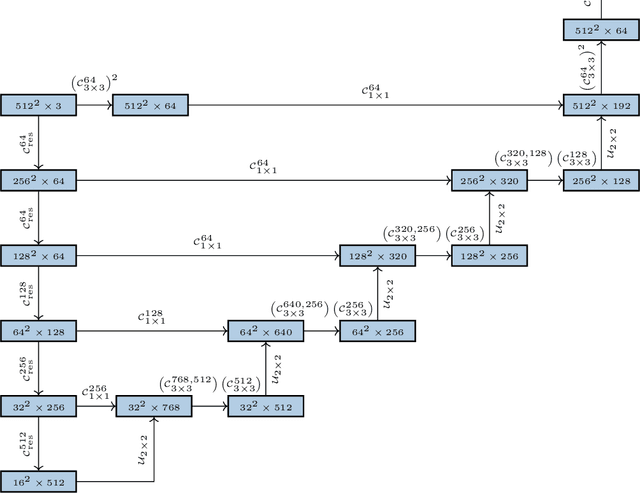
Histopathologic diagnosis is dependent on simultaneous information from a broad range of scales, ranging from nuclear aberrations ($\approx \mathcal{O}(0.1 \mu m)$) over cellular structures ($\approx \mathcal{O}(10\mu m)$) to the global tissue architecture ($\gtrapprox \mathcal{O}(1 mm)$). Bearing in mind which information is employed by human pathologists, we introduce and examine different strategies for the integration of multiple and widely separate spatial scales into common U-Net-based architectures. Based on this, we present a family of new, end-to-end trainable, multi-scale multi-encoder fully-convolutional neural networks for human modus operandi-inspired computer vision in histopathology.
Fixed Point Algorithm Based on Quasi-Newton Method for Convex Minimization Problem with Application to Image Deblurring
Dec 15, 2014

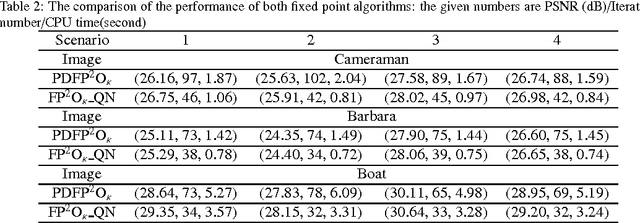
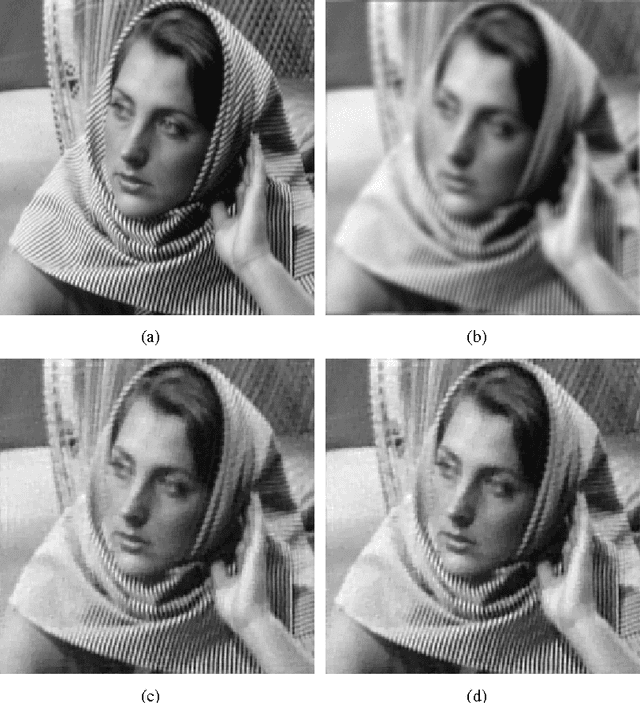
Solving an optimization problem whose objective function is the sum of two convex functions has received considerable interests in the context of image processing recently. In particular, we are interested in the scenario when a non-differentiable convex function such as the total variation (TV) norm is included in the objective function due to many variational models established in image processing have this nature. In this paper, we propose a fast fixed point algorithm based on the quasi-Newton method for solving this class of problem, and apply it in the field of TV-based image deblurring. The novel method is derived from the idea of the quasi-Newton method, and the fixed-point algorithms based on the proximity operator, which were widely investigated very recently. Utilizing the non-expansion property of the proximity operator we further investigate the global convergence of the proposed algorithm. Numerical experiments on image deblurring problem with additive or multiplicative noise are presented to demonstrate that the proposed algorithm is superior to the recently developed fixed-point algorithm in the computational efficiency.
Neuroscore: A Brain-inspired Evaluation Metric for Generative Adversarial Networks
May 10, 2019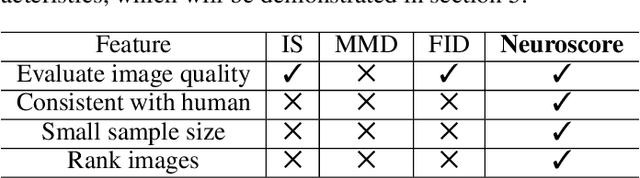
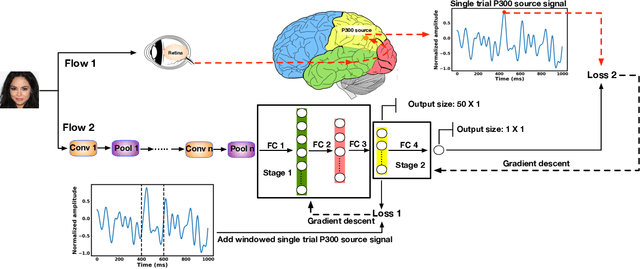
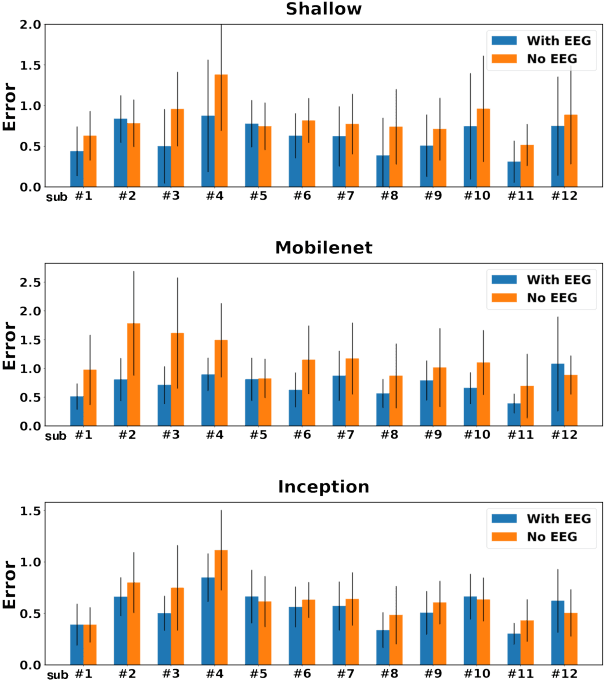

Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. Arguably the most striking results have been in the area of image synthesis. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect the human perception of the image quality. In this work, we introduce an evaluation metric we call Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performances to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network based brain-inspired framework is also proposed to predict Neuroscore from GAN-generated images. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model.
Detecting 11K Classes: Large Scale Object Detection without Fine-Grained Bounding Boxes
Aug 14, 2019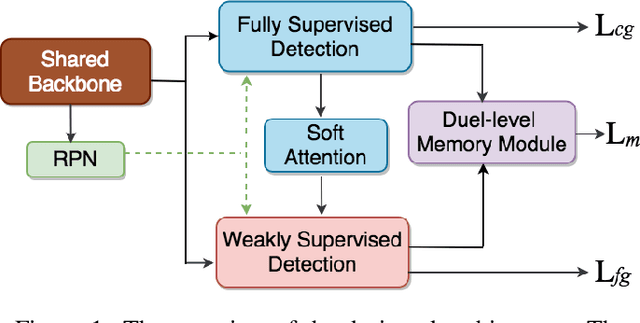
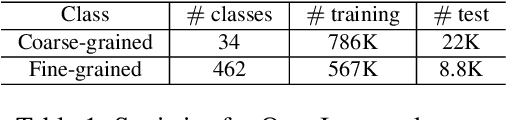
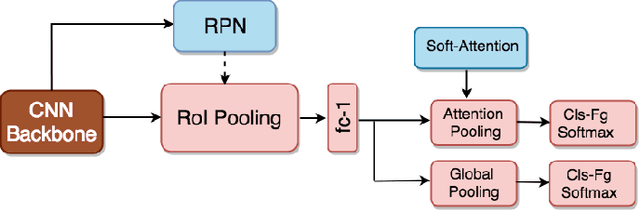
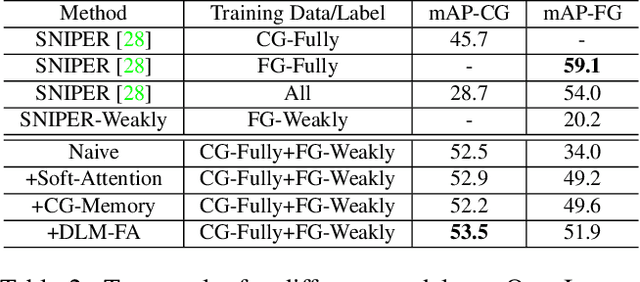
Recent advances in deep learning greatly boost the performance of object detection. State-of-the-art methods such as Faster-RCNN, FPN and R-FCN have achieved high accuracy in challenging benchmark datasets. However, these methods require fully annotated object bounding boxes for training, which are incredibly hard to scale up due to the high annotation cost. Weakly-supervised methods, on the other hand, only require image-level labels for training, but the performance is far below their fully-supervised counterparts. In this paper, we propose a semi-supervised large scale fine-grained detection method, which only needs bounding box annotations of a smaller number of coarse-grained classes and image-level labels of large scale fine-grained classes, and can detect all classes at nearly fully-supervised accuracy. We achieve this by utilizing the correlations between coarse-grained and fine-grained classes with shared backbone, soft-attention based proposal re-ranking, and a dual-level memory module. Experiment results show that our methods can achieve close accuracy on object detection to state-of-the-art fully-supervised methods on two large scale datasets, ImageNet and OpenImages, with only a small fraction of fully annotated classes.
Inducing Optimal Attribute Representations for Conditional GANs
Mar 13, 2020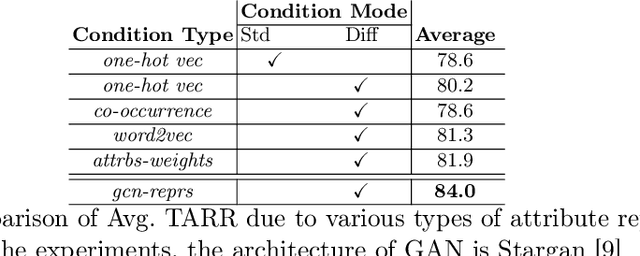

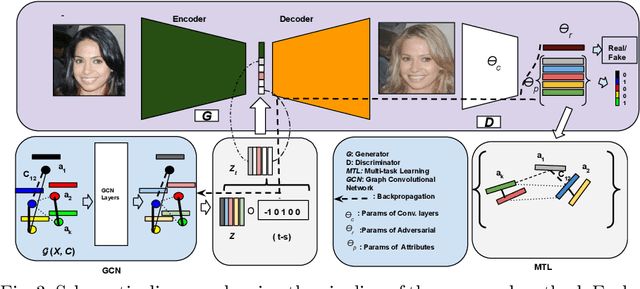
Conditional GANs are widely used in translating an image from one category to another. Meaningful conditions to GANs provide greater flexibility and control over the nature of the target domain synthetic data. Existing conditional GANs commonly encode target domain label information as hard-coded categorical vectors in the form of 0s and 1s. The major drawbacks of such representations are inability to encode the high-order semantic information of target categories and their relative dependencies. We propose a novel end-to-end learning framework with Graph Convolutional Networks to learn the attribute representations to condition on the generator. The GAN losses, i.e. the discriminator and attribute classification losses, are fed back to the Graph resulting in the synthetic images that are more natural and clearer in attributes. Moreover, prior-arts are given priorities to condition on the generator side, not on the discriminator side of GANs. We apply the conditions to the discriminator side as well via multi-task learning. We enhanced the four state-of-the art cGANs architectures: Stargan, Stargan-JNT, AttGAN and STGAN. Our extensive qualitative and quantitative evaluations on challenging face attributes manipulation data set, CelebA, LFWA, and RaFD, show that the cGANs enhanced by our methods outperform by a large margin, compared to their counter-parts and other conditioning methods, in terms of both target attributes recognition rates and quality measures such as PSNR and SSIM.
Synaptic Partner Assignment Using Attentional Voxel Association Networks
Apr 22, 2019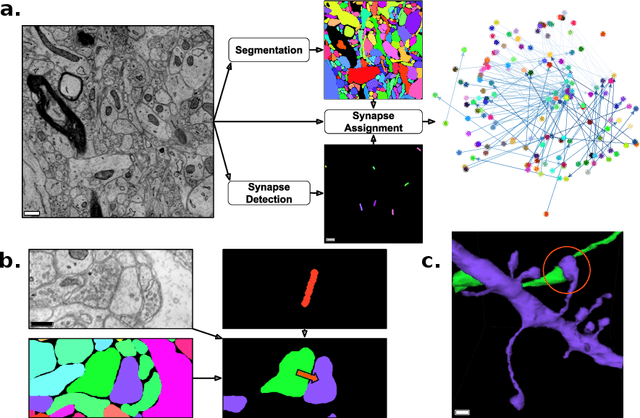
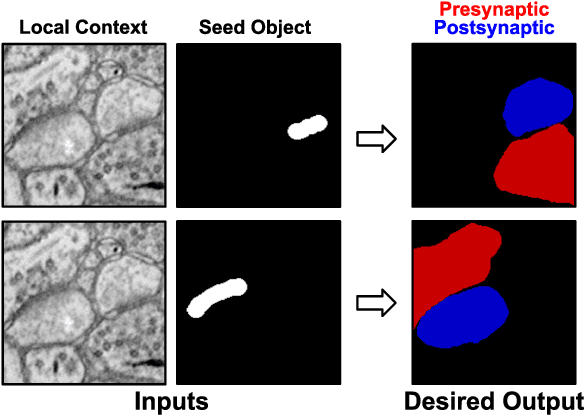

Connectomics aims to recover a complete set of synaptic connections within a dataset imaged by electron microscopy. Most systems for locating synapses use voxelwise classifier models, and train these classifiers to reproduce binary masks of synaptic clefts. However, only recent work has included a way to identify the synaptic partners that communicate at synaptic cleft segments. Here, we present a novel method for associating synaptic cleft segments with their synaptic partners using a convolutional network trained to associate the mask of a cleft with the voxels of its synaptic partners. The network takes the local image context and a mask of a single cleft segment as input. It is trained to produce two volumes of output: one which labels the voxels of the presynaptic partner within the input image, and another similar volume for the postsynaptic partner. The cleft mask acts as an attentional gating signal for the network, in that two clefts with the same local image context often have different partners. We find that an implementation of this approach performs well on a dataset of mouse somatosensory cortex, and evaluate it as part of a combined system to predict both clefts and connections.
Neural Generators of Sparse Local Linear Models for Achieving both Accuracy and Interpretability
Mar 13, 2020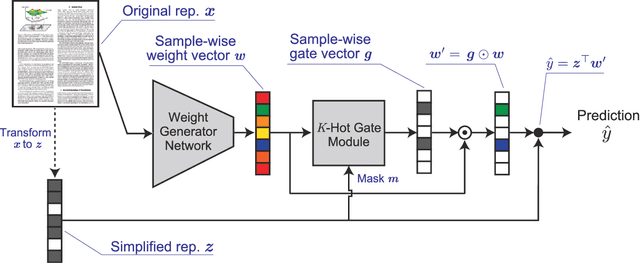
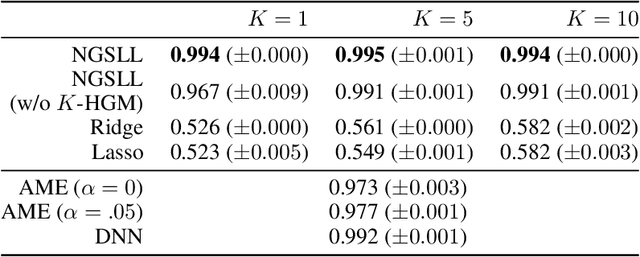
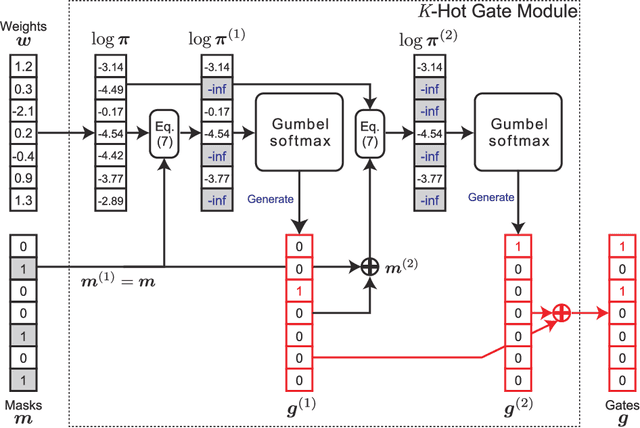

For reliability, it is important that the predictions made by machine learning methods are interpretable by human. In general, deep neural networks (DNNs) can provide accurate predictions, although it is difficult to interpret why such predictions are obtained by DNNs. On the other hand, interpretation of linear models is easy, although their predictive performance would be low since real-world data is often intrinsically non-linear. To combine both the benefits of the high predictive performance of DNNs and high interpretability of linear models into a single model, we propose neural generators of sparse local linear models (NGSLLs). The sparse local linear models have high flexibility as they can approximate non-linear functions. The NGSLL generates sparse linear weights for each sample using DNNs that take original representations of each sample (e.g., word sequence) and their simplified representations (e.g., bag-of-words) as input. By extracting features from the original representations, the weights can contain rich information to achieve high predictive performance. Additionally, the prediction is interpretable because it is obtained by the inner product between the simplified representations and the sparse weights, where only a small number of weights are selected by our gate module in the NGSLL. In experiments with real-world datasets, we demonstrate the effectiveness of the NGSLL quantitatively and qualitatively by evaluating prediction performance and visualizing generated weights on image and text classification tasks.
Adaptive Correlated Monte Carlo for Contextual Categorical Sequence Generation
Dec 31, 2019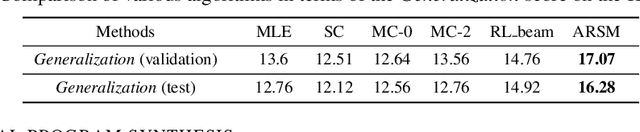
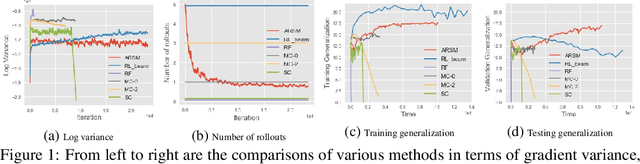

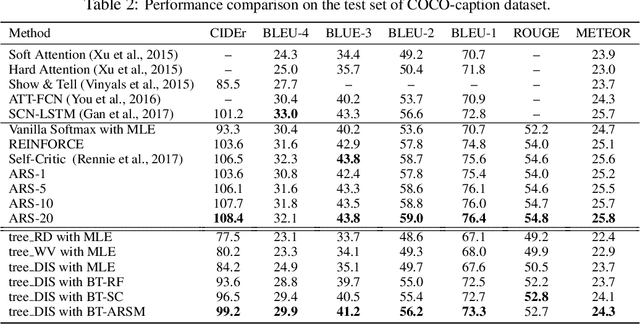
Sequence generation models are commonly refined with reinforcement learning over user-defined metrics. However, high gradient variance hinders the practical use of this method. To stabilize this method, we adapt to contextual generation of categorical sequences a policy gradient estimator, which evaluates a set of correlated Monte Carlo (MC) rollouts for variance control. Due to the correlation, the number of unique rollouts is random and adaptive to model uncertainty; those rollouts naturally become baselines for each other, and hence are combined to effectively reduce gradient variance. We also demonstrate the use of correlated MC rollouts for binary-tree softmax models, which reduce the high generation cost in large vocabulary scenarios by decomposing each categorical action into a sequence of binary actions. We evaluate our methods on both neural program synthesis and image captioning. The proposed methods yield lower gradient variance and consistent improvement over related baselines.