 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interval Neural Networks: Uncertainty Scores
Mar 25, 2020
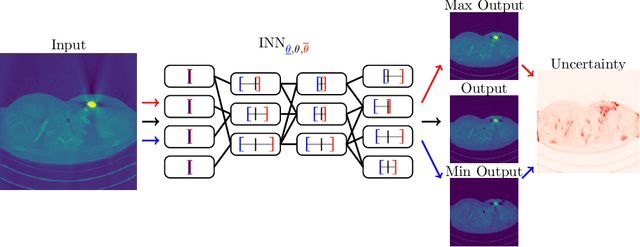
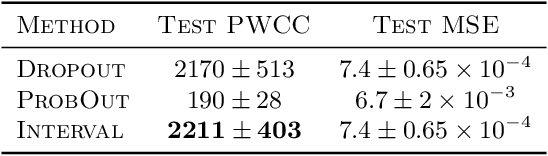
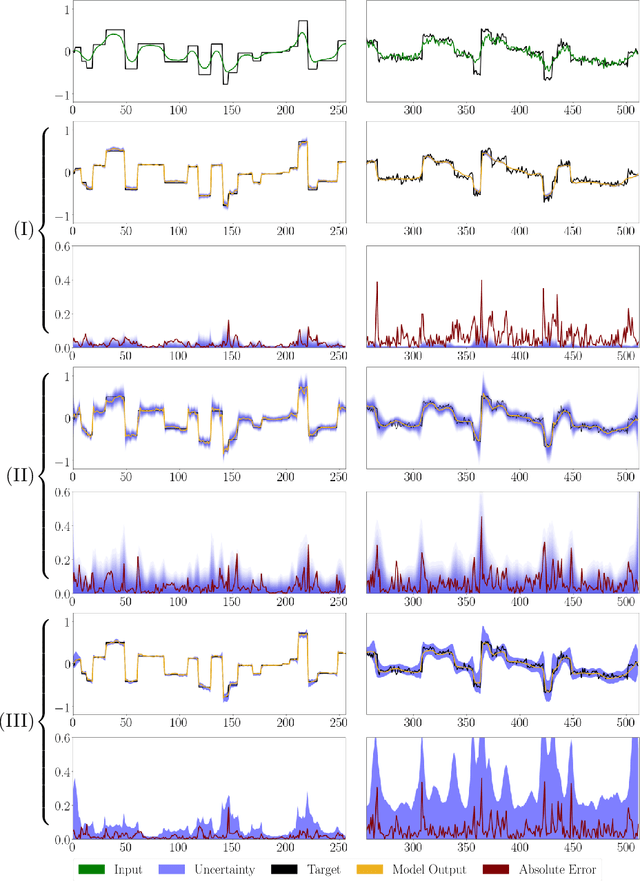
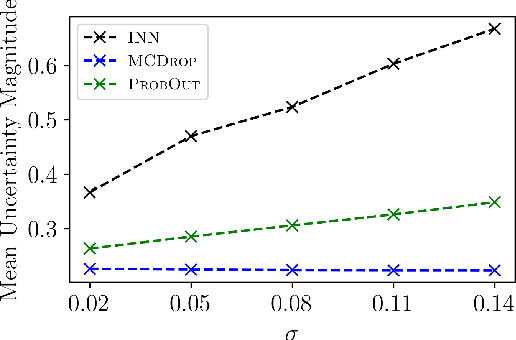
We propose a fast, non-Bayesian method for producing uncertainty scores in the output of pre-trained deep neural networks (DNNs) using a data-driven interval propagating network. This interval neural network (INN) has interval valued parameters and propagates its input using interval arithmetic. The INN produces sensible lower and upper bounds encompassing the ground truth. We provide theoretical justification for the validity of these bounds. Furthermore, its asymmetric uncertainty scores offer additional, directional information beyond what Gaussian-based, symmetric variance estimation can provide. We find that noise in the data is adequately captured by the intervals produced with our method. In numerical experiments on an image reconstruction task, we demonstrate the practical utility of INNs as a proxy for the prediction error in comparison to two state-of-the-art uncertainty quantification methods. In summary, INNs produce fast, theoretically justified uncertainty scores for DNNs that are easy to interpret, come with added information and pose as improved error proxies - features that may prove useful in advancing the usability of DNNs especially in sensitive applications such as health care.
HP2IFS: Head Pose estimation exploiting Partitioned Iterated Function Systems
Mar 25, 2020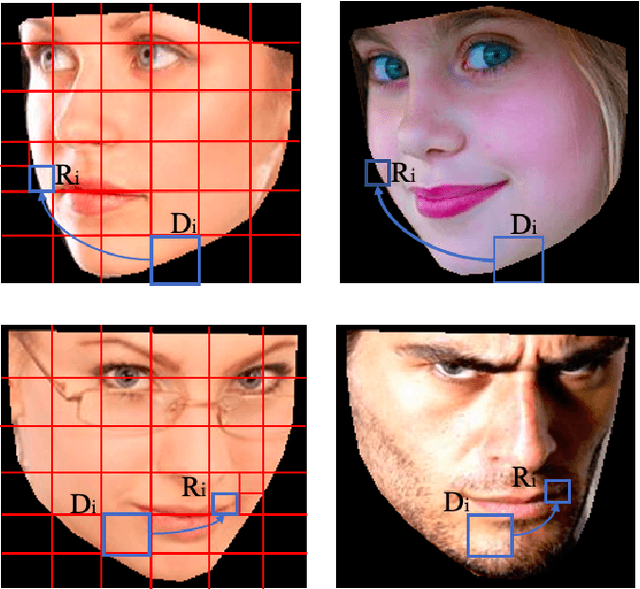
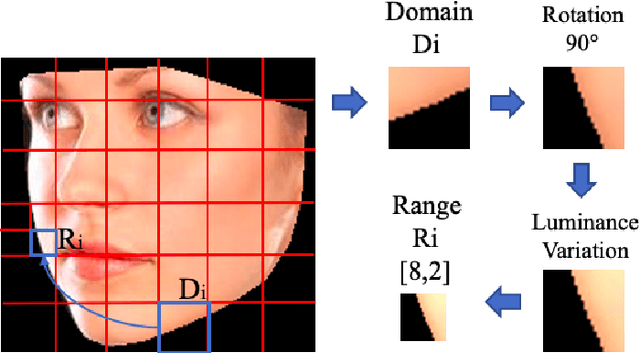
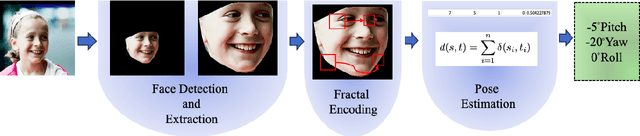
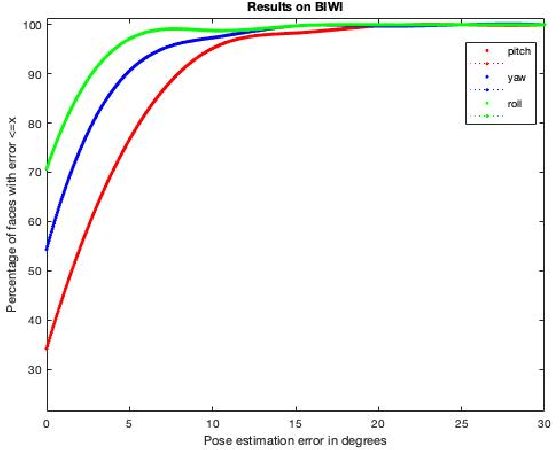
Estimating the actual head orientation from 2D images, with regard to its three degrees of freedom, is a well known problem that is highly significant for a large number of applications involving head pose knowledge. Consequently, this topic has been tackled by a plethora of methods and algorithms the most part of which exploits neural networks. Machine learning methods, indeed, achieve accurate head rotation values yet require an adequate training stage and, to that aim, a relevant number of positive and negative examples. In this paper we take a different approach to this topic by using fractal coding theory and particularly Partitioned Iterated Function Systems to extract the fractal code from the input head image and to compare this representation to the fractal code of a reference model through Hamming distance. According to experiments conducted on both the BIWI and the AFLW2000 databases, the proposed PIFS based head pose estimation method provides accurate yaw/pitch/roll angular values, with a performance approaching that of state of the art of machine-learning based algorithms and exceeding most of non-training based approaches.
SR2CNN: Zero-Shot Learning for Signal Recognition
Apr 10, 2020



Signal recognition is one of significant and challenging tasks in the signal processing and communications field. It is often a common situation that there's no training data accessible for some signal classes to perform a recognition task. Hence, as widely-used in image processing field, zero-shot learning (ZSL) is also very important for signal recognition. Unfortunately, ZSL regarding this field has hardly been studied due to inexplicable signal semantics. This paper proposes a ZSL framework, signal recognition and reconstruction convolutional neural networks (SR2CNN), to address relevant problems in this situation. The key idea behind SR2CNN is to learn the representation of signal semantic feature space by introducing a proper combination of cross entropy loss, center loss and autoencoder loss, as well as adopting a suitable distance metric space such that semantic features have greater minimal inter-class distance than maximal intra-class distance. The proposed SR2CNN can discriminate signals even if no training data is available for some signal class. Moreover, SR2CNN can gradually improve itself in the aid of signal detection, because of constantly refined class center vectors in semantic feature space. These merits are all verified by extensive experiments.
Solving machine learning optimization problems using quantum computers
Nov 17, 2019

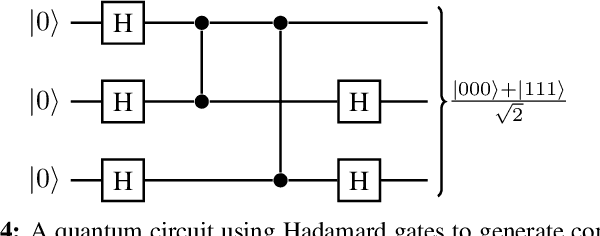
Classical optimization algorithms in machine learning often take a long time to compute when applied to a multi-dimensional problem and require a huge amount of CPU and GPU resource. Quantum parallelism has a potential to speed up machine learning algorithms. We describe a generic mathematical model to leverage quantum parallelism to speed-up machine learning algorithms. We also apply quantum machine learning and quantum parallelism applied to a $3$-dimensional image that vary with time.
Face Verification Using Boosted Cross-Image Features
Sep 28, 2013
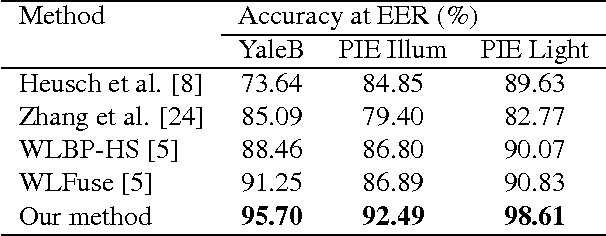
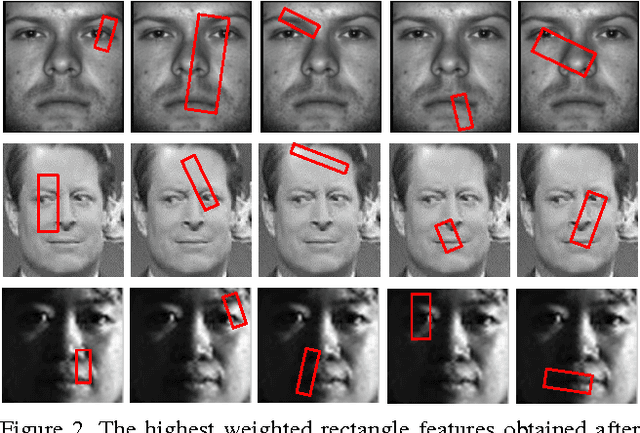

This paper proposes a new approach for face verification, where a pair of images needs to be classified as belonging to the same person or not. This problem is relatively new and not well-explored in the literature. Current methods mostly adopt techniques borrowed from face recognition, and process each of the images in the pair independently, which is counter intuitive. In contrast, we propose to extract cross-image features, i.e. features across the pair of images, which, as we demonstrate, is more discriminative to the similarity and the dissimilarity of faces. Our features are derived from the popular Haar-like features, however, extended to handle the face verification problem instead of face detection. We collect a large bank of cross-image features using filters of different sizes, locations, and orientations. Consequently, we use AdaBoost to select and weight the most discriminative features. We carried out extensive experiments on the proposed ideas using three standard face verification datasets, and obtained promising results outperforming state-of-the-art.
Texture Retrieval in the Wild through detection-based attributes
Oct 04, 2019

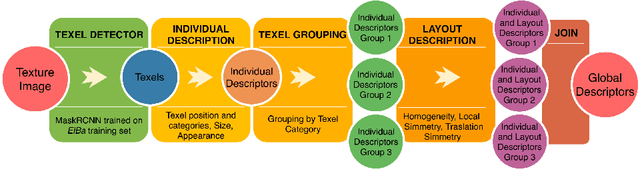
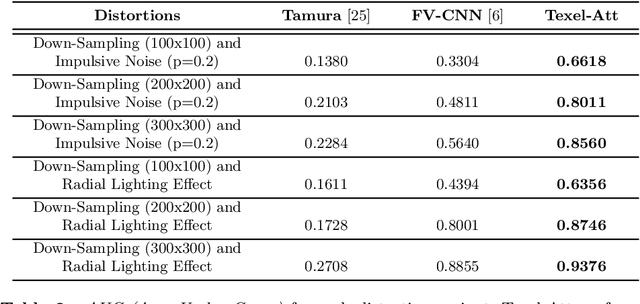
Capturing the essence of a textile image in a robust way is important to retrieve it in a large repository, especially if it has been acquired in the wild (by taking a photo of the textile of interest). In this paper we show that a texel-based representation fits well with this task. In particular, we refer to Texel-Att, a recent texel-based descriptor which has shown to capture fine grained variations of a texture, for retrieval purposes. After a brief explanation of Texel-Att, we will show in our experiments that this descriptor is robust to distortions resulting from acquisitions in the wild by setting up an experiment in which textures from the ElBa (an Element-Based texture dataset) are artificially distorted and then used to retrieve the original image. We compare our approach with existing descriptors using a simple ranking framework based on distance functions. Results show that even under extreme conditions (such as a down-sampling with a factor of 10), we perform better than alternative approaches.
The Minimum Cost Connected Subgraph Problem in Medical Image Analysis
Jun 20, 2016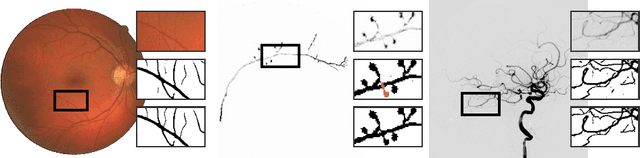

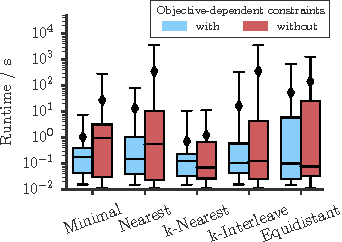
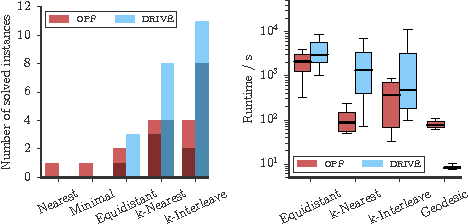
Several important tasks in medical image analysis can be stated in the form of an optimization problem whose feasible solutions are connected subgraphs. Examples include the reconstruction of neural or vascular structures under connectedness constraints. We discuss the minimum cost connected subgraph (MCCS) problem and its approximations from the perspective of medical applications. We propose a) objective-dependent constraints and b) novel constraint generation schemes to solve this optimization problem exactly by means of a branch-and-cut algorithm. These are shown to improve scalability and allow us to solve instances of two medical benchmark datasets to optimality for the first time. This enables us to perform a quantitative comparison between exact and approximative algorithms, where we identify the geodesic tree algorithm as an excellent alternative to exact inference on the examined datasets.
Deep Fusion Siamese Network for Automatic Kinship Verification
May 30, 2020

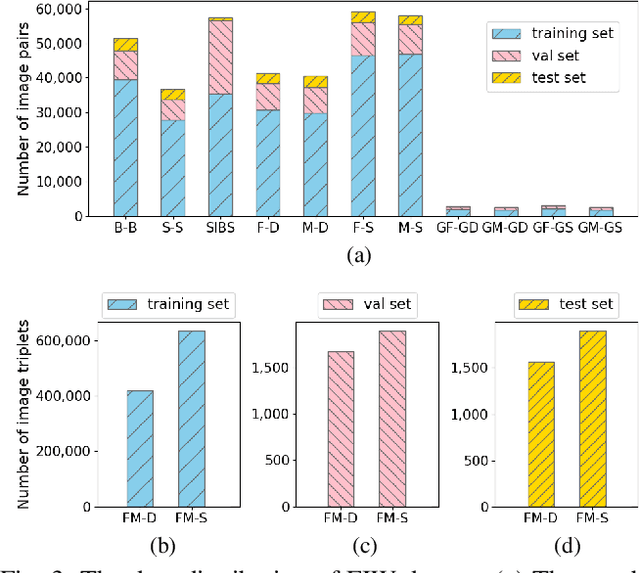
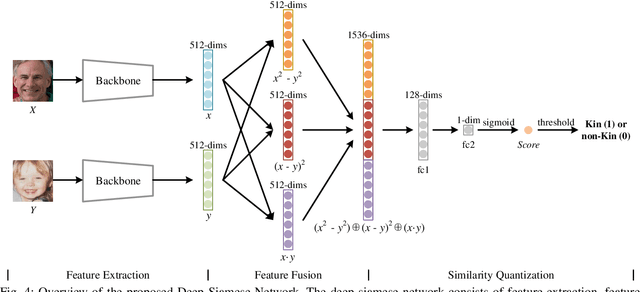
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at {\color{blue}https://github.com/gniknoil/FG2020-kinship}.
* 8 pages, 8 figures
Reducing Lateral Visual Biases in Displays
Apr 11, 2019



The human visual system is composed of multiple physiological components that apply multiple mechanisms in order to cope with the rich visual content it encounters. The complexity of this system leads to non-trivial relations between what we see and what we perceive, and in particular, between the raw intensities of an image that we display and the ones we perceive where various visual biases and illusions are introduced. In this paper we describe a method for reducing a large class of biases related to the lateral inhibition mechanism in the human retina where neurons suppress the activity of neighboring receptors. Among these biases are the well-known Mach bands and halos that appear around smooth and sharp image gradients as well as the appearance of false contrasts between identical regions. The new method removes these visual biases by computing an image that contains counter biases such that when this laterally-compensated image is viewed on a display, the inserted biases cancel the ones created in the retina.
DCDLearn: Multi-order Deep Cross-distance Learning for Vehicle Re-Identification
Mar 25, 2020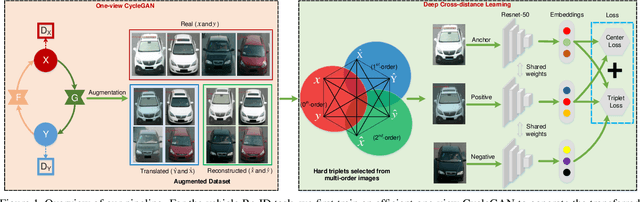

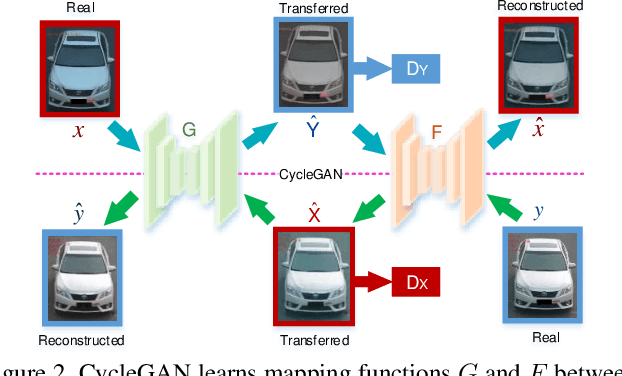
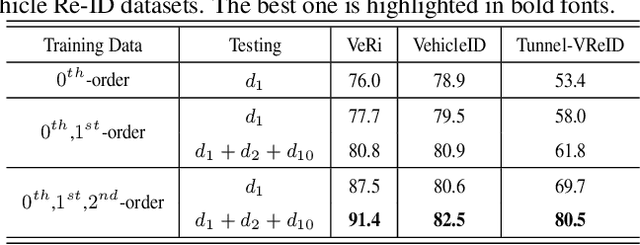
Vehicle re-identification (Re-ID) has become a popular research topic owing to its practicability in intelligent transportation systems. Vehicle Re-ID suffers the numerous challenges caused by drastic variation in illumination, occlusions, background, resolutions, viewing angles, and so on. To address it, this paper formulates a multi-order deep cross-distance learning (\textbf{DCDLearn}) model for vehicle re-identification, where an efficient one-view CycleGAN model is developed to alleviate exhaustive and enumerative cross-camera matching problem in previous works and smooth the domain discrepancy of cross cameras. Specially, we treat the transferred images and the reconstructed images generated by one-view CycleGAN as multi-order augmented data for deep cross-distance learning, where the cross distances of multi-order image set with distinct identities are learned by optimizing an objective function with multi-order augmented triplet loss and center loss to achieve the camera-invariance and identity-consistency. Extensive experiments on three vehicle Re-ID datasets demonstrate that the proposed method achieves significant improvement over the state-of-the-arts, especially for the small scale dataset.