 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DualDis: Dual-Branch Disentangling with Adversarial Learning
Jun 03, 2019
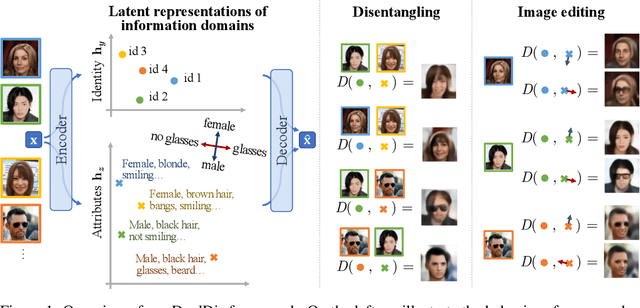
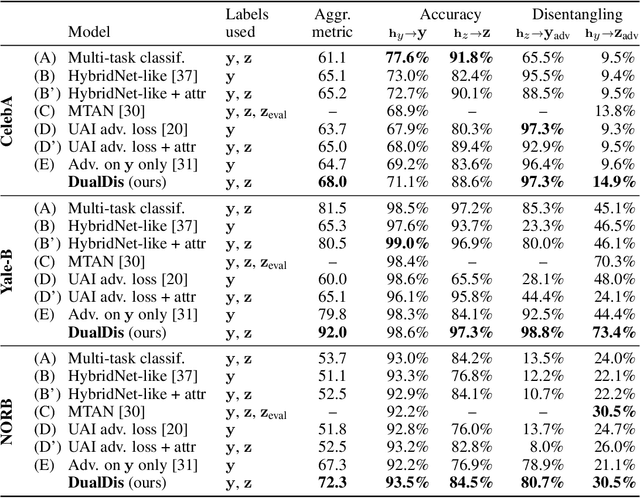
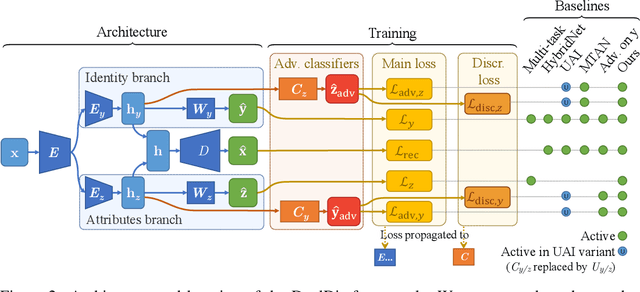
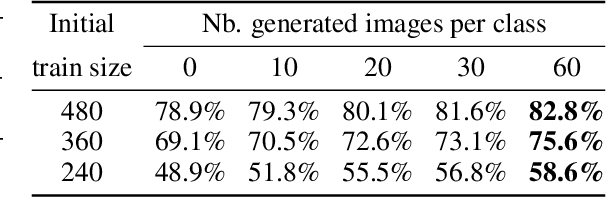
In computer vision, disentangling techniques aim at improving latent representations of images by modeling factors of variation. In this paper, we propose DualDis, a new auto-encoder-based framework that disentangles and linearizes class and attribute information. This is achieved thanks to a two-branch architecture forcing the separation of the two kinds of information, accompanied by a decoder for image reconstruction and generation. To effectively separate the information, we propose to use a combination of regular and adversarial classifiers to guide the two branches in specializing for class and attribute information respectively. We also investigate the possibility of using semi-supervised learning for an effective disentangling even using few labels. We leverage the linearization property of the latent spaces for semantic image editing and generation of new images. We validate our approach on CelebA, Yale-B and NORB by measuring the efficiency of information separation via classification metrics, visual image manipulation and data augmentation.
Plug-in Factorization for Latent Representation Disentanglement
May 29, 2019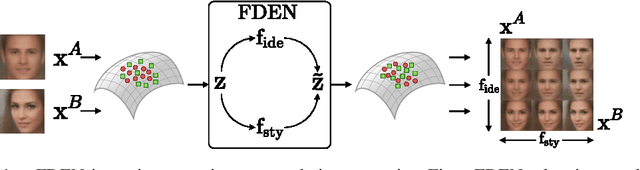
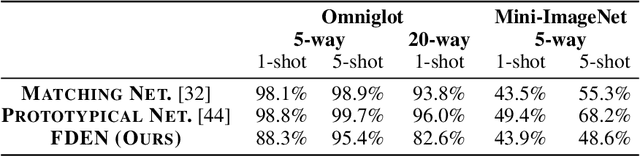
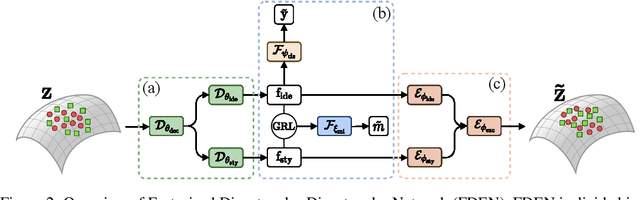
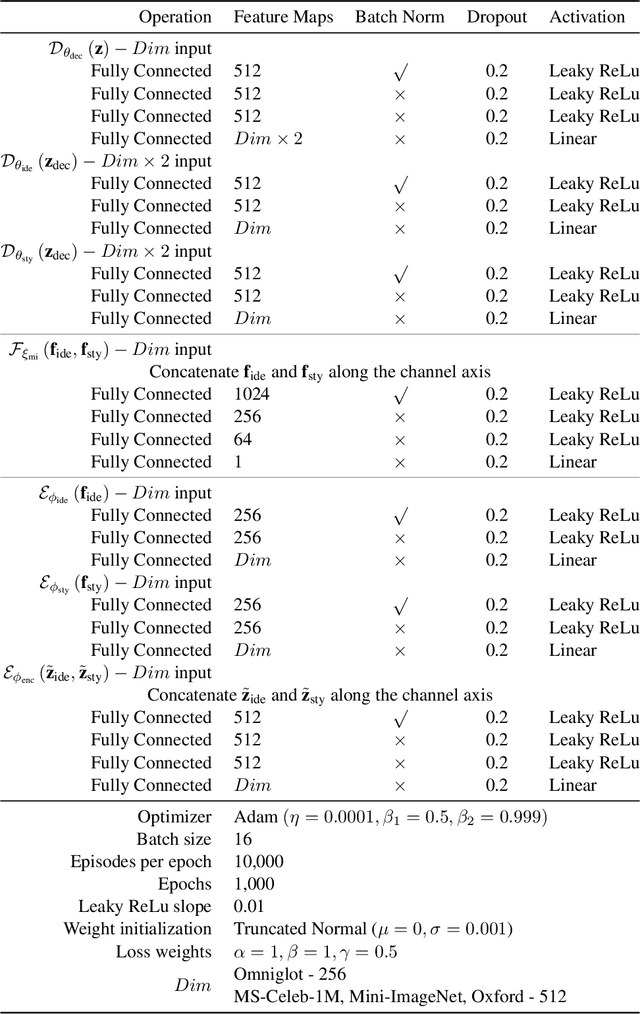
In this work, we propose a Factorized Disentangler-Entangler Network (FDEN) that learns to decompose a latent representation into two mutually independent factors, namely, identity and style. Given a latent representation, the proposed framework draws a set of interpretable factors aligned to identity of an observed data and learns to maximize the independency between these factors. Our work introduces an idea for a plug-in method to disentangle latent representations of already learned deep models with no affect to the model. In doing so, it brings the possibilities of extending state-of-the-art models to solve different tasks and also maintain the performance of its original task. Thus, FDEN is naturally applicable to jointly perform multiple tasks such as few-shot learning and image-to-image translation in a single framework. We show the effectiveness of our work in disentangling a latent representation in two parts. First, to evaluate the alignment of factor to an identity, we perform few-shot learning using only the aligned factor. Then, to evaluate the effectiveness of decomposition of latent representation and to show that plugin method does not affect the deep model in its performance, we perform image-to-image style transfer by mixing factors of different images. These evaluations show, qualitatively and quantitatively, that our proposed framework can indeed disentangle a latent representation.
An Empirical Evaluation on Robustness and Uncertainty of Regularization Methods
Mar 09, 2020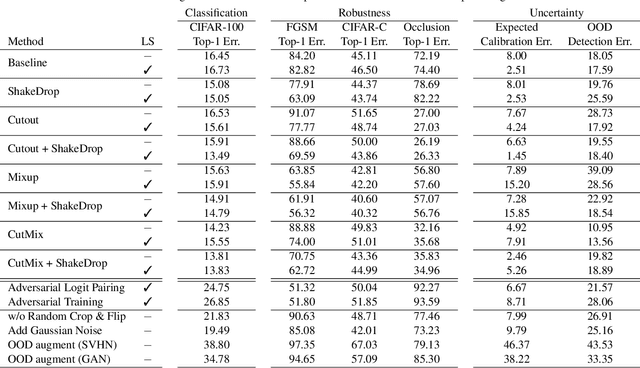
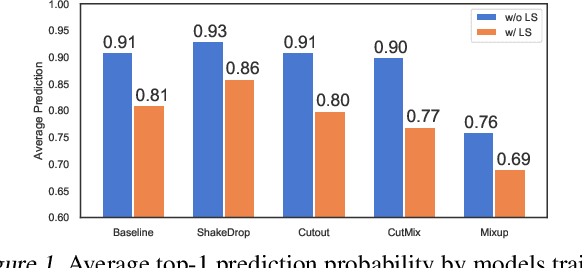

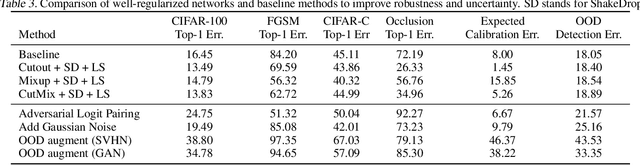
Despite apparent human-level performances of deep neural networks (DNN), they behave fundamentally differently from humans. They easily change predictions when small corruptions such as blur and noise are applied on the input (lack of robustness), and they often produce confident predictions on out-of-distribution samples (improper uncertainty measure). While a number of researches have aimed to address those issues, proposed solutions are typically expensive and complicated (e.g. Bayesian inference and adversarial training). Meanwhile, many simple and cheap regularization methods have been developed to enhance the generalization of classifiers. Such regularization methods have largely been overlooked as baselines for addressing the robustness and uncertainty issues, as they are not specifically designed for that. In this paper, we provide extensive empirical evaluations on the robustness and uncertainty estimates of image classifiers (CIFAR-100 and ImageNet) trained with state-of-the-art regularization methods. Furthermore, experimental results show that certain regularization methods can serve as strong baseline methods for robustness and uncertainty estimation of DNNs.
Classification of the Chinese Handwritten Numbers with Supervised Projective Dictionary Pair Learning
Mar 26, 2020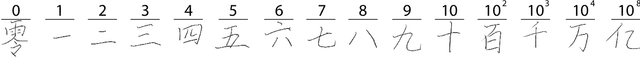
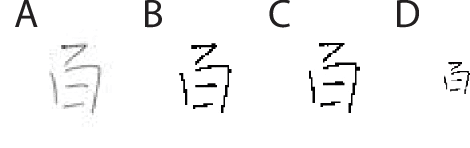

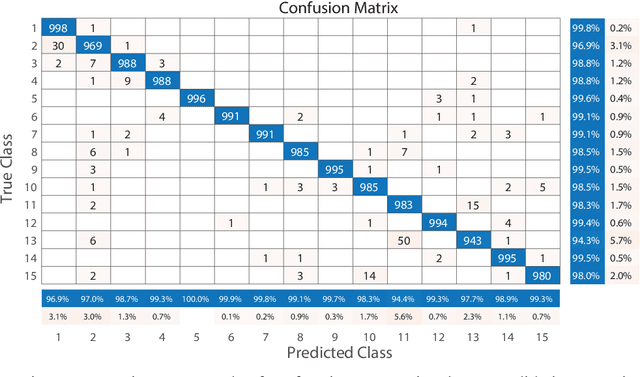
Image classification has become a key ingredient in the field of computer vision. To enhance classification accuracy, current approaches heavily focus on increasing network depth and width, e.g., inception modules, at the cost of computational requirements. To mitigate this problem, in this paper a novel dictionary learning method is proposed and tested with Chinese handwritten numbers. We have considered three important characteristics to design the dictionary: discriminability, sparsity, and classification error. We formulated these metrics into a unified cost function. The proposed architecture i) obtains an efficient sparse code in a novel feature space without relying on $\ell_0$ and $\ell_1$ norms minimisation; and ii) includes the classification error within the cost function as an extra constraint. Experimental results show that the proposed method provides superior classification performance compared to recent dictionary learning methods. With a classification accuracy of $\sim$98\%, the results suggest that our proposed sparse learning algorithm achieves comparable performance to existing well-known deep learning methods, e.g., SqueezeNet, GoogLeNet and MobileNetV2, but with a fraction of parameters.
Hyperspectral Unmixing Network Inspired by Unfolding an Optimization Problem
May 30, 2020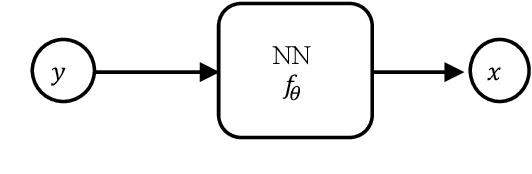
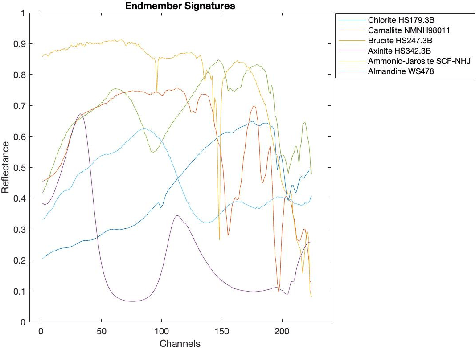
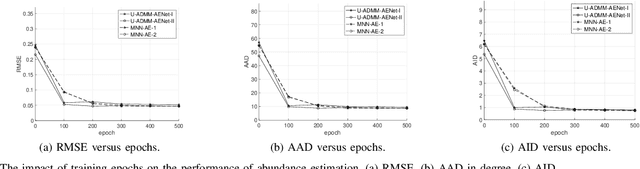
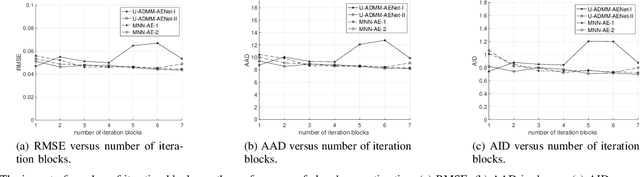
The hyperspectral image (HSI) unmixing task is essentially an inverse problem, which is commonly solved by optimization algorithms under a predefined (non-)linear mixture model. Although these optimization algorithms show impressive performance, they are very computational demanding as they often rely on an iterative updating scheme. Recently, the rise of neural networks has inspired lots of learning based algorithms in unmixing literature. However, most of them lack of interpretability and require a large training dataset. One natural question then arises: can one leverage the model based algorithm and learning based algorithm to achieve interpretable and fast algorithm for HSI unmixing problem? In this paper, we propose two novel network architectures, named U-ADMM-AENet and U-ADMM-BUNet, for abundance estimation and blind unmixing respectively, by combining the conventional optimization-model based unmixing method and the rising learning based unmixing method. We first consider a linear mixture model with sparsity constraint, then we unfold Alternating Direction Method of Multipliers (ADMM) algorithm to construct the unmixing network structures. We also show that the unfolded structures can find corresponding interpretations in machine learning literature, which further demonstrates the effectiveness of proposed methods. Benefit from the interpretation, the proposed networks can be initialized by incorporating prior information about the HSI data. Different from traditional unfolding networks, we propose a new training strategy for proposed networks to better fit in the HSI applications. Extensive experiments show that the proposed methods can achieve much faster convergence and competitive performance even with very small size of training data, when compared with state-of-art algorithms.
Uncertainty Estimation in Deep 2D Echocardiography Segmentation
May 19, 2020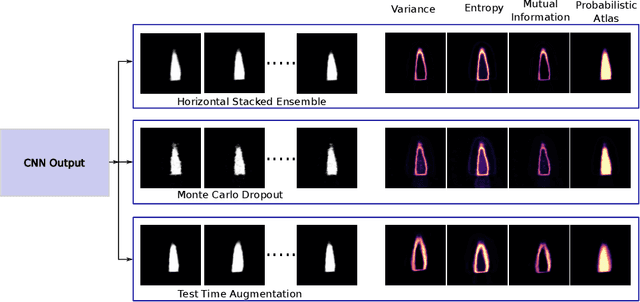

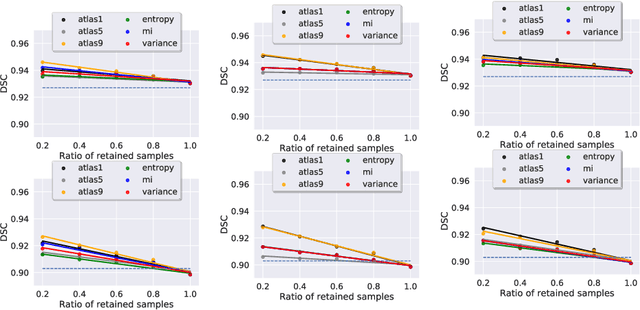
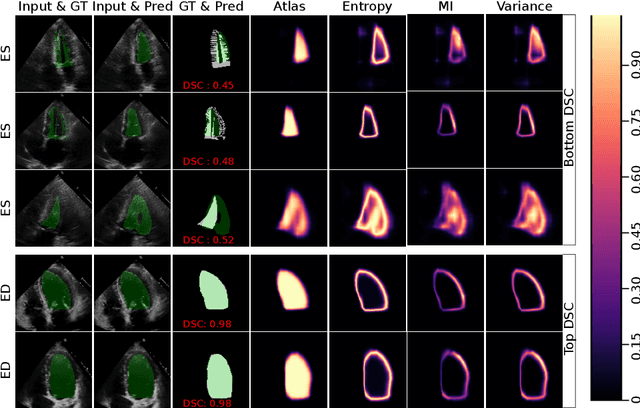
2D echocardiography is the most common imaging modality for cardiovascular diseases. The portability and relatively low-cost nature of Ultrasound (US) enable the US devices needed for performing echocardiography to be made widely available. However, acquiring and interpreting cardiac US images is operator dependent, limiting its use to only places where experts are present. Recently, Deep Learning (DL) has been used in 2D echocardiography for automated view classification, and structure and function assessment. Although these recent works show promise in developing computer-guided acquisition and automated interpretation of echocardiograms, most of these methods do not model and estimate uncertainty which can be important when testing on data coming from a distribution further away from that of the training data. Uncertainty estimates can be beneficial both during the image acquisition phase (by providing real-time feedback to the operator on acquired image's quality), and during automated measurement and interpretation. The performance of uncertainty models and quantification metric may depend on the prediction task and the models being compared. Hence, to gain insight of uncertainty modelling for left ventricular segmentation from US images, we compare three ensembling based uncertainty models quantified using four different metrics (one newly proposed) on state-of-the-art baseline networks using two publicly available echocardiogram datasets. We further demonstrate how uncertainty estimation can be used to automatically reject poor quality images and improve state-of-the-art segmentation results.
Face Quality Estimation and Its Correlation to Demographic and Non-Demographic Bias in Face Recognition
Apr 24, 2020
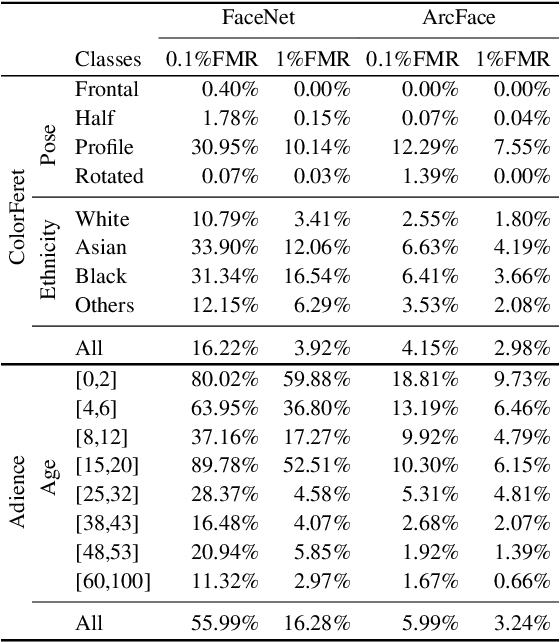
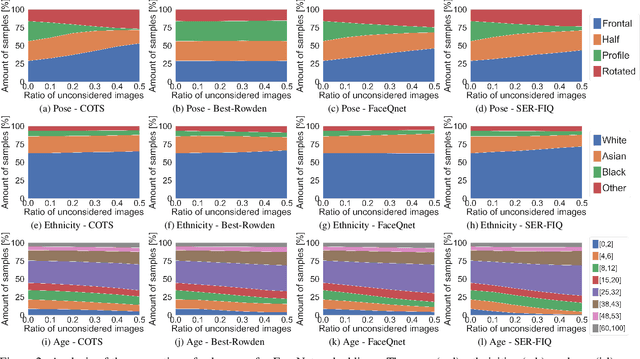
Face quality assessment aims at estimating the utility of a face image for the purpose of recognition. It is a key factor to achieve high face recognition performances. Currently, the high performance of these face recognition systems come with the cost of a strong bias against demographic and non-demographic sub-groups. Recent work has shown that face quality assessment algorithms should adapt to the deployed face recognition system, in order to achieve highly accurate and robust quality estimations. However, this could lead to a bias transfer towards the face quality assessment leading to discriminatory effects e.g. during enrolment. In this work, we present an in-depth analysis of the correlation between bias in face recognition and face quality assessment. Experiments were conducted on two publicly available datasets captured under controlled and uncontrolled circumstances with two popular face embeddings. We evaluated four state-of-the-art solutions for face quality assessment towards biases to pose, ethnicity, and age. The experiments showed that the face quality assessment solutions assign significantly lower quality values towards subgroups affected by the recognition bias demonstrating that these approaches are biased as well. This raises ethical questions towards fairness and discrimination which future works have to address.
AdaptiveWeighted Attention Network with Camera Spectral Sensitivity Prior for Spectral Reconstruction from RGB Images
May 19, 2020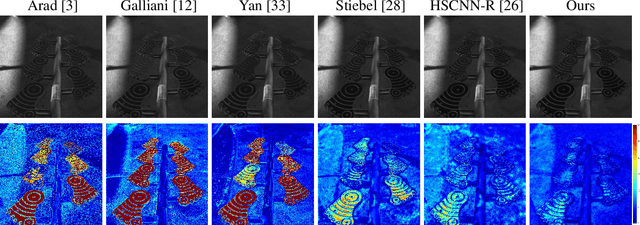
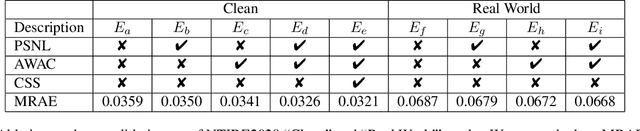
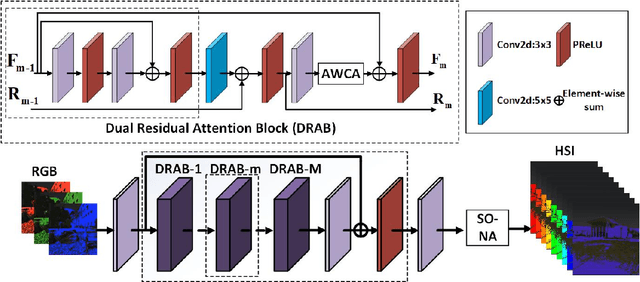
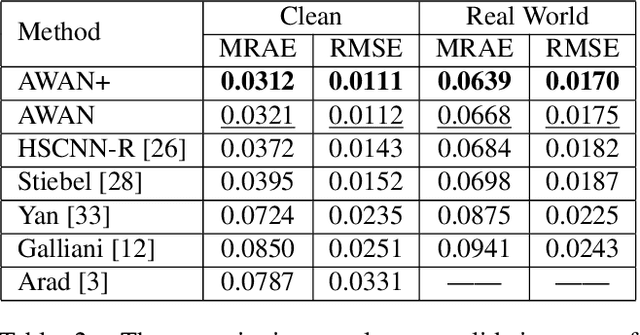
Recent promising effort for spectral reconstruction (SR) focuses on learning a complicated mapping through using a deeper and wider convolutional neural networks (CNNs). Nevertheless, most CNN-based SR algorithms neglect to explore the camera spectral sensitivity (CSS) prior and interdependencies among intermediate features, thus limiting the representation ability of the network and performance of SR. To conquer these issues, we propose a novel adaptive weighted attention network (AWAN) for SR, whose backbone is stacked with multiple dual residual attention blocks (DRAB) decorating with long and short skip connections to form the dual residual learning. Concretely, we investigate an adaptive weighted channel attention (AWCA) module to reallocate channel-wise feature responses via integrating correlations between channels. Furthermore, a patch-level second-order non-local (PSNL) module is developed to capture long-range spatial contextual information by second-order non-local operations for more powerful feature representations. Based on the fact that the recovered RGB images can be projected by the reconstructed hyperspectral image (HSI) and the given CSS function, we incorporate the discrepancies of the RGB images and HSIs as a finer constraint for more accurate reconstruction. Experimental results demonstrate the effectiveness of our proposed AWAN network in terms of quantitative comparison and perceptual quality over other state-of-the-art SR methods. In the NTIRE 2020 Spectral Reconstruction Challenge, our entries obtain the 1st ranking on the Clean track and the 3rd place on the Real World track. Codes are available at https://github.com/Deep-imagelab/AWAN.
Learning Transparent Object Matting
Jul 25, 2019
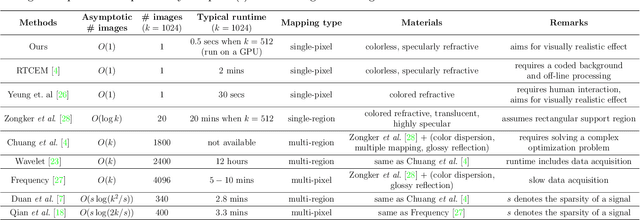
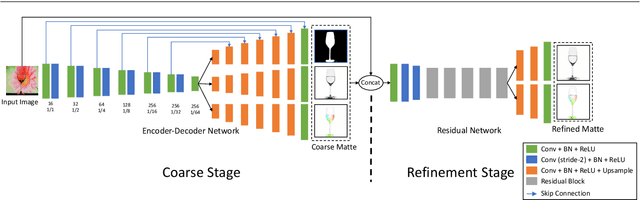

This paper addresses the problem of image matting for transparent objects. Existing approaches often require tedious capturing procedures and long processing time, which limit their practical use. In this paper, we formulate transparent object matting as a refractive flow estimation problem, and propose a deep learning framework, called TOM-Net, for learning the refractive flow. Our framework comprises two parts, namely a multi-scale encoder-decoder network for producing a coarse prediction, and a residual network for refinement. At test time, TOM-Net takes a single image as input, and outputs a matte (consisting of an object mask, an attenuation mask and a refractive flow field) in a fast feed-forward pass. As no off-the-shelf dataset is available for transparent object matting, we create a large-scale synthetic dataset consisting of $178K$ images of transparent objects rendered in front of images sampled from the Microsoft COCO dataset. We also capture a real dataset consisting of $876$ samples using $14$ transparent objects and $60$ background images. Besides, we show that our method can be easily extended to handle the cases where a trimap or a background image is available.Promising experimental results have been achieved on both synthetic and real data, which clearly demonstrate the effectiveness of our approach.
A Survey on Visual Sentiment Analysis
Apr 24, 2020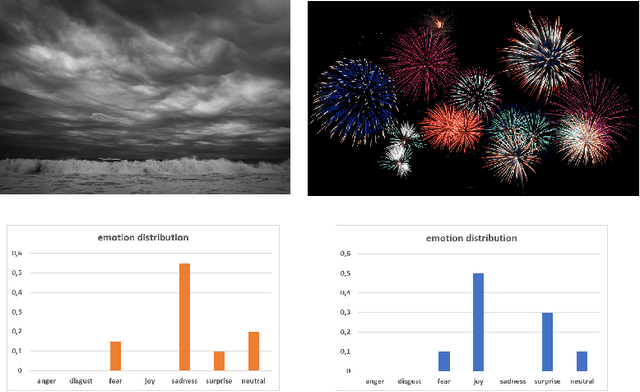
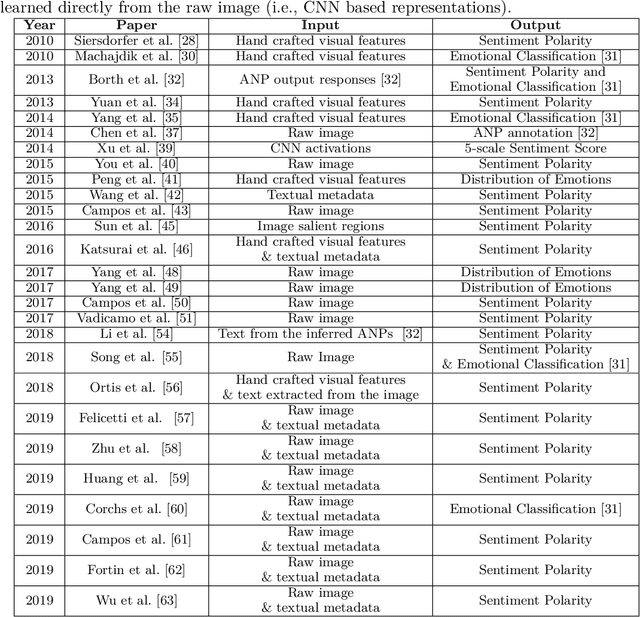
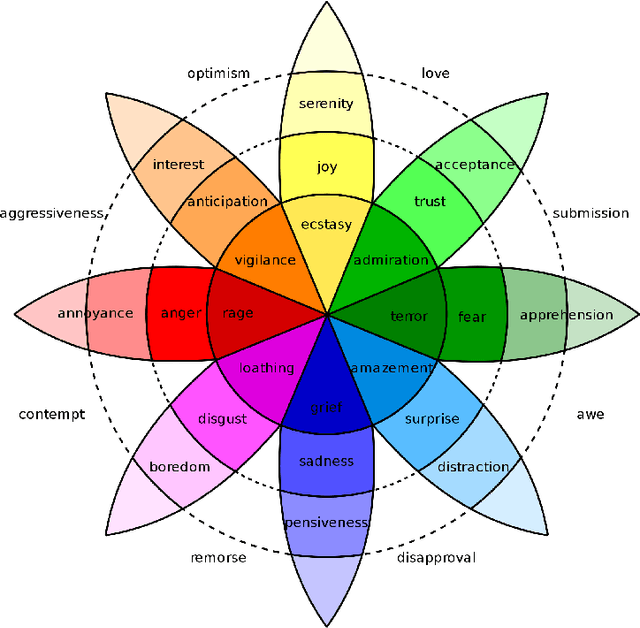
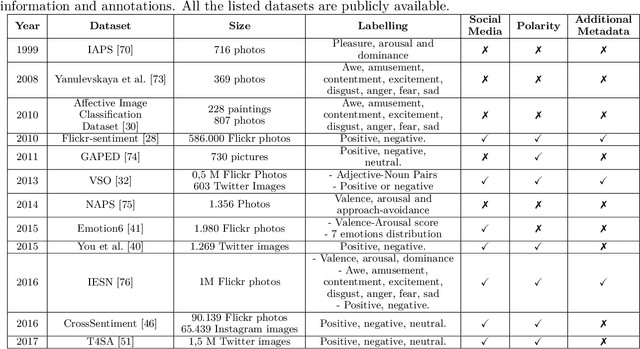
Visual Sentiment Analysis aims to understand how images affect people, in terms of evoked emotions. Although this field is rather new, over the last years, a broad range of techniques have been developed for various data sources and problems, resulting in a large body of research. This paper reviews pertinent publications and tries to present an exhaustive e view of the field. After a description of the task and the related applications, the subject is tackled under different main headings. The paper also describes principles of design of general Visual Sentiment Analysis systems from three main points of view: emotional models, dataset definition, feature design. A formalization of the problem is discussed, considering different levels of granularity, as well as the components that can affect the sentiment toward an image in different ways. To this aim, this paper considers a structured formalization of the problem which is usually used for the analysis of text, and discusses it's suitability in the context of Visual Sentiment Analysis. The paper also includes a description of new challenges, the evaluation from the viewpoint of progress toward more sophisticated systems and related practical applications, as well as a summary of the insights resulting from this study.