 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Application of Generative Adversarial Networks for Super Resolution Medical Imaging
Dec 19, 2019
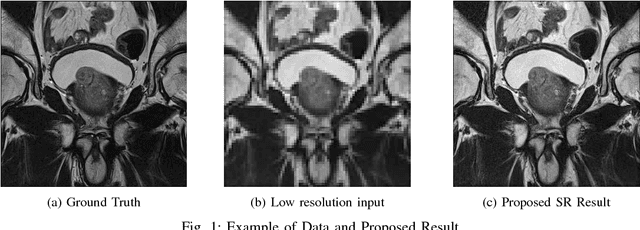
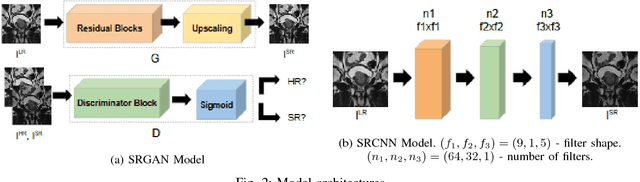

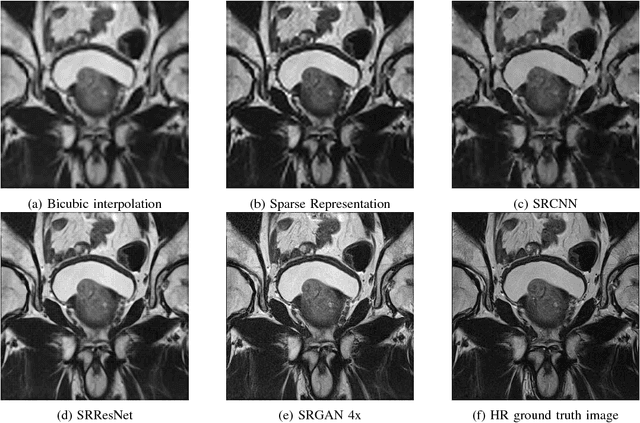
Acquiring High Resolution (HR) Magnetic Resonance (MR) images requires the patient to remain still for long periods of time, which causes patient discomfort and increases the probability of motion induced image artifacts. A possible solution is to acquire low resolution (LR) images and to process them with the Super Resolution Generative Adversarial Network (SRGAN) to create an HR version. Acquiring LR images requires a lower scan time than acquiring HR images, which allows for higher patient comfort and scanner throughput. This work applies SRGAN to MR images of the prostate to improve the in-plane resolution by factors of 4 and 8. The term 'super resolution' in the context of this paper defines the post processing enhancement of medical images as opposed to 'high resolution' which defines native image resolution acquired during the MR acquisition phase. We also compare the SRGAN to three other models: SRCNN, SRResNet, and Sparse Representation. While the SRGAN results do not have the best Peak Signal to Noise Ratio (PSNR) or Structural Similarity (SSIM) metrics, they are the visually most similar to the original HR images, as portrayed by the Mean Opinion Score (MOS) results.
* International Conference on Machine Learning Applications, 6 pages, 5 figures, 2 tables
Light Weight Residual Dense Attention Net for Spectral Reconstruction from RGB Images
Apr 19, 2020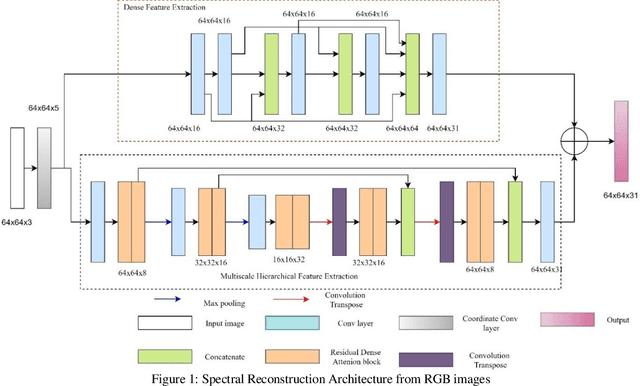
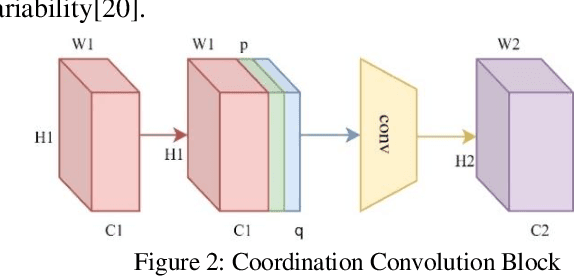
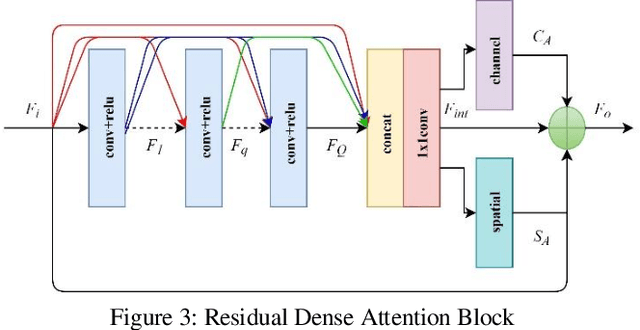

Hyperspectral Imaging is the acquisition of spectral and spatial information of a particular scene. Capturing such information from a specialized hyperspectral camera remains costly. Reconstructing such information from the RGB image achieves a better solution in both classification and object recognition tasks. This work proposes a novel light weight network with very less number of parameters about 233,059 parameters based on Residual dense model with attention mechanism to obtain this solution. This network uses Coordination Convolutional Block to get the spatial information. The weights from this block are shared by two independent feature extraction mechanisms, one by dense feature extraction and the other by the multiscale hierarchical feature extraction. Finally, the features from both the feature extraction mechanisms are globally fused to produce the 31 spectral bands. The network is trained with NTIRE 2020 challenge dataset and thus achieved 0.0457 MRAE metric value with less computational complexity.
Single-shot autofocusing of microscopy images using deep learning
Mar 21, 2020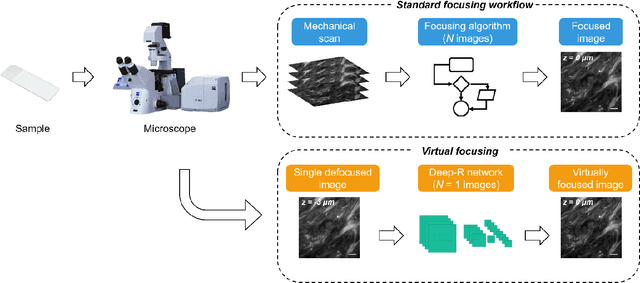
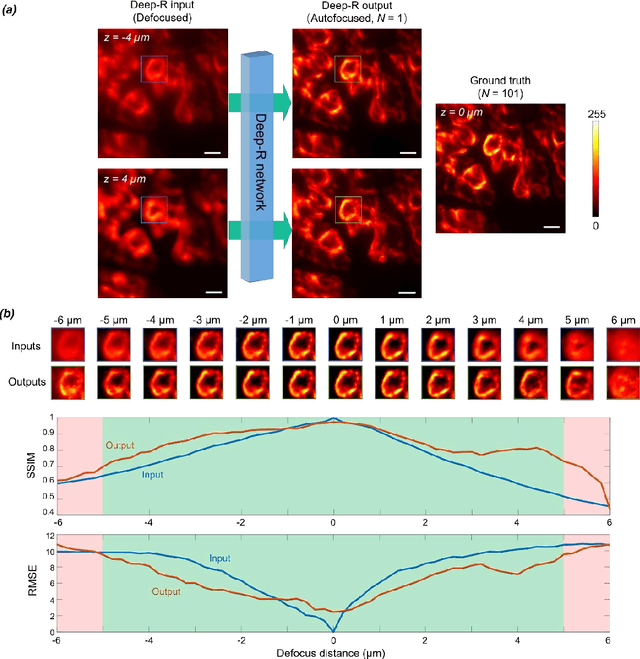
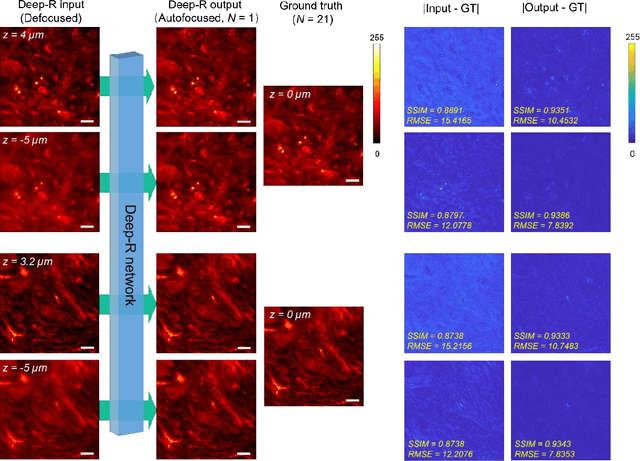
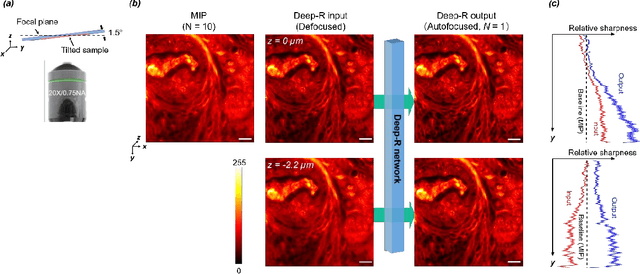
We demonstrate a deep learning-based offline autofocusing method, termed Deep-R, that is trained to rapidly and blindly autofocus a single-shot microscopy image of a specimen that is acquired at an arbitrary out-of-focus plane. We illustrate the efficacy of Deep-R using various tissue sections that were imaged using fluorescence and brightfield microscopy modalities and demonstrate snapshot autofocusing under different scenarios, such as a uniform axial defocus as well as a sample tilt within the field-of-view. Our results reveal that Deep-R is significantly faster when compared with standard online algorithmic autofocusing methods. This deep learning-based blind autofocusing framework opens up new opportunities for rapid microscopic imaging of large sample areas, also reducing the photon dose on the sample.
Abstract Universal Approximation for Neural Networks
Jul 14, 2020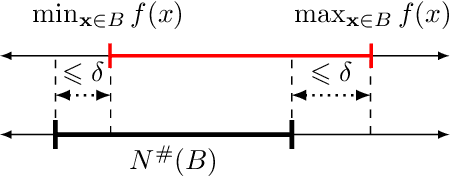



With growing concerns about the safety and robustness of neural networks, a number of researchers have successfully applied abstract interpretation with numerical domains to verify properties of neural networks. Why do numerical domains work for neural-network verification? We present a theoretical result that demonstrates the power of numerical domains, namely, the simple interval domain, for analysis of neural networks. Our main theorem, which we call the abstract universal approximation (AUA) theorem, generalizes the recent result by Baader et al. [2020] for ReLU networks to a rich class of neural networks. The classical universal approximation theorem says that, given function $f$, for any desired precision, there is a neural network that can approximate $f$. The AUA theorem states that for any function $f$, there exists a neural network whose abstract interpretation is an arbitrarily close approximation of the collecting semantics of $f$. Further, the network may be constructed using any well-behaved activation function---sigmoid, tanh, parametric ReLU, ELU, and more---making our result quite general. The implication of the AUA theorem is that there exist provably correct neural networks: Suppose, for instance, that there is an ideal robust image classifier represented as function $f$. The AUA theorem tells us that there exists a neural network that approximates $f$ and for which we can automatically construct proofs of robustness using the interval abstract domain. Our work sheds light on the existence of provably correct neural networks, using arbitrary activation functions, and establishes intriguing connections between well-known theoretical properties of neural networks and abstract interpretation using numerical domains.
SeqDialN: Sequential Visual Dialog Networks in Joint Visual-Linguistic Representation Space
Aug 02, 2020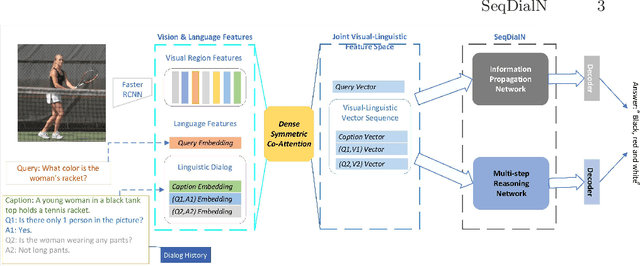

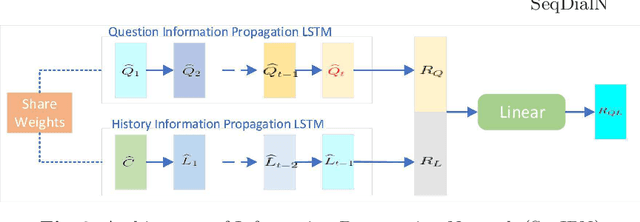
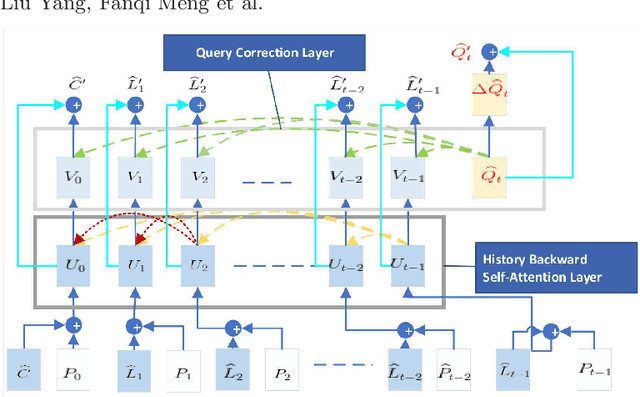
In this work, we formulate a visual dialog as an information flow in which each piece of information is encoded with the joint visual-linguistic representation of a single dialog round. Based on this formulation, we consider the visual dialog task as a sequence problem consisting of ordered visual-linguistic vectors. For featurization, we use a Dense Symmetric Co-Attention network as a lightweight vison-language joint representation generator to fuse multimodal features (i.e., image and text), yielding better computation and data efficiencies. For inference, we propose two Sequential Dialog Networks (SeqDialN): the first uses LSTM for information propagation (IP) and the second uses a modified Transformer for multi-step reasoning (MR). Our architecture separates the complexity of multimodal feature fusion from that of inference, which allows simpler design of the inference engine. IP based SeqDialN is our baseline with a simple 2-layer LSTM design that achieves decent performance. MR based SeqDialN, on the other hand, recurrently refines the semantic question/history representations through the self-attention stack of Transformer and produces promising results on the visual dialog task. On VisDial v1.0 test-std dataset, our best single generative SeqDialN achieves 62.54% NDCG and 48.63% MRR; our ensemble generative SeqDialN achieves 63.78% NDCG and 49.98% MRR, which set a new state-of-the-art generative visual dialog model. We fine-tune discriminative SeqDialN with dense annotations and boost the performance up to 72.41% NDCG and 55.11% MRR. In this work, we discuss the extensive experiments we have conducted to demonstrate the effectiveness of our model components. We also provide visualization for the reasoning process from the relevant conversation rounds and discuss our fine-tuning methods. Our code is available at https://github.com/xiaoxiaoheimei/SeqDialN
Hybrid Image Segmentation using Discerner Cluster in FCM and Histogram Thresholding
Feb 06, 2013Image thresholding has played an important role in image segmentation. This paper presents a hybrid approach for image segmentation based on the thresholding by fuzzy c-means (THFCM) algorithm for image segmentation. The goal of the proposed approach is to find a discerner cluster able to find an automatic threshold. The algorithm is formulated by applying the standard FCM clustering algorithm to the frequencies (y-values) on the smoothed histogram. Hence, the frequencies of an image can be used instead of the conventional whole data of image. The cluster that has the highest peak which represents the maximum frequency in the image histogram will play as an excellent role in determining a discerner cluster to the grey level image. Then, the pixels belong to the discerner cluster represent an object in the gray level histogram while the other clusters represent a background. Experimental results with standard test images have been obtained through the proposed approach (THFCM).
* 4 pages, 3 figures. arXiv admin note: text overlap with arXiv:1005.4020 by other authors
Regularizing Class-wise Predictions via Self-knowledge Distillation
Mar 31, 2020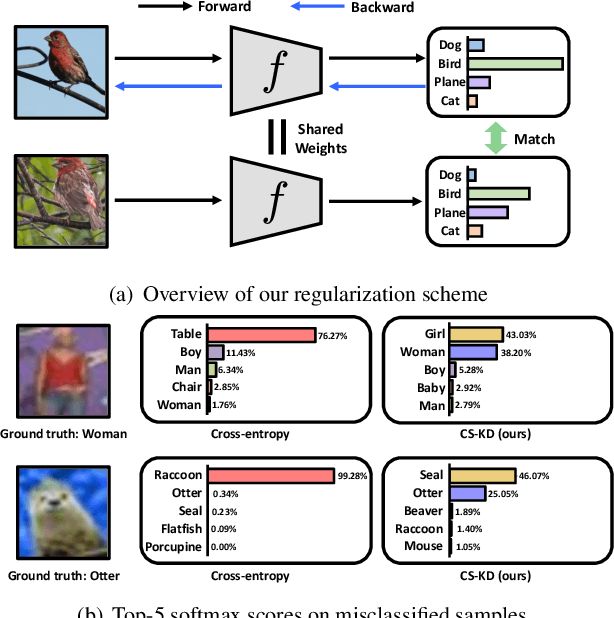
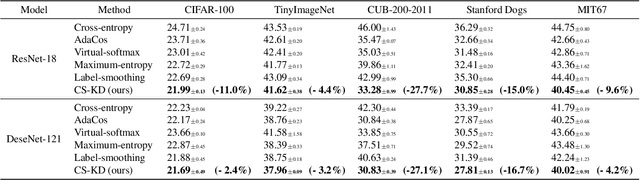
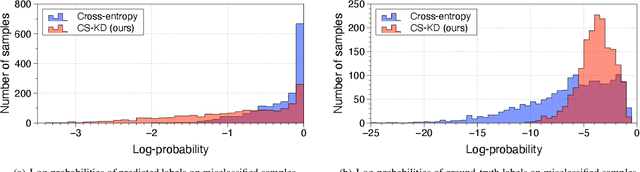

Deep neural networks with millions of parameters may suffer from poor generalization due to overfitting. To mitigate the issue, we propose a new regularization method that penalizes the predictive distribution between similar samples. In particular, we distill the predictive distribution between different samples of the same label during training. This results in regularizing the dark knowledge (i.e., the knowledge on wrong predictions) of a single network (i.e., a self-knowledge distillation) by forcing it to produce more meaningful and consistent predictions in a class-wise manner. Consequently, it mitigates overconfident predictions and reduces intra-class variations. Our experimental results on various image classification tasks demonstrate that the simple yet powerful method can significantly improve not only the generalization ability but also the calibration performance of modern convolutional neural networks.
Self-Supervised Learning Aided Class-Incremental Lifelong Learning
Jun 10, 2020
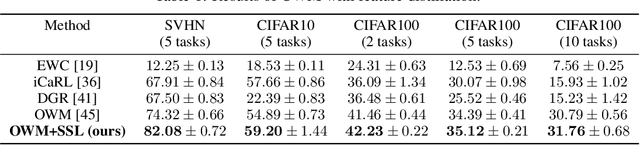
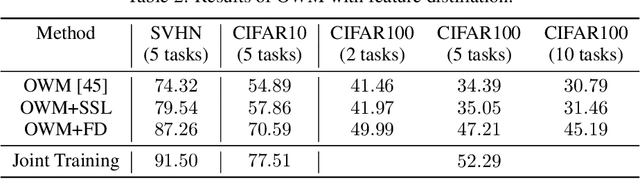
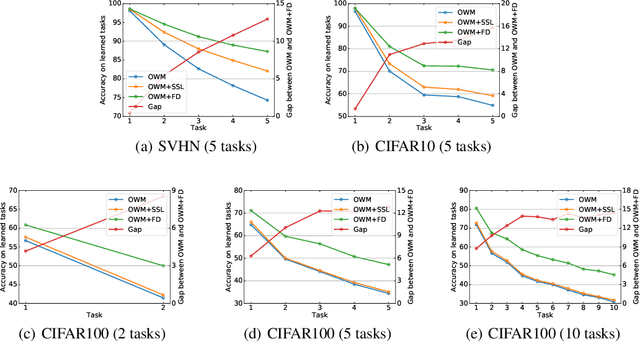
Lifelong or continual learning remains to be a challenge for artificial neural network, as it is required to be both stable for preservation of old knowledge and plastic for acquisition of new knowledge. It is common to see previous experience get overwritten, which leads to the well-known issue of catastrophic forgetting, especially in the scenario of class-incremental learning (Class-IL). Recently, many lifelong learning methods have been proposed to avoid catastrophic forgetting. However, models which learn without replay of the input data, would encounter another problem which has been ignored, and we refer to it as prior information loss (PIL). In training procedure of Class-IL, as the model has no knowledge about following tasks, it would only extract features necessary for tasks learned so far, whose information is insufficient for joint classification. In this paper, our empirical results on several image datasets show that PIL limits the performance of current state-of-the-art method for Class-IL, the orthogonal weights modification (OWM) algorithm. Furthermore, we propose to combine self-supervised learning, which can provide effective representations without requiring labels, with Class-IL to partly get around this problem. Experiments show superiority of proposed method to OWM, as well as other strong baselines.
Generative Adversarial Networks: A Survey and Taxonomy
Jun 14, 2019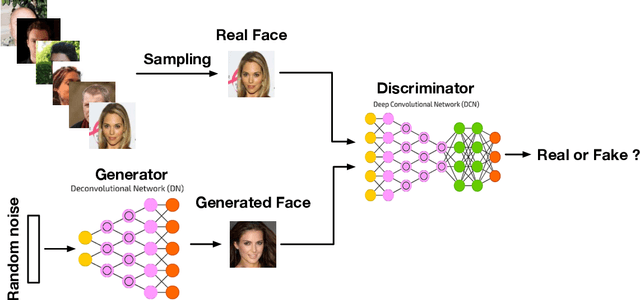
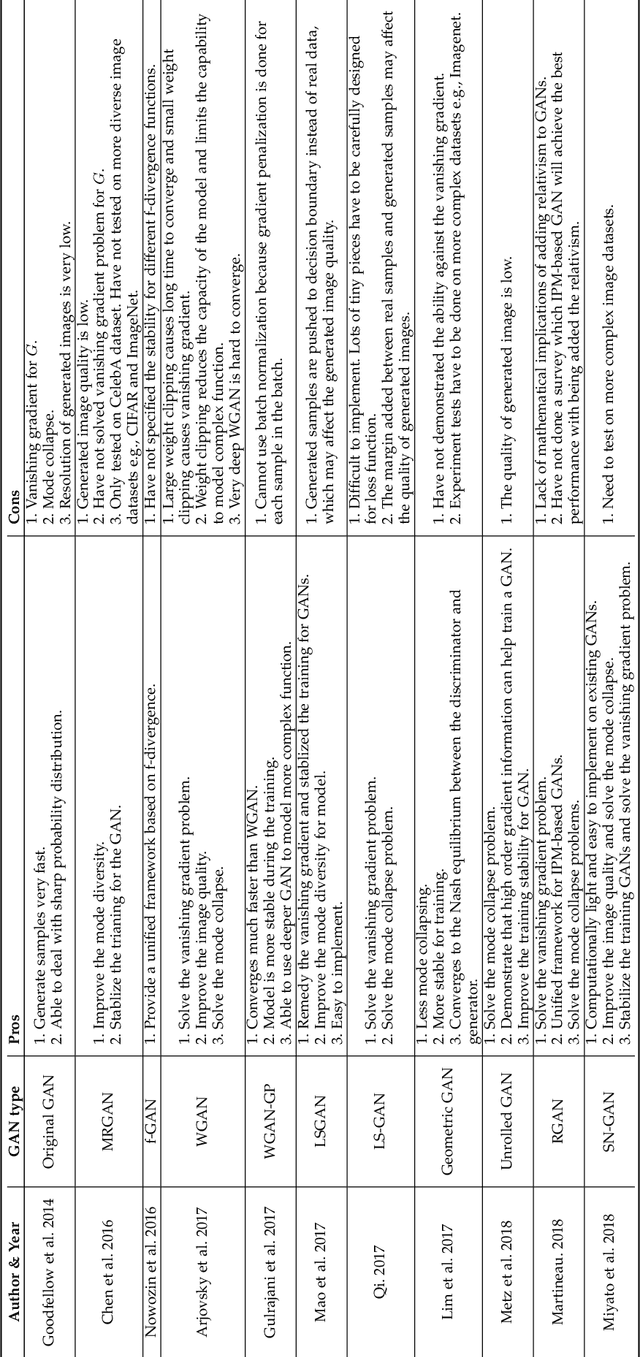
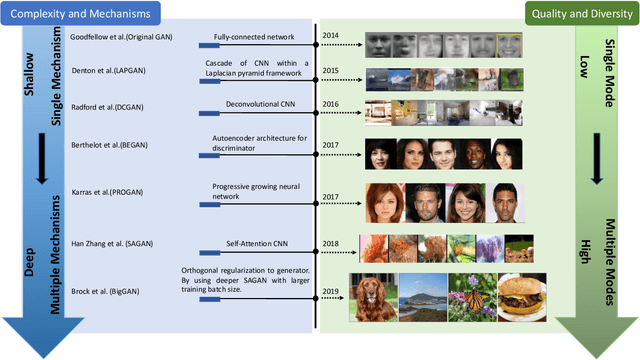
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in the computer vision field, applying GANs to real-world problems still poses significant challenges, three of which we focus on here: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Through an in-depth review of GAN-related research in the literature, we provide an account of the architecture-variants and loss-variants, which have been proposed to handle these three challenges from two perspectives. We propose loss-variants and architecture-variants for classifying the most popular GANs, and discuss the potential improvements with focusing on these two aspects. While several reviews for GANs have been presented to date, none have focused on the review of GAN-variants based on their handling the challenges mentioned above. In this paper, we review and critically discuss 7 architecture-variant GANs and 9 loss-variant GANs for remedying those three challenges. The objective of this review is to provide an insight on the footprint that current GANs research focuses on the performance improvement. Code related to GAN-variants studied in this work is summarized on https://github.com/sheqi/GAN_Review.
Joint Bilateral Learning for Real-time Universal Photorealistic Style Transfer
Apr 27, 2020
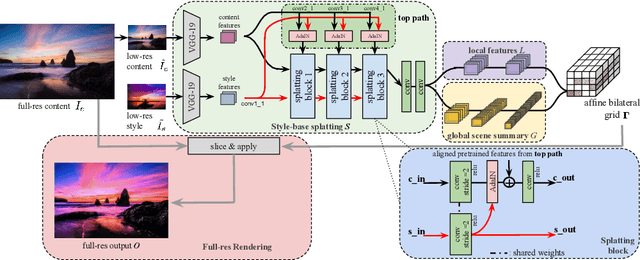


Photorealistic style transfer is the task of transferring the artistic style of an image onto a content target, producing a result that is plausibly taken with a camera. Recent approaches, based on deep neural networks, produce impressive results but are either too slow to run at practical resolutions, or still contain objectionable artifacts. We propose a new end-to-end model for photorealistic style transfer that is both fast and inherently generates photorealistic results. The core of our approach is a feed-forward neural network that learns local edge-aware affine transforms that automatically obey the photorealism constraint. When trained on a diverse set of images and a variety of styles, our model can robustly apply style transfer to an arbitrary pair of input images. Compared to the state of the art, our method produces visually superior results and is three orders of magnitude faster, enabling real-time performance at 4K on a mobile phone. We validate our method with ablation and user studies.