 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Edge of Depth: Explicit Constraints between Segmentation and Depth
Apr 01, 2020
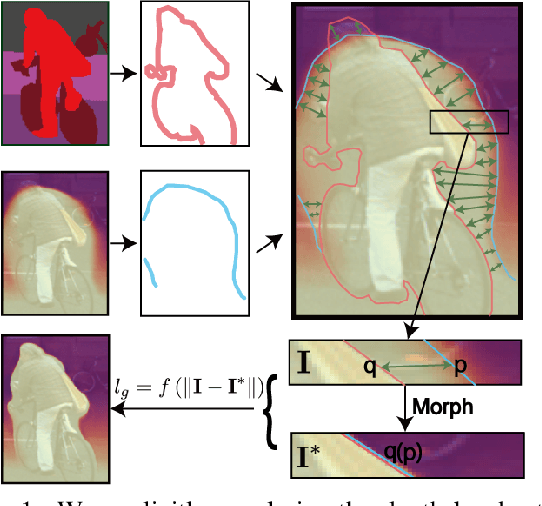
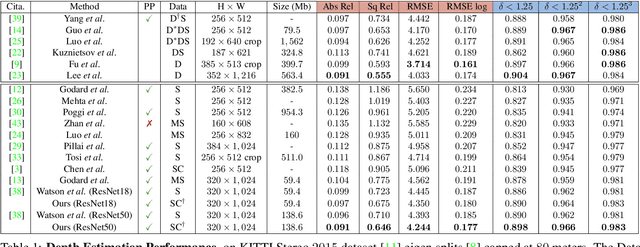
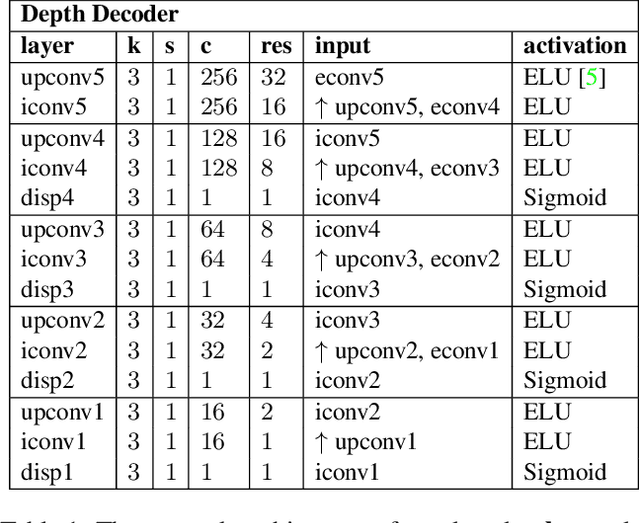
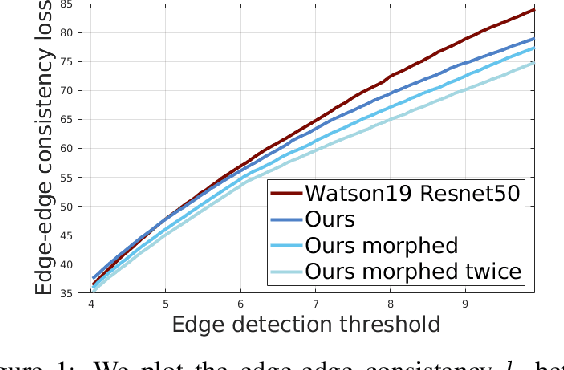
In this work we study the mutual benefits of two common computer vision tasks, self-supervised depth estimation and semantic segmentation from images. For example, to help unsupervised monocular depth estimation, constraints from semantic segmentation has been explored implicitly such as sharing and transforming features. In contrast, we propose to explicitly measure the border consistency between segmentation and depth and minimize it in a greedy manner by iteratively supervising the network towards a locally optimal solution. Partially this is motivated by our observation that semantic segmentation even trained with limited ground truth (200 images of KITTI) can offer more accurate border than that of any (monocular or stereo) image-based depth estimation. Through extensive experiments, our proposed approach advances the state of the art on unsupervised monocular depth estimation in the KITTI.
Privacy-Aware Activity Classification from First Person Office Videos
Jun 11, 2020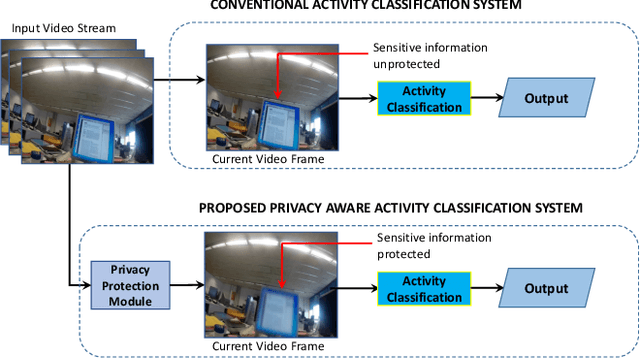

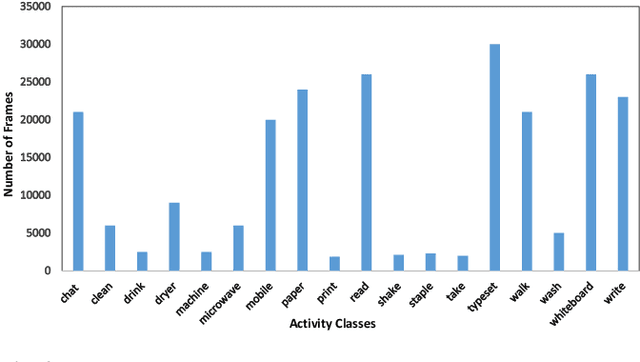

In the advent of wearable body-cameras, human activity classification from First-Person Videos (FPV) has become a topic of increasing importance for various applications, including in life-logging, law-enforcement, sports, workplace, and healthcare. One of the challenging aspects of FPV is its exposure to potentially sensitive objects within the user's field of view. In this work, we developed a privacy-aware activity classification system focusing on office videos. We utilized a Mask-RCNN with an Inception-ResNet hybrid as a feature extractor for detecting, and then blurring out sensitive objects (e.g., digital screens, human face, paper) from the videos. For activity classification, we incorporate an ensemble of Recurrent Neural Networks (RNNs) with ResNet, ResNext, and DenseNet based feature extractors. The proposed system was trained and evaluated on the FPV office video dataset that includes 18-classes made available through the IEEE Video and Image Processing (VIP) Cup 2019 competition. On the original unprotected FPVs, the proposed activity classifier ensemble reached an accuracy of 85.078% with precision, recall, and F1 scores of 0.88, 0.85 & 0.86, respectively. On privacy protected videos, the performances were slightly degraded, with accuracy, precision, recall, and F1 scores at 73.68%, 0.79, 0.75, and 0.74, respectively. The presented system won the 3rd prize in the IEEE VIP Cup 2019 competition.
Large scale near-duplicate image retrieval using Triples of Adjacent Ranked Features (TARF) with embedded geometric information
Mar 19, 2016
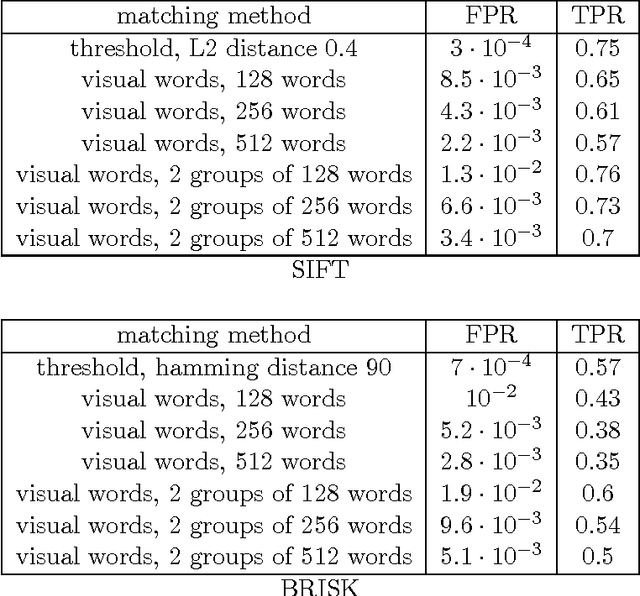

Most approaches to large-scale image retrieval are based on the construction of the inverted index of local image descriptors or visual words. A search in such an index usually results in a large number of candidates. This list of candidates is then re-ranked with the help of a geometric verification, using a RANSAC algorithm, for example. In this paper we propose a feature representation, which is built as a combination of three local descriptors. It allows one to significantly decrease the number of false matches and to shorten the list of candidates after the initial search in the inverted index. This combination of local descriptors is both reproducible and highly discriminative, and thus can be efficiently used for large-scale near-duplicate image retrieval.
Deep Semantic Matching with Foreground Detection and Cycle-Consistency
Mar 31, 2020
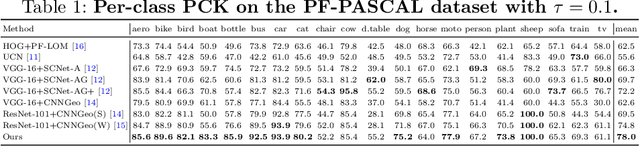
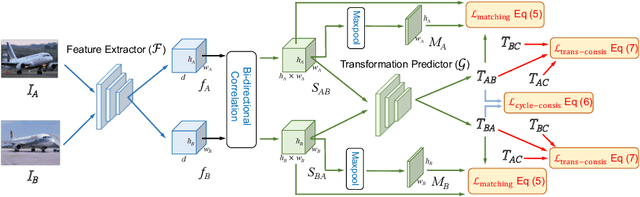
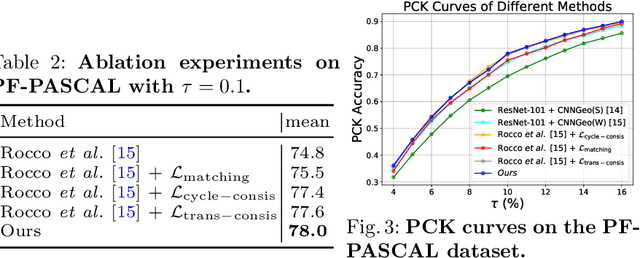
Establishing dense semantic correspondences between object instances remains a challenging problem due to background clutter, significant scale and pose differences, and large intra-class variations. In this paper, we address weakly supervised semantic matching based on a deep network where only image pairs without manual keypoint correspondence annotations are provided. To facilitate network training with this weaker form of supervision, we 1) explicitly estimate the foreground regions to suppress the effect of background clutter and 2) develop cycle-consistent losses to enforce the predicted transformations across multiple images to be geometrically plausible and consistent. We train the proposed model using the PF-PASCAL dataset and evaluate the performance on the PF-PASCAL, PF-WILLOW, and TSS datasets. Extensive experimental results show that the proposed approach performs favorably against the state-of-the-art methods.
Automated Labelling using an Attention model for Radiology reports of MRI scans (ALARM)
Feb 16, 2020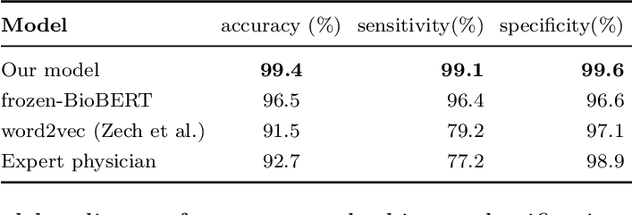
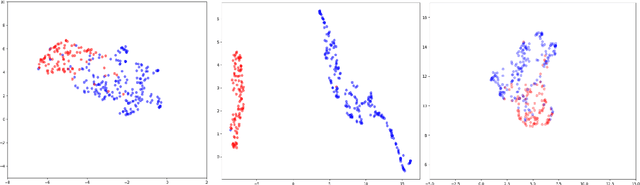


Labelling large datasets for training high-capacity neural networks is a major obstacle to the development of deep learning-based medical imaging applications. Here we present a transformer-based network for magnetic resonance imaging (MRI) radiology report classification which automates this task by assigning image labels on the basis of free-text expert radiology reports. Our model's performance is comparable to that of an expert radiologist, and better than that of an expert physician, demonstrating the feasibility of this approach. We make code available online for researchers to label their own MRI datasets for medical imaging applications.
Deep Hybrid Scattering Image Learning
Sep 19, 2018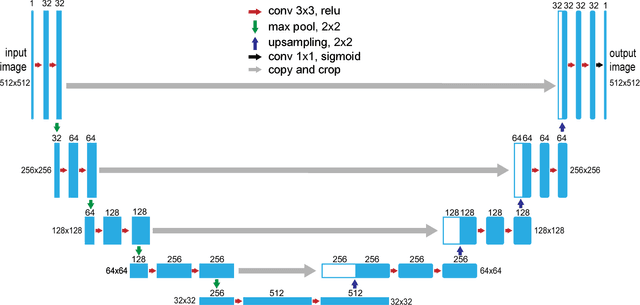
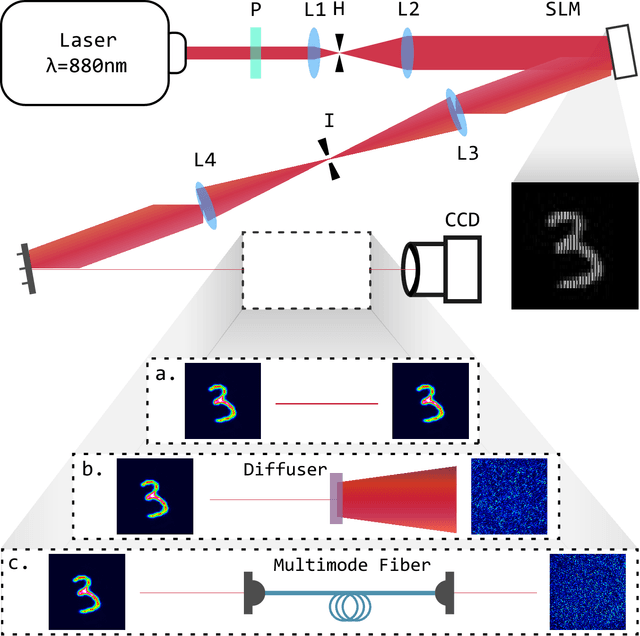
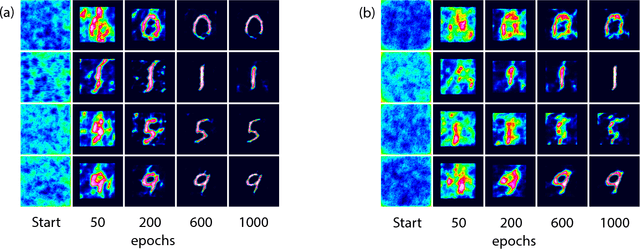
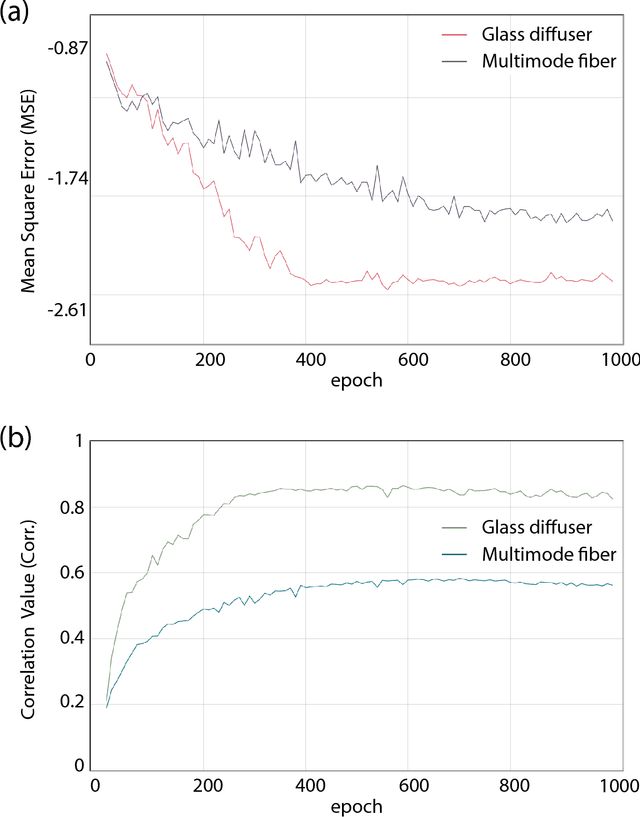
A well-trained deep neural network is shown to gain capability of simultaneously restoring two kinds of images, which are completely destroyed by two distinct scattering medias respectively. The network, based on the U-net architecture, can be trained by blended dataset of speckles-reference images pairs. We experimentally demonstrate the power of the network in reconstructing images which are strongly diffused by glass diffuser or multi-mode fiber. The learning model further shows good generalization ability to reconstruct images that are distinguished from the training dataset. Our work facilitates the study of optical transmission and expands machine learning's application in optics.
GPU Accelerated Fractal Image Compression for Medical Imaging in Parallel Computing Platform
Apr 03, 2014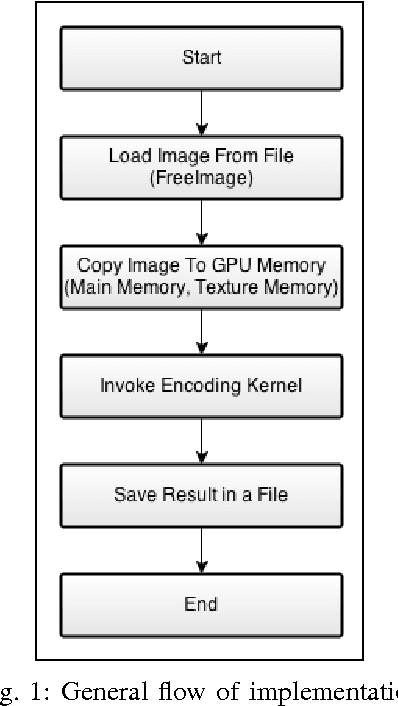
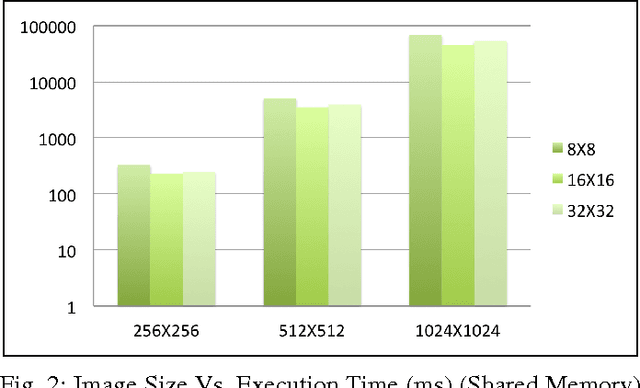
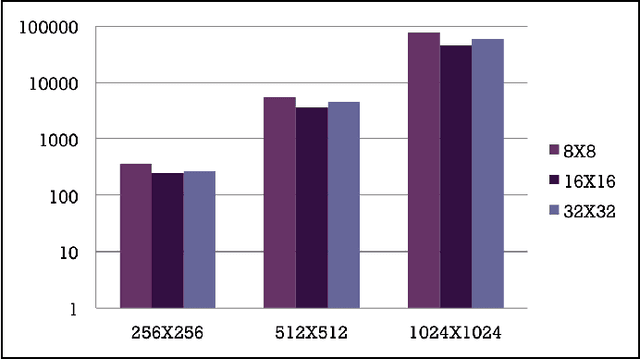
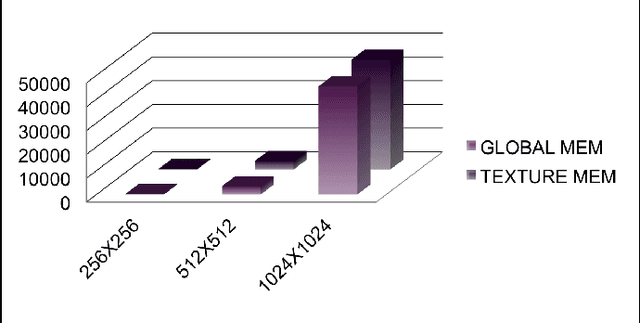
In this paper, we implemented both sequential and parallel version of fractal image compression algorithms using CUDA (Compute Unified Device Architecture) programming model for parallelizing the program in Graphics Processing Unit for medical images, as they are highly similar within the image itself. There are several improvement in the implementation of the algorithm as well. Fractal image compression is based on the self similarity of an image, meaning an image having similarity in majority of the regions. We take this opportunity to implement the compression algorithm and monitor the effect of it using both parallel and sequential implementation. Fractal compression has the property of high compression rate and the dimensionless scheme. Compression scheme for fractal image is of two kind, one is encoding and another is decoding. Encoding is very much computational expensive. On the other hand decoding is less computational. The application of fractal compression to medical images would allow obtaining much higher compression ratios. While the fractal magnification an inseparable feature of the fractal compression would be very useful in presenting the reconstructed image in a highly readable form. However, like all irreversible methods, the fractal compression is connected with the problem of information loss, which is especially troublesome in the medical imaging. A very time consuming encoding pro- cess, which can last even several hours, is another bothersome drawback of the fractal compression.
Post-hoc Calibration of Neural Networks
Jun 23, 2020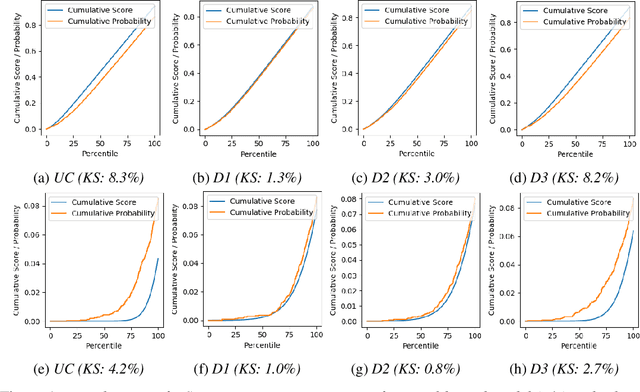

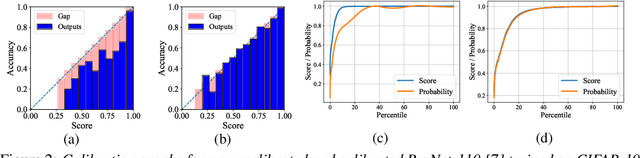
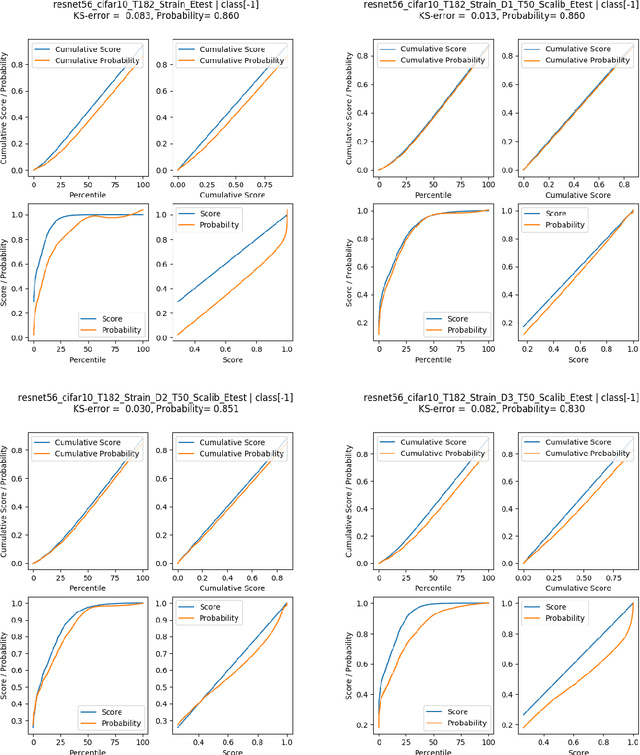
Calibration of neural networks is a critical aspect to consider when incorporating machine learning models in real-world decision-making systems where the confidence of decisions are equally important as the decisions themselves. In recent years, there is a surge of research on neural network calibration and the majority of the works can be categorized into post-hoc calibration methods, defined as methods that learn an additional function to calibrate an already trained base network. In this work, we intend to understand the post-hoc calibration methods from a theoretical point of view. Especially, it is known that minimizing Negative Log-Likelihood (NLL) will lead to a calibrated network on the training set if the global optimum is attained (Bishop, 1994). Nevertheless, it is not clear learning an additional function in a post-hoc manner would lead to calibration in the theoretical sense. To this end, we prove that even though the base network ($f$) does not lead to the global optimum of NLL, by adding additional layers ($g$) and minimizing NLL by optimizing the parameters of $g$ one can obtain a calibrated network $g \circ f$. This not only provides a less stringent condition to obtain a calibrated network but also provides a theoretical justification of post-hoc calibration methods. Our experiments on various image classification benchmarks confirm the theory.
A Survey on Recent Advancements for AI Enabled Radiomics in Neuro-Oncology
Oct 16, 2019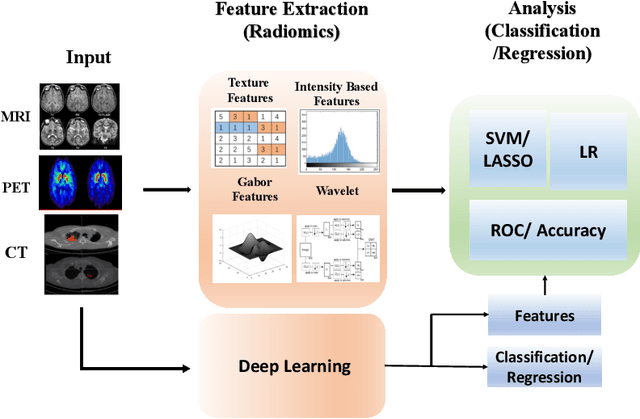
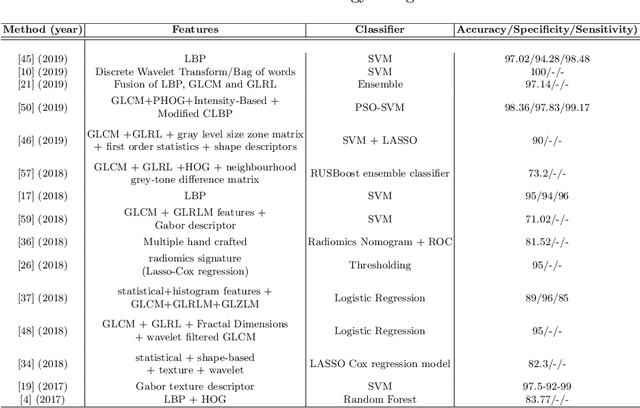
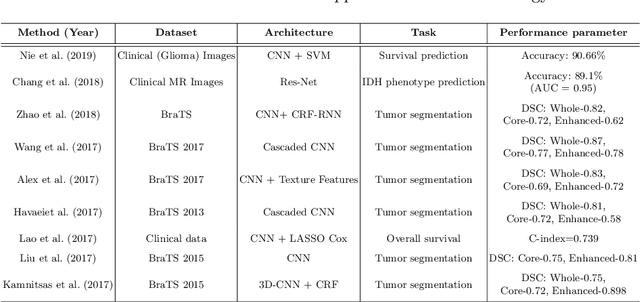
Artificial intelligence (AI) enabled radiomics has evolved immensely especially in the field of oncology. Radiomics provide assistancein diagnosis of cancer, planning of treatment strategy, and predictionof survival. Radiomics in neuro-oncology has progressed significantly inthe recent past. Deep learning has outperformed conventional machinelearning methods in most image-based applications. Convolutional neu-ral networks (CNNs) have seen some popularity in radiomics, since theydo not require hand-crafted features and can automatically extract fea-tures during the learning process. In this regard, it is observed that CNNbased radiomics could provide state-of-the-art results in neuro-oncology,similar to the recent success of such methods in a wide spectrum ofmedical image analysis applications. Herein we present a review of the most recent best practices and establish the future trends for AI enabled radiomics in neuro-oncology.
Inverse Graphics: Unsupervised Learning of 3D Shapes from Single Images
Dec 02, 2019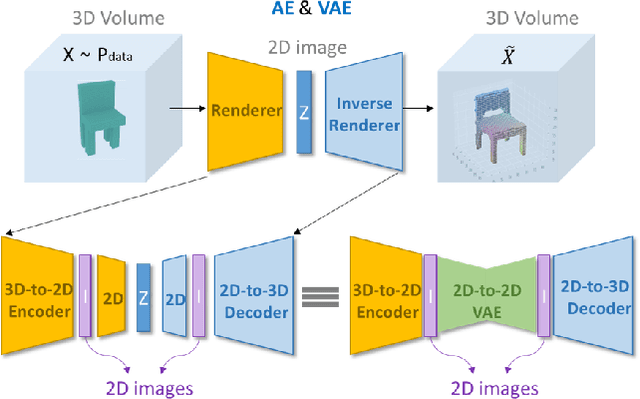

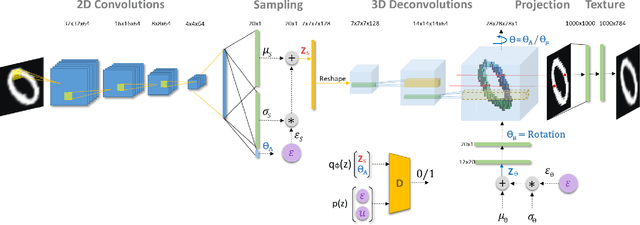
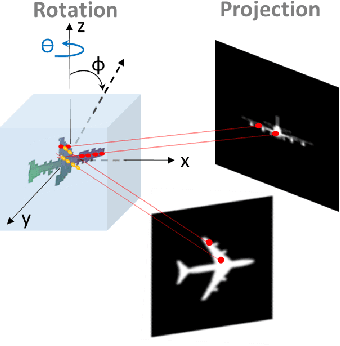
Using generative models for Inverse Graphics is an active area of research. However, most works focus on developing models for supervised and semi-supervised methods. In this paper, we study the problem of unsupervised learning of 3D geometry from single images. Our approach is to use a generative model that produces 2-D images as projections of a latent 3D voxel grid, which we train either as a variational auto-encoder or using adversarial methods. Our contributions are as follows: First, we show how to recover 3D shape and pose from general datasets such as MNIST, and MNIST Fashion in good quality. Second, we compare the shapes learned using adversarial and variational methods. Adversarial approach gives denser 3D shapes. Third, we explore the idea of modelling the pose of an object as uniform distribution to recover 3D shape from a single image. Our experiment with the CelebA dataset \cite{liu2015faceattributes} proves that we can recover complete 3D shape from a single image when the object is symmetric along one, or more axis whilst results obtained using ModelNet40 \cite{wu20153d} show the potential side-effects, in which the model learns 3D shapes such that it can render the same image from any viewpoint. Forth, we present a general end-to-end approach to learning 3D shapes from single images in a completely unsupervised fashion by modelling the factors of variation such as azimuth as independent latent variables. Our method makes no assumptions about the dataset, and can work with synthetic as well as real images (i.e. unsupervised in true sense). We present our results, by training the model using the $\mu$-VAE objective \cite{ucar2019bridging} and a dataset combining all images from MNIST, MNIST Fashion, CelebA and six categories of ModelNet40. The model is able to learn 3D shapes and the pose in qood quality and leverages information learned across all datasets.