 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo is better than one: A Collapse-free Multi-Reward RLIF Training Framework
May 21, 2026Reinforcement learning with verifiable rewards (RLVR) has substantially improved the reasoning ability of LLMs, but often depends on external supervision from human annotations or gold-standard solutions. Reinforcement learning from internal feedback (RLIF) has recently emerged as a scalable unsupervised alternative, using signals extracted from the model itself. However, existing RLIF methods typically rely on a single internal reward, which can lead to reward hacking, entropy collapse, and degraded reasoning structure. We propose a multi-reward RLIF framework that decomposes the training signal into two complementary components: an answer-level reward based on cluster voting and a completion-level reward based on token-wise self-certainty. To combine these signals robustly, we apply GDPO-based normalization to reduce reward-scale imbalance. We further introduce KL-Cov regularization, which targets low-entropy token distributions responsible for disproportionate entropy reduction, preserving exploration and preventing late-stage collapse. Across mathematical reasoning and code-generation benchmarks, our method improves stability and robustness over prior unsupervised RL approaches, while achieving performance close to supervised RLVR methods. These results show that complementary internal rewards, combined with targeted regularization, can support stable long-horizon reasoning without relying on external ground-truth supervision. Code will be released soon.
Addressing Bias in VLMs for Glaucoma Detection Without Protected Attribute Supervision
Aug 12, 2025Vision-Language Models (VLMs) have achieved remarkable success on multimodal tasks such as image-text retrieval and zero-shot classification, yet they can exhibit demographic biases even when explicit protected attributes are absent during training. In this work, we focus on automated glaucoma screening from retinal fundus images, a critical application given that glaucoma is a leading cause of irreversible blindness and disproportionately affects underserved populations. Building on a reweighting-based contrastive learning framework, we introduce an attribute-agnostic debiasing method that (i) infers proxy subgroups via unsupervised clustering of image-image embeddings, (ii) computes gradient-similarity weights between the CLIP-style multimodal loss and a SimCLR-style image-pair contrastive loss, and (iii) applies these weights in a joint, top-$k$ weighted objective to upweight underperforming clusters. This label-free approach adaptively targets the hardest examples, thereby reducing subgroup disparities. We evaluate our method on the Harvard FairVLMed glaucoma subset, reporting Equalized Odds Distance (EOD), Equalized Subgroup AUC (ES AUC), and Groupwise AUC to demonstrate equitable performance across inferred demographic subgroups.
SW-ViT: A Spatio-Temporal Vision Transformer Network with Post Denoiser for Sequential Multi-Push Ultrasound Shear Wave Elastography
May 24, 2025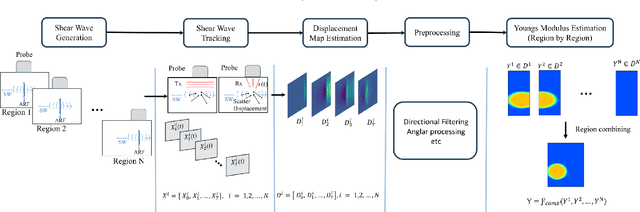



Objective: Ultrasound Shear Wave Elastography (SWE) demonstrates great potential in assessing soft-tissue pathology by mapping tissue stiffness, which is linked to malignancy. Traditional SWE methods have shown promise in estimating tissue elasticity, yet their susceptibility to noise interference, reliance on limited training data, and inability to generate segmentation masks concurrently present notable challenges to accuracy and reliability. Approach: In this paper, we propose SW-ViT, a novel two-stage deep learning framework for SWE that integrates a CNN-Spatio-Temporal Vision Transformer-based reconstruction network with an efficient Transformer-based post-denoising network. The first stage uses a 3D ResNet encoder with multi-resolution spatio-temporal Transformer blocks that capture spatial and temporal features, followed by a squeeze-and-excitation attention decoder that reconstructs 2D stiffness maps. To address data limitations, a patch-based training strategy is adopted for localized learning and reconstruction. In the second stage, a denoising network with a shared encoder and dual decoders processes inclusion and background regions to produce a refined stiffness map and segmentation mask. A hybrid loss combining regional, smoothness, fusion, and Intersection over Union (IoU) components ensures improvements in both reconstruction and segmentation. Results: On simulated data, our method achieves PSNR of 32.68 dB, CNR of 46.78 dB, and SSIM of 0.995. On phantom data, results include PSNR of 21.11 dB, CNR of 42.14 dB, and SSIM of 0.936. Segmentation IoU values reach 0.949 (simulation) and 0.738 (phantom) with ASSD values being 0.184 and 1.011, respectively. Significance: SW-ViT delivers robust, high-quality elasticity map estimates from noisy SWE data and holds clear promise for clinical application.
SegCodeNet: Color-Coded Segmentation Masks for Activity Detection from Wearable Cameras
Aug 19, 2020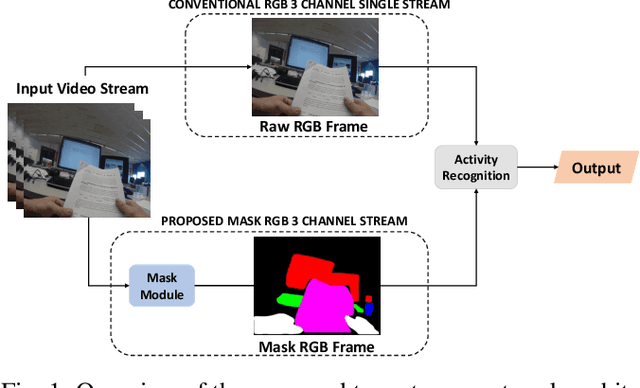
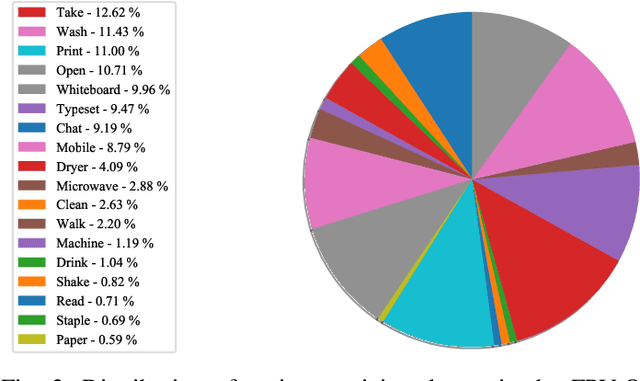
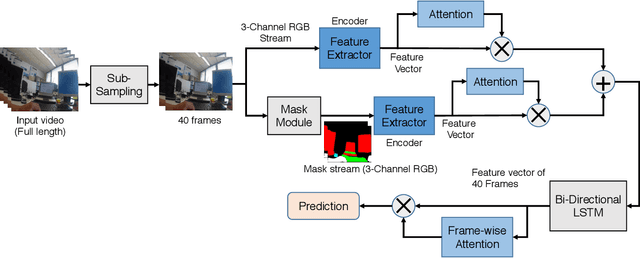
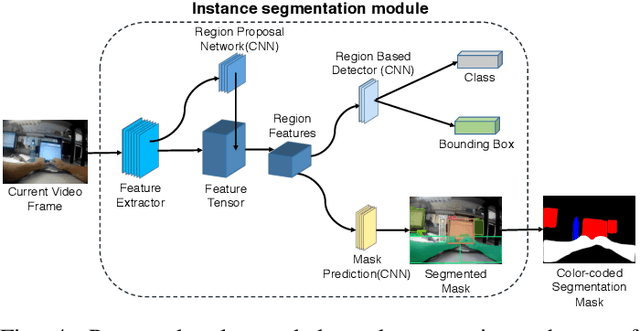
Activity detection from first-person videos (FPV) captured using a wearable camera is an active research field with potential applications in many sectors, including healthcare, law enforcement, and rehabilitation. State-of-the-art methods use optical flow-based hybrid techniques that rely on features derived from the motion of objects from consecutive frames. In this work, we developed a two-stream network, the \emph{SegCodeNet}, that uses a network branch containing video-streams with color-coded semantic segmentation masks of relevant objects in addition to the original RGB video-stream. We also include a stream-wise attention gating that prioritizes between the two streams and a frame-wise attention module that prioritizes the video frames that contain relevant features. Experiments are conducted on an FPV dataset containing $18$ activity classes in office environments. In comparison to a single-stream network, the proposed two-stream method achieves an absolute improvement of $14.366\%$ and $10.324\%$ for averaged F1 score and accuracy, respectively, when average results are compared for three different frame sizes $224\times224$, $112\times112$, and $64\times64$. The proposed method provides significant performance gains for lower-resolution images with absolute improvements of $17\%$ and $26\%$ in F1 score for input dimensions of $112\times112$ and $64\times64$, respectively. The best performance is achieved for a frame size of $224\times224$ yielding an F1 score and accuracy of $90.176\%$ and $90.799\%$ which outperforms the state-of-the-art Inflated 3D ConvNet (I3D) \cite{carreira2017quo} method by an absolute margin of $4.529\%$ and $2.419\%$, respectively.
Privacy-Aware Activity Classification from First Person Office Videos
Jun 11, 2020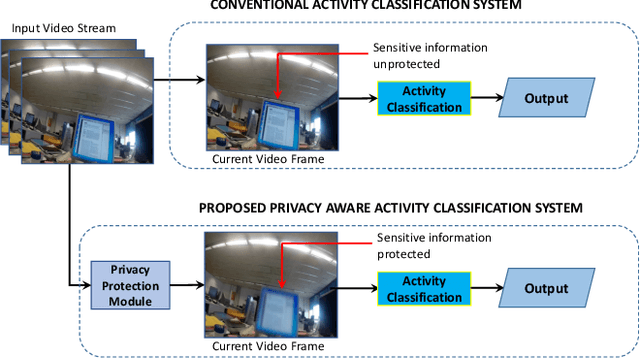

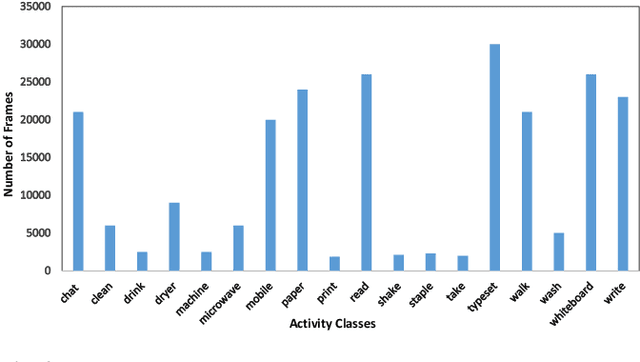

In the advent of wearable body-cameras, human activity classification from First-Person Videos (FPV) has become a topic of increasing importance for various applications, including in life-logging, law-enforcement, sports, workplace, and healthcare. One of the challenging aspects of FPV is its exposure to potentially sensitive objects within the user's field of view. In this work, we developed a privacy-aware activity classification system focusing on office videos. We utilized a Mask-RCNN with an Inception-ResNet hybrid as a feature extractor for detecting, and then blurring out sensitive objects (e.g., digital screens, human face, paper) from the videos. For activity classification, we incorporate an ensemble of Recurrent Neural Networks (RNNs) with ResNet, ResNext, and DenseNet based feature extractors. The proposed system was trained and evaluated on the FPV office video dataset that includes 18-classes made available through the IEEE Video and Image Processing (VIP) Cup 2019 competition. On the original unprotected FPVs, the proposed activity classifier ensemble reached an accuracy of 85.078% with precision, recall, and F1 scores of 0.88, 0.85 & 0.86, respectively. On privacy protected videos, the performances were slightly degraded, with accuracy, precision, recall, and F1 scores at 73.68%, 0.79, 0.75, and 0.74, respectively. The presented system won the 3rd prize in the IEEE VIP Cup 2019 competition.