 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generic Image Classification Approaches Excel on Face Recognition
Sep 30, 2013
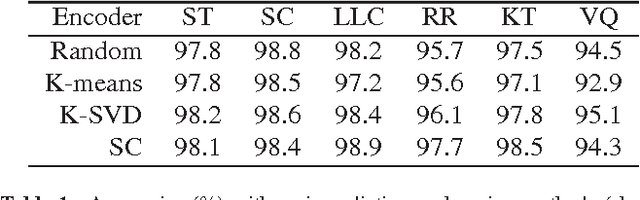
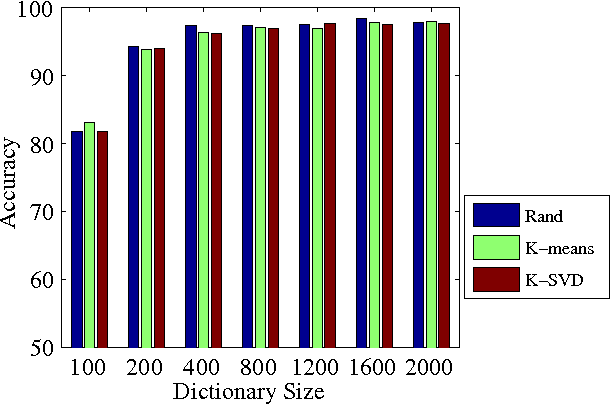

The main finding of this work is that the standard image classification pipeline, which consists of dictionary learning, feature encoding, spatial pyramid pooling and linear classification, outperforms all state-of-the-art face recognition methods on the tested benchmark datasets (we have tested on AR, Extended Yale B, the challenging FERET, and LFW-a datasets). This surprising and prominent result suggests that those advances in generic image classification can be directly applied to improve face recognition systems. In other words, face recognition may not need to be viewed as a separate object classification problem. While recently a large body of residual based face recognition methods focus on developing complex dictionary learning algorithms, in this work we show that a dictionary of randomly extracted patches (even from non-face images) can achieve very promising results using the image classification pipeline. That means, the choice of dictionary learning methods may not be important. Instead, we find that learning multiple dictionaries using different low-level image features often improve the final classification accuracy. Our proposed face recognition approach offers the best reported results on the widely-used face recognition benchmark datasets. In particular, on the challenging FERET and LFW-a datasets, we improve the best reported accuracies in the literature by about 20% and 30% respectively.
Encoder-Decoder based CNN and Fully Connected CRFs for Remote Sensed Image Segmentation
Oct 14, 2019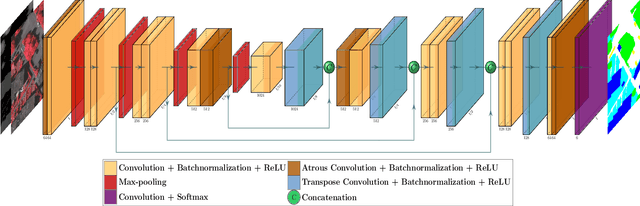
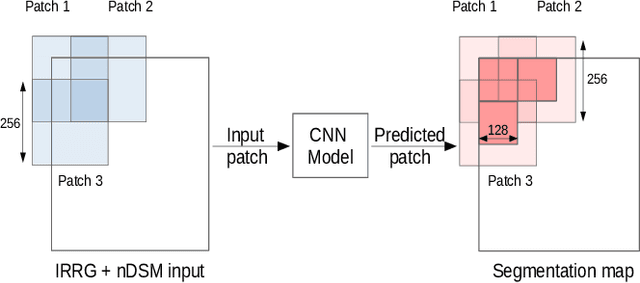

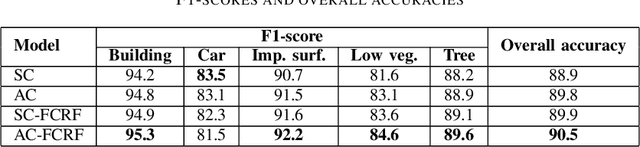
With the advancement of remote-sensed imaging large volumes of very high resolution land cover images can now be obtained. Automation of object recognition in these 2D images, however, is still a key issue. High intra-class variance and low inter-class variance in Very High Resolution (VHR) images hamper the accuracy of prediction in object recognition tasks. Most successful techniques in various computer vision tasks recently are based on deep supervised learning. In this work, a deep Convolutional Neural Network (CNN) based on symmetric encoder-decoder architecture with skip connections is employed for the 2D semantic segmentation of most common land cover object classes - impervious surface, buildings, low vegetation, trees and cars. Atrous convolutions are employed to have large receptive field in the proposed CNN model. Further, the CNN outputs are post-processed using Fully Connected Conditional Random Field (FCRF) model to refine the CNN pixel label predictions. The proposed CNN-FCRF model achieves an overall accuracy of 90.5% on the ISPRS Vaihingen Dataset.
MBIS: Multivariate Bayesian Image Segmentation Tool
Apr 07, 2014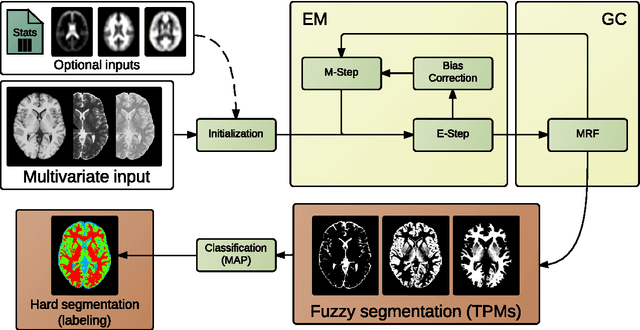
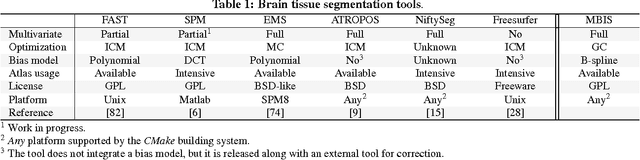
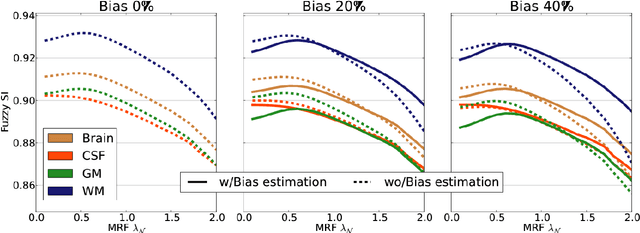
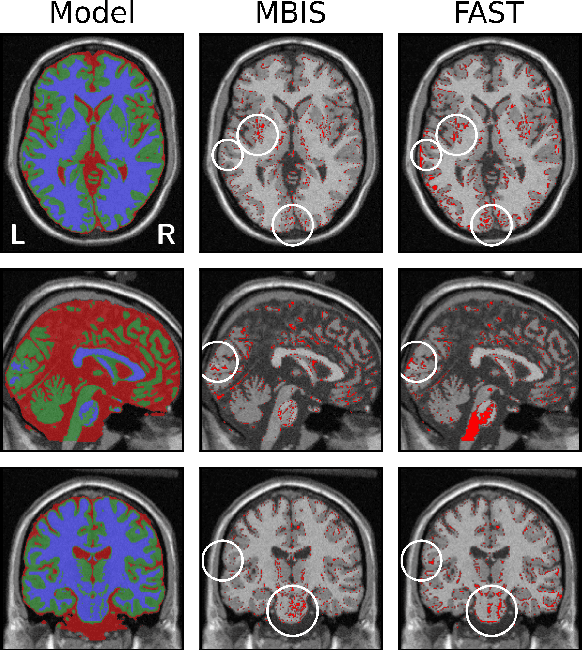
We present MBIS (Multivariate Bayesian Image Segmentation tool), a clustering tool based on the mixture of multivariate normal distributions model. MBIS supports multi-channel bias field correction based on a B-spline model. A second methodological novelty is the inclusion of graph-cuts optimization for the stationary anisotropic hidden Markov random field model. Along with MBIS, we release an evaluation framework that contains three different experiments on multi-site data. We first validate the accuracy of segmentation and the estimated bias field for each channel. MBIS outperforms a widely used segmentation tool in a cross-comparison evaluation. The second experiment demonstrates the robustness of results on atlas-free segmentation of two image sets from scan-rescan protocols on 21 healthy subjects. Multivariate segmentation is more replicable than the monospectral counterpart on T1-weighted images. Finally, we provide a third experiment to illustrate how MBIS can be used in a large-scale study of tissue volume change with increasing age in 584 healthy subjects. This last result is meaningful as multivariate segmentation performs robustly without the need for prior knowledge
Deep Categorization with Semi-Supervised Self-Organizing Maps
Jun 17, 2020
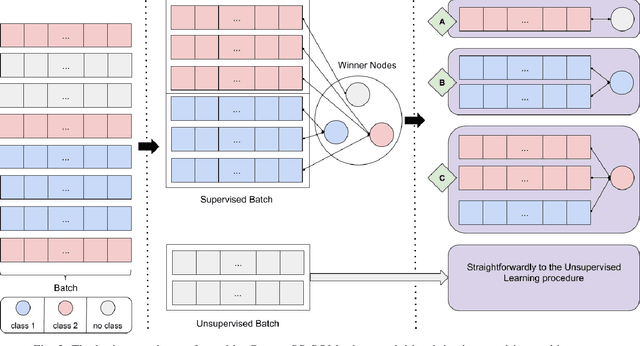
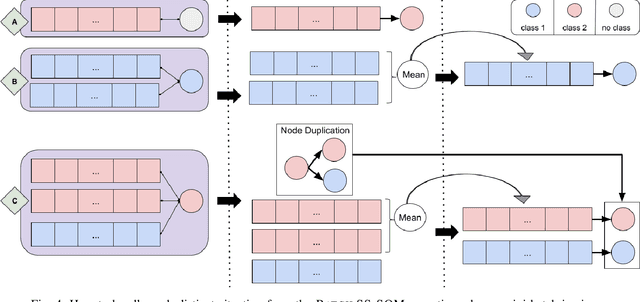

Nowadays, with the advance of technology, there is an increasing amount of unstructured data being generated every day. However, it is a painful job to label and organize it. Labeling is an expensive, time-consuming, and difficult task. It is usually done manually, which collaborates with the incorporation of noise and errors to the data. Hence, it is of great importance to developing intelligent models that can benefit from both labeled and unlabeled data. Currently, works on unsupervised and semi-supervised learning are still being overshadowed by the successes of purely supervised learning. However, it is expected that they become far more important in the longer term. This article presents a semi-supervised model, called Batch Semi-Supervised Self-Organizing Map (Batch SS-SOM), which is an extension of a SOM incorporating some advances that came with the rise of Deep Learning, such as batch training. The results show that Batch SS-SOM is a good option for semi-supervised classification and clustering. It performs well in terms of accuracy and clustering error, even with a small number of labeled samples, as well as when presented to unsupervised data, and shows competitive results in transfer learning scenarios in traditional image classification benchmark datasets.
Simultaneous Hand Pose and Skeleton Bone-Lengths Estimation from a Single Depth Image
Dec 08, 2017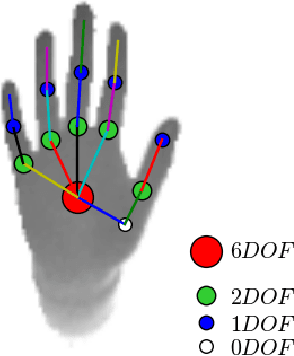
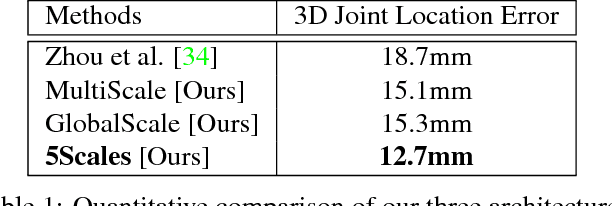
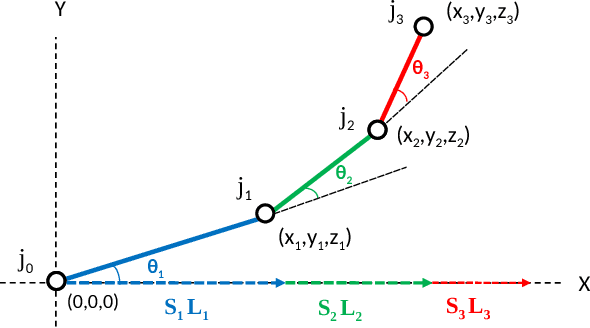

Articulated hand pose estimation is a challenging task for human-computer interaction. The state-of-the-art hand pose estimation algorithms work only with one or a few subjects for which they have been calibrated or trained. Particularly, the hybrid methods based on learning followed by model fitting or model based deep learning do not explicitly consider varying hand shapes and sizes. In this work, we introduce a novel hybrid algorithm for estimating the 3D hand pose as well as bone-lengths of the hand skeleton at the same time, from a single depth image. The proposed CNN architecture learns hand pose parameters and scale parameters associated with the bone-lengths simultaneously. Subsequently, a new hybrid forward kinematics layer employs both parameters to estimate 3D joint positions of the hand. For end-to-end training, we combine three public datasets NYU, ICVL and MSRA-2015 in one unified format to achieve large variation in hand shapes and sizes. Among hybrid methods, our method shows improved accuracy over the state-of-the-art on the combined dataset and the ICVL dataset that contain multiple subjects. Also, our algorithm is demonstrated to work well with unseen images.
Gender Slopes: Counterfactual Fairness for Computer Vision Models by Attribute Manipulation
May 21, 2020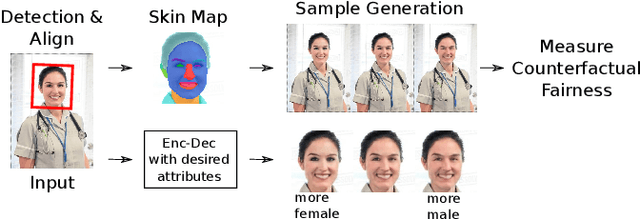
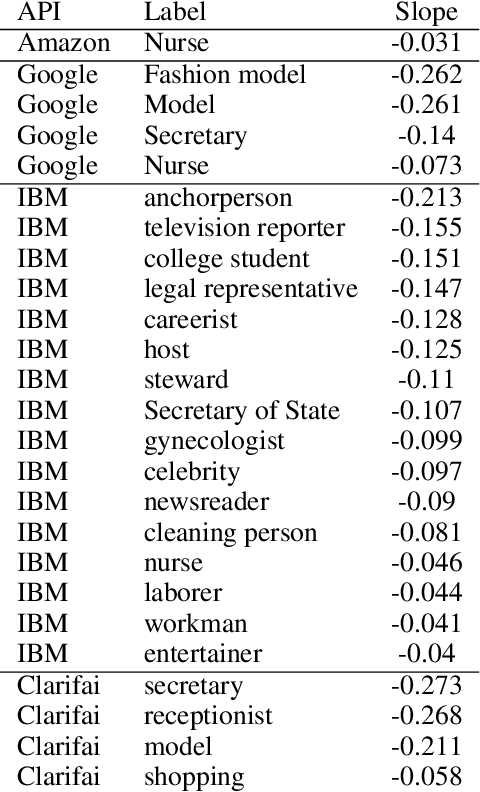

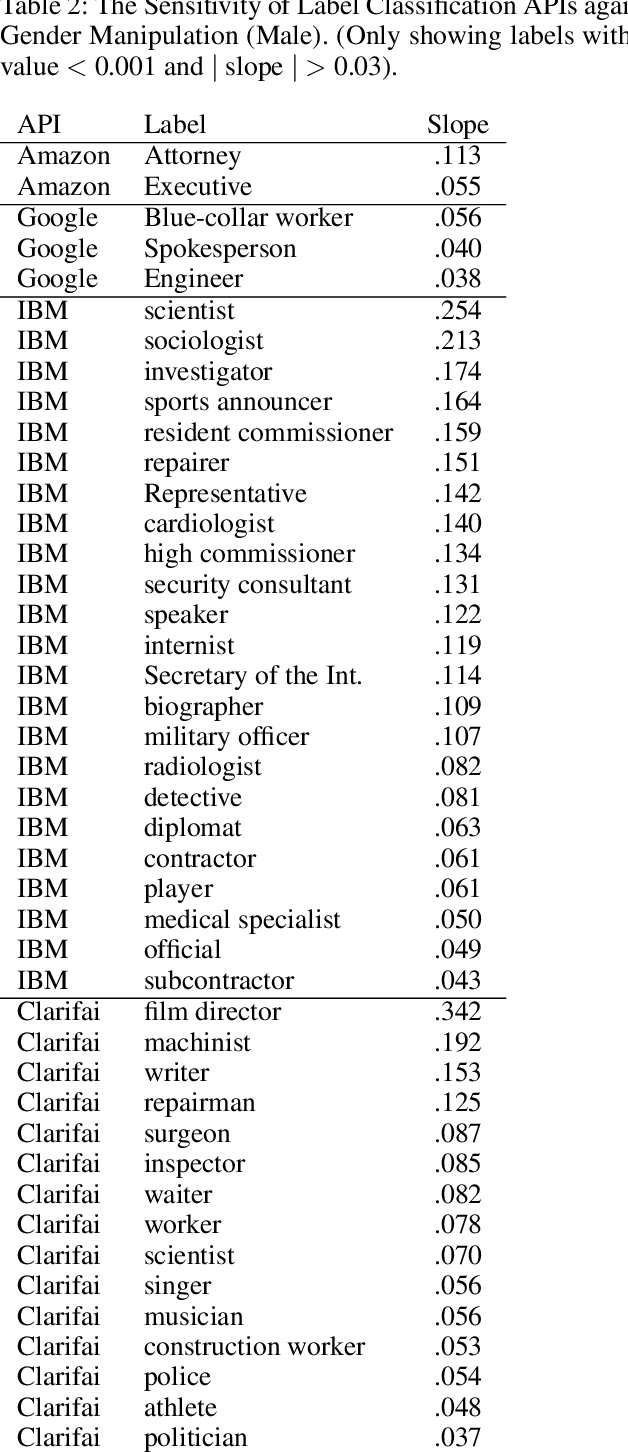
Automated computer vision systems have been applied in many domains including security, law enforcement, and personal devices, but recent reports suggest that these systems may produce biased results, discriminating against people in certain demographic groups. Diagnosing and understanding the underlying true causes of model biases, however, are challenging tasks because modern computer vision systems rely on complex black-box models whose behaviors are hard to decode. We propose to use an encoder-decoder network developed for image attribute manipulation to synthesize facial images varying in the dimensions of gender and race while keeping other signals intact. We use these synthesized images to measure counterfactual fairness of commercial computer vision classifiers by examining the degree to which these classifiers are affected by gender and racial cues controlled in the images, e.g., feminine faces may elicit higher scores for the concept of nurse and lower scores for STEM-related concepts. We also report the skewed gender representations in an online search service on profession-related keywords, which may explain the origin of the biases encoded in the models.
Learning from Small Data Through Sampling an Implicit Conditional Generative Latent Optimization Model
Apr 17, 2020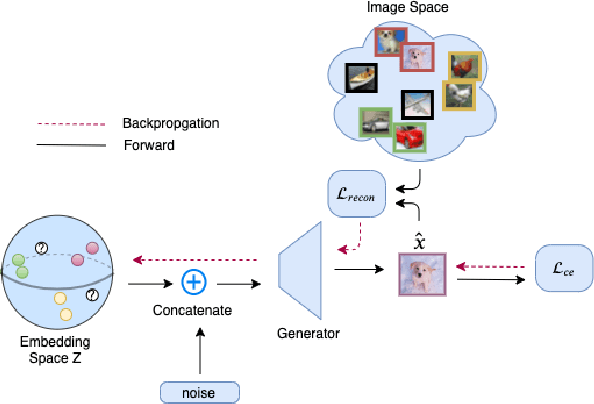

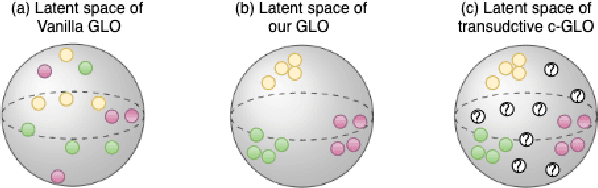

We revisit the long-standing problem of \emph{learning from small sample}. In recent years major efforts have been invested into the generation of new samples from a small set of training data points. Some use classical transformations, others synthesize new examples. Our approach belongs to the second one. We propose a new model based on conditional Generative Latent Optimization (cGLO). Our model learns to synthesize completely new samples for every class just by interpolating between samples in the latent space. The proposed method samples the learned latent space using spherical interpolations (\emph{slerp}) and generates a new sample using the trained generator. Our empirical results show that the new sampled set is diverse enough, leading to improvement in image classification in comparison to the state of the art, when trained on small samples of CIFAR-100 and CUB-200.
Improving Limited Angle CT Reconstruction with a Robust GAN Prior
Oct 14, 2019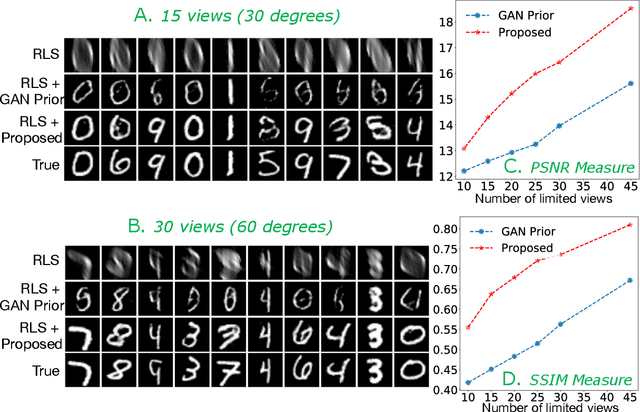
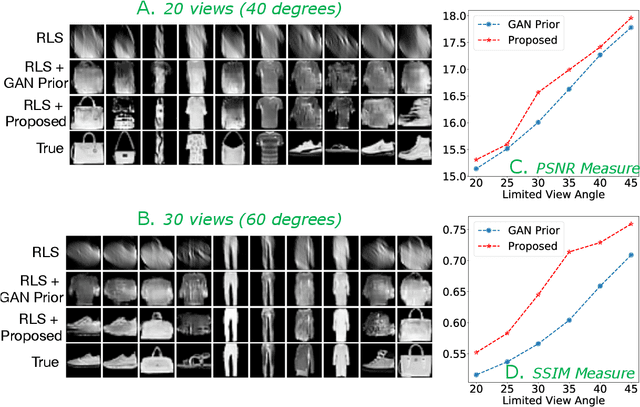
Limited angle CT reconstruction is an under-determined linear inverse problem that requires appropriate regularization techniques to be solved. In this work we study how pre-trained generative adversarial networks (GANs) can be used to clean noisy, highly artifact laden reconstructions from conventional techniques, by effectively projecting onto the inferred image manifold. In particular, we use a robust version of the popularly used GAN prior for inverse problems, based on a recent technique called corruption mimicking, that significantly improves the reconstruction quality. The proposed approach operates in the image space directly, as a result of which it does not need to be trained or require access to the measurement model, is scanner agnostic, and can work over a wide range of sensing scenarios.
Augmented Reality on the Large Scene Based on a Markerless Registration Framework
Mar 07, 2020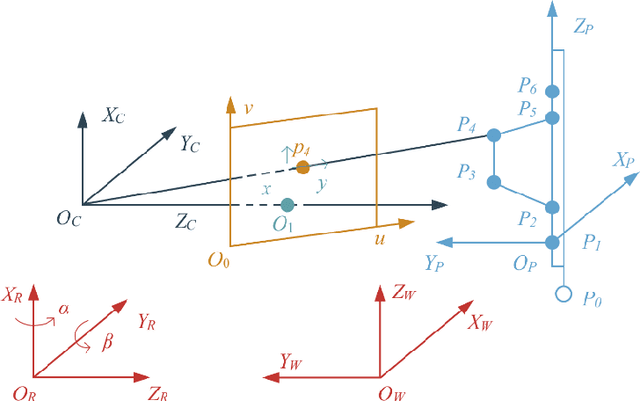

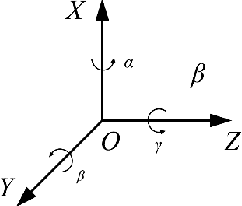
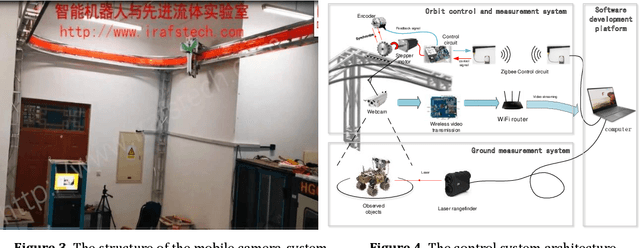
In this paper, a mobile camera positioning method based on forward and inverse kinematics of robot is proposed, which can realize far point positioning of imaging position and attitude tracking in large scene enhancement. Orbit precision motion through the framework overhead cameras and combining with the ground system of sensor array object such as mobile robot platform of various sensors, realize the good 3 d image registration, solve any artifacts that is mobile robot in the large space position initialization problem, effectively implement the large space no marks augmented reality, human-computer interaction, and information summary. Finally, the feasibility and effectiveness of the method are verified by experiments.
Ensemble Sparse Models for Image Analysis
Feb 27, 2013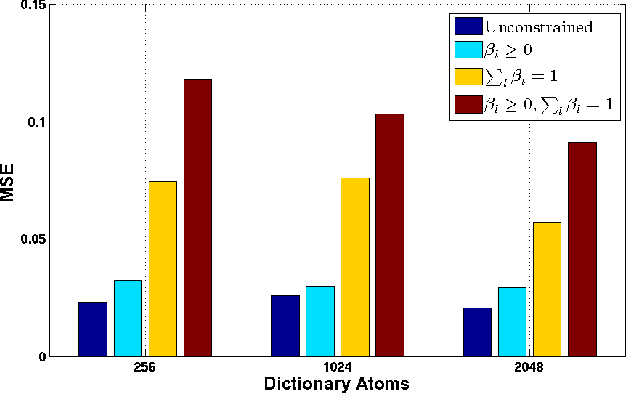
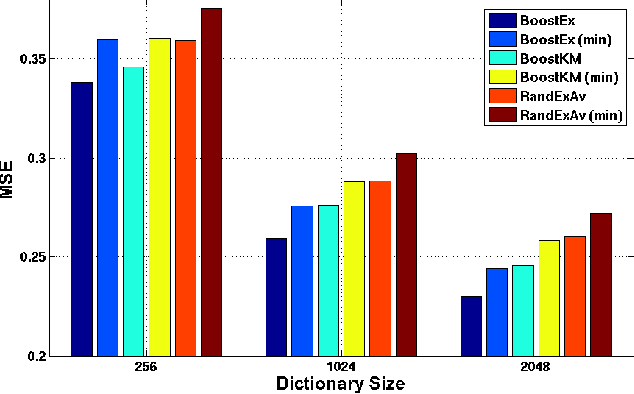
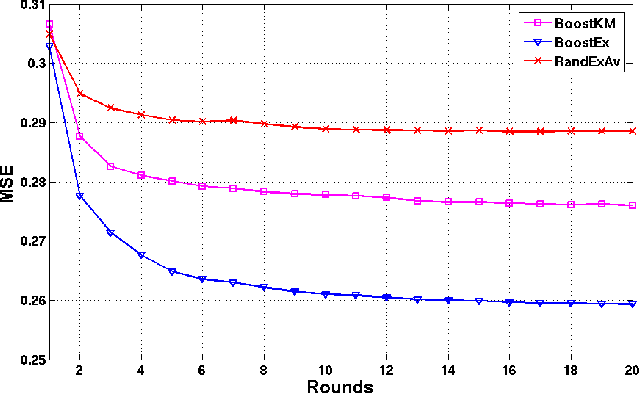
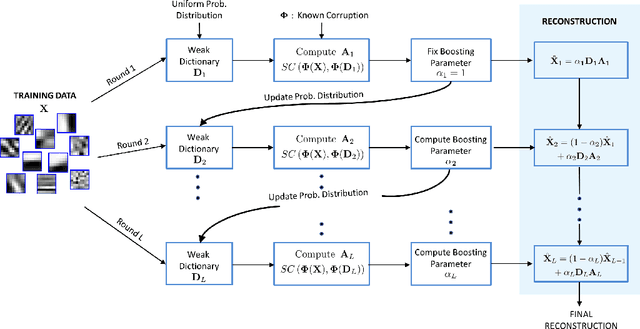
Sparse representations with learned dictionaries have been successful in several image analysis applications. In this paper, we propose and analyze the framework of ensemble sparse models, and demonstrate their utility in image restoration and unsupervised clustering. The proposed ensemble model approximates the data as a linear combination of approximations from multiple \textit{weak} sparse models. Theoretical analysis of the ensemble model reveals that even in the worst-case, the ensemble can perform better than any of its constituent individual models. The dictionaries corresponding to the individual sparse models are obtained using either random example selection or boosted approaches. Boosted approaches learn one dictionary per round such that the dictionary learned in a particular round is optimized for the training examples having high reconstruction error in the previous round. Results with compressed recovery show that the ensemble representations lead to a better performance compared to using a single dictionary obtained with the conventional alternating minimization approach. The proposed ensemble models are also used for single image superresolution, and we show that they perform comparably to the recent approaches. In unsupervised clustering, experiments show that the proposed model performs better than baseline approaches in several standard datasets.