 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLOD-TTA: Test-Time Adaptation of Vision-Language Object Detectors
Oct 01, 2025Vision-language object detectors (VLODs) such as YOLO-World and Grounding DINO achieve impressive zero-shot recognition by aligning region proposals with text representations. However, their performance often degrades under domain shift. We introduce VLOD-TTA, a test-time adaptation (TTA) framework for VLODs that leverages dense proposal overlap and image-conditioned prompt scores. First, an IoU-weighted entropy objective is proposed that concentrates adaptation on spatially coherent proposal clusters and reduces confirmation bias from isolated boxes. Second, image-conditioned prompt selection is introduced, which ranks prompts by image-level compatibility and fuses the most informative prompts with the detector logits. Our benchmarking across diverse distribution shifts -- including stylized domains, driving scenes, low-light conditions, and common corruptions -- shows the effectiveness of our method on two state-of-the-art VLODs, YOLO-World and Grounding DINO, with consistent improvements over the zero-shot and TTA baselines. Code : https://github.com/imatif17/VLOD-TTA
Visual Modality Prompt for Adapting Vision-Language Object Detectors
Dec 01, 2024



The zero-shot performance of object detectors degrades when tested on different modalities, such as infrared and depth. While recent work has explored image translation techniques to adapt detectors to new modalities, these methods are limited to a single modality and apply only to traditional detectors. Recently, vision-language detectors, such as YOLO-World and Grounding DINO, have shown promising zero-shot capabilities, however, they have not yet been adapted for other visual modalities. Traditional fine-tuning approaches tend to compromise the zero-shot capabilities of the detectors. The visual prompt strategies commonly used for classification with vision-language models apply the same linear prompt translation to each image making them less effective. To address these limitations, we propose ModPrompt, a visual prompt strategy to adapt vision-language detectors to new modalities without degrading zero-shot performance. In particular, an encoder-decoder visual prompt strategy is proposed, further enhanced by the integration of inference-friendly task residuals, facilitating more robust adaptation. Empirically, we benchmark our method for modality adaptation on two vision-language detectors, YOLO-World and Grounding DINO, and on challenging infrared (LLVIP, FLIR) and depth (NYUv2) data, achieving performance comparable to full fine-tuning while preserving the model's zero-shot capability. Our code is available at: https://github.com/heitorrapela/ModPrompt
MiPa: Mixed Patch Infrared-Visible Modality Agnostic Object Detection
Apr 29, 2024In this paper, we present a different way to use two modalities, in which either one modality or the other is seen by a single model. This can be useful when adapting an unimodal model to leverage more information while respecting a limited computational budget. This would mean having a single model that is able to deal with any modalities. To describe this, we coined the term anymodal learning. An example of this, is a use case where, surveillance in a room when the lights are off would be much more valuable using an infrared modality while a visible one would provide more discriminative information when lights are on. This work investigates how to efficiently leverage visible and infrared/thermal modalities for transformer-based object detection backbone to create an anymodal architecture. Our work does not create any inference overhead during the testing while exploring an effective way to exploit the two modalities during the training. To accomplish such a task, we introduce the novel anymodal training technique: Mixed Patches (MiPa), in conjunction with a patch-wise domain agnostic module, which is responsible of learning the best way to find a common representation of both modalities. This approach proves to be able to balance modalities by reaching competitive results on individual modality benchmarks with the alternative of using an unimodal architecture on three different visible-infrared object detection datasets. Finally, our proposed method, when used as a regularization for the strongest modality, can beat the performance of multimodal fusion methods while only requiring a single modality during inference. Notably, MiPa became the state-of-the-art on the LLVIP visible/infrared benchmark. Code: https://github.com/heitorrapela/MiPa
A Framework for Studying Reinforcement Learning and Sim-to-Real in Robot Soccer
Aug 18, 2020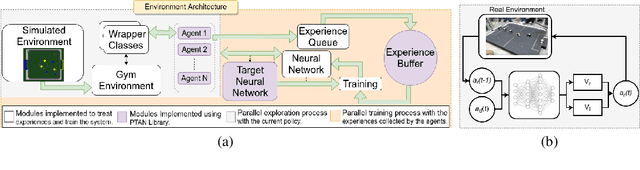
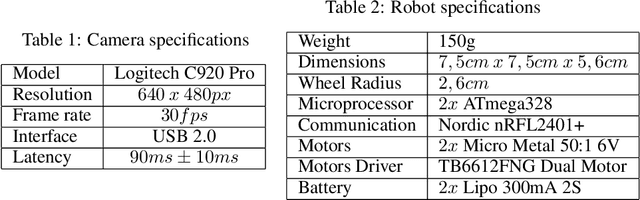

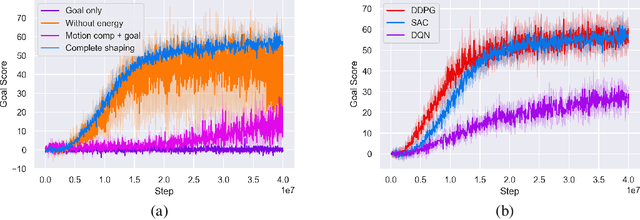
This article introduces an open framework, called VSSS-RL, for studying Reinforcement Learning (RL) and sim-to-real in robot soccer, focusing on the IEEE Very Small Size Soccer (VSSS) league. We propose a simulated environment in which continuous or discrete control policies can be trained to control the complete behavior of soccer agents and a sim-to-real method based on domain adaptation to adapt the obtained policies to real robots. Our results show that the trained policies learned a broad repertoire of behaviors that are difficult to implement with handcrafted control policies. With VSSS-RL, we were able to beat human-designed policies in the 2019 Latin American Robotics Competition (LARC), achieving 4th place out of 21 teams, being the first to apply Reinforcement Learning (RL) successfully in this competition. Both environment and hardware specifications are available open-source to allow reproducibility of our results and further studies.
Deep Categorization with Semi-Supervised Self-Organizing Maps
Jun 17, 2020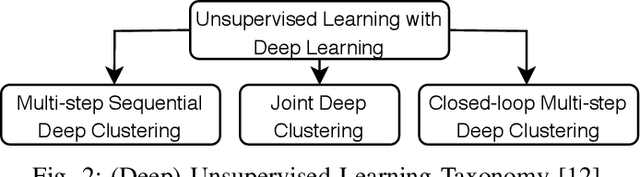
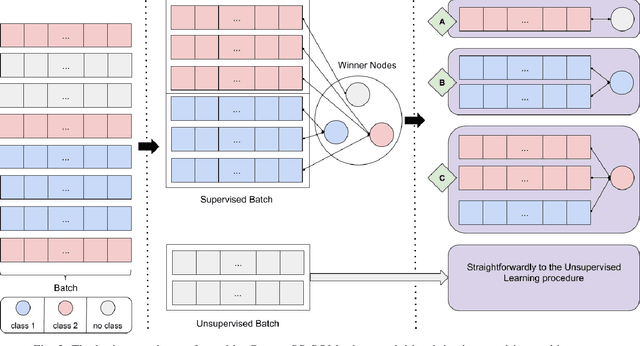
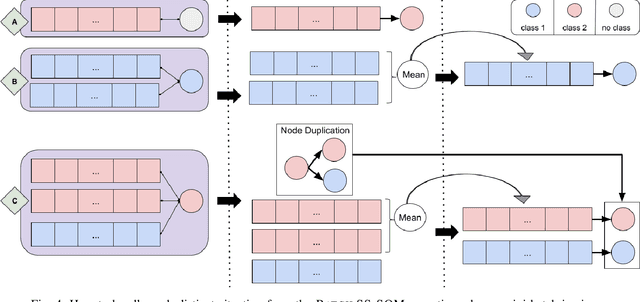

Nowadays, with the advance of technology, there is an increasing amount of unstructured data being generated every day. However, it is a painful job to label and organize it. Labeling is an expensive, time-consuming, and difficult task. It is usually done manually, which collaborates with the incorporation of noise and errors to the data. Hence, it is of great importance to developing intelligent models that can benefit from both labeled and unlabeled data. Currently, works on unsupervised and semi-supervised learning are still being overshadowed by the successes of purely supervised learning. However, it is expected that they become far more important in the longer term. This article presents a semi-supervised model, called Batch Semi-Supervised Self-Organizing Map (Batch SS-SOM), which is an extension of a SOM incorporating some advances that came with the rise of Deep Learning, such as batch training. The results show that Batch SS-SOM is a good option for semi-supervised classification and clustering. It performs well in terms of accuracy and clustering error, even with a small number of labeled samples, as well as when presented to unsupervised data, and shows competitive results in transfer learning scenarios in traditional image classification benchmark datasets.
Learning to Play Soccer by Reinforcement and Applying Sim-to-Real to Compete in the Real World
Mar 24, 2020
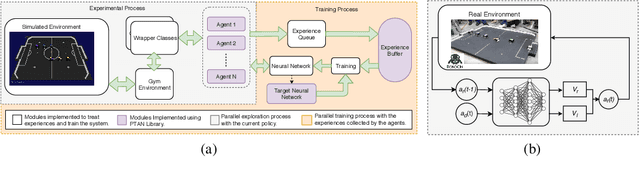
This work presents an application of Reinforcement Learning (RL) for the complete control of real soccer robots of the IEEE Very Small Size Soccer (VSSS), a traditional league in the Latin American Robotics Competition (LARC). In the VSSS league, two teams of three small robots play against each other. We propose a simulated environment in which continuous or discrete control policies can be trained, and a Sim-to-Real method to allow using the obtained policies to control a robot in the real world. The results show that the learned policies display a broad repertoire of behaviors that are difficult to specify by hand. This approach, called VSSS-RL, was able to beat the human-designed policy for the striker of the team ranked 3rd place in the 2018 LARC, in 1-vs-1 matches.