 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-level Stress Assessment Using Multi-domain Fusion of ECG Signal
Aug 12, 2020
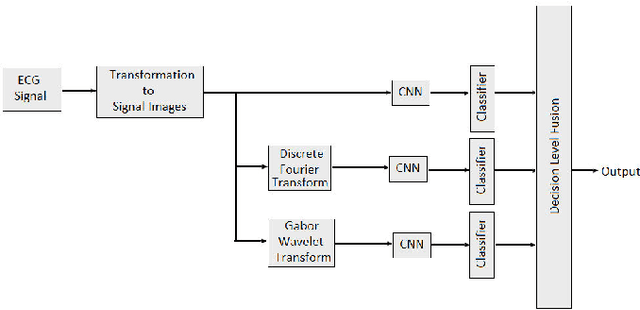
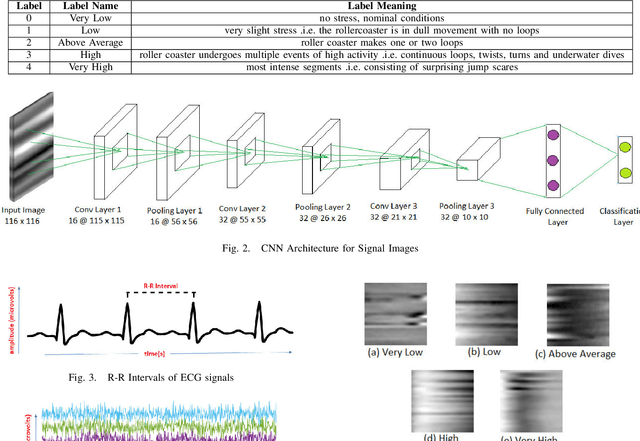
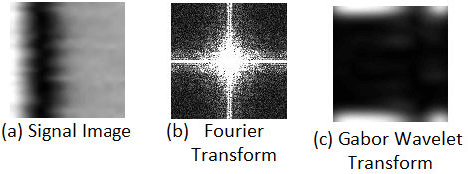
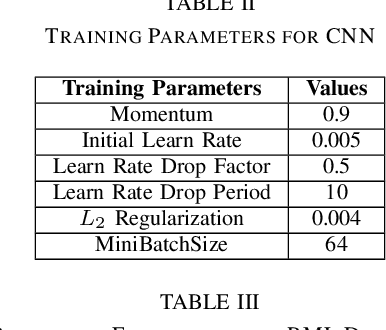
Stress analysis and assessment of affective states of mind using ECG as a physiological signal is a burning research topic in biomedical signal processing. However, existing literature provides only binary assessment of stress, while multiple levels of assessment may be more beneficial for healthcare applications. Furthermore, in present research, ECG signal for stress analysis is examined independently in spatial domain or in transform domains but the advantage of fusing these domains has not been fully utilized. To get the maximum advantage of fusing diferent domains, we introduce a dataset with multiple stress levels and then classify these levels using a novel deep learning approach by converting ECG signal into signal images based on R-R peaks without any feature extraction. Moreover, We made signal images multimodal and multidomain by converting them into time-frequency and frequency domain using Gabor wavelet transform (GWT) and Discrete Fourier Transform (DFT) respectively. Convolutional Neural networks (CNNs) are used to extract features from different modalities and then decision level fusion is performed for improving the classification accuracy. The experimental results on an in-house dataset collected with 15 users show that with proposed fusion framework and using ECG signal to image conversion, we reach an average accuracy of 85.45%.
An efficient iterative thresholding method for image segmentation
Aug 12, 2016
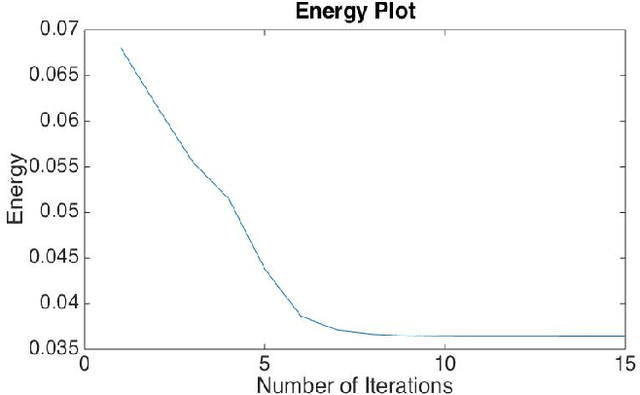
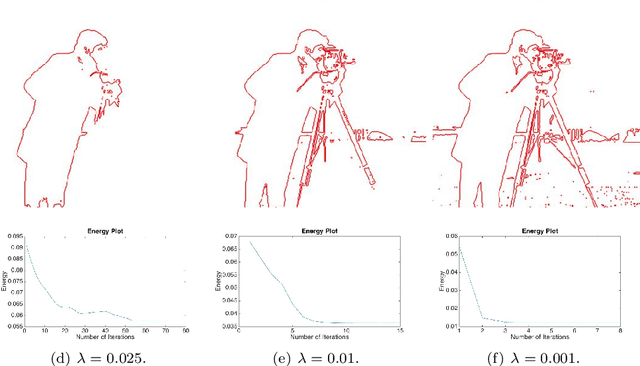
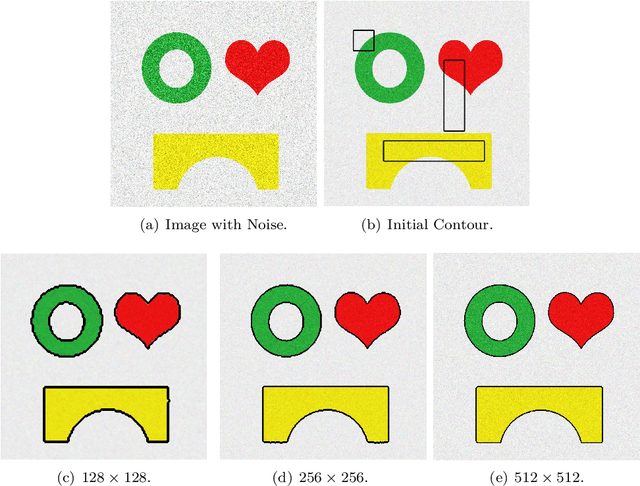
We proposed an efficient iterative thresholding method for multi-phase image segmentation. The algorithm is based on minimizing piecewise constant Mumford-Shah functional in which the contour length (or perimeter) is approximated by a non-local multi-phase energy. The minimization problem is solved by an iterative method. Each iteration consists of computing simple convolutions followed by a thresholding step. The algorithm is easy to implement and has the optimal complexity $O(N \log N)$ per iteration. We also show that the iterative algorithm has the total energy decaying property. We present some numerical results to show the efficiency of our method.
The Analysis of Local Motion and Deformation in Image Sequences Inspired by Physical Electromagnetic Interaction
Oct 12, 2016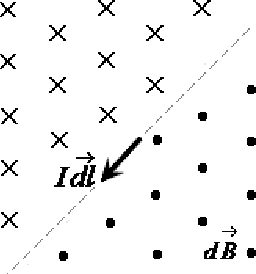
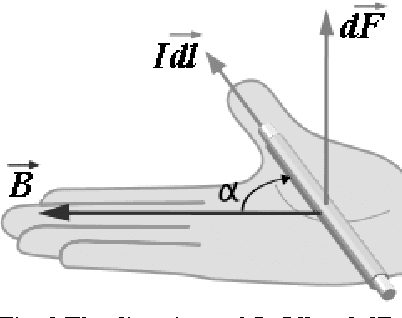

In order to analyze the moving and deforming of the objects in image sequence, a novel way is presented to analyze the local changes of object edges between two related images (such as two adjacent frames in a video sequence), which is inspired by the physical electromagnetic interaction. The changes of edge between adjacent frames in sequences are analyzed by simulation of virtual current interaction, which can reflect the change of the object's position or shape. The virtual current along the main edge line is proposed based on the significant edge extraction. Then the virtual interaction between the current elements in the two related images is studied by imitating the interaction between physical current-carrying wires. The experimental results prove that the distribution of magnetic forces on the current elements in one image applied by the other can reflect the local change of edge lines from one image to the other, which is important in further analysis.
* 15 pages, 23 figures. arXiv admin note: substantial text overlap with arXiv:1610.03615, arXiv:1610.02762
Multi-Attention-Network for Semantic Segmentation of High-Resolution Remote Sensing Images
Sep 03, 2020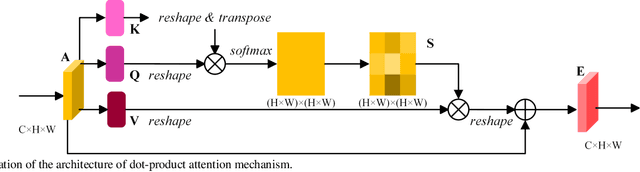
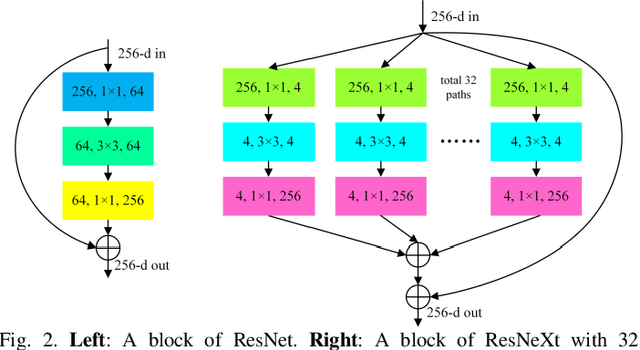
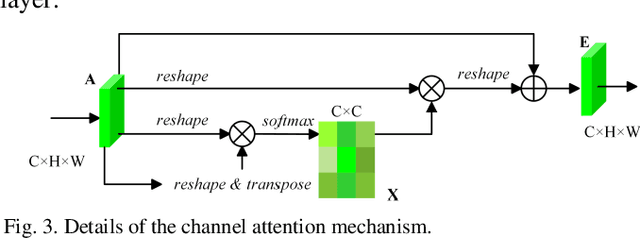
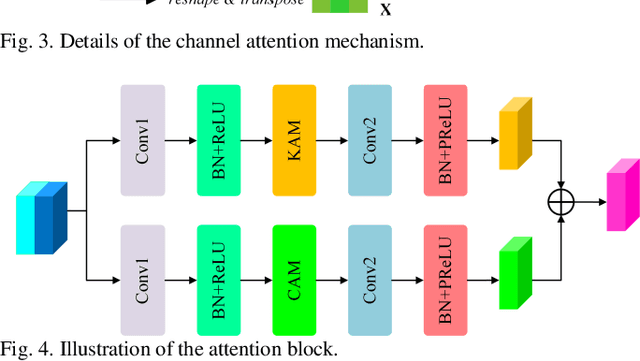
Semantic segmentation of remote sensing images plays an important role in land resource management, yield estimation, and economic assessment. Even though the semantic segmentation of remote sensing images has been prominently improved by convolutional neural networks, there are still several limitations contained in standard models. First, for encoder-decoder architectures like U-Net, the utilization of multi-scale features causes overuse of information, where similar low-level features are exploited at multiple scales for multiple times. Second, long-range dependencies of feature maps are not sufficiently explored, leading to feature representations associated with each semantic class are not optimal. Third, despite the dot-product attention mechanism has been introduced and harnessed widely in semantic segmentation to model long-range dependencies, the high time and space complexities of attention impede the usage of attention in application scenarios with large input. In this paper, we proposed a Multi-Attention-Network (MANet) to remedy these drawbacks, which extracts contextual dependencies by multi efficient attention mechanisms. A novel attention mechanism named kernel attention with linear complexity is proposed to alleviate the high computational demand of attention. Based on kernel attention and channel attention, we integrate local feature maps extracted by ResNeXt-101 with their corresponding global dependencies, and adaptively signalize interdependent channel maps. Experiments conducted on two remote sensing image datasets captured by variant satellites demonstrate that the performance of our MANet transcends the DeepLab V3+, PSPNet, FastFCN, and other baseline algorithms.
Fast Implementation of Morphological Filtering Using ARM NEON Extension
Feb 19, 2020

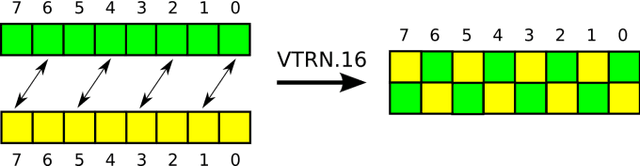
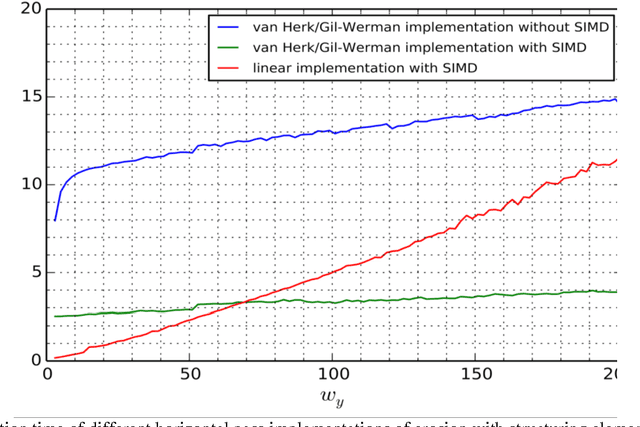
In this paper we consider speedup potential of morphological image filtering on ARM processors. Morphological operations are widely used in image analysis and recognition and their speedup in some cases can significantly reduce overall execution time of recognition. More specifically, we propose fast implementation of erosion and dilation using ARM SIMD extension NEON. These operations with the rectangular structuring element are separable. They were implemented using the advantages of separability as sequential horizontal and vertical passes. Each pass was implemented using van Herk/Gil-Werman algorithm for large windows and low-constant linear complexity algorithm for small windows. Final implementation was improved with SIMD and used a combination of these methods. We also considered fast transpose implementation of 8x8 and 16x16 matrices using ARM NEON to get additional computational gain for morphological operations. Experiments showed 3 times efficiency increase for final implementation of erosion and dilation compared to van Herk/Gil-Werman algorithm without SIMD, 5.7 times speedup for 8x8 matrix transpose and 12 times speedup for 16x16 matrix transpose compared to transpose without SIMD.
* 6 pages, 4 figures
Very high resolution Airborne PolSAR Image Classification using Convolutional Neural Networks
Oct 31, 2019
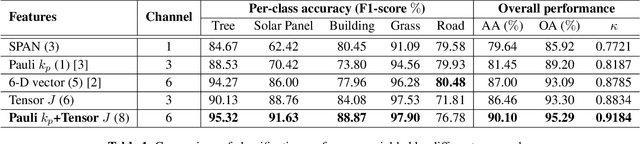
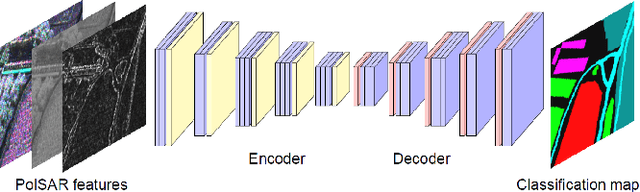
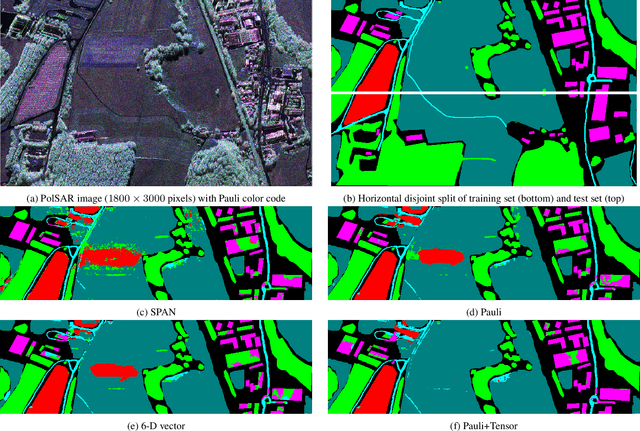
In this work, we exploit convolutional neural networks (CNNs) for the classification of very high resolution (VHR) polarimetric SAR (PolSAR) data. Due to the significant appearance of heterogeneous textures within these data, not only polarimetric features but also structural tensors are exploited to feed CNN models. For deep networks, we use the SegNet model for semantic segmentation, which corresponds to pixelwise classification in remote sensing. Our experiments on the airborne F-SAR data show that for VHR PolSAR images, SegNet could provide high accuracy for the classification task; and introducing structural tensors with polarimetric features as inputs could help the network to focus more on geometrical information to significantly improve the classification performance.
Novelty Detection via Non-Adversarial Generative Network
Feb 03, 2020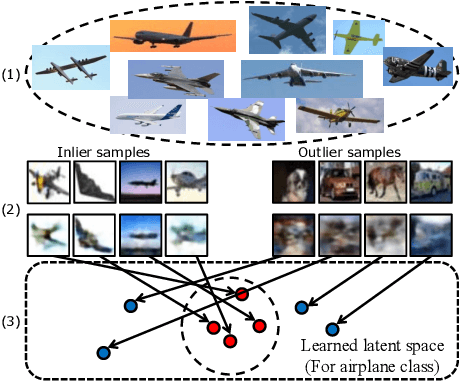

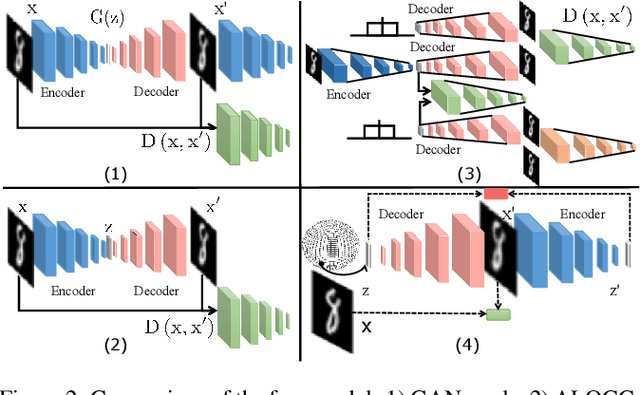
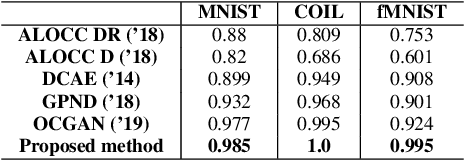
One-class novelty detection is the process of determining if a query example differs from the training examples (the target class). Most of previous strategies attempt to learn the real characteristics of target sample by using generative adversarial networks (GANs) methods. However, the training process of GANs remains challenging, suffering from instability issues such as mode collapse and vanishing gradients. In this paper, by adopting non-adversarial generative networks, a novel decoder-encoder framework is proposed for novelty detection task, insteading of classical encoder-decoder style. Under the non-adversarial framework, both latent space and image reconstruction space are jointly optimized, leading to a more stable training process with super fast convergence and lower training losses. During inference, inspired by cycleGAN, we design a new testing scheme to conduct image reconstruction, which is the reverse way of training sequence. Experiments show that our model has the clear superiority over cutting-edge novelty detectors and achieves the state-of-the-art results on the datasets.
Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network
Mar 20, 2020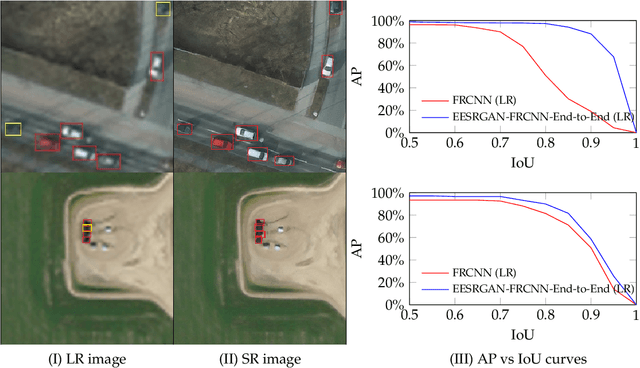
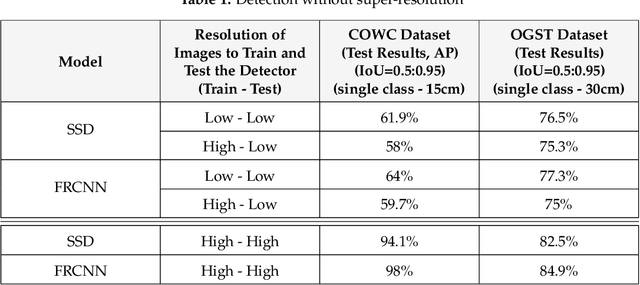
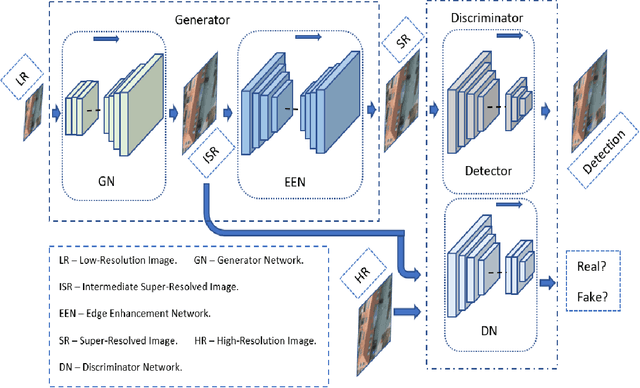
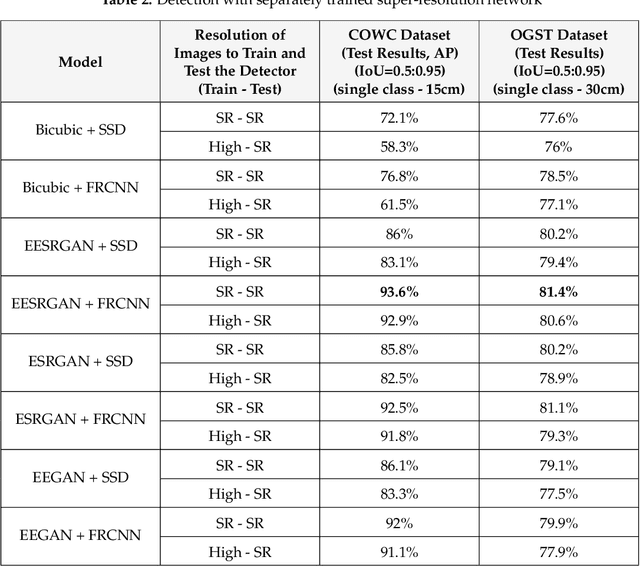
The detection performance of small objects in remote sensing images is not satisfactory compared to large objects, especially in low-resolution and noisy images. A generative adversarial network (GAN)-based model called enhanced super-resolution GAN (ESRGAN) shows remarkable image enhancement performance, but reconstructed images miss high-frequency edge information. Therefore, object detection performance degrades for the small objects on recovered noisy and low-resolution remote sensing images. Inspired by the success of edge enhanced GAN (EEGAN) and ESRGAN, we apply a new edge-enhanced super-resolution GAN (EESRGAN) to improve the image quality of remote sensing images and used different detector networks in an end-to-end manner where detector loss is backpropagated into the EESRGAN to improve the detection performance. We propose an architecture with three components: ESRGAN, Edge Enhancement Network (EEN), and Detection network. We use residual-in-residual dense blocks (RRDB) for both the GAN and EEN, and for the detector network, we use the faster region-based convolutional network (FRCNN) (two-stage detector) and single-shot multi-box detector (SSD) (one stage detector). Extensive experiments on car overhead with context and oil and gas storage tank (created by us) data sets show superior performance of our method compared to the standalone state-of-the-art object detectors.
Saliency-driven Class Impressions for Feature Visualization of Deep Neural Networks
Jul 31, 2020



In this paper, we propose a data-free method of extracting Impressions of each class from the classifier's memory. The Deep Learning regime empowers classifiers to extract distinct patterns (or features) of a given class from training data, which is the basis on which they generalize to unseen data. Before deploying these models on critical applications, it is advantageous to visualize the features considered to be essential for classification. Existing visualization methods develop high confidence images consisting of both background and foreground features. This makes it hard to judge what the crucial features of a given class are. In this work, we propose a saliency-driven approach to visualize discriminative features that are considered most important for a given task. Another drawback of existing methods is that confidence of the generated visualizations is increased by creating multiple instances of the given class. We restrict the algorithm to develop a single object per image, which helps further in extracting features of high confidence and also results in better visualizations. We further demonstrate the generation of negative images as naturally fused images of two or more classes.
An In-depth Walkthrough on Evolution of Neural Machine Translation
Apr 10, 2020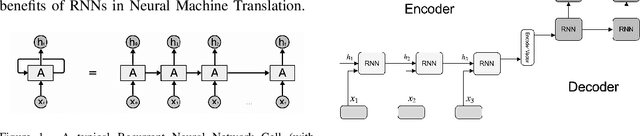
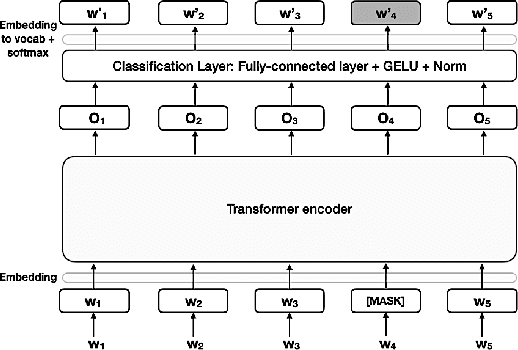
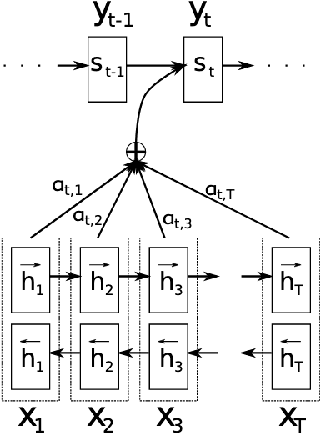
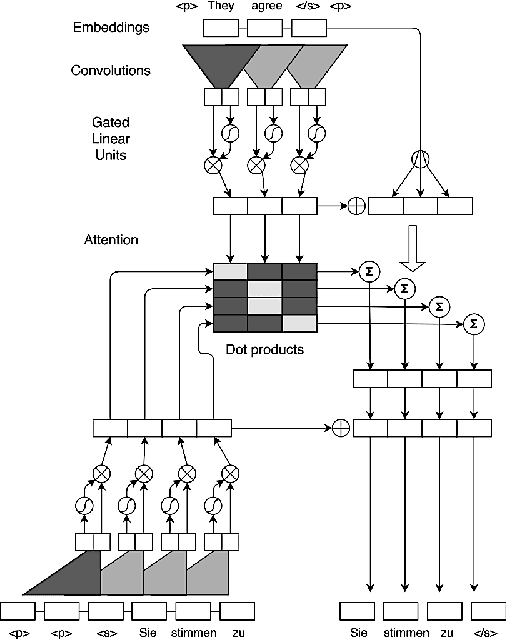
Neural Machine Translation (NMT) methodologies have burgeoned from using simple feed-forward architectures to the state of the art; viz. BERT model. The use cases of NMT models have been broadened from just language translations to conversational agents (chatbots), abstractive text summarization, image captioning, etc. which have proved to be a gem in their respective applications. This paper aims to study the major trends in Neural Machine Translation, the state of the art models in the domain and a high level comparison between them.