 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Content Based Image Indexing and Retrieval
Jan 08, 2014


In this paper, we present the efficient content based image retrieval systems which employ the color, texture and shape information of images to facilitate the retrieval process. For efficient feature extraction, we extract the color, texture and shape feature of images automatically using edge detection which is widely used in signal processing and image compression. For facilitated the speedy retrieval we are implements the antipole-tree algorithm for indexing the images.
* 12 pages
Image Retrieval And Classification Using Local Feature Vectors
Sep 02, 2014
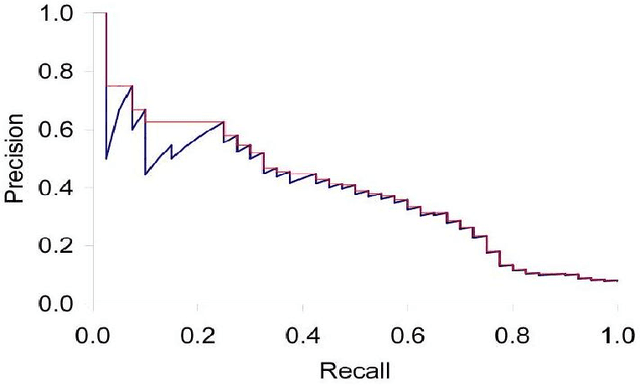
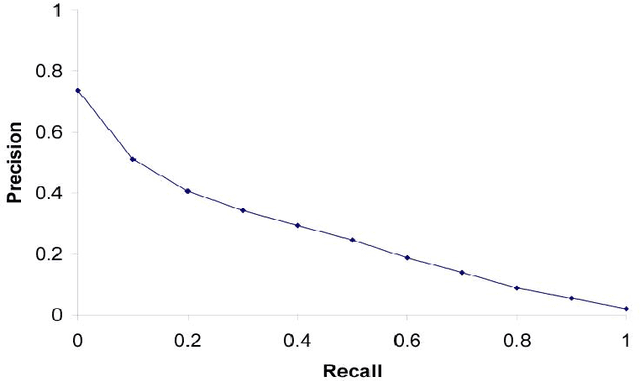
Content Based Image Retrieval(CBIR) is one of the important subfield in the field of Information Retrieval. The goal of a CBIR algorithm is to retrieve semantically similar images in response to a query image submitted by the end user. CBIR is a hard problem because of the phenomenon known as $\textit {semantic gap}$. In this thesis, we aim at analyzing the performance of a CBIR system build using local feature vectors and Intermediate Matching Kernel. We also propose a Two-Step Matching process for reducing the response time of the CBIR systems. Further, we develop a Meta-Learning framework for improving the retrieval performance of these systems. Our results show that the Two-Step Matching process significantly reduces response time and the Meta-Learning Framework improves the retrieval performance by more than two fold. We also analyze the performance of various image classification systems that use different image representations constructed from the local feature vectors.
Planar Ultrametric Rounding for Image Segmentation
Sep 10, 2015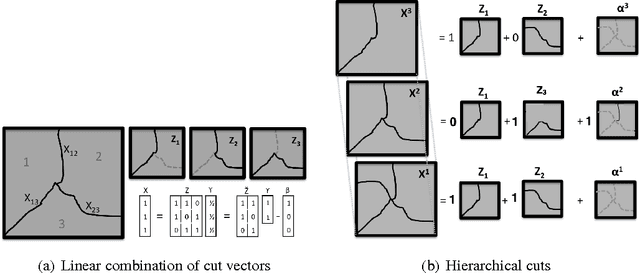


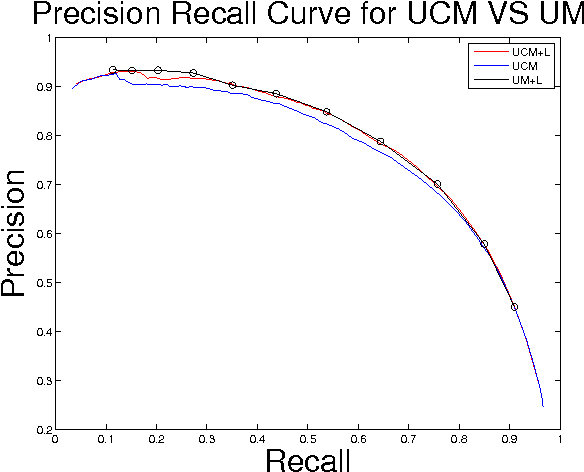
We study the problem of hierarchical clustering on planar graphs. We formulate this in terms of an LP relaxation of ultrametric rounding. To solve this LP efficiently we introduce a dual cutting plane scheme that uses minimum cost perfect matching as a subroutine in order to efficiently explore the space of planar partitions. We apply our algorithm to the problem of hierarchical image segmentation.
Understanding Knowledge Gaps in Visual Question Answering: Implications for Gap Identification and Testing
Apr 08, 2020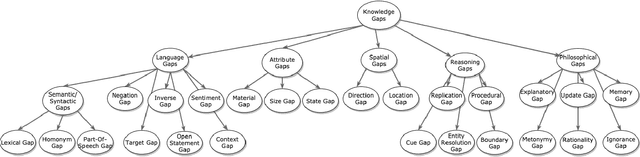
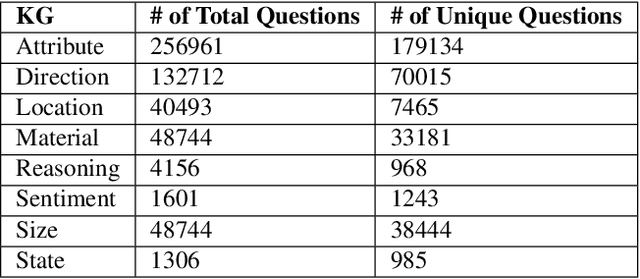

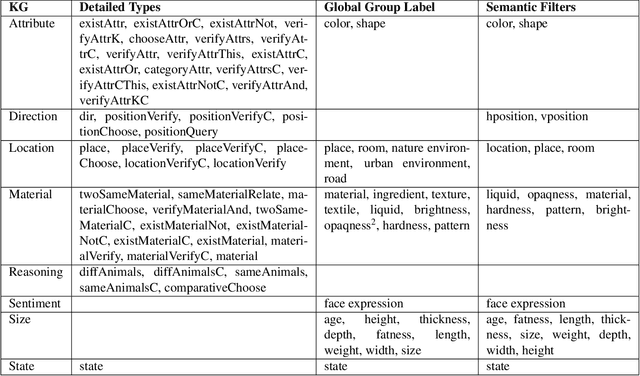
Visual Question Answering (VQA) systems are tasked with answering natural language questions corresponding to a presented image. Current VQA datasets typically contain questions related to the spatial information of objects, object attributes, or general scene questions. Recently, researchers have recognized the need for improving the balance of such datasets to reduce the system's dependency on memorized linguistic features and statistical biases and to allow for improved visual understanding. However, it is unclear as to whether there are any latent patterns that can be used to quantify and explain these failures. To better quantify our understanding of the performance of VQA models, we use a taxonomy of Knowledge Gaps (KGs) to identify/tag questions with one or more types of KGs. Each KG describes the reasoning abilities needed to arrive at a resolution, and failure to resolve gaps indicate an absence of the required reasoning ability. After identifying KGs for each question, we examine the skew in the distribution of the number of questions for each KG. In order to reduce the skew in the distribution of questions across KGs, we introduce a targeted question generation model. This model allows us to generate new types of questions for an image.
The Newspaper Navigator Dataset: Extracting And Analyzing Visual Content from 16 Million Historic Newspaper Pages in Chronicling America
May 04, 2020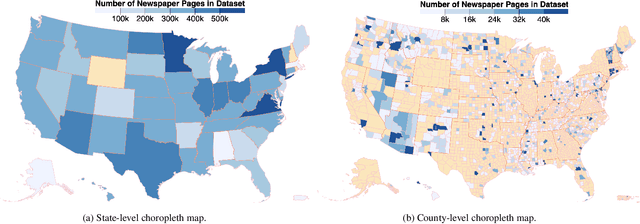
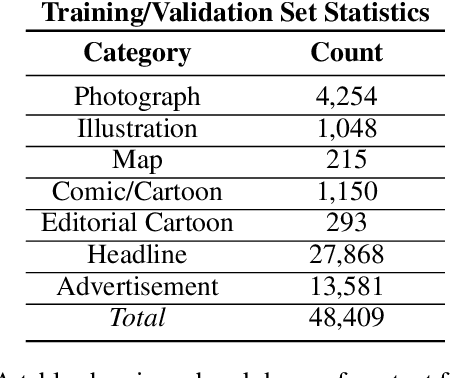
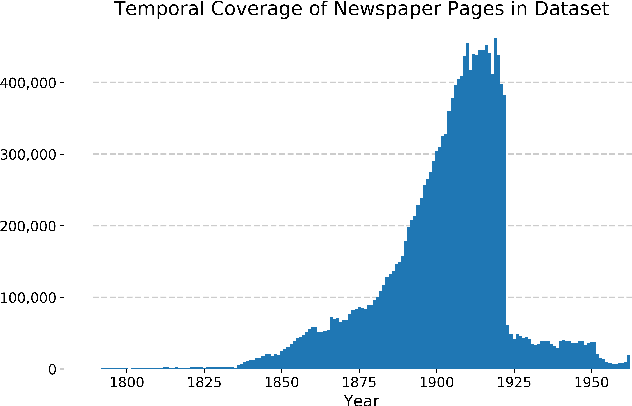
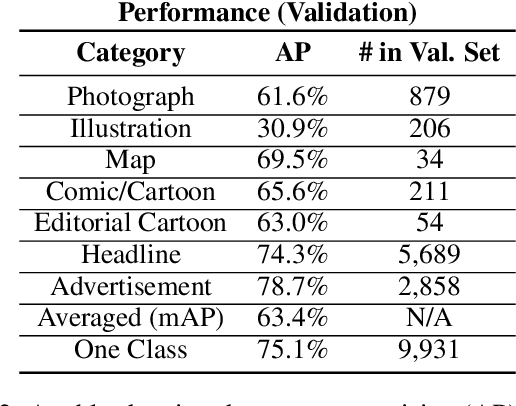
Chronicling America is a product of the National Digital Newspaper Program, a partnership between the Library of Congress and the National Endowment for the Humanities to digitize historic newspapers. Over 16 million pages of historic American newspapers have been digitized for Chronicling America to date, complete with high-resolution images and machine-readable METS/ALTO OCR. Of considerable interest to Chronicling America users is a semantified corpus, complete with extracted visual content and headlines. To accomplish this, we introduce a visual content recognition model trained on bounding box annotations of photographs, illustrations, maps, comics, and editorial cartoons collected as part of the Library of Congress's Beyond Words crowdsourcing initiative and augmented with additional annotations including those of headlines and advertisements. We describe our pipeline that utilizes this deep learning model to extract 7 classes of visual content: headlines, photographs, illustrations, maps, comics, editorial cartoons, and advertisements, complete with textual content such as captions derived from the METS/ALTO OCR, as well as image embeddings for fast image similarity querying. We report the results of running the pipeline on 16.3 million pages from the Chronicling America corpus and describe the resulting Newspaper Navigator dataset, the largest dataset of extracted visual content from historic newspapers ever produced. The Newspaper Navigator dataset, finetuned visual content recognition model, and all source code are placed in the public domain for unrestricted re-use.
Frequency-Weighted Robust Tensor Principal Component Analysis
Apr 21, 2020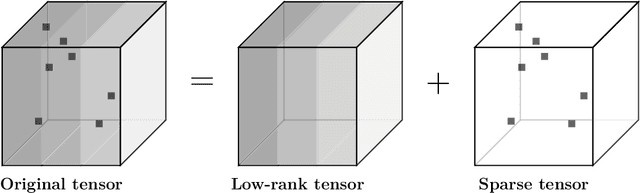
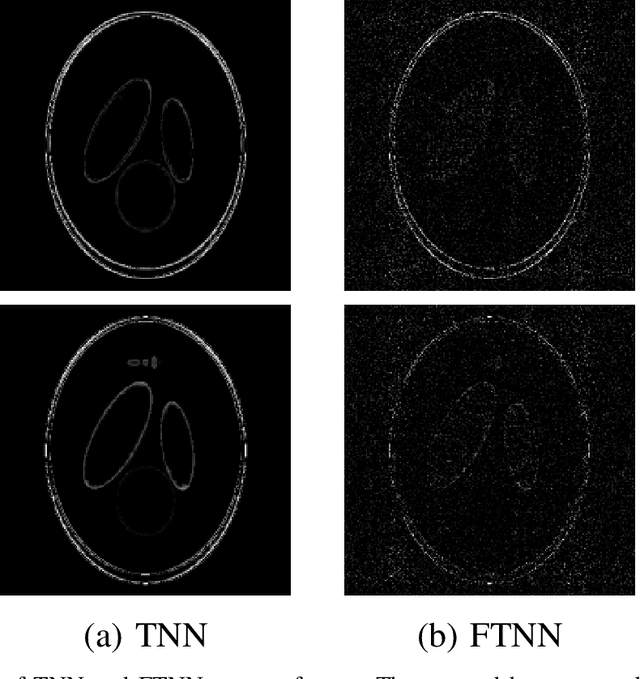
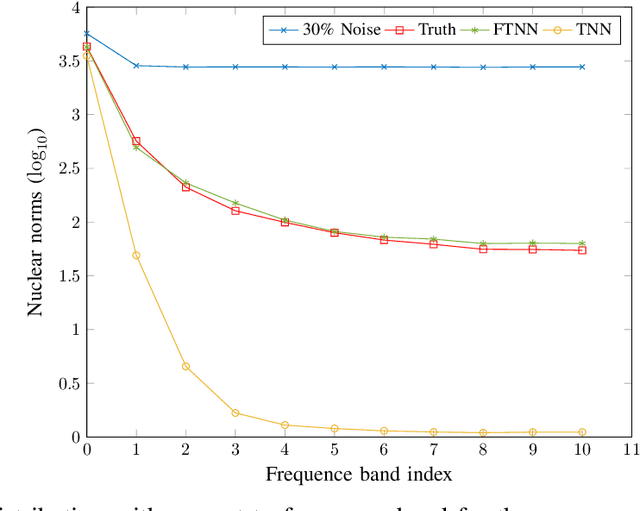
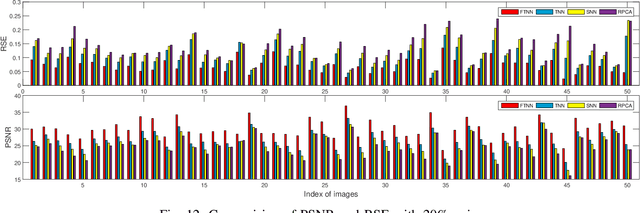
Robust tensor principal component analysis (RTPCA) can separate the low-rank component and sparse component from multidimensional data, which has been used successfully in several image applications. Its performance varies with different kinds of tensor decompositions, and the tensor singular value decomposition (t-SVD) is a popularly selected one. The standard t-SVD takes the discrete Fourier transform to exploit the residual in the 3rd mode in the decomposition. When minimizing the tensor nuclear norm related to t-SVD, all the frontal slices in frequency domain are optimized equally. In this paper, we incorporate frequency component analysis into t-SVD to enhance the RTPCA performance. Specially, different frequency bands are unequally weighted with respect to the corresponding physical meanings, and the frequency-weighted tensor nuclear norm can be obtained. Accordingly we rigorously deduce the frequency-weighted tensor singular value threshold operator, and apply it for low rank approximation subproblem in RTPCA. The newly obtained frequency-weighted RTPCA can be solved by alternating direction method of multipliers, and it is the first time that frequency analysis is taken in tensor principal component analysis. Numerical experiments on synthetic 3D data, color image denoising and background modeling verify that the proposed method outperforms the state-of-the-art algorithms both in accuracy and computational complexity.
Concurrently Extrapolating and Interpolating Networks for Continuous Model Generation
Jan 12, 2020


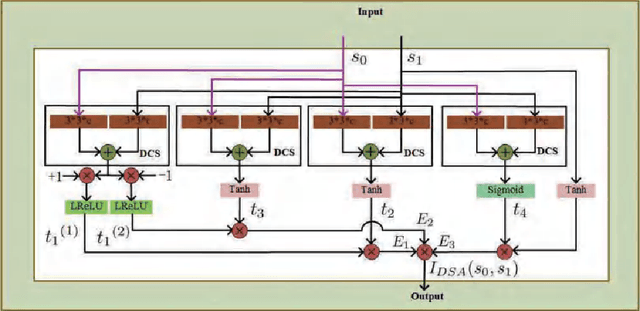
Most deep image smoothing operators are always trained repetitively when different explicit structure-texture pairs are employed as label images for each algorithm configured with different parameters. This kind of training strategy often takes a long time and spends equipment resources in a costly manner. To address this challenging issue, we generalize continuous network interpolation as a more powerful model generation tool, and then propose a simple yet effective model generation strategy to form a sequence of models that only requires a set of specific-effect label images. To precisely learn image smoothing operators, we present a double-state aggregation (DSA) module, which can be easily inserted into most of current network architecture. Based on this module, we design a double-state aggregation neural network structure with a local feature aggregation block and a nonlocal feature aggregation block to obtain operators with large expression capacity. Through the evaluation of many objective and visual experimental results, we show that the proposed method is capable of producing a series of continuous models and achieves better performance than that of several state-of-the-art methods for image smoothing.
Weakly Aligned Joint Cross-Modality Super Resolution
Apr 21, 2020
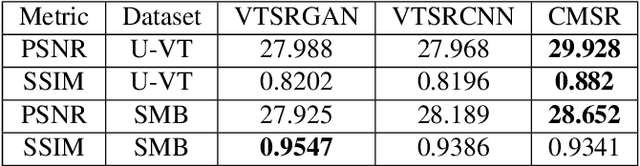


Non-visual imaging sensors are widely used in the industry for different purposes. Those sensors are more expensive than visual (RGB) sensors, and usually produce images with lower resolution. To this end, Cross-Modality Super-Resolution methods were introduced, where an RGB image of a high-resolution assists in increasing the resolution of the low-resolution modality. However, fusing images from different modalities is not a trivial task; the output must be artifact-free and remain loyal to the characteristics of the target modality. Moreover, the input images are never perfectly aligned, which results in further artifacts during the fusion process. We present CMSR, a deep network for Cross-Modality Super-Resolution, which unlike previous methods, is designed to deal with weakly aligned images. The network is trained on the two input images only, learns their internal statistics and correlations, and applies them to up-sample the target modality. CMSR contains an internal transformer that is trained on-the-fly together with the up-sampling process itself, without explicit supervision. We show that CMSR succeeds to increase the resolution of the input image, gaining valuable information from its RGB counterpart, yet in a conservative way, without introducing artifacts or irrelevant details.
DynaMiTe: A Dynamic Local Motion Model with Temporal Constraints for Robust Real-Time Feature Matching
Jul 31, 2020

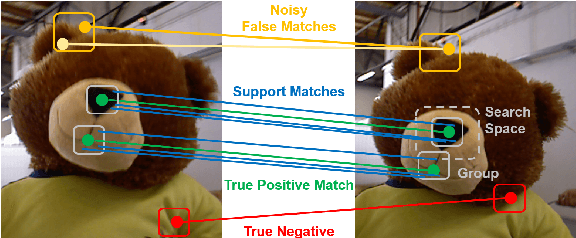
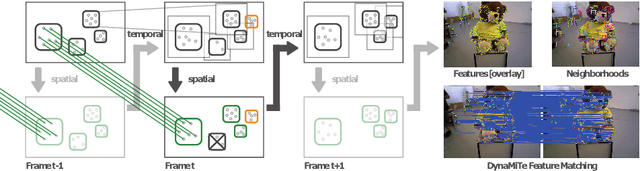
Feature based visual odometry and SLAM methods require accurate and fast correspondence matching between consecutive image frames for precise camera pose estimation in real-time. Current feature matching pipelines either rely solely on the descriptive capabilities of the feature extractor or need computationally complex optimization schemes. We present the lightweight pipeline DynaMiTe, which is agnostic to the descriptor input and leverages spatial-temporal cues with efficient statistical measures. The theoretical backbone of the method lies within a probabilistic formulation of feature matching and the respective study of physically motivated constraints. A dynamically adaptable local motion model encapsulates groups of features in an efficient data structure. Temporal constraints transfer information of the local motion model across time, thus additionally reducing the search space complexity for matching. DynaMiTe achieves superior results both in terms of matching accuracy and camera pose estimation with high frame rates, outperforming state-of-the-art matching methods while being computationally more efficient.
A Confidence-Calibrated MOBA Game Winner Predictor
Jun 28, 2020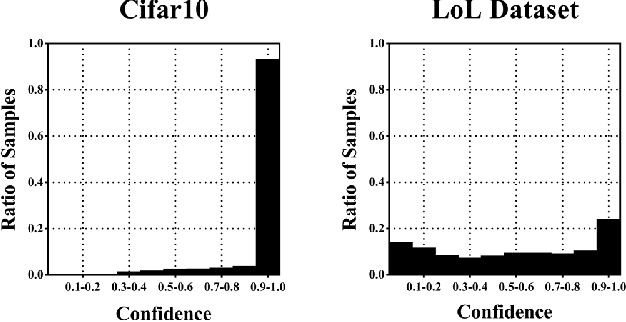
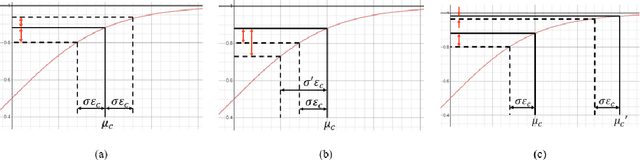
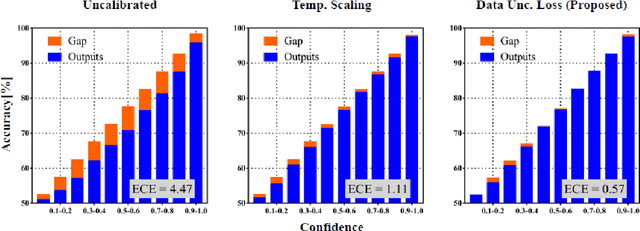
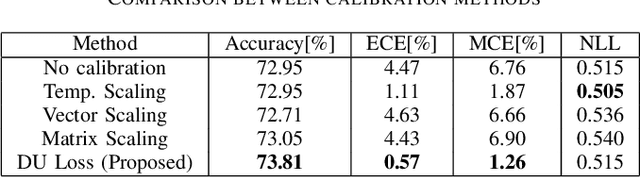
In this paper, we propose a confidence-calibration method for predicting the winner of a famous multiplayer online battle arena (MOBA) game, League of Legends. In MOBA games, the dataset may contain a large amount of input-dependent noise; not all of such noise is observable. Hence, it is desirable to attempt a confidence-calibrated prediction. Unfortunately, most existing confidence calibration methods are pertaining to image and document classification tasks where consideration on uncertainty is not crucial. In this paper, we propose a novel calibration method that takes data uncertainty into consideration. The proposed method achieves an outstanding expected calibration error (ECE) (0.57%) mainly owing to data uncertainty consideration, compared to a conventional temperature scaling method of which ECE value is 1.11%.