 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Federated Learning In Real World Application -- A Case Study
Feb 10, 2025



This paper presents an implementation of machine learning model training using private federated learning (PFL) on edge devices. We introduce a novel framework that uses PFL to address the challenge of training a model using users' private data. The framework ensures that user data remain on individual devices, with only essential model updates transmitted to a central server for aggregation with privacy guarantees. We detail the architecture of our app selection model, which incorporates a neural network with attention mechanisms and ambiguity handling through uncertainty management. Experiments conducted through off-line simulations and on device training demonstrate the feasibility of our approach in real-world scenarios. Our results show the potential of PFL to improve the accuracy of an app selection model by adapting to changes in user behavior over time, while adhering to privacy standards. The insights gained from this study are important for industries looking to implement PFL, offering a robust strategy for training a predictive model directly on edge devices while ensuring user data privacy.
Retrieval Augmented Correction of Named Entity Speech Recognition Errors
Sep 09, 2024



In recent years, end-to-end automatic speech recognition (ASR) systems have proven themselves remarkably accurate and performant, but these systems still have a significant error rate for entity names which appear infrequently in their training data. In parallel to the rise of end-to-end ASR systems, large language models (LLMs) have proven to be a versatile tool for various natural language processing (NLP) tasks. In NLP tasks where a database of relevant knowledge is available, retrieval augmented generation (RAG) has achieved impressive results when used with LLMs. In this work, we propose a RAG-like technique for correcting speech recognition entity name errors. Our approach uses a vector database to index a set of relevant entities. At runtime, database queries are generated from possibly errorful textual ASR hypotheses, and the entities retrieved using these queries are fed, along with the ASR hypotheses, to an LLM which has been adapted to correct ASR errors. Overall, our best system achieves 33%-39% relative word error rate reductions on synthetic test sets focused on voice assistant queries of rare music entities without regressing on the STOP test set, a publicly available voice assistant test set covering many domains.
Applying RLAIF for Code Generation with API-usage in Lightweight LLMs
Jun 28, 2024



Reinforcement Learning from AI Feedback (RLAIF) has demonstrated significant potential across various domains, including mitigating harm in LLM outputs, enhancing text summarization, and mathematical reasoning. This paper introduces an RLAIF framework for improving the code generation abilities of lightweight (<1B parameters) LLMs. We specifically focus on code generation tasks that require writing appropriate API calls, which is challenging due to the well-known issue of hallucination in LLMs. Our framework extracts AI feedback from a larger LLM (e.g., GPT-3.5) through a specialized prompting strategy and uses this data to train a reward model towards better alignment from smaller LLMs. We run our experiments on the Gorilla dataset and meticulously assess the quality of the model-generated code across various metrics, including AST, ROUGE, and Code-BLEU, and develop a pipeline to compute its executability rate accurately. Our approach significantly enhances the fine-tuned LLM baseline's performance, achieving a 4.5% improvement in executability rate. Notably, a smaller LLM model (780M parameters) trained with RLAIF surpasses a much larger fine-tuned baseline with 7B parameters, achieving a 1.0% higher code executability rate.
ProTIP: Progressive Tool Retrieval Improves Planning
Dec 16, 2023Large language models (LLMs) are increasingly employed for complex multi-step planning tasks, where the tool retrieval (TR) step is crucial for achieving successful outcomes. Two prevalent approaches for TR are single-step retrieval, which utilizes the complete query, and sequential retrieval using task decomposition (TD), where a full query is segmented into discrete atomic subtasks. While single-step retrieval lacks the flexibility to handle "inter-tool dependency," the TD approach necessitates maintaining "subtask-tool atomicity alignment," as the toolbox can evolve dynamically. To address these limitations, we introduce the Progressive Tool retrieval to Improve Planning (ProTIP) framework. ProTIP is a lightweight, contrastive learning-based framework that implicitly performs TD without the explicit requirement of subtask labels, while simultaneously maintaining subtask-tool atomicity. On the ToolBench dataset, ProTIP outperforms the ChatGPT task decomposition-based approach by a remarkable margin, achieving a 24% improvement in Recall@K=10 for TR and a 41% enhancement in tool accuracy for plan generation.
Understanding Knowledge Gaps in Visual Question Answering: Implications for Gap Identification and Testing
Apr 08, 2020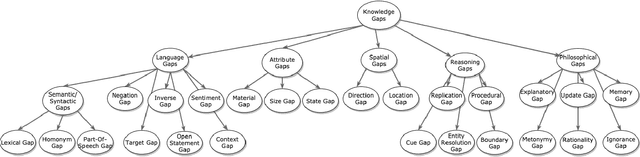
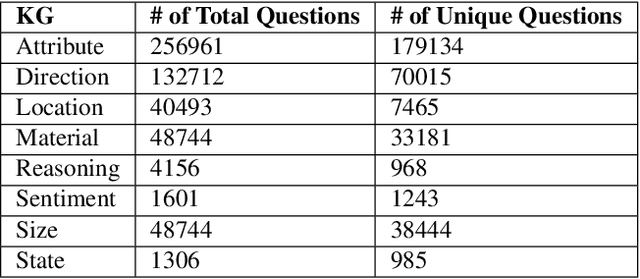

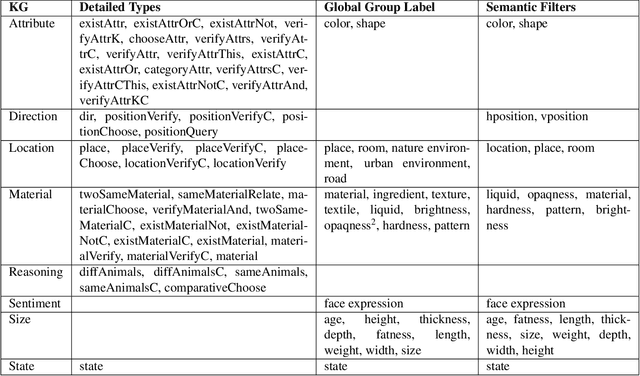
Visual Question Answering (VQA) systems are tasked with answering natural language questions corresponding to a presented image. Current VQA datasets typically contain questions related to the spatial information of objects, object attributes, or general scene questions. Recently, researchers have recognized the need for improving the balance of such datasets to reduce the system's dependency on memorized linguistic features and statistical biases and to allow for improved visual understanding. However, it is unclear as to whether there are any latent patterns that can be used to quantify and explain these failures. To better quantify our understanding of the performance of VQA models, we use a taxonomy of Knowledge Gaps (KGs) to identify/tag questions with one or more types of KGs. Each KG describes the reasoning abilities needed to arrive at a resolution, and failure to resolve gaps indicate an absence of the required reasoning ability. After identifying KGs for each question, we examine the skew in the distribution of the number of questions for each KG. In order to reduce the skew in the distribution of questions across KGs, we introduce a targeted question generation model. This model allows us to generate new types of questions for an image.
ATP: Directed Graph Embedding with Asymmetric Transitivity Preservation
Nov 06, 2018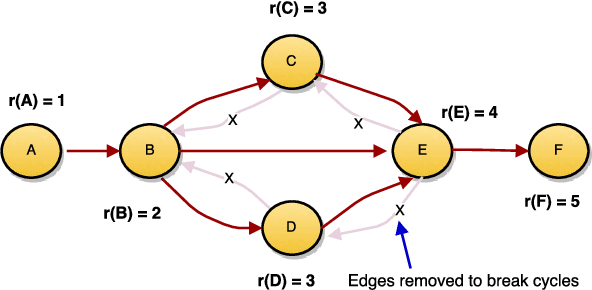
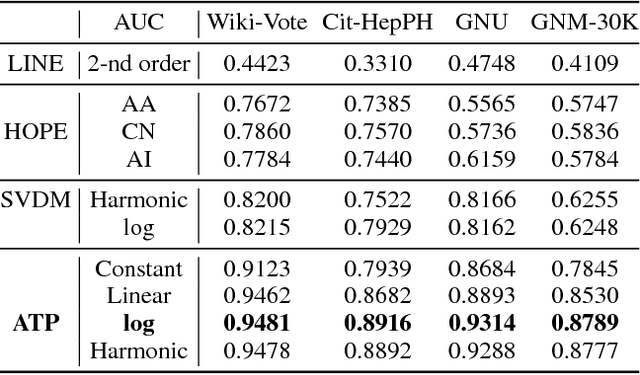
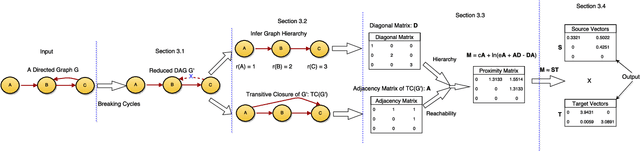
Directed graphs have been widely used in Community Question Answering services (CQAs) to model asymmetric relationships among different types of nodes in CQA graphs, e.g., question, answer, user. Asymmetric transitivity is an essential property of directed graphs, since it can play an important role in downstream graph inference and analysis. Question difficulty and user expertise follow the characteristic of asymmetric transitivity. Maintaining such properties, while reducing the graph to a lower dimensional vector embedding space, has been the focus of much recent research. In this paper, we tackle the challenge of directed graph embedding with asymmetric transitivity preservation and then leverage the proposed embedding method to solve a fundamental task in CQAs: how to appropriately route and assign newly posted questions to users with the suitable expertise and interest in CQAs. The technique incorporates graph hierarchy and reachability information naturally by relying on a non-linear transformation that operates on the core reachability and implicit hierarchy within such graphs. Subsequently, the methodology levers a factorization-based approach to generate two embedding vectors for each node within the graph, to capture the asymmetric transitivity. Extensive experiments show that our framework consistently and significantly outperforms the state-of-the-art baselines on two diverse real-world tasks: link prediction, and question difficulty estimation and expert finding in online forums like Stack Exchange. Particularly, our framework can support inductive embedding learning for newly posted questions (unseen nodes during training), and therefore can properly route and assign these kinds of questions to experts in CQAs.
Cognitive Database: A Step towards Endowing Relational Databases with Artificial Intelligence Capabilities
Dec 19, 2017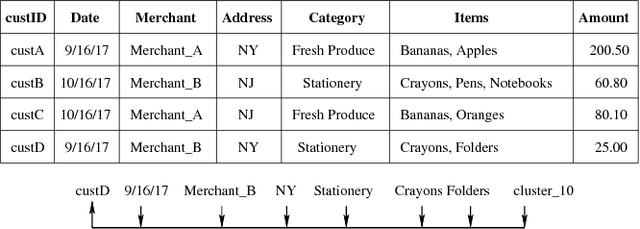
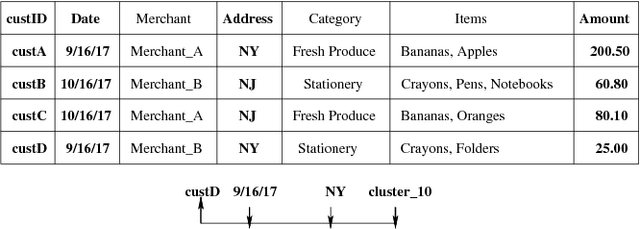
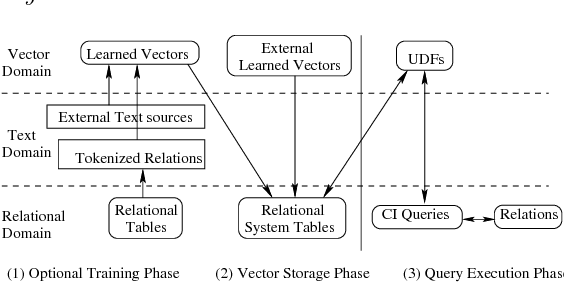
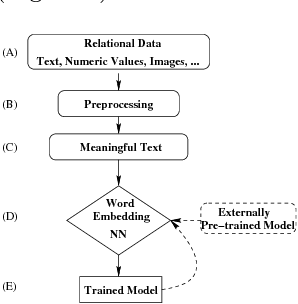
We propose Cognitive Databases, an approach for transparently enabling Artificial Intelligence (AI) capabilities in relational databases. A novel aspect of our design is to first view the structured data source as meaningful unstructured text, and then use the text to build an unsupervised neural network model using a Natural Language Processing (NLP) technique called word embedding. This model captures the hidden inter-/intra-column relationships between database tokens of different types. For each database token, the model includes a vector that encodes contextual semantic relationships. We seamlessly integrate the word embedding model into existing SQL query infrastructure and use it to enable a new class of SQL-based analytics queries called cognitive intelligence (CI) queries. CI queries use the model vectors to enable complex queries such as semantic matching, inductive reasoning queries such as analogies, predictive queries using entities not present in a database, and, more generally, using knowledge from external sources. We demonstrate unique capabilities of Cognitive Databases using an Apache Spark based prototype to execute inductive reasoning CI queries over a multi-modal database containing text and images. We believe our first-of-a-kind system exemplifies using AI functionality to endow relational databases with capabilities that were previously very hard to realize in practice.