 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Camera-Based Adaptive Trajectory Guidance via Neural Networks
Jan 09, 2020


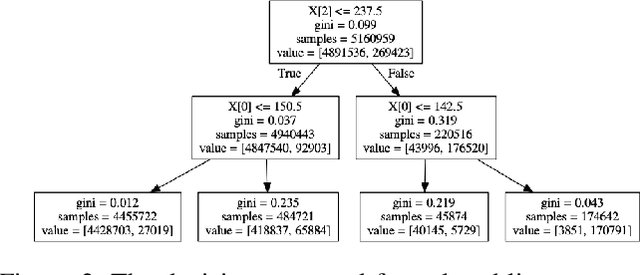
In this paper, we introduce a novel method to capture visual trajectories for navigating an indoor robot in dynamic settings using streaming image data. First, an image processing pipeline is proposed to accurately segment trajectories from noisy backgrounds. Next, the captured trajectories are used to design, train, and compare two neural network architectures for predicting acceleration and steering commands for a line following robot over a continuous space in real time. Lastly, experimental results demonstrate the performance of the neural networks versus human teleoperation of the robot and the viability of the system in environments with occlusions and/or low-light conditions.
Bootstrapping Disjoint Datasets for Multilingual Multimodal Representation Learning
Nov 09, 2019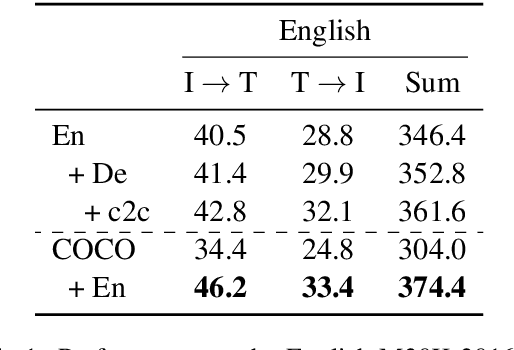

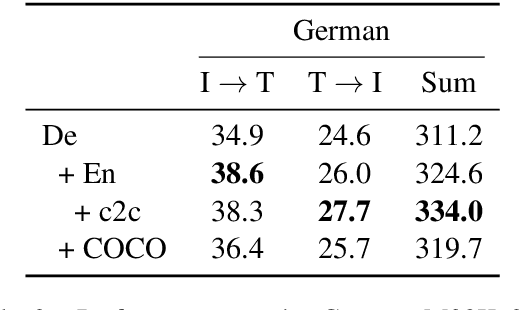

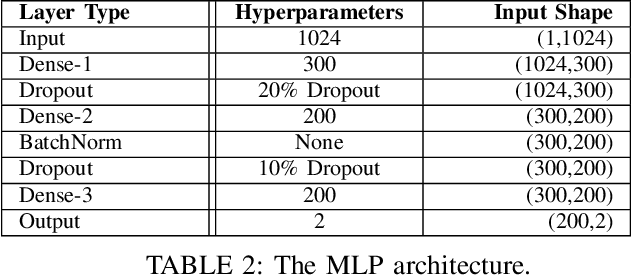
Recent work has highlighted the advantage of jointly learning grounded sentence representations from multiple languages. However, the data used in these studies has been limited to an aligned scenario: the same images annotated with sentences in multiple languages. We focus on the more realistic disjoint scenario in which there is no overlap between the images in multilingual image--caption datasets. We confirm that training with aligned data results in better grounded sentence representations than training with disjoint data, as measured by image--sentence retrieval performance. In order to close this gap in performance, we propose a pseudopairing method to generate synthetically aligned English--German--image triplets from the disjoint sets. The method works by first training a model on the disjoint data, and then creating new triples across datasets using sentence similarity under the learned model. Experiments show that pseudopairs improve image--sentence retrieval performance compared to disjoint training, despite requiring no external data or models. However, we do find that using an external machine translation model to generate the synthetic data sets results in better performance.
A superconducting nanowire spiking element for neural networks
Jul 29, 2020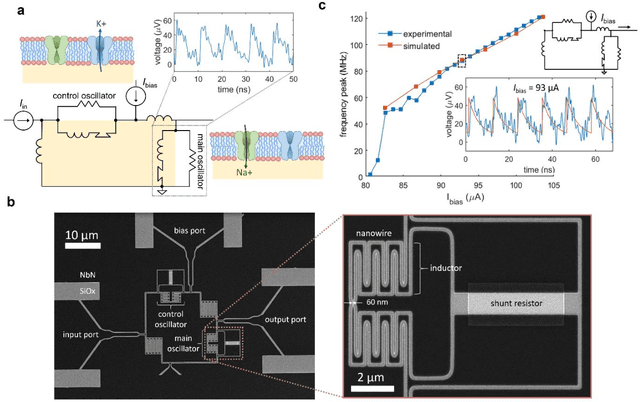
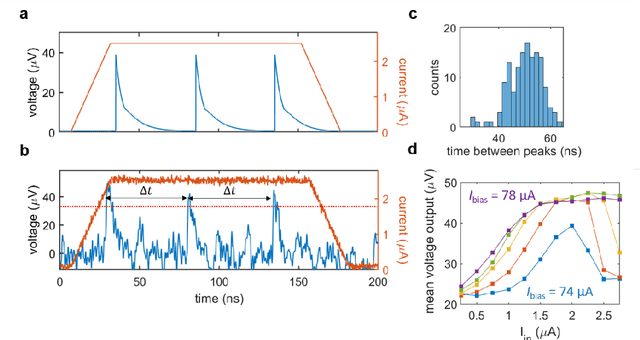
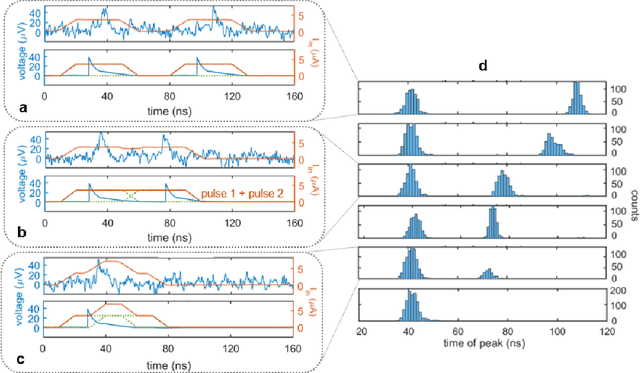
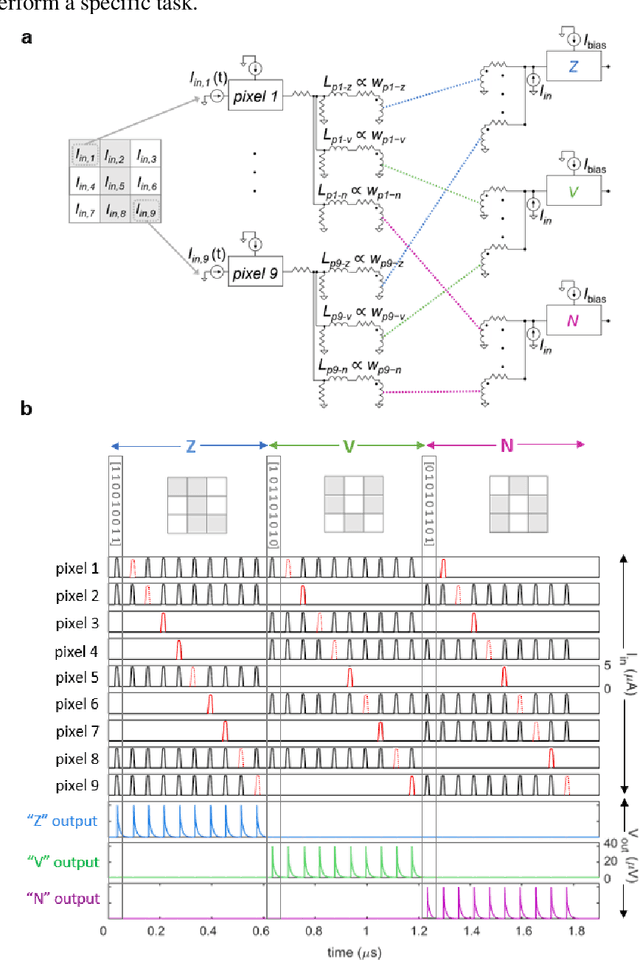
As the limits of traditional von Neumann computing come into view, the brain's ability to communicate vast quantities of information using low-power spikes has become an increasing source of inspiration for alternative architectures. Key to the success of these largescale neural networks is a power-efficient spiking element that is scalable and easily interfaced with traditional control electronics. In this work, we present a spiking element fabricated from superconducting nanowires that has pulse energies on the order of ~10 aJ. We demonstrate that the device reproduces essential characteristics of biological neurons, such as a refractory period and a firing threshold. Through simulations using experimentally measured device parameters, we show how nanowire-based networks may be used for inference in image recognition, and that the probabilistic nature of nanowire switching may be exploited for modeling biological processes and for applications that rely on stochasticity.
PointAR: Efficient Lighting Estimation for Mobile Augmented Reality
Mar 30, 2020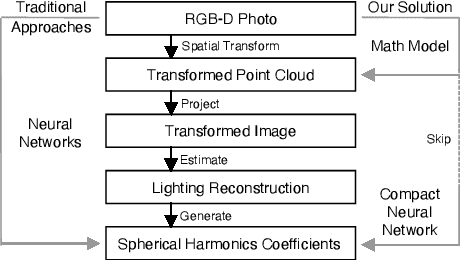
We propose an efficient lighting estimation pipeline that is suitable to run on modern mobile devices, with comparable resource complexities to state-of-the-art on-device deep learning models. Our pipeline, referred to as PointAR, takes a single RGB-D image captured from the mobile camera and a 2D location in that image, and estimates a 2nd order spherical harmonics coefficients which can be directly utilized by rendering engines for indoor lighting in the context of augmented reality. Our key insight is to formulate the lighting estimation as a learning problem directly from point clouds, which is in part inspired by the Monte Carlo integration leveraged by real-time spherical harmonics lighting. While existing approaches estimate lighting information with complex deep learning pipelines, our method focuses on reducing the computational complexity. Through both quantitative and qualitative experiments, we demonstrate that PointAR achieves lower lighting estimation errors compared to state-of-the-art methods. Further, our method requires an order of magnitude lower resource, comparable to that of mobile-specific DNNs.
Blind Image Deblurring by Spectral Properties of Convolution Operators
Apr 22, 2014



In this paper, we study the problem of recovering a sharp version of a given blurry image when the blur kernel is unknown. Previous methods often introduce an image-independent regularizer (such as Gaussian or sparse priors) on the desired blur kernel. We shall show that the blurry image itself encodes rich information about the blur kernel. Such information can be found through analyzing and comparing how the spectrum of an image as a convolution operator changes before and after blurring. Our analysis leads to an effective convex regularizer on the blur kernel which depends only on the given blurry image. We show that the minimizer of this regularizer guarantees to give good approximation to the blur kernel if the original image is sharp enough. By combining this powerful regularizer with conventional image deblurring techniques, we show how we could significantly improve the deblurring results through simulations and experiments on real images. In addition, our analysis and experiments help explaining a widely accepted doctrine; that is, the edges are good features for deblurring.
Deep Belief Networks for Image Denoising
Jan 02, 2014

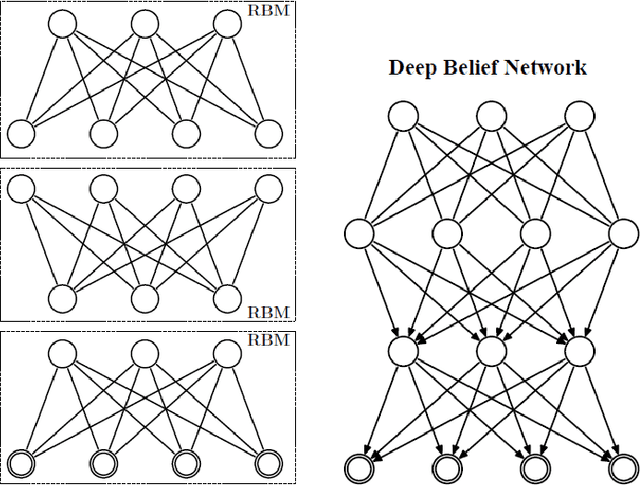
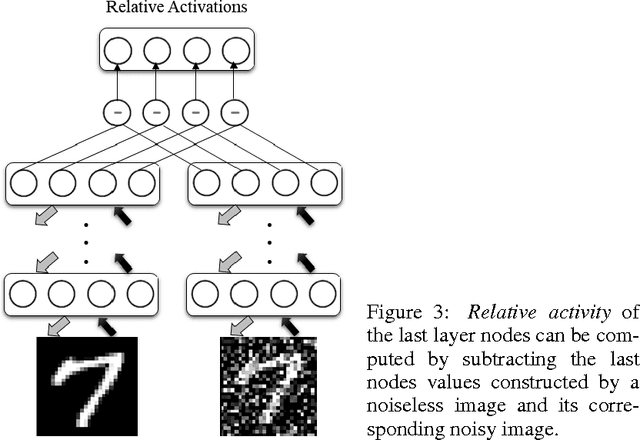
Deep Belief Networks which are hierarchical generative models are effective tools for feature representation and extraction. Furthermore, DBNs can be used in numerous aspects of Machine Learning such as image denoising. In this paper, we propose a novel method for image denoising which relies on the DBNs' ability in feature representation. This work is based upon learning of the noise behavior. Generally, features which are extracted using DBNs are presented as the values of the last layer nodes. We train a DBN a way that the network totally distinguishes between nodes presenting noise and nodes presenting image content in the last later of DBN, i.e. the nodes in the last layer of trained DBN are divided into two distinct groups of nodes. After detecting the nodes which are presenting the noise, we are able to make the noise nodes inactive and reconstruct a noiseless image. In section 4 we explore the results of applying this method on the MNIST dataset of handwritten digits which is corrupted with additive white Gaussian noise (AWGN). A reduction of 65.9% in average mean square error (MSE) was achieved when the proposed method was used for the reconstruction of the noisy images.
Object-based Illumination Estimation with Rendering-aware Neural Networks
Aug 06, 2020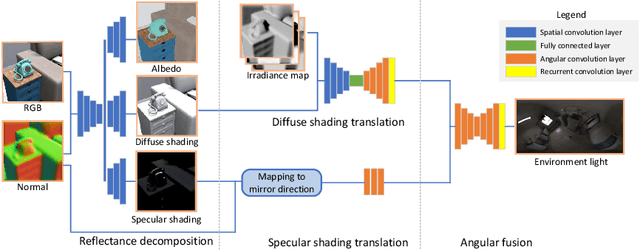
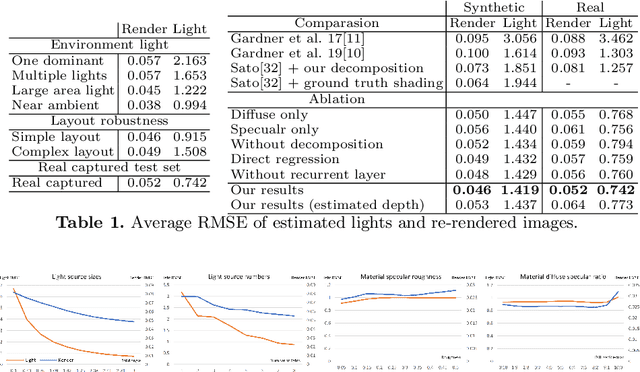


We present a scheme for fast environment light estimation from the RGBD appearance of individual objects and their local image areas. Conventional inverse rendering is too computationally demanding for real-time applications, and the performance of purely learning-based techniques may be limited by the meager input data available from individual objects. To address these issues, we propose an approach that takes advantage of physical principles from inverse rendering to constrain the solution, while also utilizing neural networks to expedite the more computationally expensive portions of its processing, to increase robustness to noisy input data as well as to improve temporal and spatial stability. This results in a rendering-aware system that estimates the local illumination distribution at an object with high accuracy and in real time. With the estimated lighting, virtual objects can be rendered in AR scenarios with shading that is consistent to the real scene, leading to improved realism.
Local Rotation Invariance in 3D CNNs
Mar 19, 2020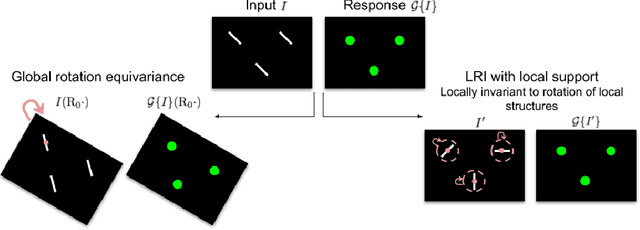
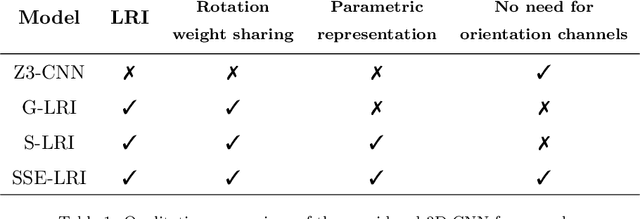
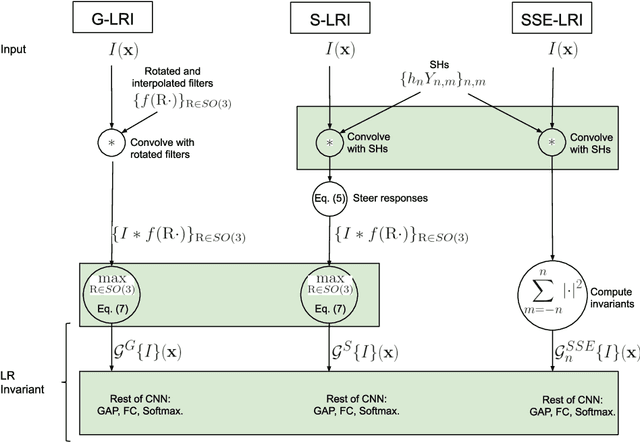
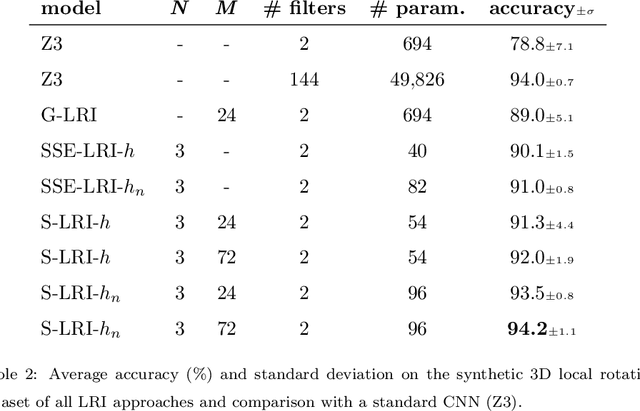
Locally Rotation Invariant (LRI) image analysis was shown to be fundamental in many applications and in particular in medical imaging where local structures of tissues occur at arbitrary rotations. LRI constituted the cornerstone of several breakthroughs in texture analysis, including Local Binary Patterns (LBP), Maximum Response 8 (MR8) and steerable filterbanks. Whereas globally rotation invariant Convolutional Neural Networks (CNN) were recently proposed, LRI was very little investigated in the context of deep learning. LRI designs allow learning filters accounting for all orientations, which enables a drastic reduction of trainable parameters and training data when compared to standard 3D CNNs. In this paper, we propose and compare several methods to obtain LRI CNNs with directional sensitivity. Two methods use orientation channels (responses to rotated kernels), either by explicitly rotating the kernels or using steerable filters. These orientation channels constitute a locally rotation equivariant representation of the data. Local pooling across orientations yields LRI image analysis. Steerable filters are used to achieve a fine and efficient sampling of 3D rotations as well as a reduction of trainable parameters and operations, thanks to a parametric representations involving solid Spherical Harmonics (SH), which are products of SH with associated learned radial profiles.Finally, we investigate a third strategy to obtain LRI based on rotational invariants calculated from responses to a learned set of solid SHs. The proposed methods are evaluated and compared to standard CNNs on 3D datasets including synthetic textured volumes composed of rotated patterns, and pulmonary nodule classification in CT. The results show the importance of LRI image analysis while resulting in a drastic reduction of trainable parameters, outperforming standard 3D CNNs trained with data augmentation.
Line Art Correlation Matching Network for Automatic Animation Colorization
Apr 14, 2020
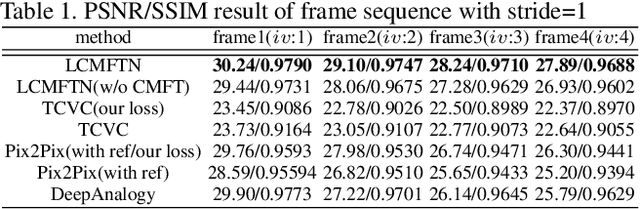
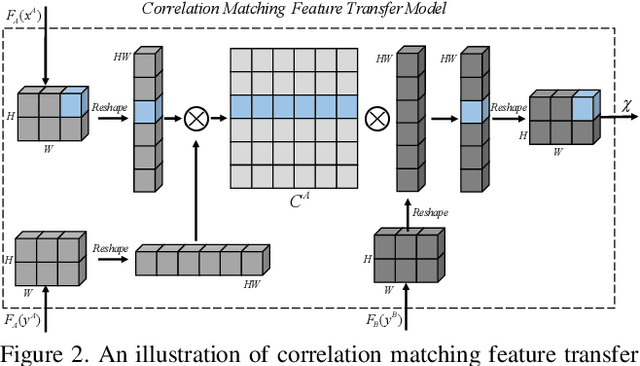
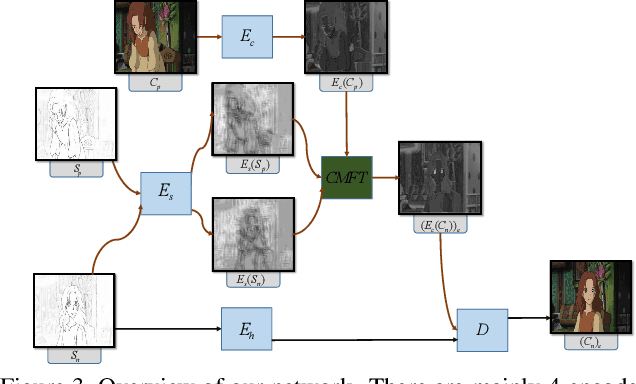
Automatic animation line art colorization is a challenging computer vision problem since line art is a highly sparse and abstracted information and there exists a strict requirement for the color and style consistency between frames. Recently, a lot of GAN(Generative Adversarial Network) based image-to-image transfer method for single line art colorization has emerged. They can generate perceptually appealing result conditioned on line art. However,these methods can not be adopted to the task of animation colorization because of the lack of consideration of in-between frame consistency. Existing methods simply input the previous colored frame as a reference to color the next line art, which will mislead the colorization due to the spatial misalignment of the previous colored frame and the next line art especially at positions where apparent changes happen. To address these challenges, we design a kind of matching model called CM(co-rrelation matching) to align the colored reference in an learnable way and integrate the model into an U-Net structure generator in a coarse-to-fine manner. Extension evaluations shows that CM model can effectively improve the in-between consistency and generating quality expecially when the motion is intense and diverse.
Learning a Recurrent Visual Representation for Image Caption Generation
Nov 20, 2014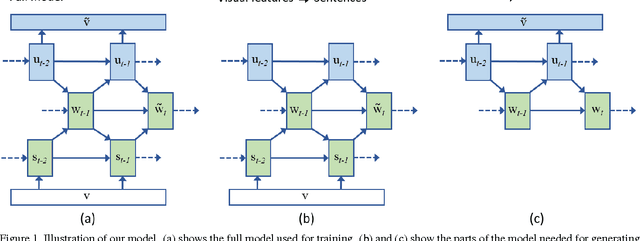
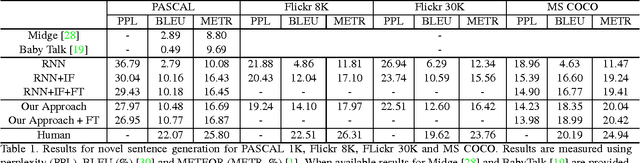

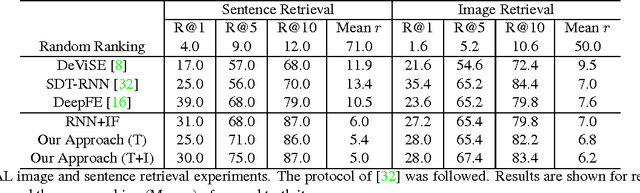
In this paper we explore the bi-directional mapping between images and their sentence-based descriptions. We propose learning this mapping using a recurrent neural network. Unlike previous approaches that map both sentences and images to a common embedding, we enable the generation of novel sentences given an image. Using the same model, we can also reconstruct the visual features associated with an image given its visual description. We use a novel recurrent visual memory that automatically learns to remember long-term visual concepts to aid in both sentence generation and visual feature reconstruction. We evaluate our approach on several tasks. These include sentence generation, sentence retrieval and image retrieval. State-of-the-art results are shown for the task of generating novel image descriptions. When compared to human generated captions, our automatically generated captions are preferred by humans over $19.8\%$ of the time. Results are better than or comparable to state-of-the-art results on the image and sentence retrieval tasks for methods using similar visual features.