 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-based marker tracking and registration for intraoperative 3D image-guided interventions using augmented reality
Aug 08, 2019
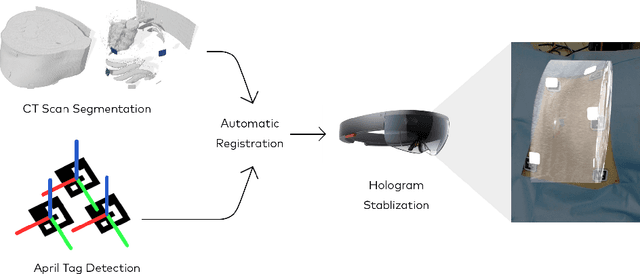
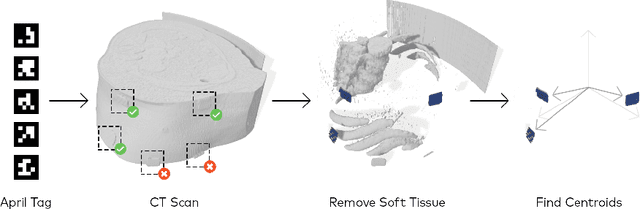
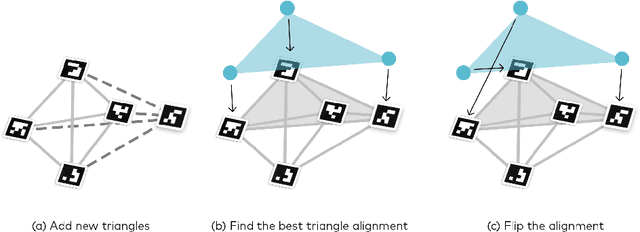
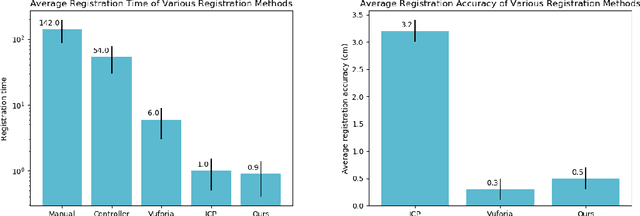
Augmented reality has the potential to improve operating room workflow by allowing physicians to "see" inside a patient through the projection of imaging directly onto the surgical field. For this to be useful the acquired imaging must be quickly and accurately registered with patient and the registration must be maintained. Here we describe a method for projecting a CT scan with Microsoft Hololens and then aligning that projection to a set of fiduciary markers. Radio-opaque stickers with unique QR-codes are placed on an object prior to acquiring a CT scan. The location of the markers in the CT scan are extracted and the CT scan is converted into a 3D surface object. The 3D object is then projected using the Hololens onto a table on which the same markers are placed. We designed an algorithm that aligns the markers on the 3D object with the markers on the table. To extract the markers and convert the CT into a 3D object took less than 5 seconds. To align three markers, it took $0.9 \pm 0.2$ seconds to achieve an accuracy of $5 \pm 2$ mm. These findings show that it is feasible to use a combined radio-opaque optical marker, placed on a patient prior to a CT scan, to subsequently align the acquired CT scan with the patient.
A Surrogate Lagrangian Relaxation-based Model Compression for Deep Neural Networks
Dec 18, 2020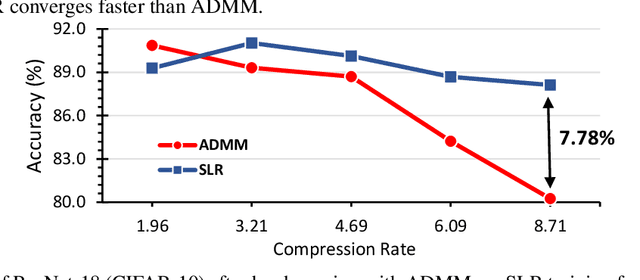
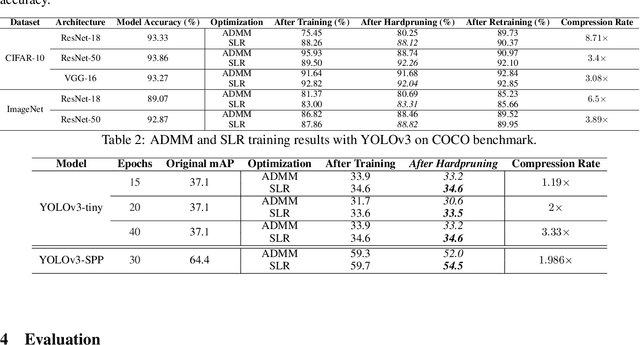
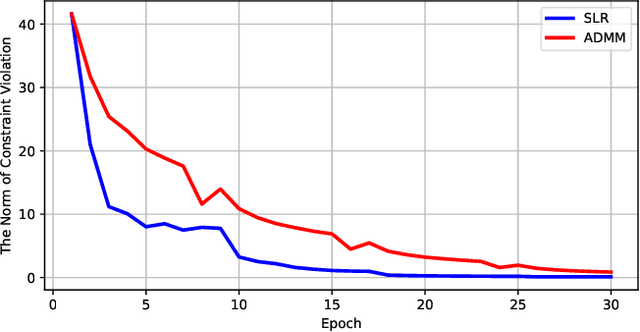
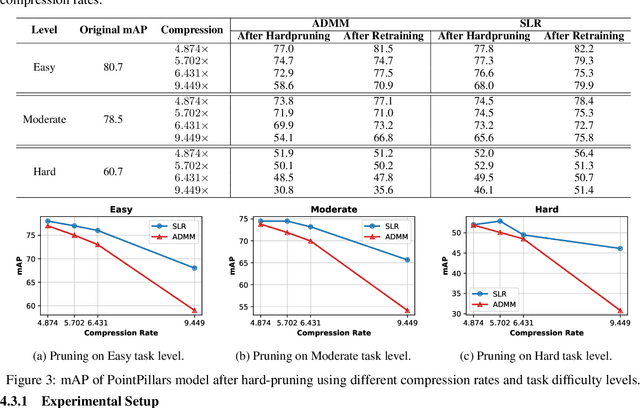
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline, i.e., training, pruning and retraining (fine-tuning) significantly increases the overall training trails. For instance, the retraining process could take up to 80 epochs for ResNet-18 on ImageNet, that is 70% of the original model training trails. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation (SLR), which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem while ensuring fast convergence. We decompose the weight-pruning problem into subproblems, which are coordinated by updating Lagrangian multipliers. Convergence is then accelerated by using quadratic penalty terms. We evaluate the proposed method on image classification tasks, i.e., ResNet-18, ResNet-50 and VGG-16 using ImageNet and CIFAR-10, as well as object detection tasks, i.e., YOLOv3 and YOLOv3-tiny using COCO 2014, PointPillars using KITTI 2017, and Ultra-Fast-Lane-Detection using TuSimple lane detection dataset. Numerical testing results demonstrate that with the adoption of the Surrogate Lagrangian Relaxation method, our SLR-based weight-pruning optimization approach achieves a high model accuracy even at the hard-pruning stage without retraining for many epochs, such as on PointPillars object detection model on KITTI dataset where we achieve 9.44x compression rate by only retraining for 3 epochs with less than 1% accuracy loss. As the compression rate increases, SLR starts to perform better than ADMM and the accuracy gap between them increases. SLR achieves 15.2% better accuracy than ADMM on PointPillars after pruning under 9.49x compression. Given a limited budget of retraining epochs, our approach quickly recovers the model accuracy.
Variational Transfer Learning for Fine-grained Few-shot Visual Recognition
Oct 12, 2020
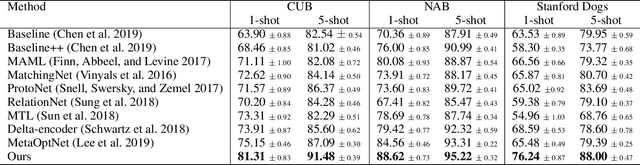
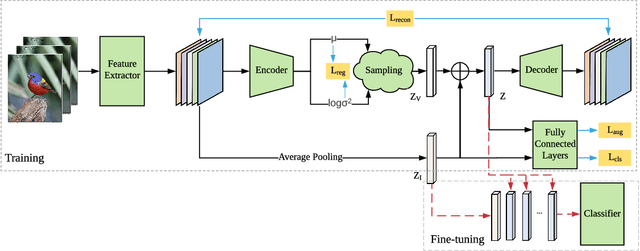
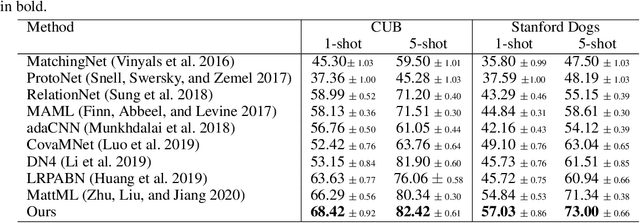
Fine-grained few-shot recognition often suffers from the problem of training data scarcity for novel categories.The network tends to overfit and does not generalize well to unseen classes due to insufficient training data. Many methods have been proposed to synthesize additional data to support the training. In this paper, we focus one enlarging the intra-class variance of the unseen class to improve few-shot classification performance. We assume that the distribution of intra-class variance generalizes across the base class and the novel class. Thus, the intra-class variance of the base set can be transferred to the novel set for feature augmentation. Specifically, we first model the distribution of intra-class variance on the base set via variational inference. Then the learned distribution is transferred to the novel set to generate additional features, which are used together with the original ones to train a classifier. Experimental results show a significant boost over the state-of-the-art methods on the challenging fine-grained few-shot image classification benchmarks.
Spatiotemporal Imaging with Diffeomorphic Optimal Transportation
Nov 24, 2020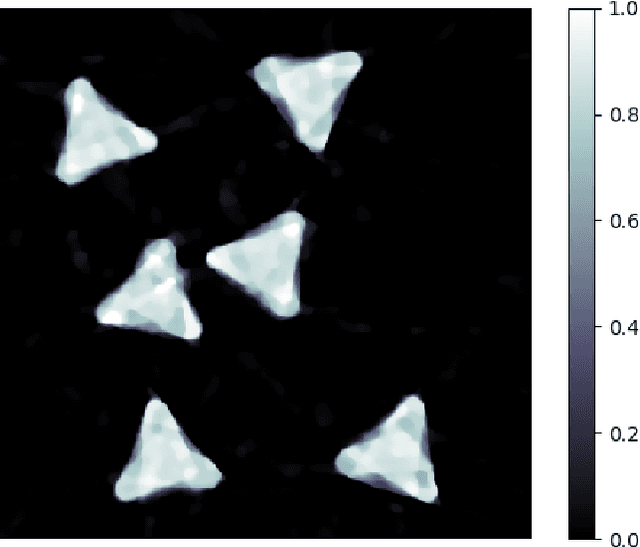

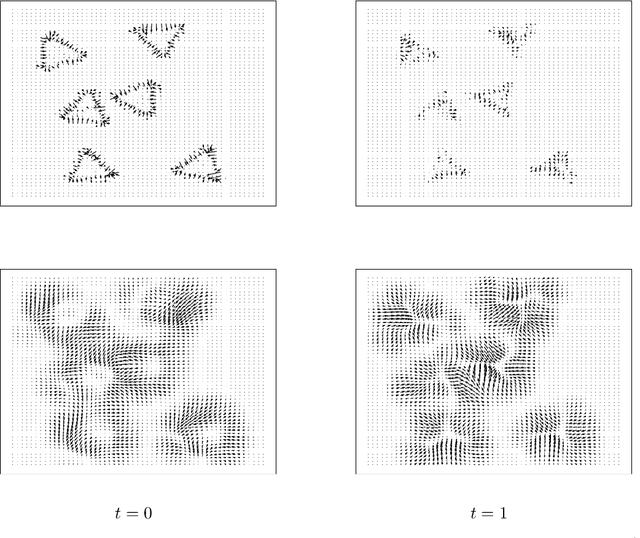
We propose a variational model with diffeomorphic optimal transportation for joint image reconstruction and motion estimation. The proposed model is a production of assembling the Wasserstein distance with the Benamou--Brenier formula in optimal transportation and the flow of diffeomorphisms involved in large deformation diffeomorphic metric mapping, which is suitable for the scenario of spatiotemporal imaging with large diffeomorphic and mass-preserving deformations. Specifically, we first use the Benamou--Brenier formula to characterize the optimal transport cost among the flow of mass-preserving images, and restrict the velocity field into the admissible Hilbert space to guarantee the generated deformation flow being diffeomorphic. We then gain the ODE-constrained equivalent formulation for Benamou--Brenier formula. We finally obtain the proposed model with ODE constraint following the framework that presented in our previous work. We further get the equivalent PDE-constrained optimal control formulation. The proposed model is compared against several existing alternatives theoretically. The alternating minimization algorithm is presented for solving the time-discretized version of the proposed model with ODE constraint. Several important issues on the proposed model and associated algorithms are also discussed. Particularly, we present several potential models based on the proposed diffeomorphic optimal transportation. Under appropriate conditions, the proposed algorithm also provides a new scheme to solve the models using quadratic Wasserstein distance. The performance is finally evaluated by several numerical experiments in space-time tomography, where the data is measured from the concerned sequential images with sparse views and/or various noise levels.
One of these (Few) Things is Not Like the Others
May 22, 2020
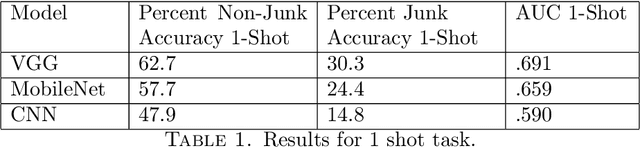
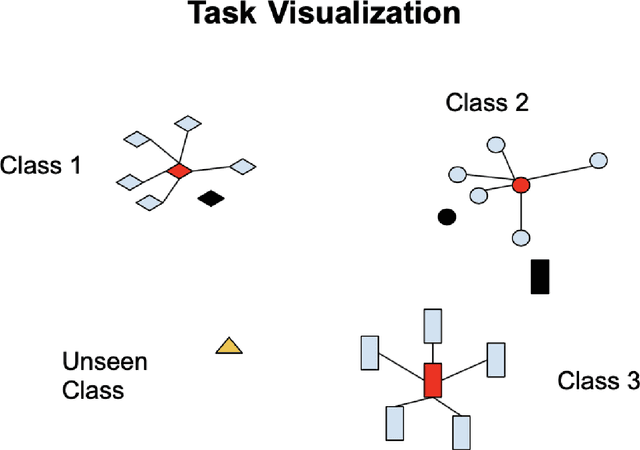
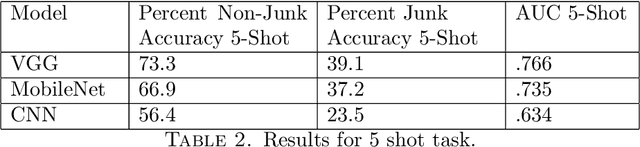
To perform well, most deep learning based image classification systems require large amounts of data and computing resources. These constraints make it difficult to quickly personalize to individual users or train models outside of fairly powerful machines. To deal with these problems, there has been a large body of research into teaching machines to learn to classify images based on only a handful of training examples, a field known as few-shot learning. Few-shot learning research traditionally makes the simplifying assumption that all images belong to one of a fixed number of previously seen groups. However, many image datasets, such as a camera roll on a phone, will be noisy and contain images that may not be relevant or fit into any clear group. We propose a model which can both classify new images based on a small number of examples and recognize images which do not belong to any previously seen group. We adapt previous few-shot learning work to include a simple mechanism for learning a cutoff that determines whether an image should be excluded or classified. We examine how well our method performs in a realistic setting, benchmarking the approach on a noisy and ambiguous dataset of images. We evaluate performance over a spectrum of model architectures, including setups small enough to be run on low powered devices, such as mobile phones or web browsers. We find that this task of excluding irrelevant images poses significant extra difficulty beyond that of the traditional few-shot task. We decompose the sources of this error, and suggest future improvements that might alleviate this difficulty.
CovidCTNet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image
May 06, 2020Coronavirus disease 2019 (Covid-19) is highly contagious with limited treatment options. Early and accurate diagnosis of Covid-19 is crucial in reducing the spread of the disease and its accompanied mortality. Currently, detection by reverse transcriptase polymerase chain reaction (RT-PCR) is the gold standard of outpatient and inpatient detection of Covid-19. RT-PCR is a rapid method, however, its accuracy in detection is only ~70-75%. Another approved strategy is computed tomography (CT) imaging. CT imaging has a much higher sensitivity of ~80-98%, but similar accuracy of 70%. To enhance the accuracy of CT imaging detection, we developed an open-source set of algorithms called CovidCTNet that successfully differentiates Covid-19 from community-acquired pneumonia (CAP) and other lung diseases. CovidCTNet increases the accuracy of CT imaging detection to 90% compared to radiologists (70%). The model is designed to work with heterogeneous and small sample sizes independent of the CT imaging hardware. In order to facilitate the detection of Covid-19 globally and assist radiologists and physicians in the screening process, we are releasing all algorithms and parametric details in an open-source format. Open-source sharing of our CovidCTNet enables developers to rapidly improve and optimize services, while preserving user privacy and data ownership.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 12, 2020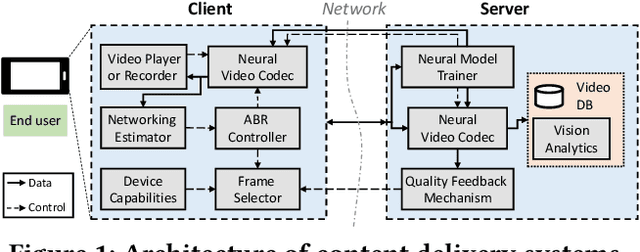


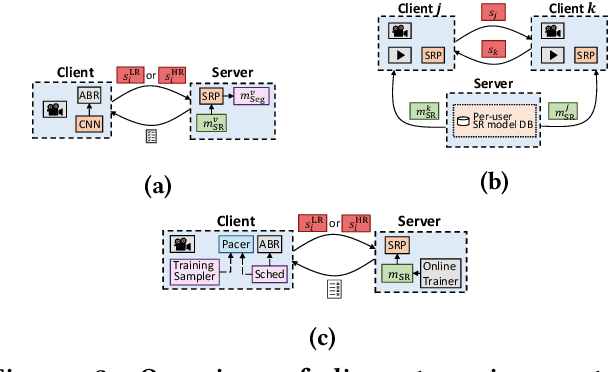
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
Emerging from Water: Underwater Image Color Correction Based on Weakly Supervised Color Transfer
Jan 03, 2018
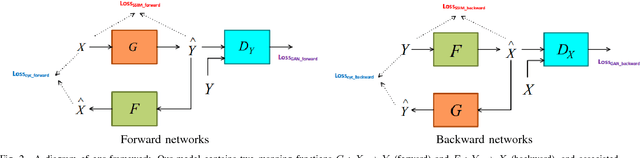


Underwater vision suffers from severe effects due to selective attenuation and scattering when light propagates through water. Such degradation not only affects the quality of underwater images but limits the ability of vision tasks. Different from existing methods which either ignore the wavelength dependency of the attenuation or assume a specific spectral profile, we tackle color distortion problem of underwater image from a new view. In this letter, we propose a weakly supervised color transfer method to correct color distortion, which relaxes the need of paired underwater images for training and allows for the underwater images unknown where were taken. Inspired by Cycle-Consistent Adversarial Networks, we design a multi-term loss function including adversarial loss, cycle consistency loss, and SSIM (Structural Similarity Index Measure) loss, which allows the content and structure of the corrected result the same as the input, but the color as if the image was taken without the water. Experiments on underwater images captured under diverse scenes show that our method produces visually pleasing results, even outperforms the art-of-the-state methods. Besides, our method can improve the performance of vision tasks.
* Submitted to IEEE Signal Processing Letters
Fractional differentiation based image processing
Apr 07, 2015There are many resources useful for processing images, most of them freely available and quite friendly to use. In spite of this abundance of tools, a study of the processing methods is still worthy of efforts. Here, we want to discuss the possibilities arising from the use of fractional differential calculus. This calculus evolved in the research field of pure mathematics until 1920, when applied science started to use it. Only recently, fractional calculus was involved in image processing methods. As we shall see, the fractional calculation is able to enhance the quality of images, with interesting possibilities in edge detection and image restoration. We suggest also the fractional differentiation as a tool to reveal faint objects in astronomical images.
Image quality assessment measure based on natural image statistics in the Tetrolet domain
Dec 08, 2014
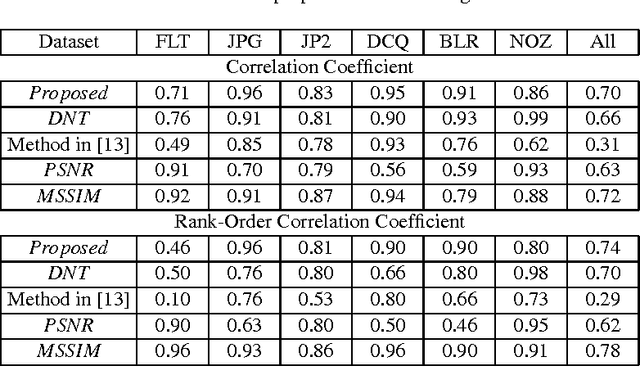

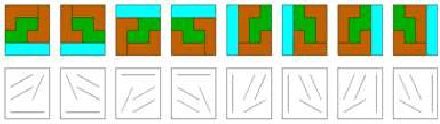
This paper deals with a reduced reference (RR) image quality measure based on natural image statistics modeling. For this purpose, Tetrolet transform is used since it provides a convenient way to capture local geometric structures. This transform is applied to both reference and distorted images. Then, Gaussian Scale Mixture (GSM) is proposed to model subbands in order to take account statistical dependencies between tetrolet coefficients. In order to quantify the visual degradation, a measure based on Kullback Leibler Divergence (KLD) is provided. The proposed measure was tested on the Cornell VCL A-57 dataset and compared with other measures according to FR-TV1 VQEG framework.