 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The STDyn-SLAM: A stereo vision and semantic segmentation approach for SLAM in dynamic outdoor environments
Oct 19, 2020

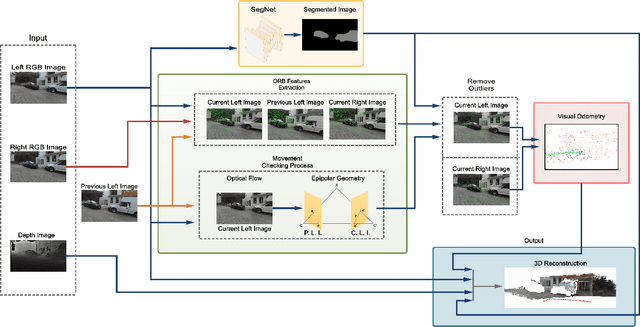
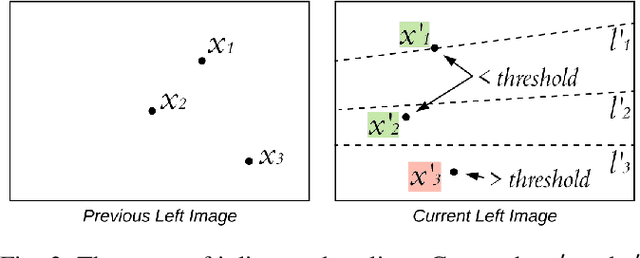
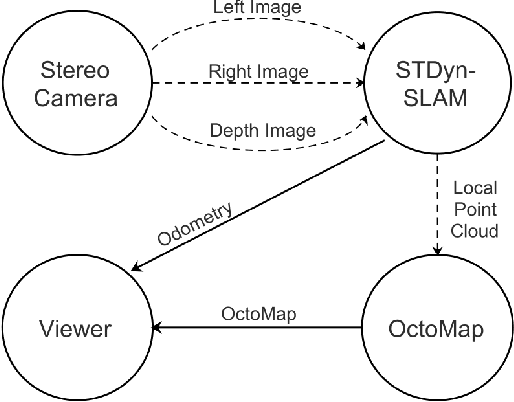
Commonly, SLAM algorithms are focused on a static environment, however, there are several scenes where dynamic objects are present. This work presents the STDyn-SLAM an image feature-based SLAM system working on dynamic environments using a series of sub-systems, like optic flow, orb features extraction, visual odometry, and convolutional neural networks to discern moving objects in the scene. The neural network is used to support object detection and segmentation to avoid erroneous maps and wrong system localization. The STDyn-SLAM employs a stereo pair and is developed for outdoor environments. Moreover, the processing time of the proposed system is fast enough to run in real-time as it was demonstrated through the experiments given in real dynamic outdoor environments. Further, we compare our SLAM with state-of-the-art methods achieving promising results.
Cross-modal Deep Face Normals with Deactivable Skip Connections
Mar 30, 2020
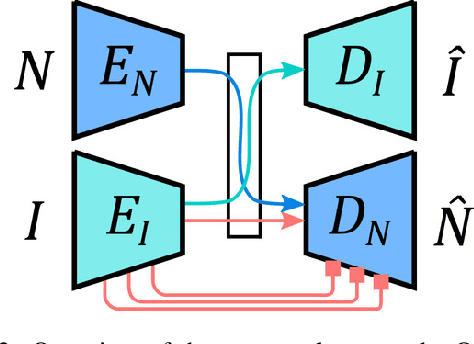
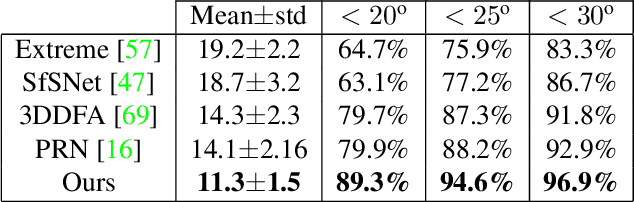
We present an approach for estimating surface normals from in-the-wild color images of faces. While data-driven strategies have been proposed for single face images, limited available ground truth data makes this problem difficult. To alleviate this issue, we propose a method that can leverage all available image and normal data, whether paired or not, thanks to a novel cross-modal learning architecture. In particular, we enable additional training with single modality data, either color or normal, by using two encoder-decoder networks with a shared latent space. The proposed architecture also enables face details to be transferred between the image and normal domains, given paired data, through skip connections between the image encoder and normal decoder. Core to our approach is a novel module that we call deactivable skip connections, which allows integrating both the auto-encoded and image-to-normal branches within the same architecture that can be trained end-to-end. This allows learning of a rich latent space that can accurately capture the normal information. We compare against state-of-the-art methods and show that our approach can achieve significant improvements, both quantitative and qualitative, with natural face images.
Visualization of Supervised and Self-Supervised Neural Networks via Attribution Guided Factorization
Dec 03, 2020

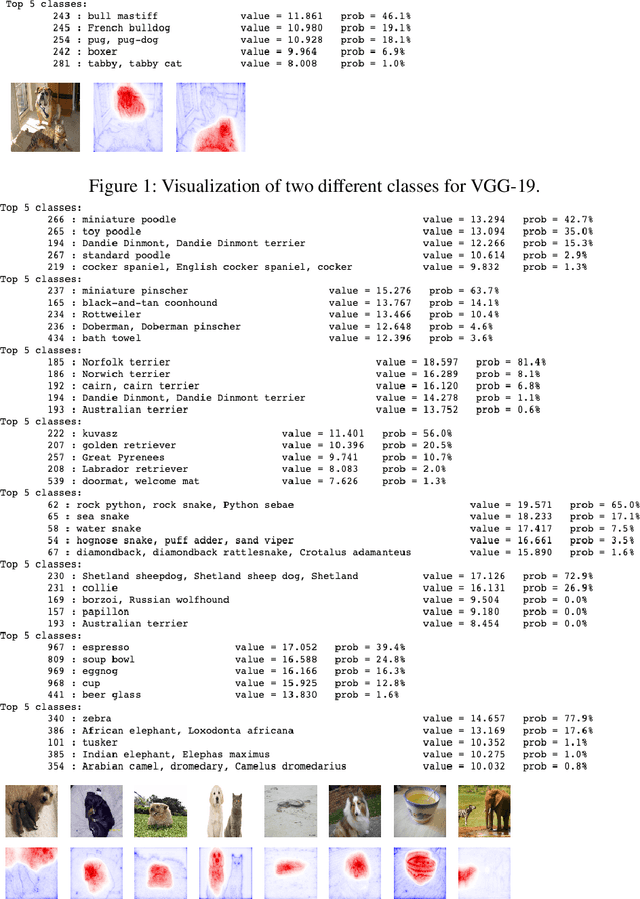
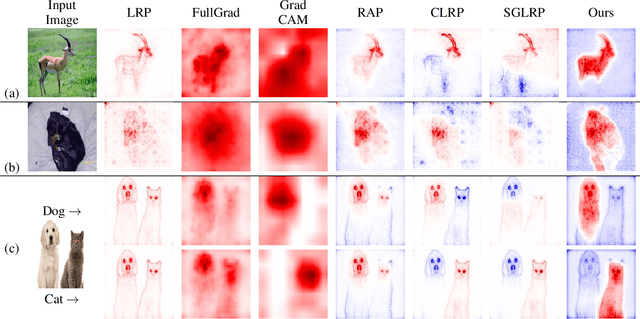
Neural network visualization techniques mark image locations by their relevancy to the network's classification. Existing methods are effective in highlighting the regions that affect the resulting classification the most. However, as we show, these methods are limited in their ability to identify the support for alternative classifications, an effect we name {\em the saliency bias} hypothesis. In this work, we integrate two lines of research: gradient-based methods and attribution-based methods, and develop an algorithm that provides per-class explainability. The algorithm back-projects the per pixel local influence, in a manner that is guided by the local attributions, while correcting for salient features that would otherwise bias the explanation. In an extensive battery of experiments, we demonstrate the ability of our methods to class-specific visualization, and not just the predicted label. Remarkably, the method obtains state of the art results in benchmarks that are commonly applied to gradient-based methods as well as in those that are employed mostly for evaluating attribution methods. Using a new unsupervised procedure, our method is also successful in demonstrating that self-supervised methods learn semantic information.
Multi-channel Weighted Nuclear Norm Minimization for Real Color Image Denoising
May 28, 2017
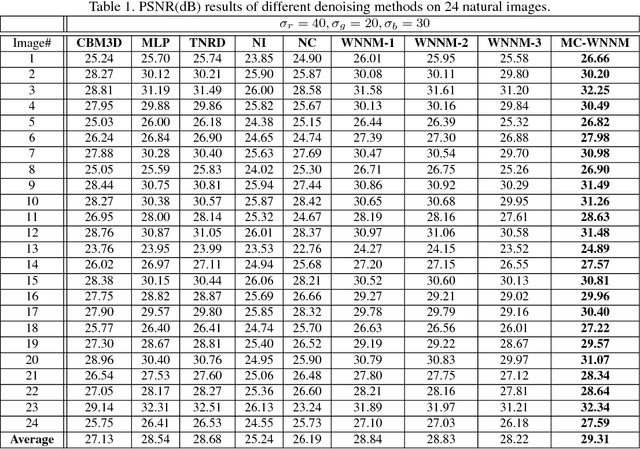

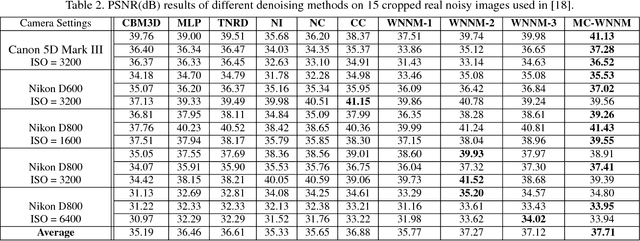
Most of the existing denoising algorithms are developed for grayscale images, while it is not a trivial work to extend them for color image denoising because the noise statistics in R, G, B channels can be very different for real noisy images. In this paper, we propose a multi-channel (MC) optimization model for real color image denoising under the weighted nuclear norm minimization (WNNM) framework. We concatenate the RGB patches to make use of the channel redundancy, and introduce a weight matrix to balance the data fidelity of the three channels in consideration of their different noise statistics. The proposed MC-WNNM model does not have an analytical solution. We reformulate it into a linear equality-constrained problem and solve it with the alternating direction method of multipliers. Each alternative updating step has closed-form solution and the convergence can be guaranteed. Extensive experiments on both synthetic and real noisy image datasets demonstrate the superiority of the proposed MC-WNNM over state-of-the-art denoising methods.
Application of Structural Similarity Analysis of Visually Salient Areas and Hierarchical Clustering in the Screening of Similar Wireless Capsule Endoscopic Images
Apr 01, 2020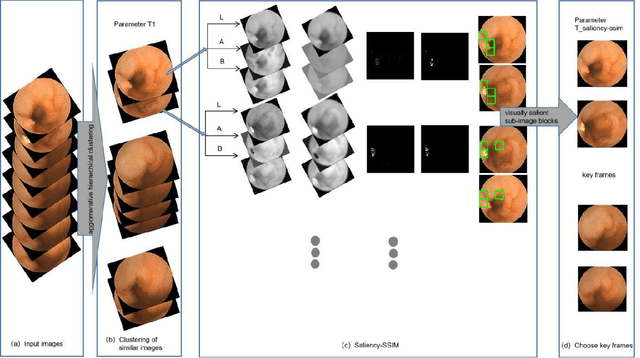
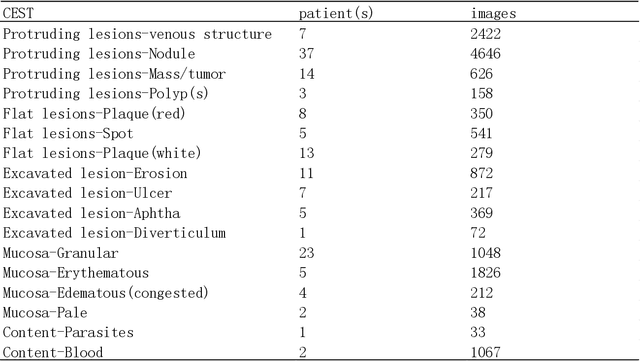

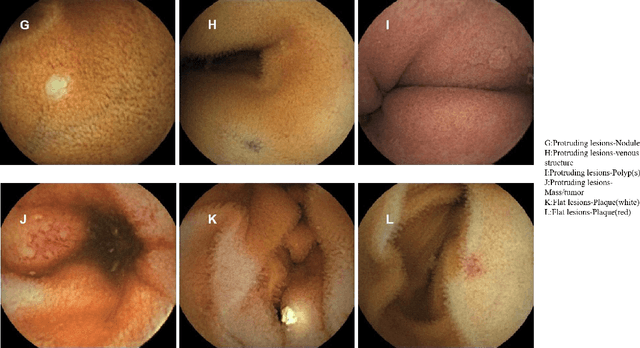
Small intestinal capsule endoscopy is the mainstream method for inspecting small intestinal lesions,but a single small intestinal capsule endoscopy will produce 60,000 - 120,000 images, the majority of which are similar and have no diagnostic value. It takes 2 - 3 hours for doctors to identify lesions from these images. This is time-consuming and increase the probability of misdiagnosis and missed diagnosis since doctors are likely to experience visual fatigue while focusing on a large number of similar images for an extended period of time.In order to solve these problems, we proposed a similar wireless capsule endoscope (WCE) image screening method based on structural similarity analysis and the hierarchical clustering of visually salient sub-image blocks. The similarity clustering of images was automatically identified by hierarchical clustering based on the hue,saturation,value (HSV) spatial color characteristics of the images,and the keyframe images were extracted based on the structural similarity of the visually salient sub-image blocks, in order to accurately identify and screen out similar small intestinal capsule endoscopic images. Subsequently, the proposed method was applied to the capsule endoscope imaging workstation. After screening out similar images in the complete data gathered by the Type I OMOM Small Intestinal Capsule Endoscope from 52 cases covering 17 common types of small intestinal lesions, we obtained a lesion recall of 100% and an average similar image reduction ratio of 76%. With similar images screened out, the average play time of the OMOM image workstation was 18 minutes, which greatly reduced the time spent by doctors viewing the images.
Single image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction
Mar 18, 2017

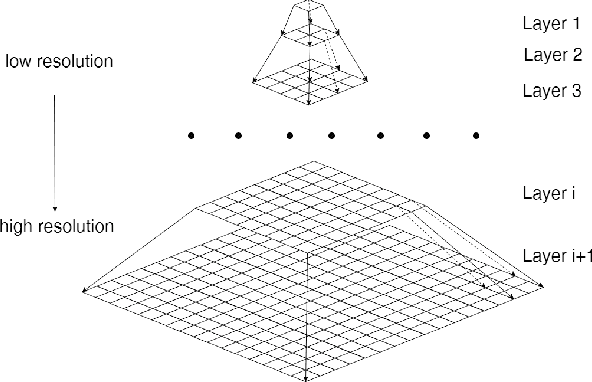
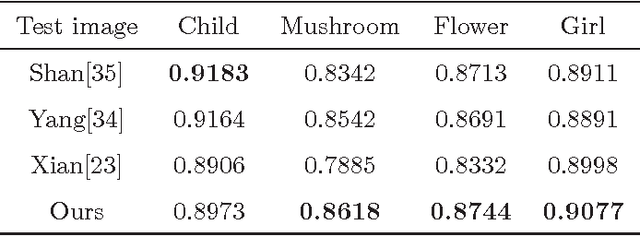
Image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction aims to recover detailed information from low-resolution images and reconstruct them into high-resolution images. Due to the limited amount of data and information retrieved from low-resolution images, it is difficult to restore clear, artifact-free images, while still preserving enough structure of the image such as the texture. This paper presents a new single image super-resolution method which is based on adaptive fractional-order gradient interpolation and reconstruction. The interpolated image gradient via optimal fractional-order gradient is first constructed according to the image similarity and afterwards the minimum energy function is employed to reconstruct the final high-resolution image. Fractional-order gradient based interpolation methods provide an additional degree of freedom which helps optimize the implementation quality due to the fact that an extra free parameter $\alpha$-order is being used. The proposed method is able to produce a rich texture detail while still being able to maintain structural similarity even under large zoom conditions. Experimental results show that the proposed method performs better than current single image super-resolution techniques.
Ontology-driven Event Type Classification in Images
Nov 09, 2020
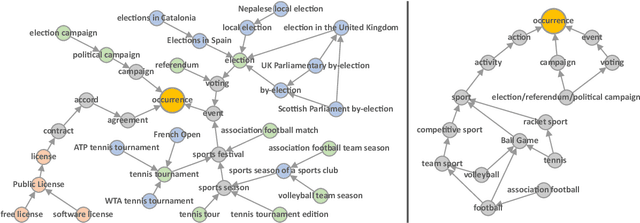
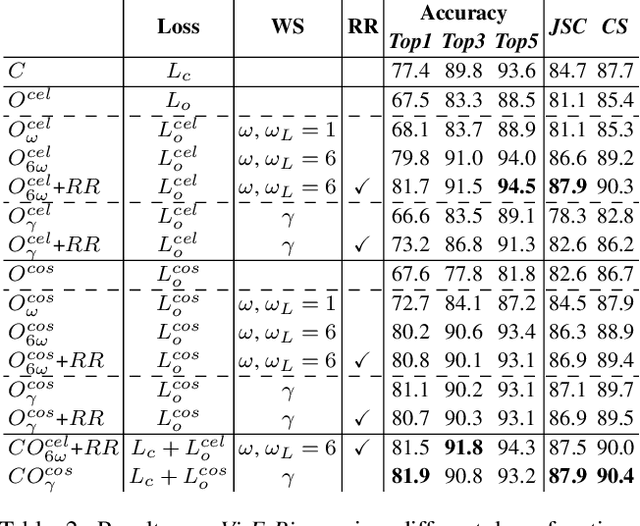
Event classification can add valuable information for semantic search and the increasingly important topic of fact validation in news. So far, only few approaches address image classification for newsworthy event types such as natural disasters, sports events, or elections. Previous work distinguishes only between a limited number of event types and relies on rather small datasets for training. In this paper, we present a novel ontology-driven approach for the classification of event types in images. We leverage a large number of real-world news events to pursue two objectives: First, we create an ontology based on Wikidata comprising the majority of event types. Second, we introduce a novel large-scale dataset that was acquired through Web crawling. Several baselines are proposed including an ontology-driven learning approach that aims to exploit structured information of a knowledge graph to learn relevant event relations using deep neural networks. Experimental results on existing as well as novel benchmark datasets demonstrate the superiority of the proposed ontology-driven approach.
Open-World Learning Without Labels
Dec 14, 2020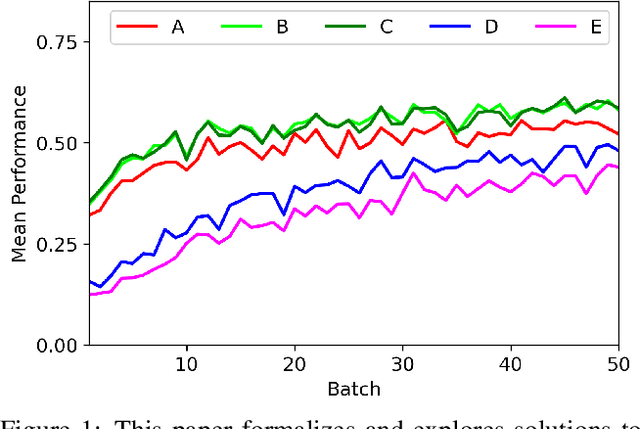

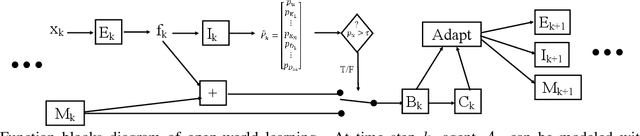
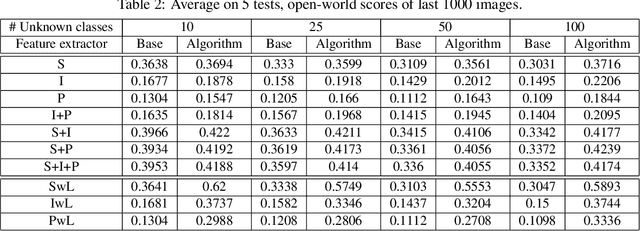
Open-world learning is a problem where an autonomous agent detects things that it does not know and learns them over time from a non-stationary and never-ending stream of data; in an open-world environment, the training data and objective criteria are never available at once. The agent should grasp new knowledge from learning without forgetting acquired prior knowledge. Researchers proposed a few open-world learning agents for image classification tasks that operate in complex scenarios. However, all prior work on open-world learning has all labeled data to learn the new classes from the stream of images. In scenarios where autonomous agents should respond in near real-time or work in areas with limited communication infrastructure, human labeling of data is not possible. Therefore, supervised open-world learning agents are not scalable solutions for such applications. Herein, we propose a new framework that enables agents to learn new classes from a stream of unlabeled data in an unsupervised manner. Also, we study the robustness and learning speed of such agents with supervised and unsupervised feature representation. We also introduce a new metric for open-world learning without labels. We anticipate our theories and method to be a starting point for developing autonomous true open-world never-ending learning agents.
DIPN: Deep Interaction Prediction Network with Application to Clutter Removal
Nov 09, 2020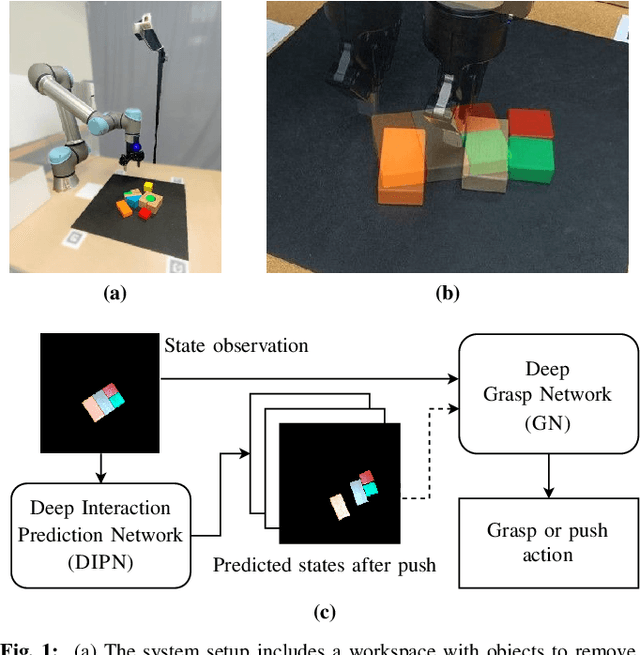
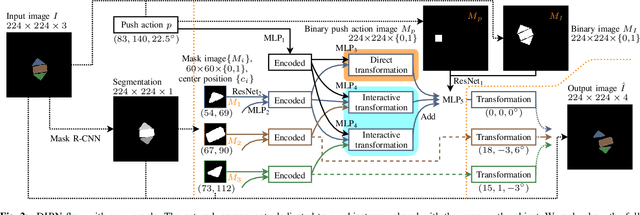
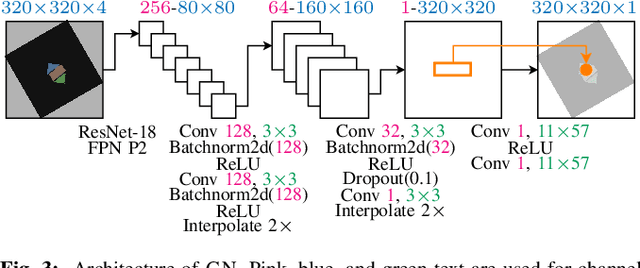
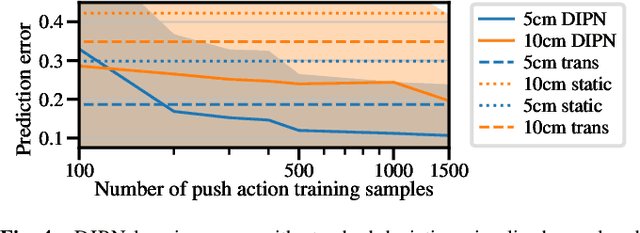
We propose a Deep Interaction Prediction Network (DIPN) for learning to predict complex interactions that ensue as a robot end-effector pushes multiple objects, whose physical properties, including size, shape, mass, and friction coefficients may be unknown a priori. DIPN "imagines" the effect of a push action and generates an accurate synthetic image of the predicted outcome. DIPN is shown to be sample efficient when trained in simulation or with a real robotic system. The high accuracy of DIPN allows direct integration with a grasp network, yielding a robotic manipulation system capable of executing challenging clutter removal tasks while being trained in a fully self-supervised manner. The overall network demonstrates intelligent behavior in selecting proper actions between push and grasp for completing clutter removal tasks and significantly outperforms the previous state-of-the-art. Remarkably, DIPN achieves even better performance on the real robotic hardware system than in simulation. Selected evaluation video clips, code, and experiments log are available at https://github.com/rutgers-arc-lab/dipn.
Size-to-depth: A New Perspective for Single Image Depth Estimation
Jan 13, 2018
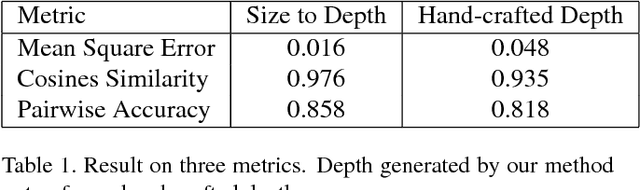


In this paper we consider the problem of single monocular image depth estimation. It is a challenging problem due to its ill-posedness nature and has found wide application in industry. Previous efforts belongs roughly to two families: learning-based method and interactive method. Learning-based method, in which deep convolutional neural network (CNN) is widely used, can achieve good result. But they suffer low generalization ability and typically perform poorly for unfamiliar scenes. Besides, data-hungry nature for such method makes data aquisition expensive and time-consuming. Interactive method requires human annotation of depth which, however, is errorneous and of large variance. To overcome these problems, we propose a new perspective for single monocular image depth estimation problem: size to depth. Our method require sparse label for real-world size of object rather than raw depth. A Coarse depth map is then inferred following geometric relationships according to size labels. Then we refine the depth map by doing energy function optimization on conditional random field(CRF). We experimentally demonstrate that our method outperforms traditional depth-labeling methods and can produce satisfactory depth maps.