 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring DeshuffleGANs in Self-Supervised Generative Adversarial Networks
Nov 03, 2020
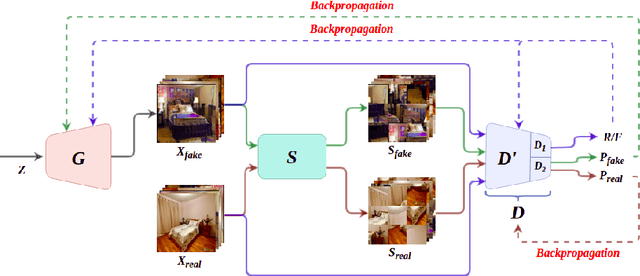

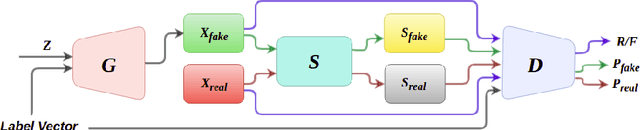

Generative Adversarial Networks (GANs) have become the most used network models towards solving the problem of image generation. In recent years, self-supervised GANs are proposed to aid stabilized GAN training without the catastrophic forgetting problem and to improve the image generation quality without the need for the class labels of the data. However, the generalizability of the self-supervision tasks on different GAN architectures is not studied before. To that end, we extensively analyze the contribution of the deshuffling task of DeshuffleGANs in the generalizability context. We assign the deshuffling task to two different GAN discriminators and study the effects of the deshuffling on both architectures. We also evaluate the performance of DeshuffleGANs on various datasets that are mostly used in GAN benchmarks: LSUN-Bedroom, LSUN-Church, and CelebA-HQ. We show that the DeshuffleGAN obtains the best FID results for LSUN datasets compared to the other self-supervised GANs. Furthermore, we compare the deshuffling with the rotation prediction that is firstly deployed to the GAN training and demonstrate that its contribution exceeds the rotation prediction. Lastly, we show the contribution of the self-supervision tasks to the GAN training on loss landscape and present that the effects of the self-supervision tasks may not be cooperative to the adversarial training in some settings. Our code can be found at https://github.com/gulcinbaykal/DeshuffleGAN.
An Efficient Evolutionary Based Method For Image Segmentation
Dec 06, 2017
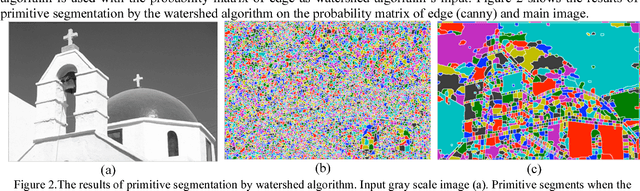
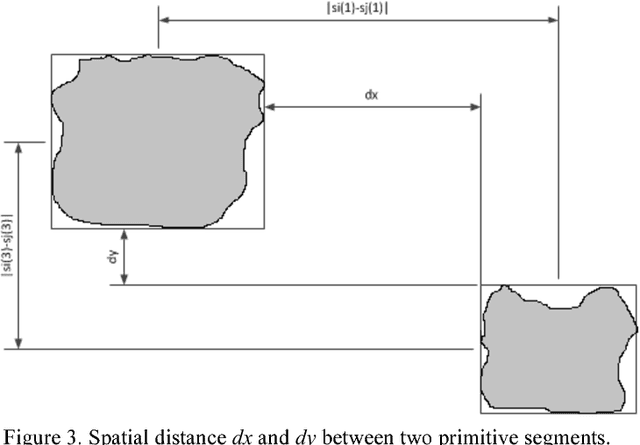
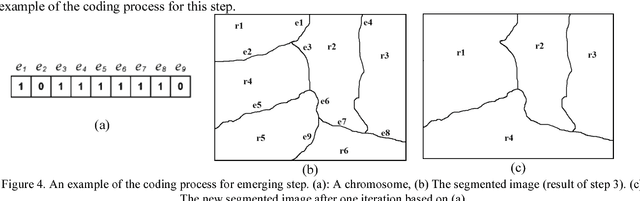
The goal of this paper is to present a new efficient image segmentation method based on evolutionary computation which is a model inspired from human behavior. Based on this model, a four layer process for image segmentation is proposed using the split/merge approach. In the first layer, an image is split into numerous regions using the watershed algorithm. In the second layer, a co-evolutionary process is applied to form centers of finals segments by merging similar primary regions. In the third layer, a meta-heuristic process uses two operators to connect the residual regions to their corresponding determined centers. In the final layer, an evolutionary algorithm is used to combine the resulted similar and neighbor regions. Different layers of the algorithm are totally independent, therefore for certain applications a specific layer can be changed without constraint of changing other layers. Some properties of this algorithm like the flexibility of its method, the ability to use different feature vectors for segmentation (grayscale, color, texture, etc), the ability to control uniformity and the number of final segments using free parameters and also maintaining small regions, makes it possible to apply the algorithm to different applications. Moreover, the independence of each region from other regions in the second layer, and the independence of centers in the third layer, makes parallel implementation possible. As a result the algorithm speed will increase. The presented algorithm was tested on a standard dataset (BSDS 300) of images, and the region boundaries were compared with different people segmentation contours. Results show the efficiency of the algorithm and its improvement to similar methods. As an instance, in 70% of tested images, results are better than ACT algorithm, besides in 100% of tested images, we had better results in comparison with VSP algorithm.
Prediction of 5-year Progression-Free Survival in Advanced Nasopharyngeal Carcinoma with Pretreatment PET/CT using Multi-Modality Deep Learning-based Radiomics
Mar 09, 2021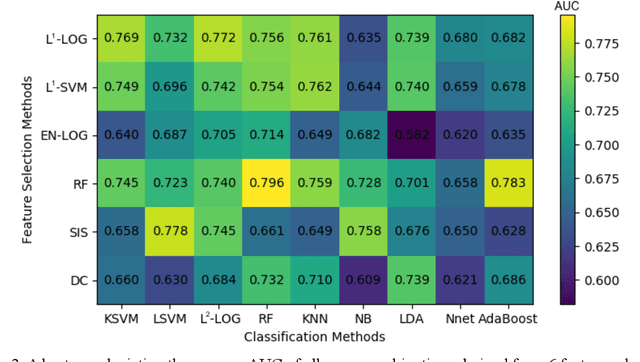
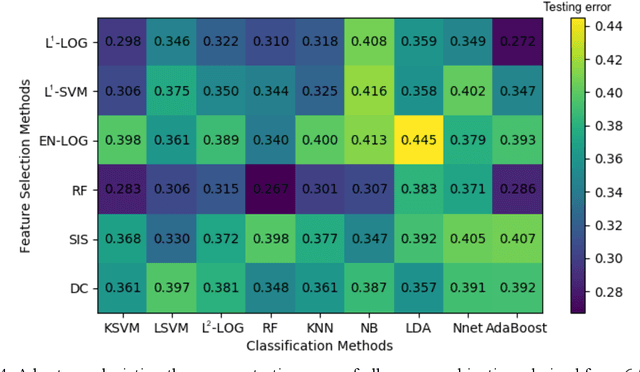
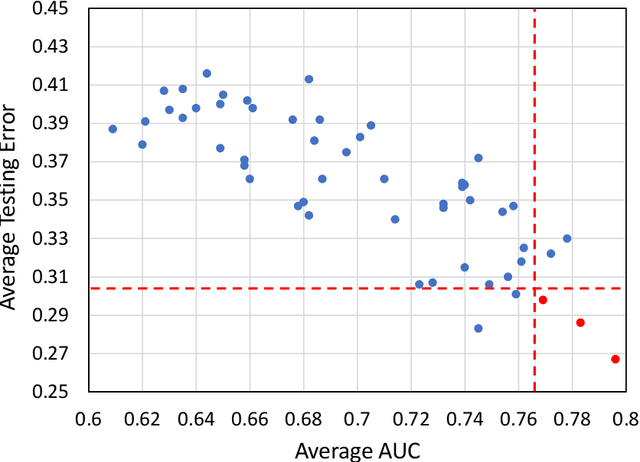
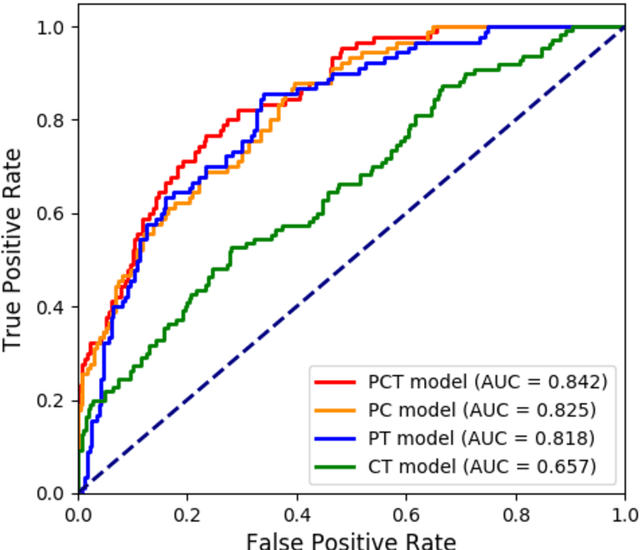
Deep Learning-based Radiomics (DLR) has achieved great success on medical image analysis. In this study, we aim to explore the capability of DLR for survival prediction in NPC. We developed an end-to-end multi-modality DLR model using pretreatment PET/CT images to predict 5-year Progression-Free Survival (PFS) in advanced NPC. A total of 170 patients with pathological confirmed advanced NPC (TNM stage III or IVa) were enrolled in this study. A 3D Convolutional Neural Network (CNN), with two branches to process PET and CT separately, was optimized to extract deep features from pretreatment multi-modality PET/CT images and use the derived features to predict the probability of 5-year PFS. Optionally, TNM stage, as a high-level clinical feature, can be integrated into our DLR model to further improve prognostic performance. For a comparison between CR and DLR, 1456 handcrafted features were extracted, and three top CR methods were selected as benchmarks from 54 combinations of 6 feature selection methods and 9 classification methods. Compared to the three CR methods, our multi-modality DLR models using both PET and CT, with or without TNM stage (named PCT or PC model), resulted in the highest prognostic performance. Furthermore, the multi-modality PCT model outperformed single-modality DLR models using only PET and TNM stage (PT model) or only CT and TNM stage (CT model). Our study identified potential radiomics-based prognostic model for survival prediction in advanced NPC, and suggests that DLR could serve as a tool for aiding in cancer management.
High-quality Panorama Stitching based on Asymmetric Bidirectional Optical Flow
Jun 01, 2020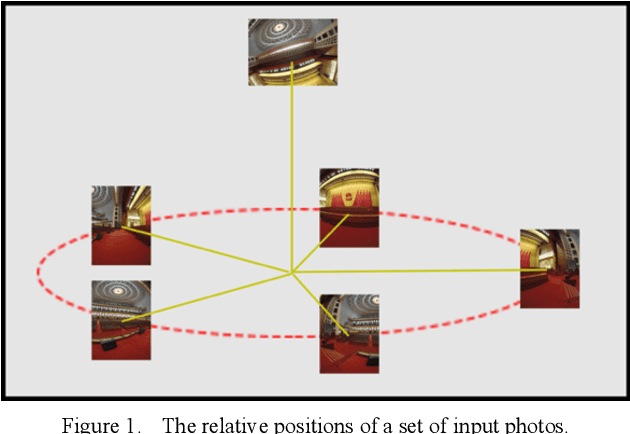
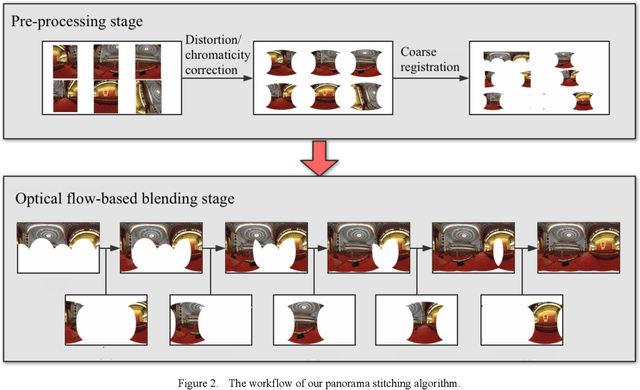
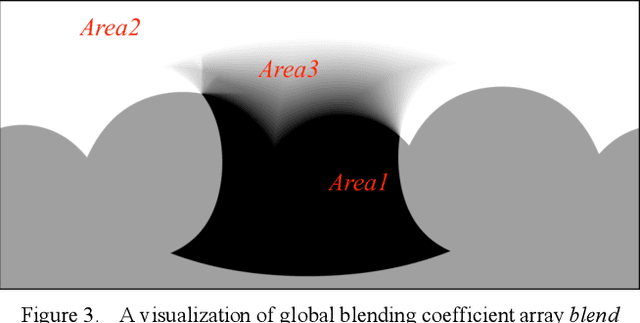

In this paper, we propose a panorama stitching algorithm based on asymmetric bidirectional optical flow. This algorithm expects multiple photos captured by fisheye lens cameras as input, and then, through the proposed algorithm, these photos can be merged into a high-quality 360-degree spherical panoramic image. For photos taken from a distant perspective, the parallax among them is relatively small, and the obtained panoramic image can be nearly seamless and undistorted. For photos taken from a close perspective or with a relatively large parallax, a seamless though partially distorted panoramic image can also be obtained. Besides, with the help of Graphics Processing Unit (GPU), this algorithm can complete the whole stitching process at a very fast speed: typically, it only takes less than 30s to obtain a panoramic image of 9000-by-4000 pixels, which means our panorama stitching algorithm is of high value in many real-time applications. Our code is available at https://github.com/MungoMeng/Panorama-OpticalFlow.
Unsupervised Pathology Image Segmentation Using Representation Learning with Spherical K-means
Apr 11, 2018This paper presents a novel method for unsupervised segmentation of pathology images. Staging of lung cancer is a major factor of prognosis. Measuring the maximum dimensions of the invasive component in a pathology images is an essential task. Therefore, image segmentation methods for visualizing the extent of invasive and noninvasive components on pathology images could support pathological examination. However, it is challenging for most of the recent segmentation methods that rely on supervised learning to cope with unlabeled pathology images. In this paper, we propose a unified approach to unsupervised representation learning and clustering for pathology image segmentation. Our method consists of two phases. In the first phase, we learn feature representations of training patches from a target image using the spherical k-means. The purpose of this phase is to obtain cluster centroids which could be used as filters for feature extraction. In the second phase, we apply conventional k-means to the representations extracted by the centroids and then project cluster labels to the target images. We evaluated our methods on pathology images of lung cancer specimen. Our experiments showed that the proposed method outperforms traditional k-means segmentation and the multithreshold Otsu method both quantitatively and qualitatively with an improved normalized mutual information (NMI) score of 0.626 compared to 0.168 and 0.167, respectively. Furthermore, we found that the centroids can be applied to the segmentation of other slices from the same sample.
* This paper was presented at SPIE Medical Imaging 2018, Houston, TX, USA
A needle-based deep-neural-network camera
Nov 14, 2020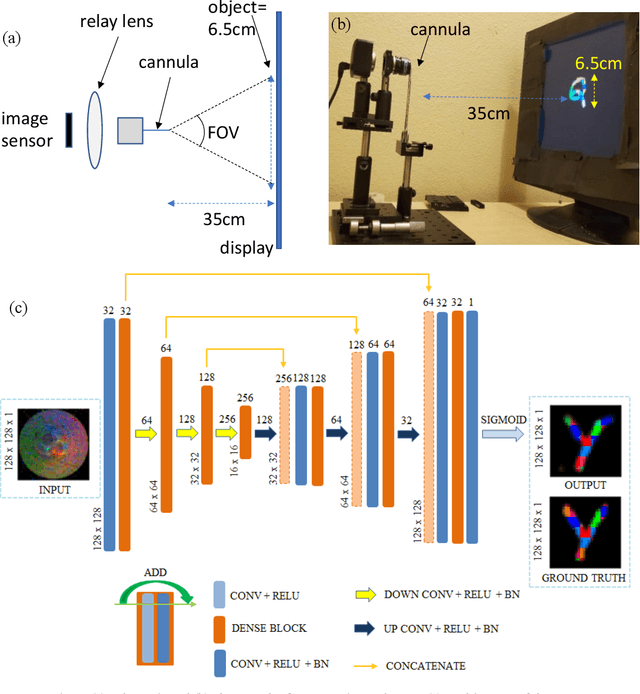

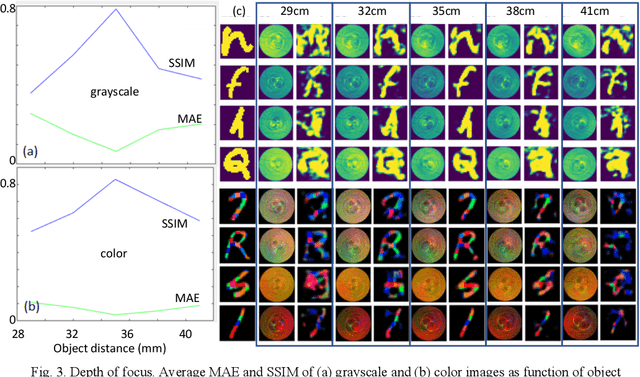
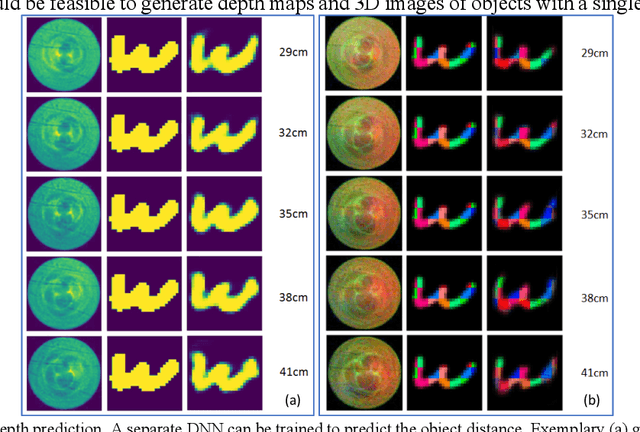
We experimentally demonstrate a camera whose primary optic is a cannula (diameter=0.22mm and length=12.5mm) that acts a lightpipe transporting light intensity from an object plane (35cm away) to its opposite end. Deep neural networks (DNNs) are used to reconstruct color and grayscale images with field of view of 180 and angular resolution of ~0.40. When trained on images with depth information, the DNN can create depth maps. Finally, we show DNN-based classification of the EMNIST dataset without and with image reconstructions. The former could be useful for imaging with enhanced privacy.
Explaining Neural Scaling Laws
Feb 12, 2021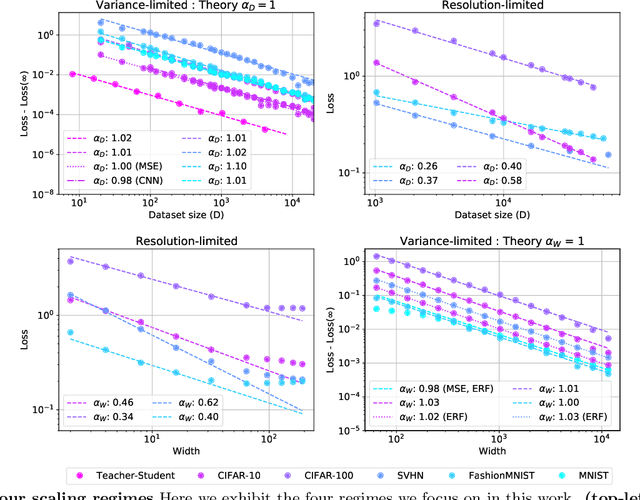
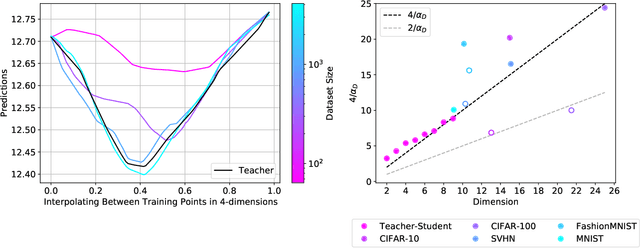
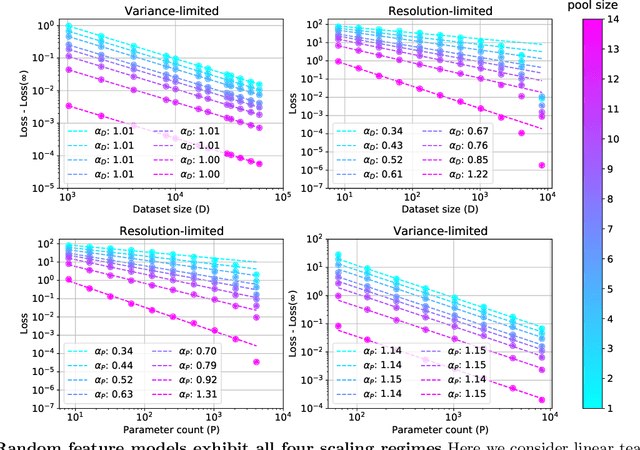
The test loss of well-trained neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents: super-classing image tasks does not change exponents, while changing input distribution (via changing datasets or adding noise) has a strong effect. We further explore the effect of architecture aspect ratio on scaling exponents.
DPDnet: A Robust People Detector using Deep Learning with an Overhead Depth Camera
Jun 01, 2020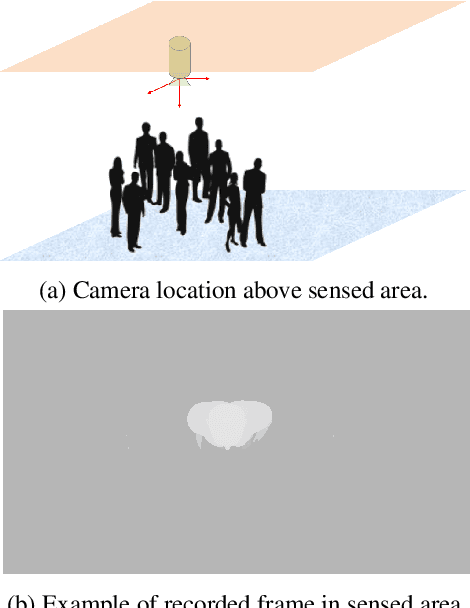
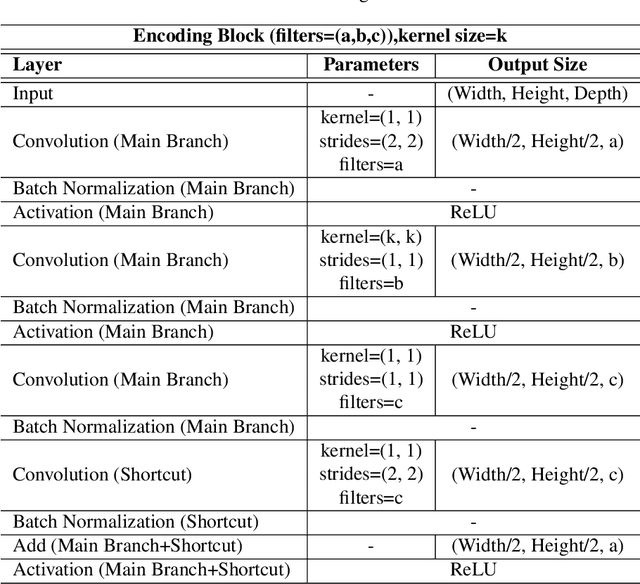
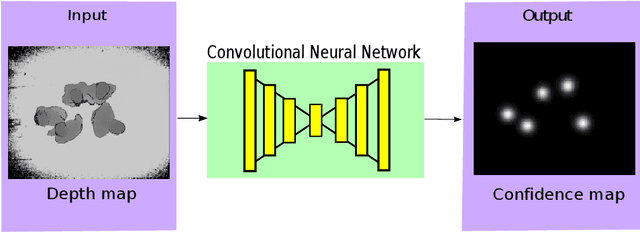
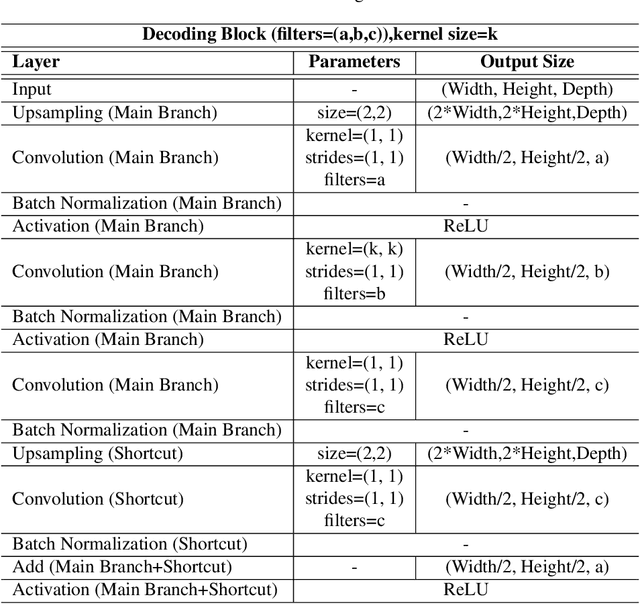
In this paper we propose a method based on deep learning that detects multiple people from a single overhead depth image with high reliability. Our neural network, called DPDnet, is based on two fully-convolutional encoder-decoder neural blocks based on residual layers. The Main Block takes a depth image as input and generates a pixel-wise confidence map, where each detected person in the image is represented by a Gaussian-like distribution. The refinement block combines the depth image and the output from the main block, to refine the confidence map. Both blocks are simultaneously trained end-to-end using depth images and head position labels. The experimental work shows that DPDNet outperforms state-of-the-art methods, with accuracies greater than 99% in three different publicly available datasets, without retraining not fine-tuning. In addition, the computational complexity of our proposal is independent of the number of people in the scene and runs in real time using conventional GPUs.
Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning
Feb 12, 2021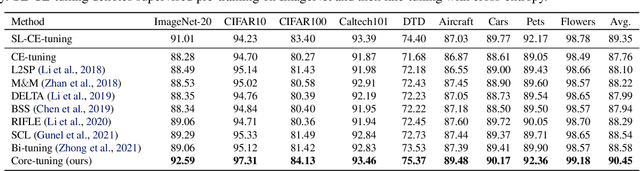
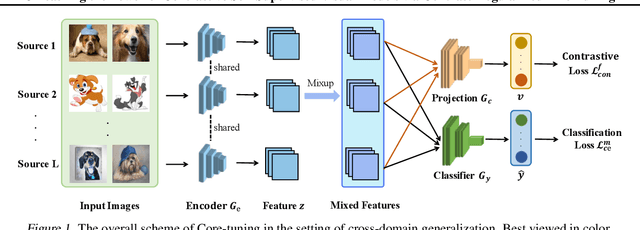
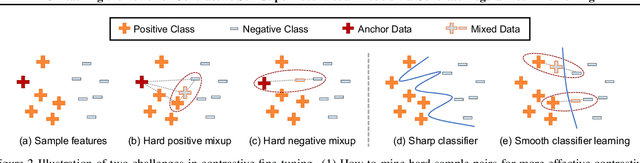

Contrastive self-supervised learning (CSL) leverages unlabeled data to train models that provide instance-discriminative visual representations uniformly scattered in the feature space. In deployment, the common practice is to directly fine-tune models with the cross-entropy loss, which however may not be an optimal strategy. Although cross-entropy tends to separate inter-class features, the resulted models still have limited capability of reducing intra-class feature scattering that inherits from pre-training, and thus may suffer unsatisfactory performance on downstream tasks. In this paper, we investigate whether applying contrastive learning to fine-tuning would bring further benefits, and analytically find that optimizing the supervised contrastive loss benefits both class-discriminative representation learning and model optimization during fine-tuning. Inspired by these findings, we propose Contrast-regularized tuning (Core-tuning), a novel approach for fine-tuning contrastive self-supervised visual models. Instead of simply adding the contrastive loss to the objective of fine-tuning, Core-tuning also generates hard sample pairs for more effective contrastive learning through a novel feature mixup strategy, as well as improves the generalizability of the model by smoothing the decision boundary via mixed samples. Extensive experiments on image classification and semantic segmentation verify the effectiveness of Core-tuning.
Target Oriented High Resolution SAR Image Formation via Semantic Information Guided Regularizations
Apr 24, 2017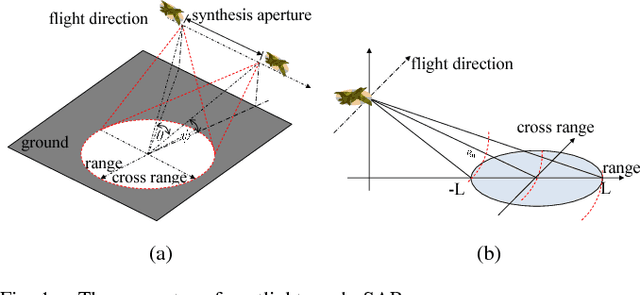



Sparsity-regularized synthetic aperture radar (SAR) imaging framework has shown its remarkable performance to generate a feature enhanced high resolution image, in which a sparsity-inducing regularizer is involved by exploiting the sparsity priors of some visual features in the underlying image. However, since the simple prior of low level features are insufficient to describe different semantic contents in the image, this type of regularizer will be incapable of distinguishing between the target of interest and unconcerned background clutters. As a consequence, the features belonging to the target and clutters are simultaneously affected in the generated image without concerning their underlying semantic labels. To address this problem, we propose a novel semantic information guided framework for target oriented SAR image formation, which aims at enhancing the interested target scatters while suppressing the background clutters. Firstly, we develop a new semantics-specific regularizer for image formation by exploiting the statistical properties of different semantic categories in a target scene SAR image. In order to infer the semantic label for each pixel in an unsupervised way, we moreover induce a novel high-level prior-driven regularizer and some semantic causal rules from the prior knowledge. Finally, our regularized framework for image formation is further derived as a simple iteratively reweighted $\ell_1$ minimization problem which can be conveniently solved by many off-the-shelf solvers. Experimental results demonstrate the effectiveness and superiority of our framework for SAR image formation in terms of target enhancement and clutters suppression, compared with the state of the arts. Additionally, the proposed framework opens a new direction of devoting some machine learning strategies to image formation, which can benefit the subsequent decision making tasks.