 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Evolutionary Based Method For Image Segmentation
Dec 06, 2017
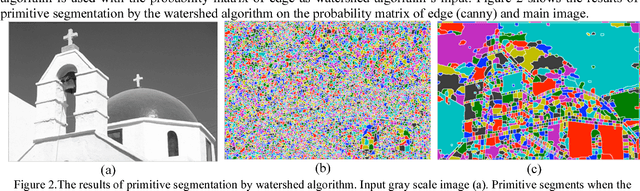
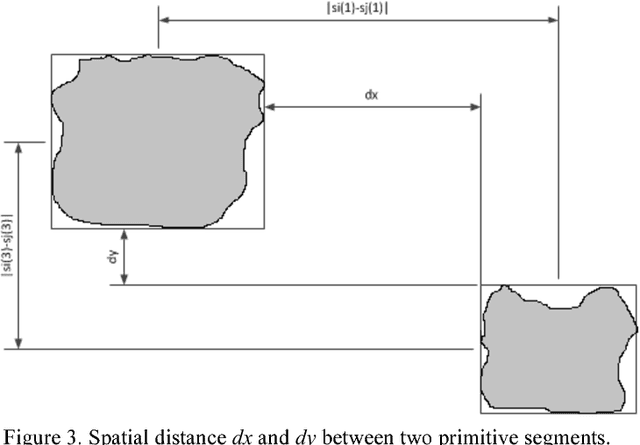
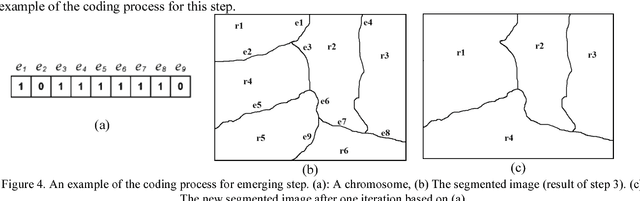
The goal of this paper is to present a new efficient image segmentation method based on evolutionary computation which is a model inspired from human behavior. Based on this model, a four layer process for image segmentation is proposed using the split/merge approach. In the first layer, an image is split into numerous regions using the watershed algorithm. In the second layer, a co-evolutionary process is applied to form centers of finals segments by merging similar primary regions. In the third layer, a meta-heuristic process uses two operators to connect the residual regions to their corresponding determined centers. In the final layer, an evolutionary algorithm is used to combine the resulted similar and neighbor regions. Different layers of the algorithm are totally independent, therefore for certain applications a specific layer can be changed without constraint of changing other layers. Some properties of this algorithm like the flexibility of its method, the ability to use different feature vectors for segmentation (grayscale, color, texture, etc), the ability to control uniformity and the number of final segments using free parameters and also maintaining small regions, makes it possible to apply the algorithm to different applications. Moreover, the independence of each region from other regions in the second layer, and the independence of centers in the third layer, makes parallel implementation possible. As a result the algorithm speed will increase. The presented algorithm was tested on a standard dataset (BSDS 300) of images, and the region boundaries were compared with different people segmentation contours. Results show the efficiency of the algorithm and its improvement to similar methods. As an instance, in 70% of tested images, results are better than ACT algorithm, besides in 100% of tested images, we had better results in comparison with VSP algorithm.
Real time text localization for Indoor Mobile Robot Navigation
Sep 22, 2017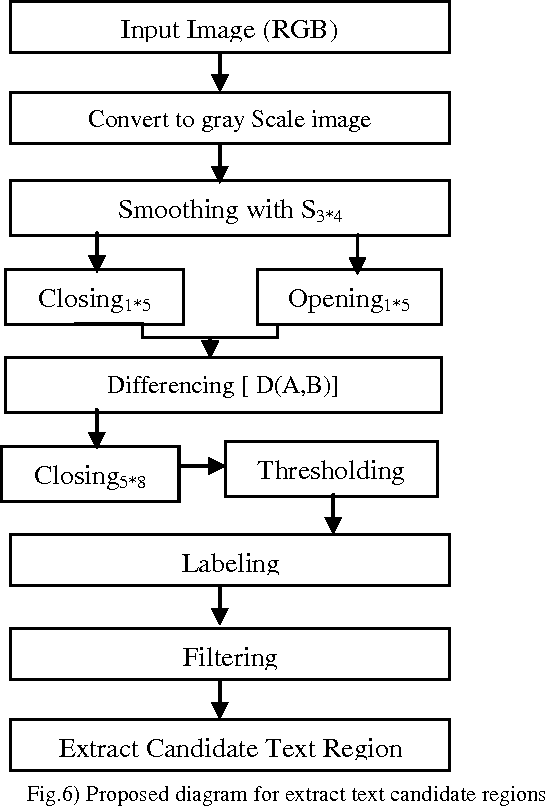
Scene text is an important feature to be extracted, especially in vision-based mobile robot navigation as many potential landmarks such as nameplates and information signs contain text. In this paper, a novel two-step text localization method for Indoor Mobile Robot Navigation is introduced. This method is based on morphological operators and machine learning techniques and can be used in real time environments. The proposed method has two steps. At First, a new set of morphological operators is applied with a particular sequence to extract high contrast areas that have high probability of text existence. Using of morphological operators has many advantages such as: high computation speed, being invariant to several geometrical transformations like translation, rotations, and scaling, and being able to extract all areas containing text. After extracting text candidate regions, a set of nine features are extracted for accurate detection and deletion of the regions that don't have text. These features are descriptors for texture properties and are computed in real time. Then, we use a SVM classifier to detect the existence of text in the region. Performance of the proposed algorithm is compared against a number of widely used text localization algorithms and the results show that this method can quickly and effectively localize and extract text regions from real scenes and can be used in mobile robot navigation under an indoor environment to detect text based landmarks.
* 5 pages