 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reproducing Activation Function for Deep Learning
Jan 13, 2021
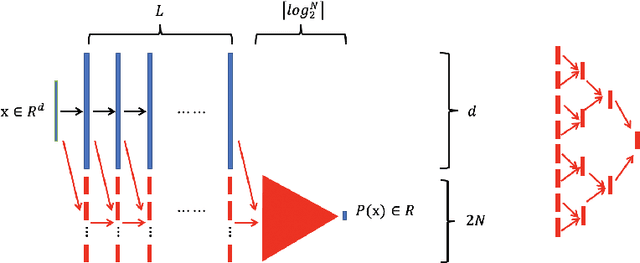
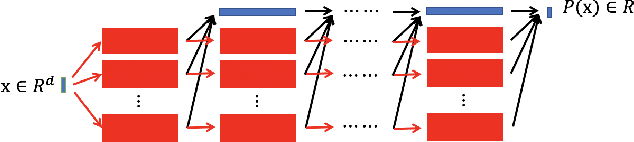

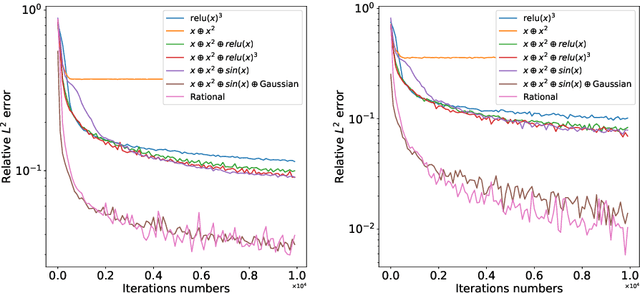
In this paper, we propose the reproducing activation function to improve deep learning accuracy for various applications ranging from computer vision problems to scientific computing problems. The idea of reproducing activation functions is to employ several basic functions and their learnable linear combination to construct neuron-wise data-driven activation functions for each neuron. Armed with such activation functions, deep neural networks can reproduce traditional approximation tools and, therefore, approximate target functions with a smaller number of parameters than traditional neural networks. In terms of training dynamics of deep learning, reproducing activation functions can generate neural tangent kernels with a better condition number than traditional activation functions lessening the spectral bias of deep learning. As demonstrated by extensive numerical tests, the proposed activation function can facilitate the convergence of deep learning optimization for a solution with higher accuracy than existing deep learning solvers for audio/image/video reconstruction, PDEs, and eigenvalue problems.
Investigating Emotion-Color Association in Deep Neural Networks
Nov 22, 2020
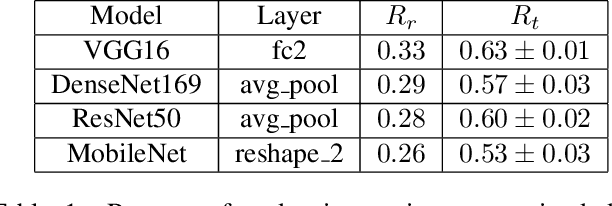
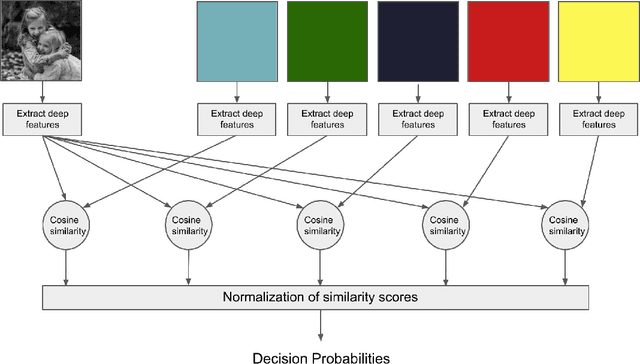
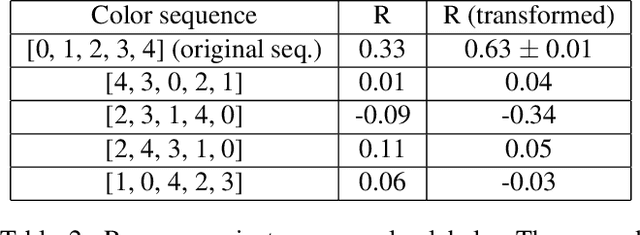
It has been found that representations learned by Deep Neural Networks (DNNs) correlate very well to neural responses measured in primates' brains and psychological representations exhibited by human similarity judgment. On another hand, past studies have shown that particular colors can be associated with specific emotion arousal in humans. Do deep neural networks also learn this behavior? In this study, we investigate if DNNs can learn implicit associations in stimuli, particularly, an emotion-color association between image stimuli. Our study was conducted in two parts. First, we collected human responses on a forced-choice decision task in which subjects were asked to select a color for a specified emotion-inducing image. Next, we modeled this decision task on neural networks using the similarity between deep representation (extracted using DNNs trained on object classification tasks) of the images and images of colors used in the task. We found that our model showed a fuzzy linear relationship between the two decision probabilities. This results in two interesting findings, 1. The representations learned by deep neural networks can indeed show an emotion-color association 2. The emotion-color association is not just random but involves some cognitive phenomena. Finally, we also show that this method can help us in the emotion classification task, specifically when there are very few examples to train the model. This analysis can be relevant to psychologists studying emotion-color associations and artificial intelligence researchers modeling emotional intelligence in machines or studying representations learned by deep neural networks.
Contraction Mapping of Feature Norms for Classifier Learning on the Data with Different Quality
Jul 27, 2020
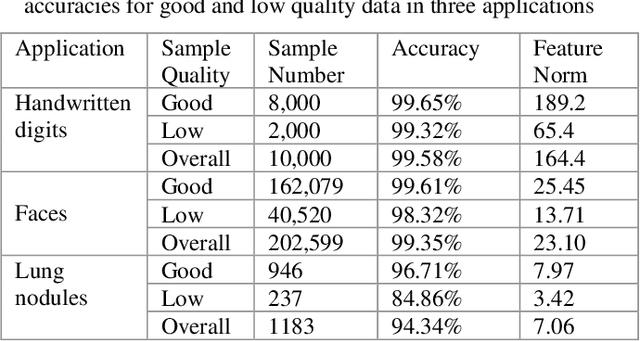
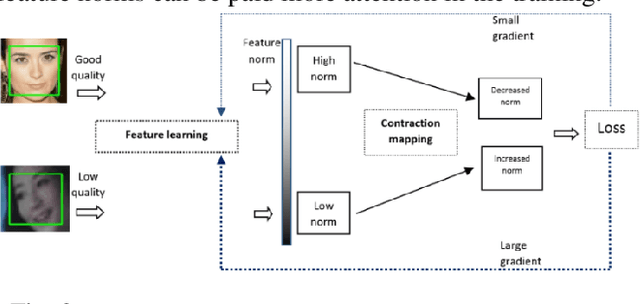
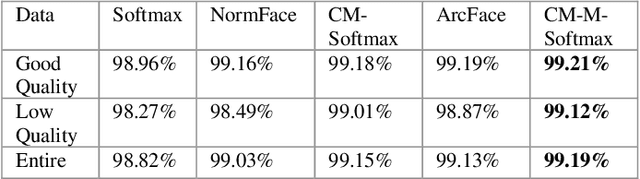
The popular softmax loss and its recent extensions have achieved great success in the deep learning-based image clas-sification. However, the data for training image classifiers usually has different quality. Ignoring such problem, the cor-rect classification of low quality data is hard to be solved. In this paper, we discover the positive correlation between the feature norm of an image and its quality through careful ex-periments on various applications and various deep neural networks. Based on this finding, we propose a contraction mapping function to compress the range of feature norms of training images according to their quality and embed this con-traction mapping function into softmax loss or its extensions to produce novel learning objectives. The experiments on var-ious classification applications, including handwritten digit recognition, lung nodule classification, face verification and face recognition, demonstrate that the proposed approach is promising to effectively deal with the problem of learning on the data with different quality and leads to the significant and stable improvements in the classification accuracy.
Reducing false-positive biopsies with deep neural networks that utilize local and global information in screening mammograms
Sep 19, 2020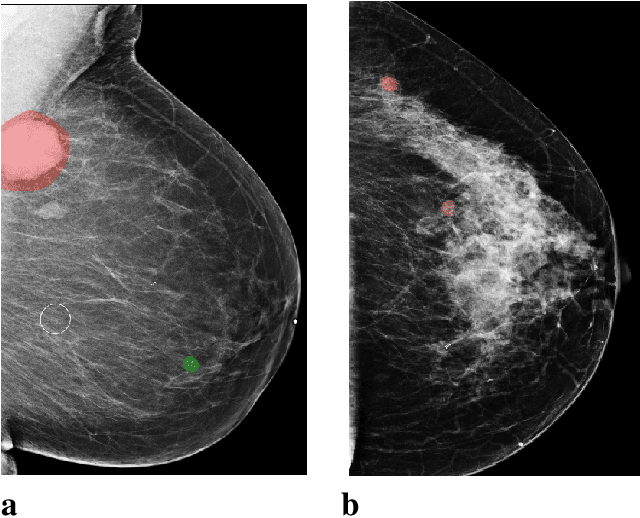
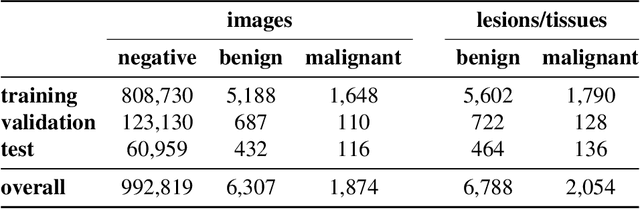
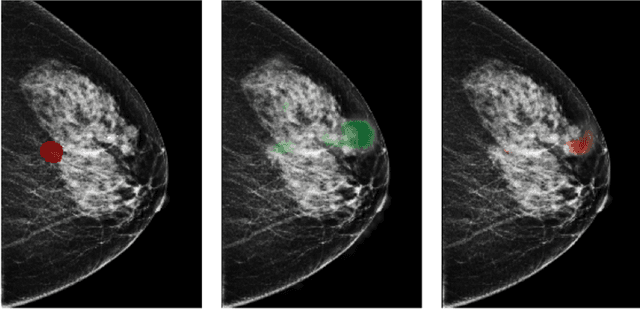
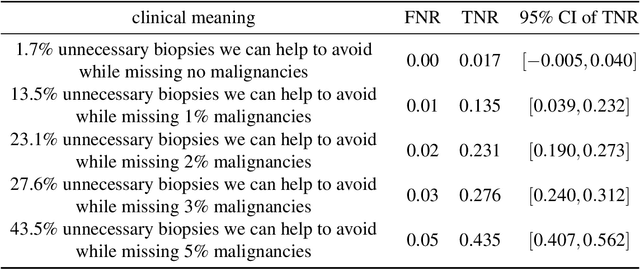
Breast cancer is the most common cancer in women, and hundreds of thousands of unnecessary biopsies are done around the world at a tremendous cost. It is crucial to reduce the rate of biopsies that turn out to be benign tissue. In this study, we build deep neural networks (DNNs) to classify biopsied lesions as being either malignant or benign, with the goal of using these networks as second readers serving radiologists to further reduce the number of false positive findings. We enhance the performance of DNNs that are trained to learn from small image patches by integrating global context provided in the form of saliency maps learned from the entire image into their reasoning, similar to how radiologists consider global context when evaluating areas of interest. Our experiments are conducted on a dataset of 229,426 screening mammography exams from 141,473 patients. We achieve an AUC of 0.8 on a test set consisting of 464 benign and 136 malignant lesions.
Self-Supervised Learning for Monocular Depth Estimation from Aerial Imagery
Aug 17, 2020
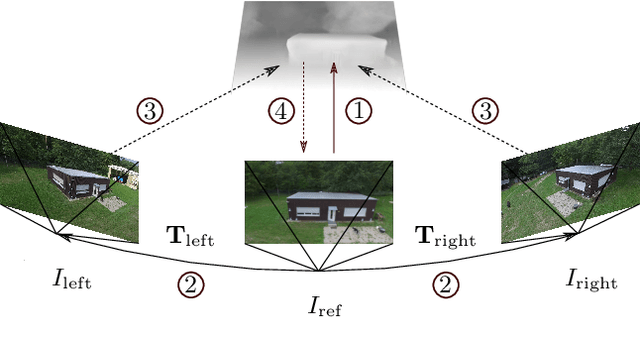
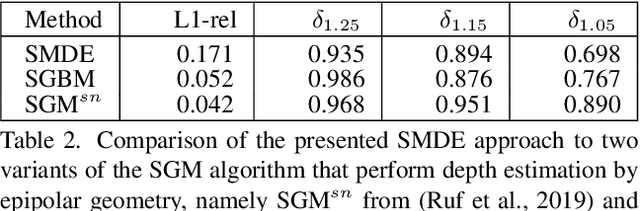
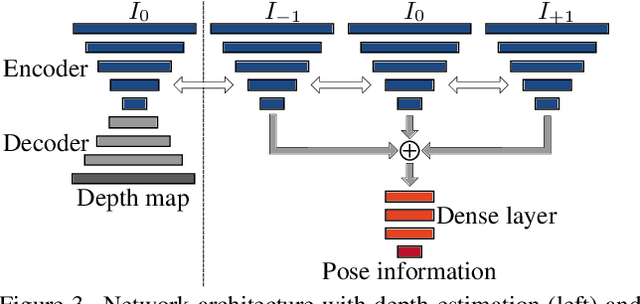
Supervised learning based methods for monocular depth estimation usually require large amounts of extensively annotated training data. In the case of aerial imagery, this ground truth is particularly difficult to acquire. Therefore, in this paper, we present a method for self-supervised learning for monocular depth estimation from aerial imagery that does not require annotated training data. For this, we only use an image sequence from a single moving camera and learn to simultaneously estimate depth and pose information. By sharing the weights between pose and depth estimation, we achieve a relatively small model, which favors real-time application. We evaluate our approach on three diverse datasets and compare the results to conventional methods that estimate depth maps based on multi-view geometry. We achieve an accuracy {\delta}1.25 of up to 93.5 %. In addition, we have paid particular attention to the generalization of a trained model to unknown data and the self-improving capabilities of our approach. We conclude that, even though the results of monocular depth estimation are inferior to those achieved by conventional methods, they are well suited to provide a good initialization for methods that rely on image matching or to provide estimates in regions where image matching fails, e.g. occluded or texture-less regions.
Superpixel-based Refinement for Object Proposal Generation
Jan 12, 2021
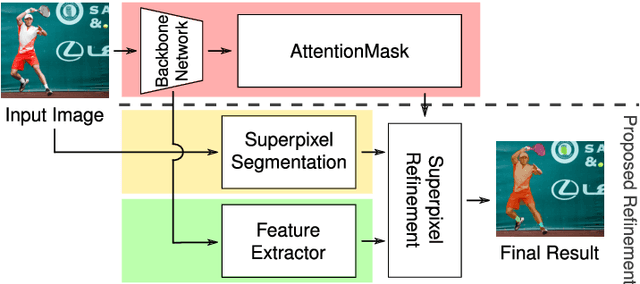
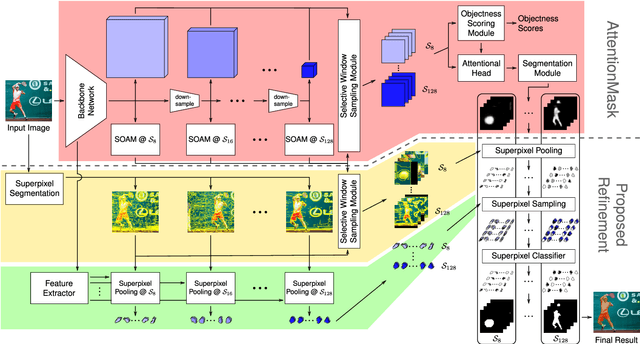

Precise segmentation of objects is an important problem in tasks like class-agnostic object proposal generation or instance segmentation. Deep learning-based systems usually generate segmentations of objects based on coarse feature maps, due to the inherent downsampling in CNNs. This leads to segmentation boundaries not adhering well to the object boundaries in the image. To tackle this problem, we introduce a new superpixel-based refinement approach on top of the state-of-the-art object proposal system AttentionMask. The refinement utilizes superpixel pooling for feature extraction and a novel superpixel classifier to determine if a high precision superpixel belongs to an object or not. Our experiments show an improvement of up to 26.0% in terms of average recall compared to original AttentionMask. Furthermore, qualitative and quantitative analyses of the segmentations reveal significant improvements in terms of boundary adherence for the proposed refinement compared to various deep learning-based state-of-the-art object proposal generation systems.
Super-Resolving Cross-Domain Face Miniatures by Peeking at One-Shot Exemplar
Mar 16, 2021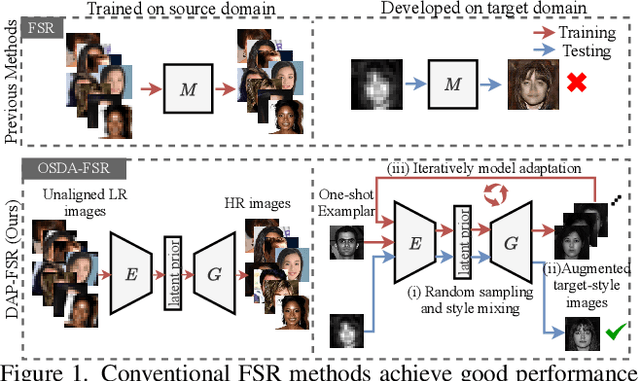
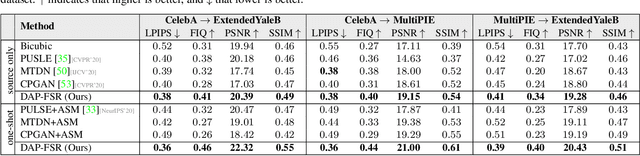
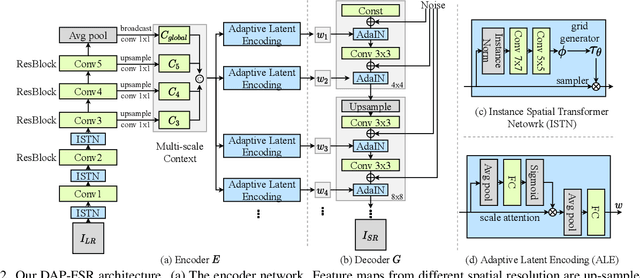
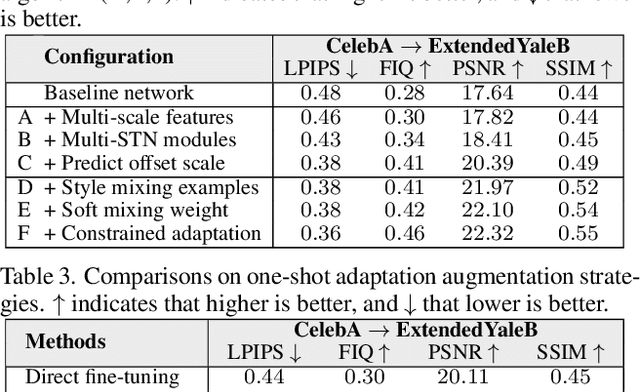
Conventional face super-resolution methods usually assume testing low-resolution (LR) images lie in the same domain as the training ones. Due to different lighting conditions and imaging hardware, domain gaps between training and testing images inevitably occur in many real-world scenarios. Neglecting those domain gaps would lead to inferior face super-resolution (FSR) performance. However, how to transfer a trained FSR model to a target domain efficiently and effectively has not been investigated. To tackle this problem, we develop a Domain-Aware Pyramid-based Face Super-Resolution network, named DAP-FSR network. Our DAP-FSR is the first attempt to super-resolve LR faces from a target domain by exploiting only a pair of high-resolution (HR) and LR exemplar in the target domain. To be specific, our DAP-FSR firstly employs its encoder to extract the multi-scale latent representations of the input LR face. Considering only one target domain example is available, we propose to augment the target domain data by mixing the latent representations of the target domain face and source domain ones, and then feed the mixed representations to the decoder of our DAP-FSR. The decoder will generate new face images resembling the target domain image style. The generated HR faces in turn are used to optimize our decoder to reduce the domain gap. By iteratively updating the latent representations and our decoder, our DAP-FSR will be adapted to the target domain, thus achieving authentic and high-quality upsampled HR faces. Extensive experiments on three newly constructed benchmarks validate the effectiveness and superior performance of our DAP-FSR compared to the state-of-the-art.
An Efficient Evolutionary Based Method For Image Segmentation
Dec 06, 2017
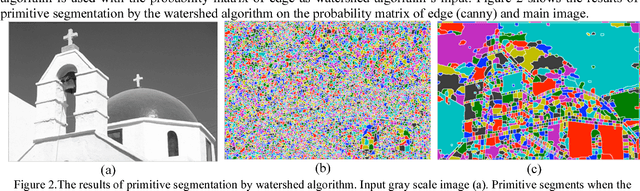
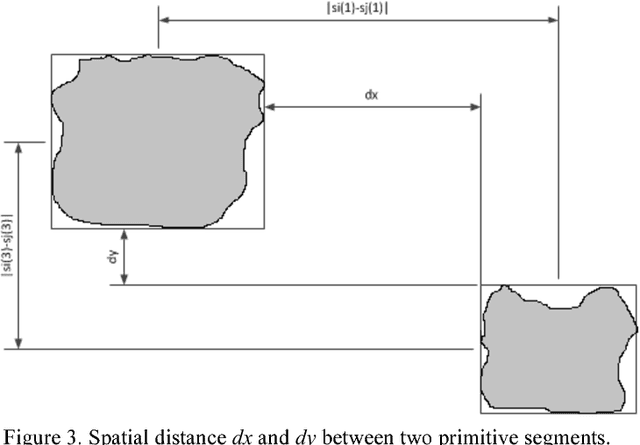
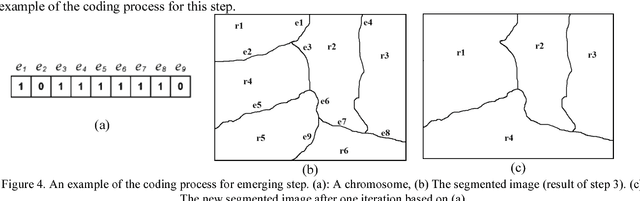
The goal of this paper is to present a new efficient image segmentation method based on evolutionary computation which is a model inspired from human behavior. Based on this model, a four layer process for image segmentation is proposed using the split/merge approach. In the first layer, an image is split into numerous regions using the watershed algorithm. In the second layer, a co-evolutionary process is applied to form centers of finals segments by merging similar primary regions. In the third layer, a meta-heuristic process uses two operators to connect the residual regions to their corresponding determined centers. In the final layer, an evolutionary algorithm is used to combine the resulted similar and neighbor regions. Different layers of the algorithm are totally independent, therefore for certain applications a specific layer can be changed without constraint of changing other layers. Some properties of this algorithm like the flexibility of its method, the ability to use different feature vectors for segmentation (grayscale, color, texture, etc), the ability to control uniformity and the number of final segments using free parameters and also maintaining small regions, makes it possible to apply the algorithm to different applications. Moreover, the independence of each region from other regions in the second layer, and the independence of centers in the third layer, makes parallel implementation possible. As a result the algorithm speed will increase. The presented algorithm was tested on a standard dataset (BSDS 300) of images, and the region boundaries were compared with different people segmentation contours. Results show the efficiency of the algorithm and its improvement to similar methods. As an instance, in 70% of tested images, results are better than ACT algorithm, besides in 100% of tested images, we had better results in comparison with VSP algorithm.
Demystifying Inductive Biases for $β$-VAE Based Architectures
Feb 12, 2021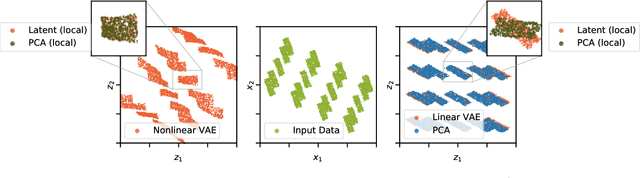
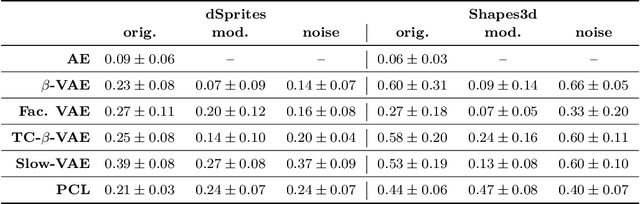
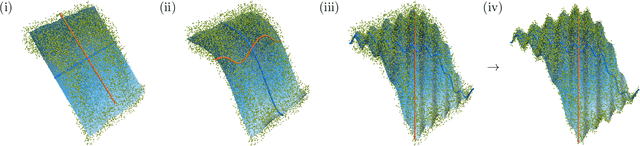

The performance of $\beta$-Variational-Autoencoders ($\beta$-VAEs) and their variants on learning semantically meaningful, disentangled representations is unparalleled. On the other hand, there are theoretical arguments suggesting the impossibility of unsupervised disentanglement. In this work, we shed light on the inductive bias responsible for the success of VAE-based architectures. We show that in classical datasets the structure of variance, induced by the generating factors, is conveniently aligned with the latent directions fostered by the VAE objective. This builds the pivotal bias on which the disentangling abilities of VAEs rely. By small, elaborate perturbations of existing datasets, we hide the convenient correlation structure that is easily exploited by a variety of architectures. To demonstrate this, we construct modified versions of standard datasets in which (i) the generative factors are perfectly preserved; (ii) each image undergoes a mild transformation causing a small change of variance; (iii) the leading \textbf{VAE-based disentanglement architectures fail to produce disentangled representations whilst the performance of a non-variational method remains unchanged}. The construction of our modifications is nontrivial and relies on recent progress on mechanistic understanding of $\beta$-VAEs and their connection to PCA. We strengthen that connection by providing additional insights that are of stand-alone interest.
Improving Road Signs Detection performance by Combining the Features of Hough Transform and Texture
Oct 13, 2020With the large uses of the intelligent systems in different domains, and in order to increase the drivers and pedestrians safety, the road and traffic sign recognition system has been a challenging issue and an important task for many years. But studies, done in this field of detection and recognition of traffic signs in an image, which are interested in the Arab context, are still insufficient. Detection of the road signs present in the scene is the one of the main stages of the traffic sign detection and recognition. In this paper, an efficient solution to enhance road signs detection, including Arabic context, performance based on color segmentation, Randomized Hough Transform and the combination of Zernike moments and Haralick features has been made. Segmentation stage is useful to determine the Region of Interest (ROI) in the image. The Randomized Hough Transform (RHT) is used to detect the circular and octagonal shapes. This stage is improved by the extraction of the Haralick features and Zernike moments. Furthermore, we use it as input of a classifier based on SVM. Experimental results show that the proposed approach allows us to perform the measurements precision.