 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data-Efficient Image Recognition with Contrastive Predictive Coding
May 22, 2019
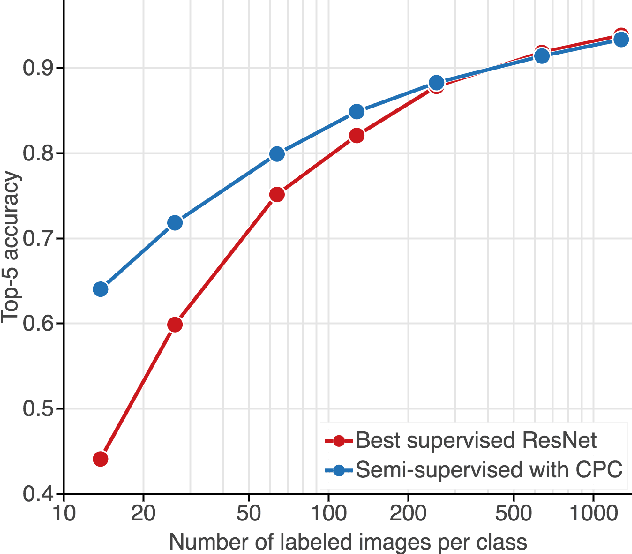
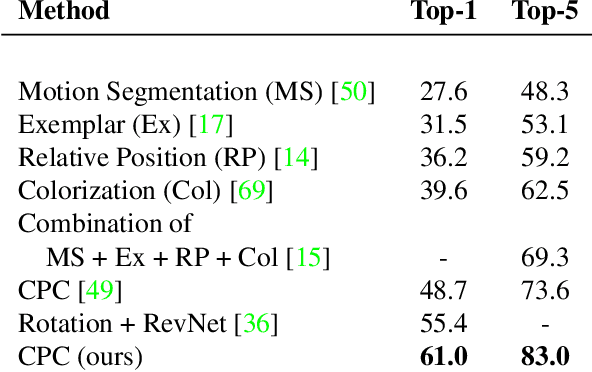
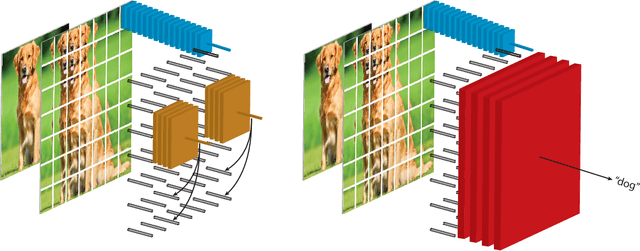
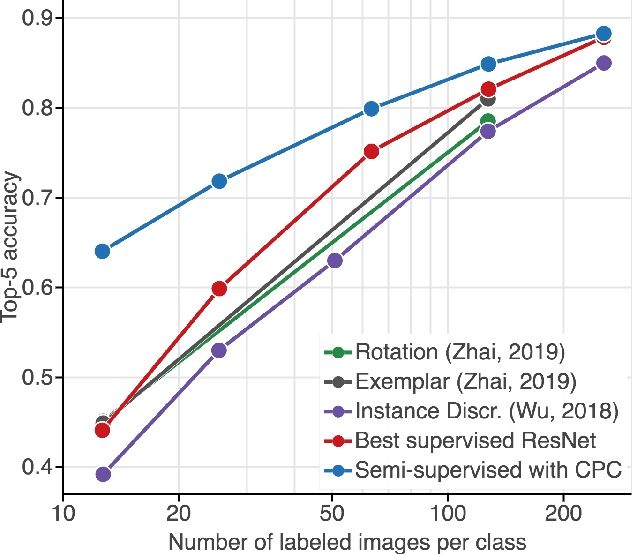
Large scale deep learning excels when labeled images are abundant, yet data-efficient learning remains a longstanding challenge. While biological vision is thought to leverage vast amounts of unlabeled data to solve classification problems with limited supervision, computer vision has so far not succeeded in this `semi-supervised' regime. Our work tackles this challenge with Contrastive Predictive Coding, an unsupervised objective which extracts stable structure from still images. The result is a representation which, equipped with a simple linear classifier, separates ImageNet categories better than all competing methods, and surpasses the performance of a fully-supervised AlexNet model. When given a small number of labeled images (as few as 13 per class), this representation retains a strong classification performance, outperforming state-of-the-art semi-supervised methods by 10% Top-5 accuracy and supervised methods by 20%. Finally, we find our unsupervised representation to serve as a useful substrate for image detection on the PASCAL-VOC 2007 dataset, approaching the performance of representations trained with a fully annotated ImageNet dataset. We expect these results to open the door to pipelines that use scalable unsupervised representations as a drop-in replacement for supervised ones for real-world vision tasks where labels are scarce.
Energy-Efficient AI over a Virtualized Cloud Fog Network
May 07, 2021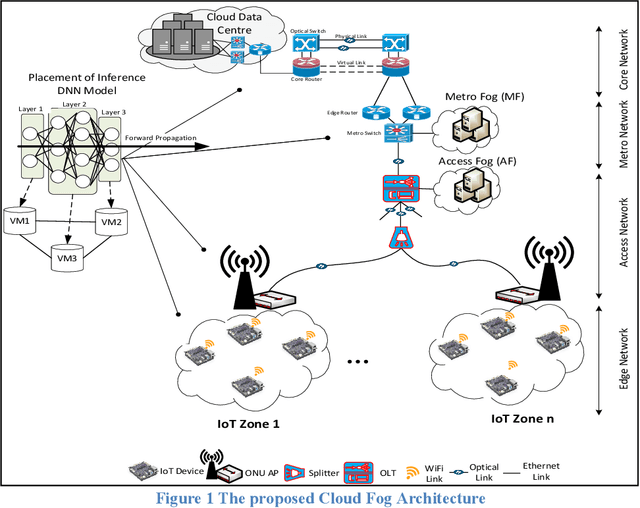
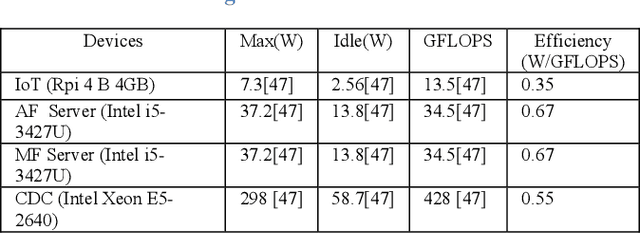
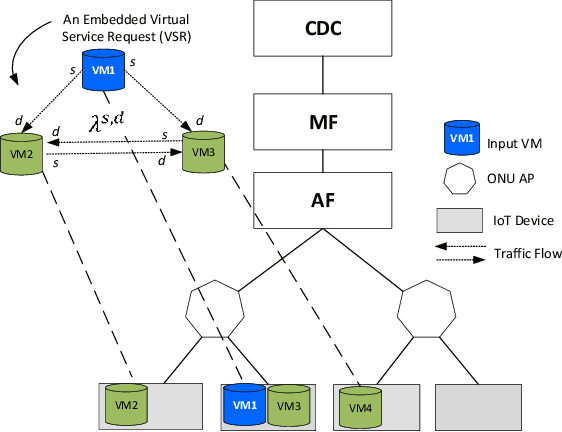
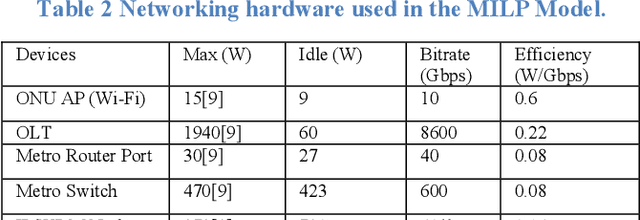
Deep Neural Networks (DNNs) have served as a catalyst in introducing a plethora of next-generation services in the era of Internet of Things (IoT), thanks to the availability of massive amounts of data collected by the objects on the edge. Currently, DNN models are used to deliver many Artificial Intelligence (AI) services that include image and natural language processing, speech recognition, and robotics. Accordingly, such services utilize various DNN models that make it computationally intensive for deployment on the edge devices alone. Thus, most AI models are offloaded to distant cloud data centers (CDCs), which tend to consolidate large amounts of computing and storage resources into one or more CDCs. Deploying services in the CDC will inevitably lead to excessive latencies and overall increase in power consumption. Instead, fog computing allows for cloud services to be extended to the edge of the network, which allows for data processing to be performed closer to the end-user device. However, different from cloud data centers, fog nodes have limited computational power and are highly distributed in the network. In this paper, using Mixed Integer Linear Programming (MILP), we formulate the placement of DNN inference models, which is abstracted as a network embedding problem in a Cloud Fog Network (CFN) architecture, where power savings are introduced through trade-offs between processing and networking. We study the performance of the CFN architecture by comparing the energy savings when compared to the baseline approach which is the CDC.
Image as Data: Automated Visual Content Analysis for Political Science
Oct 03, 2018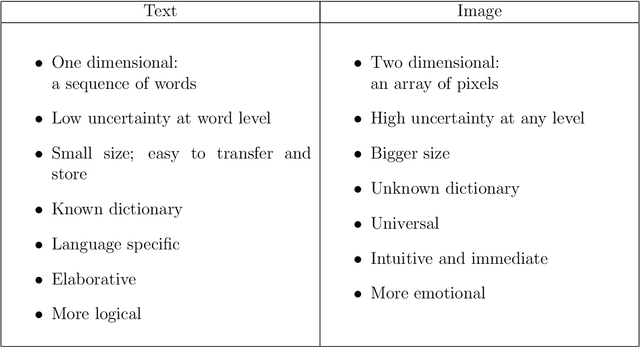
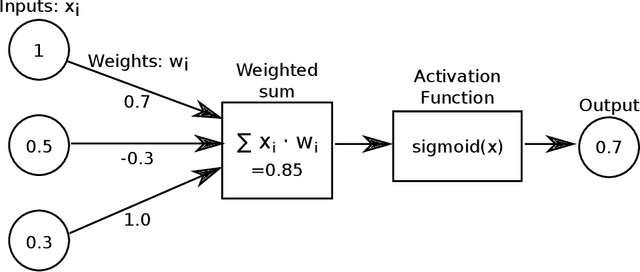
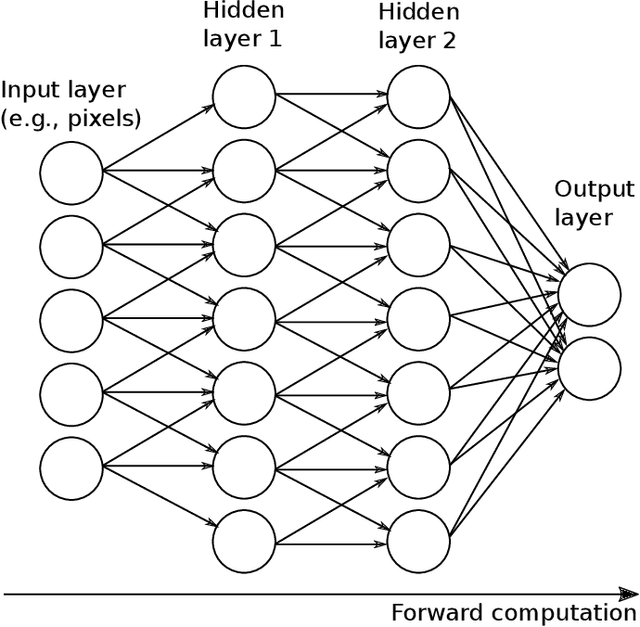

Image data provide unique information about political events, actors, and their interactions which are difficult to measure from or not available in text data. This article introduces a new class of automated methods based on computer vision and deep learning which can automatically analyze visual content data. Scholars have already recognized the importance of visual data and a variety of large visual datasets have become available. The lack of scalable analytic methods, however, has prevented from incorporating large scale image data in political analysis. This article aims to offer an in-depth overview of automated methods for visual content analysis and explains their usages and implementations. We further elaborate on how these methods and results can be validated and interpreted. We then discuss how these methods can contribute to the study of political communication, identity and politics, development, and conflict, by enabling a new set of research questions at scale.
Residual-Guide Feature Fusion Network for Single Image Deraining
Apr 20, 2018

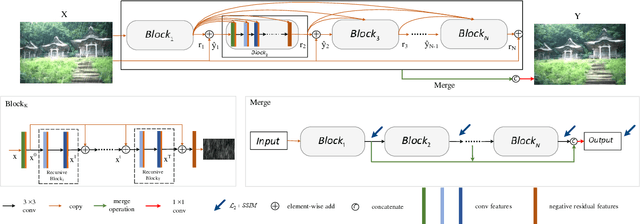

Single image rain streaks removal is extremely important since rainy images adversely affect many computer vision systems. Deep learning based methods have found great success in image deraining tasks. In this paper, we propose a novel residual-guide feature fusion network, called ResGuideNet, for single image deraining that progressively predicts highquality reconstruction. Specifically, we propose a cascaded network and adopt residuals generated from shallower blocks to guide deeper blocks. By using this strategy, we can obtain a coarse to fine estimation of negative residual as the blocks go deeper. The outputs of different blocks are merged into the final reconstruction. We adopt recursive convolution to build each block and apply supervision to all intermediate results, which enable our model to achieve promising performance on synthetic and real-world data while using fewer parameters than previous required. ResGuideNet is detachable to meet different rainy conditions. For images with light rain streaks and limited computational resource at test time, we can obtain a decent performance even with several building blocks. Experiments validate that ResGuideNet can benefit other low- and high-level vision tasks.
Efficient Visual Pretraining with Contrastive Detection
Mar 19, 2021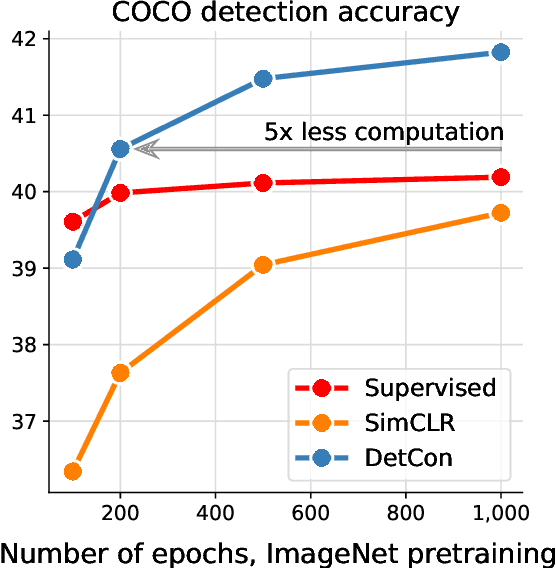
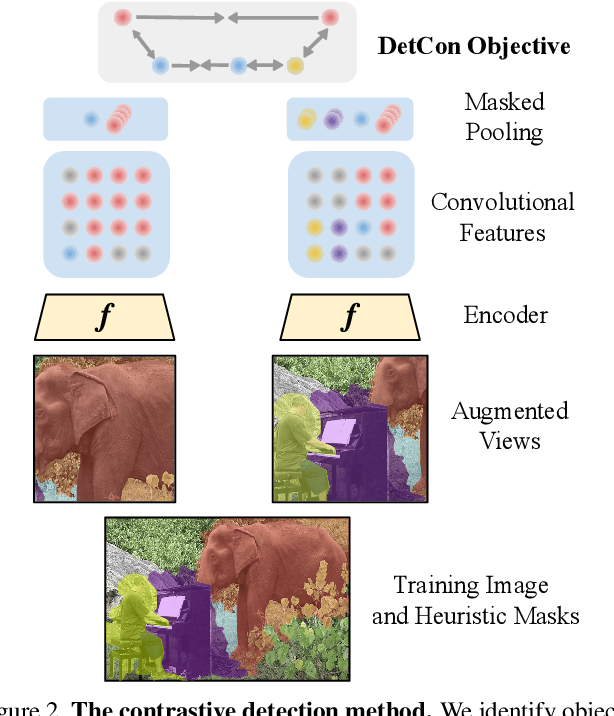
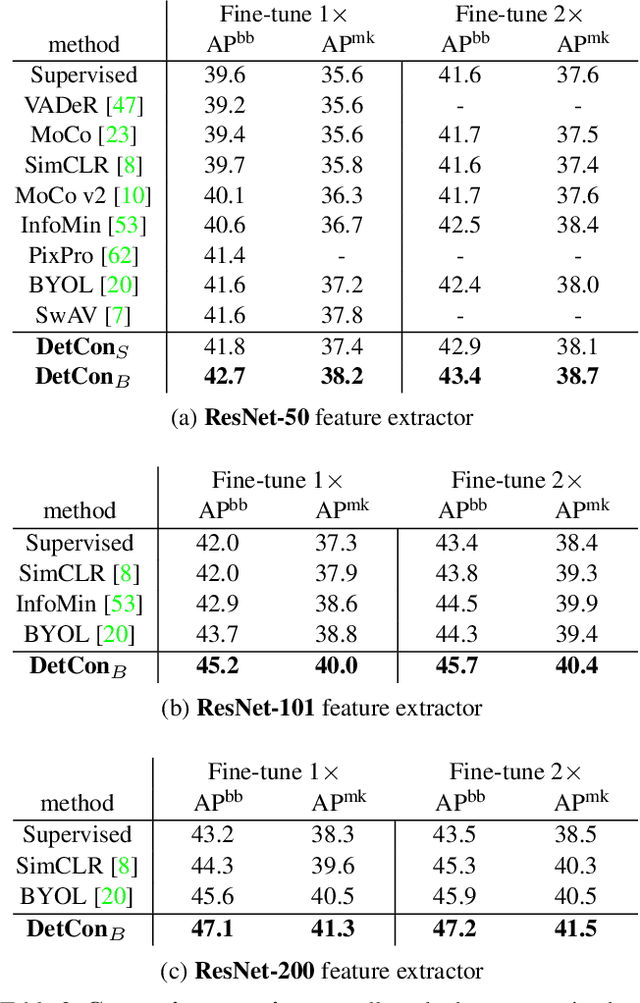

Self-supervised pretraining has been shown to yield powerful representations for transfer learning. These performance gains come at a large computational cost however, with state-of-the-art methods requiring an order of magnitude more computation than supervised pretraining. We tackle this computational bottleneck by introducing a new self-supervised objective, contrastive detection, which tasks representations with identifying object-level features across augmentations. This objective extracts a rich learning signal per image, leading to state-of-the-art transfer performance from ImageNet to COCO, while requiring up to 5x less pretraining. In particular, our strongest ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pretraining data. Finally, our objective seamlessly handles pretraining on more complex images such as those in COCO, closing the gap with supervised transfer learning from COCO to PASCAL.
Deep Retinal Image Understanding
Sep 05, 2016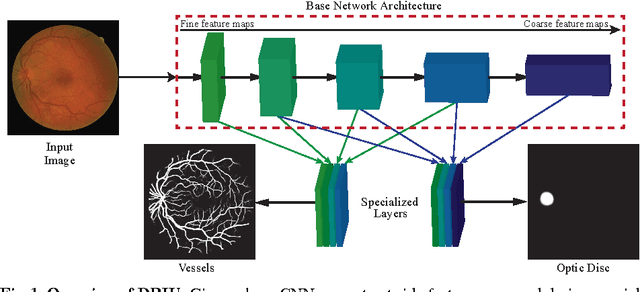
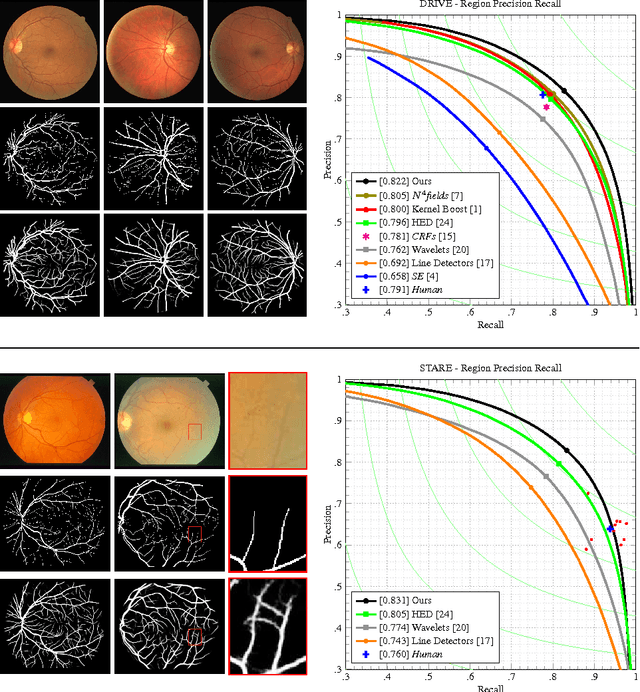
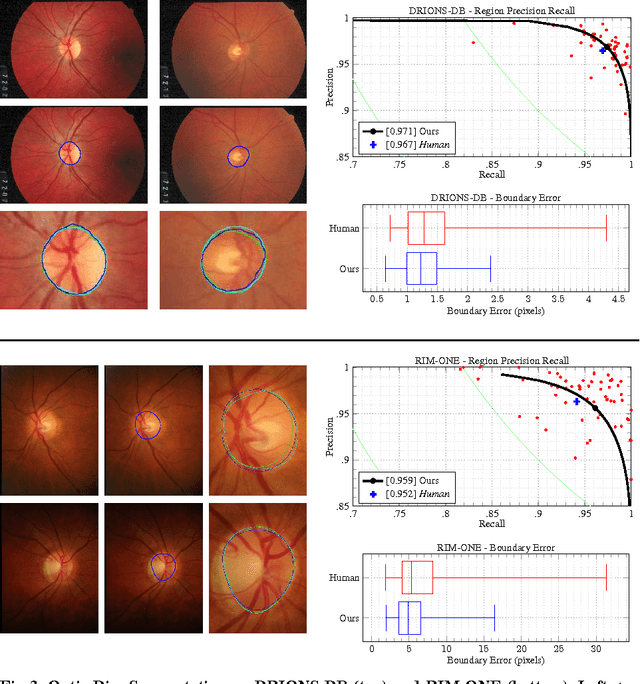
This paper presents Deep Retinal Image Understanding (DRIU), a unified framework of retinal image analysis that provides both retinal vessel and optic disc segmentation. We make use of deep Convolutional Neural Networks (CNNs), which have proven revolutionary in other fields of computer vision such as object detection and image classification, and we bring their power to the study of eye fundus images. DRIU uses a base network architecture on which two set of specialized layers are trained to solve both the retinal vessel and optic disc segmentation. We present experimental validation, both qualitative and quantitative, in four public datasets for these tasks. In all of them, DRIU presents super-human performance, that is, it shows results more consistent with a gold standard than a second human annotator used as control.
Patch Shortcuts: Interpretable Proxy Models Efficiently Find Black-Box Vulnerabilities
Apr 22, 2021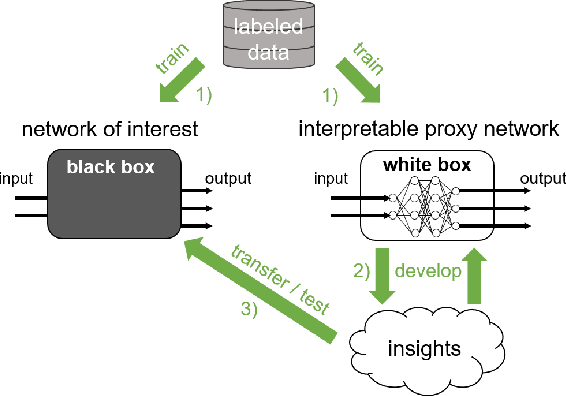
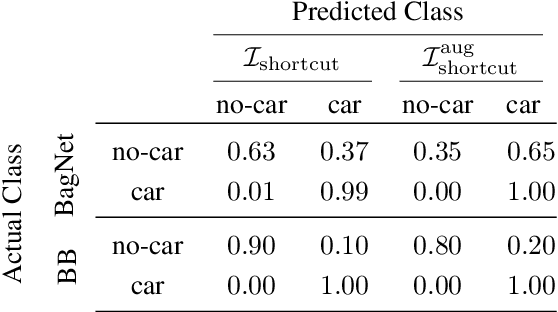

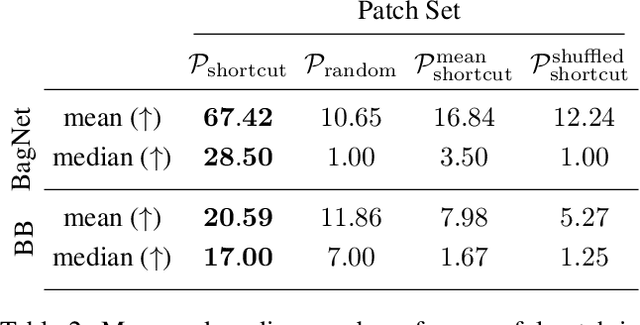
An important pillar for safe machine learning (ML) is the systematic mitigation of weaknesses in neural networks to afford their deployment in critical applications. An ubiquitous class of safety risks are learned shortcuts, i.e. spurious correlations a network exploits for its decisions that have no semantic connection to the actual task. Networks relying on such shortcuts bear the risk of not generalizing well to unseen inputs. Explainability methods help to uncover such network vulnerabilities. However, many of these techniques are not directly applicable if access to the network is constrained, in so-called black-box setups. These setups are prevalent when using third-party ML components. To address this constraint, we present an approach to detect learned shortcuts using an interpretable-by-design network as a proxy to the black-box model of interest. Leveraging the proxy's guarantees on introspection we automatically extract candidates for learned shortcuts. Their transferability to the black box is validated in a systematic fashion. Concretely, as proxy model we choose a BagNet, which bases its decisions purely on local image patches. We demonstrate on the autonomous driving dataset A2D2 that extracted patch shortcuts significantly influence the black box model. By efficiently identifying such patch-based vulnerabilities, we contribute to safer ML models.
Hierarchical Proxy-based Loss for Deep Metric Learning
Mar 25, 2021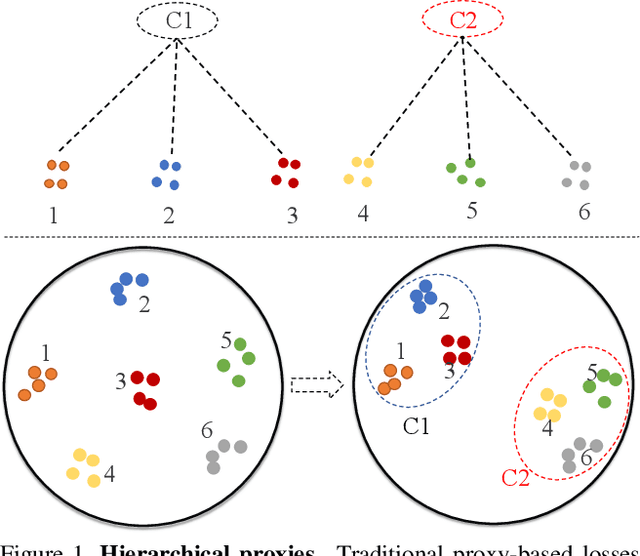
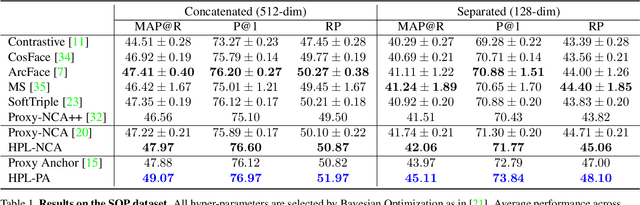
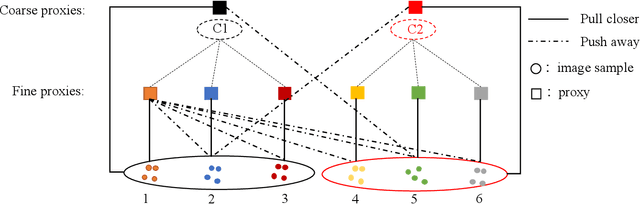
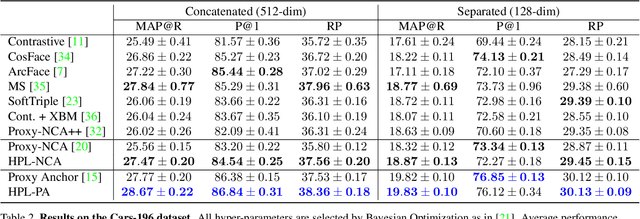
Proxy-based metric learning losses are superior to pair-based losses due to their fast convergence and low training complexity. However, existing proxy-based losses focus on learning class-discriminative features while overlooking the commonalities shared across classes which are potentially useful in describing and matching samples. Moreover, they ignore the implicit hierarchy of categories in real-world datasets, where similar subordinate classes can be grouped together. In this paper, we present a framework that leverages this implicit hierarchy by imposing a hierarchical structure on the proxies and can be used with any existing proxy-based loss. This allows our model to capture both class-discriminative features and class-shared characteristics without breaking the implicit data hierarchy. We evaluate our method on five established image retrieval datasets such as In-Shop and SOP. Results demonstrate that our hierarchical proxy-based loss framework improves the performance of existing proxy-based losses, especially on large datasets which exhibit strong hierarchical structure.
Noise-Aware Texture-Preserving Low-Light Enhancement
Sep 02, 2020
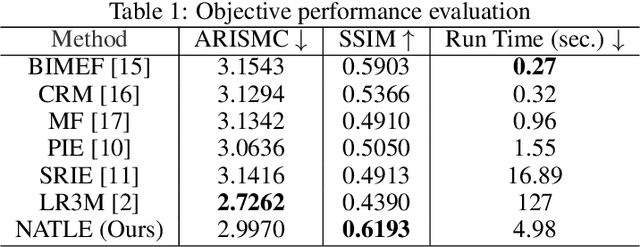


A simple and effective low-light image enhancement method based on a noise-aware texture-preserving retinex model is proposed in this work. The new method, called NATLE, attempts to strike a balance between noise removal and natural texture preservation through a low-complexity solution. Its cost function includes an estimated piece-wise smooth illumination map and a noise-free texture-preserving reflectance map. Afterwards, illumination is adjusted to form the enhanced image together with the reflectance map. Extensive experiments are conducted on common low-light image enhancement datasets to demonstrate the superior performance of NATLE.
Learning When to Quit: Meta-Reasoning for Motion Planning
Mar 07, 2021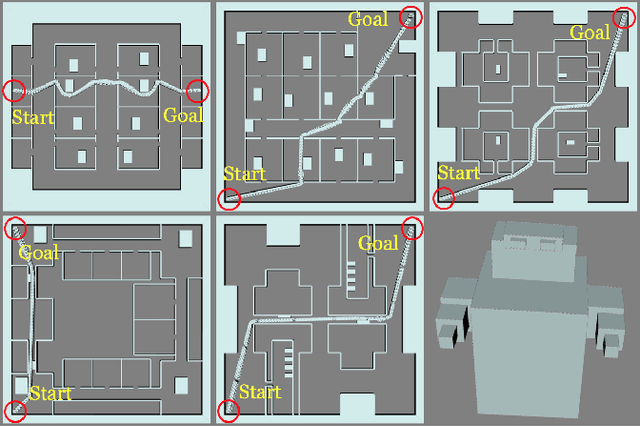
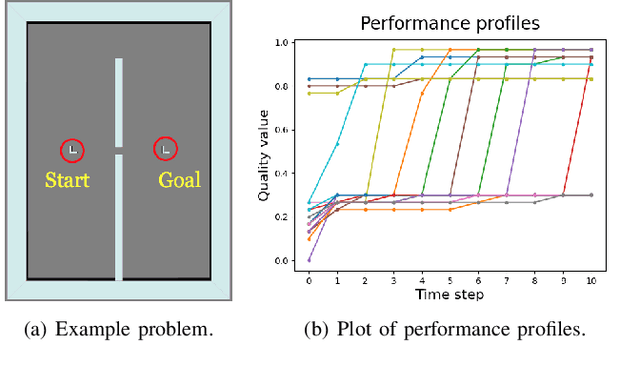
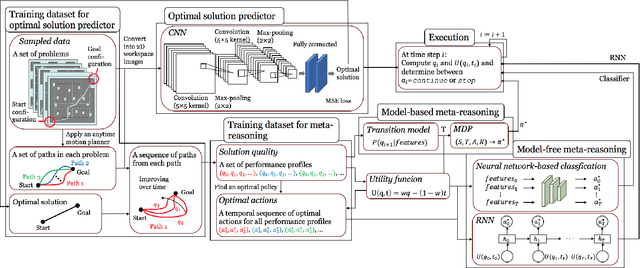
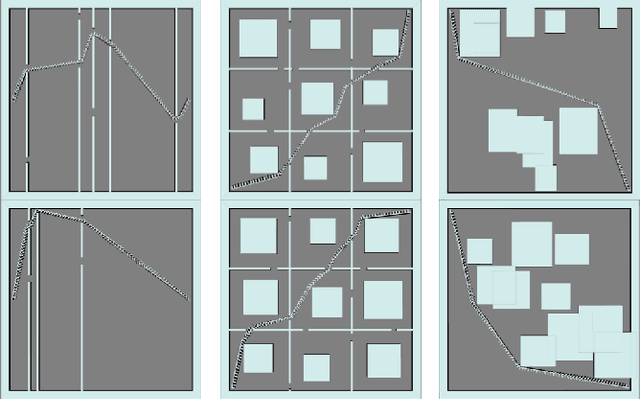
Anytime motion planners are widely used in robotics. However, the relationship between their solution quality and computation time is not well understood, and thus, determining when to quit planning and start execution is unclear. In this paper, we address the problem of deciding when to stop deliberation under bounded computational capacity, so called meta-reasoning, for anytime motion planning. We propose data-driven learning methods, model-based and model-free meta-reasoning, that are applicable to different environment distributions and agnostic to the choice of anytime motion planners. As a part of the framework, we design a convolutional neural network-based optimal solution predictor that predicts the optimal path length from a given 2D workspace image. We empirically evaluate the performance of the proposed methods in simulation in comparison with baselines.