 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Image: Scaling up Image Recognition
Jul 06, 2015
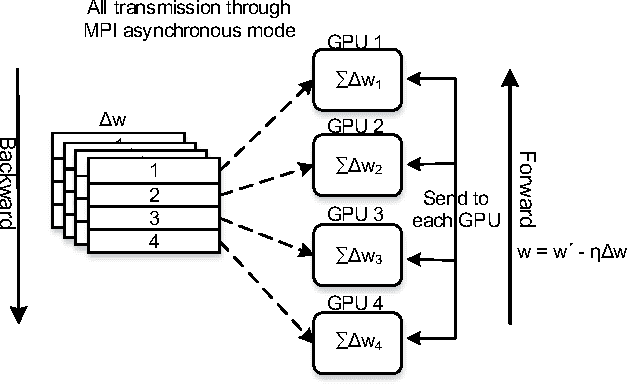
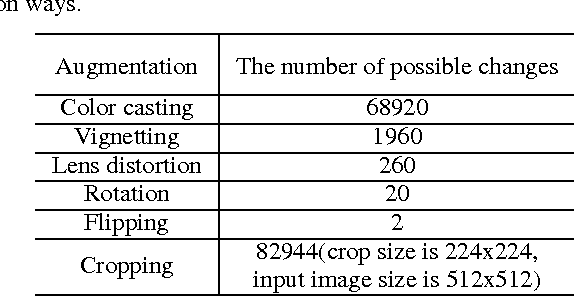
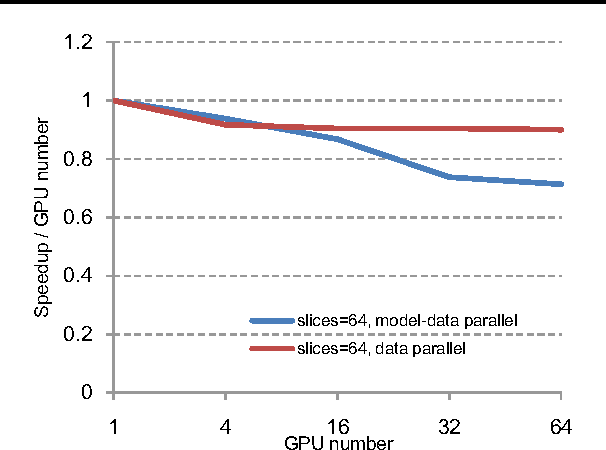
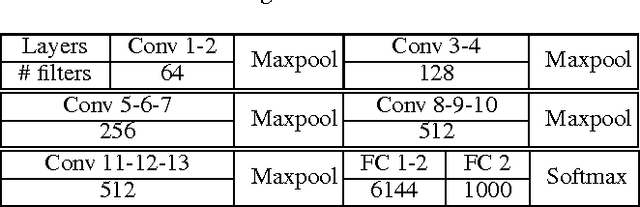
We present a state-of-the-art image recognition system, Deep Image, developed using end-to-end deep learning. The key components are a custom-built supercomputer dedicated to deep learning, a highly optimized parallel algorithm using new strategies for data partitioning and communication, larger deep neural network models, novel data augmentation approaches, and usage of multi-scale high-resolution images. Our method achieves excellent results on multiple challenging computer vision benchmarks.
Boundary and Entropy-driven Adversarial Learning for Fundus Image Segmentation
Jul 26, 2019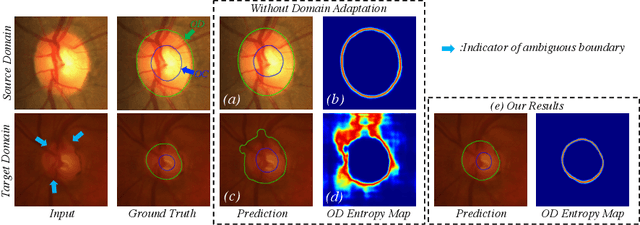

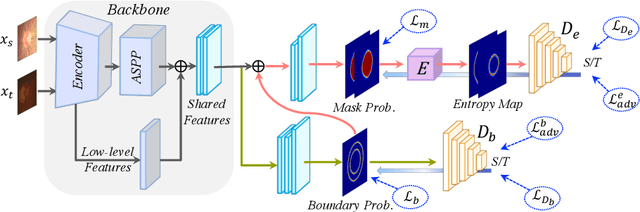
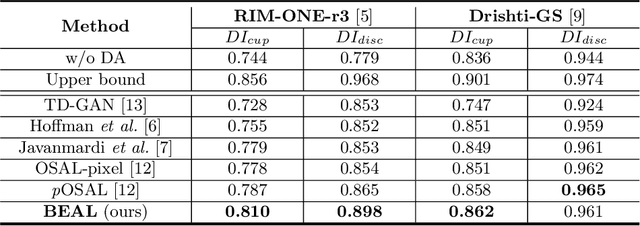
Accurate segmentation of the optic disc (OD) and cup (OC)in fundus images from different datasets is critical for glaucoma disease screening. The cross-domain discrepancy (domain shift) hinders the generalization of deep neural networks to work on different domain datasets.In this work, we present an unsupervised domain adaptation framework,called Boundary and Entropy-driven Adversarial Learning (BEAL), to improve the OD and OC segmentation performance, especially on the ambiguous boundary regions. In particular, our proposed BEAL frame-work utilizes the adversarial learning to encourage the boundary prediction and mask probability entropy map (uncertainty map) of the target domain to be similar to the source ones, generating more accurate boundaries and suppressing the high uncertainty predictions of OD and OC segmentation. We evaluate the proposed BEAL framework on two public retinal fundus image datasets (Drishti-GS and RIM-ONE-r3), and the experiment results demonstrate that our method outperforms the state-of-the-art unsupervised domain adaptation methods. Codes will be available at https://github.com/EmmaW8/BEAL.
Unpaired image denoising using a generative adversarial network in X-ray CT
Mar 04, 2019

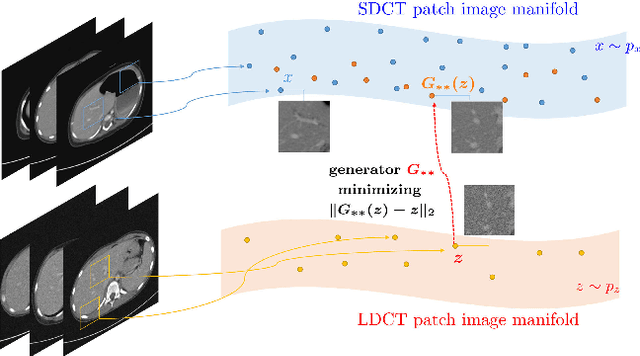
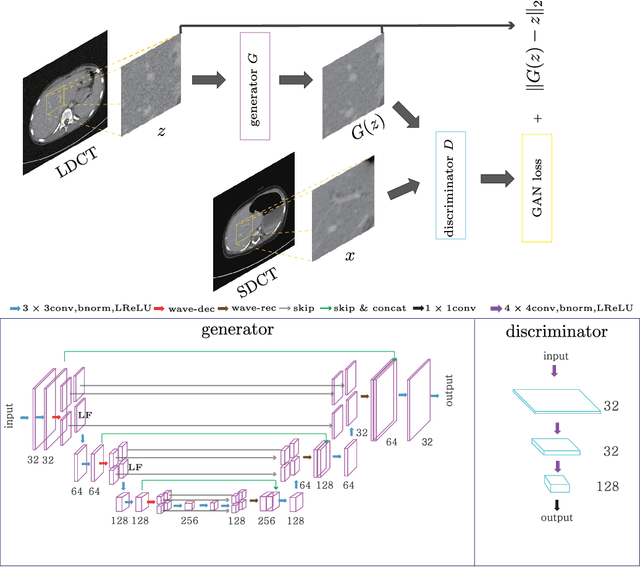
This paper proposes a deep learning-based denoising method for noisy low-dose computerized tomography (CT) images in the absence of paired training data. The proposed method uses a fidelity-embedded generative adversarial network (GAN) to learn a denoising function from unpaired training data of low-dose CT (LDCT) and standard-dose CT (SDCT) images, where the denoising function is the optimal generator in the GAN framework. Given an optimal discriminator in the GAN, the generator is optimized by minimizing a weighted sum of two losses: the Kullback-Leibler divergence between an SDCT data distribution and a generated distribution, and the $\ell_2$ loss between the LDCT image and the corresponding generated images (or denoised image). The experimental results show that the proposed deep-learning method with unpaired datasets performs comparably to a method using paired datasets. Clinical experiment was also performed to show the validity of the proposed method for non-Gaussian noise arising in the low-dose X-ray CT.
Lightweight Detection of Out-of-Distribution and Adversarial Samples via Channel Mean Discrepancy
Apr 23, 2021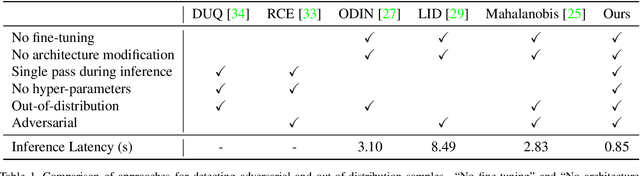


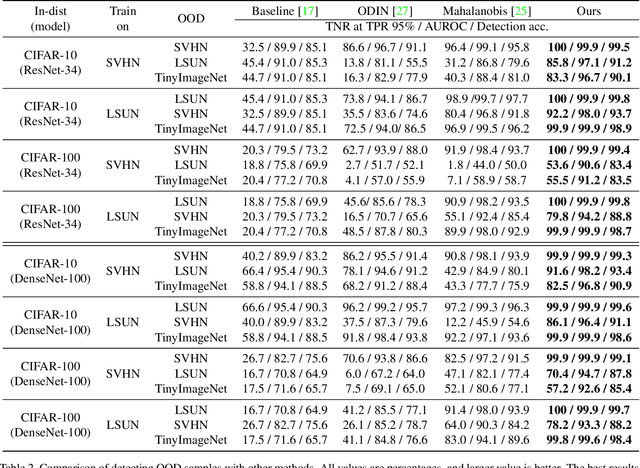
Detecting out-of-distribution (OOD) and adversarial samples is essential when deploying classification models in real-world applications. We introduce Channel Mean Discrepancy (CMD), a model-agnostic distance metric for evaluating the statistics of features extracted by classification models, inspired by integral probability metrics. CMD compares the feature statistics of incoming samples against feature statistics estimated from previously seen training samples with minimal overhead. We experimentally demonstrate that CMD magnitude is significantly smaller for legitimate samples than for OOD and adversarial samples. We propose a simple method to reliably differentiate between legitimate samples from OOD and adversarial samples using CMD, requiring only a single forward pass on a pre-trained classification model per sample. We further demonstrate how to achieve single image detection by using a lightweight model for channel sensitivity tuning, an improvement on other statistical detection methods. Preliminary results show that our simple yet effective method outperforms several state-of-the-art approaches to detecting OOD and adversarial samples across various datasets and attack methods with high efficiency and generalizability.
Image Inpainting for High-Resolution Textures using CNN Texture Synthesis
Feb 12, 2018
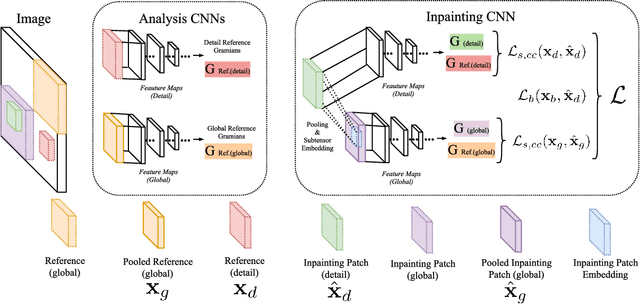
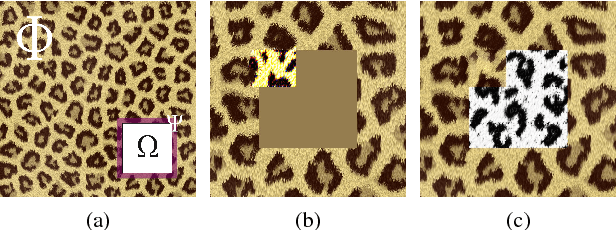

Deep neural networks have been successfully applied to problems such as image segmentation, image super-resolution, coloration and image inpainting. In this work we propose the use of convolutional neural networks (CNN) for image inpainting of large regions in high-resolution textures. Due to limited computational resources processing high-resolution images with neural networks is still an open problem. Existing methods separate inpainting of global structure and the transfer of details, which leads to blurry results and loss of global coherence in the detail transfer step. Based on advances in texture synthesis using CNNs we propose patch-based image inpainting by a CNN that is able to optimize for global as well as detail texture statistics. Our method is capable of filling large inpainting regions, oftentimes exceeding the quality of comparable methods for high-resolution images. For reference patch look-up we propose to use the same summary statistics that are used in the inpainting process.
Exploring Autoencoder-Based Error-Bounded Compression for Scientific Data
May 25, 2021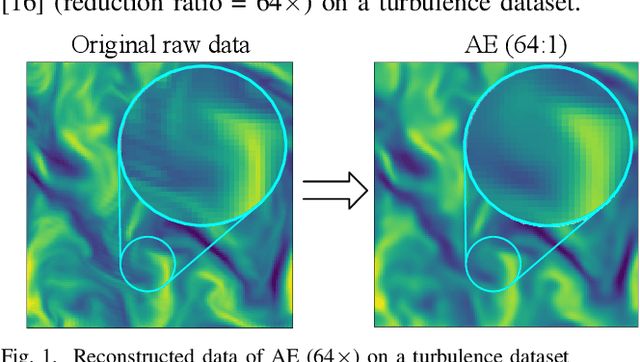
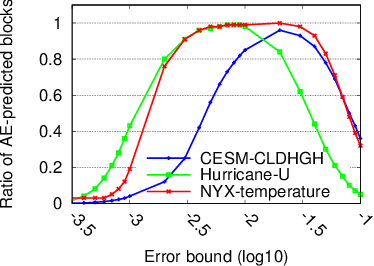
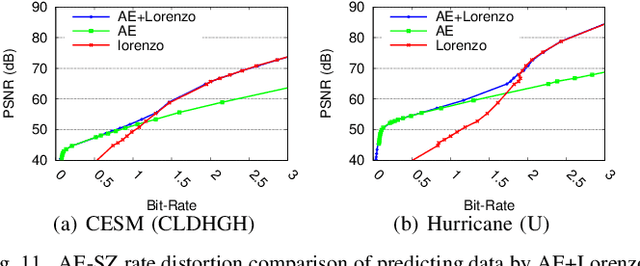
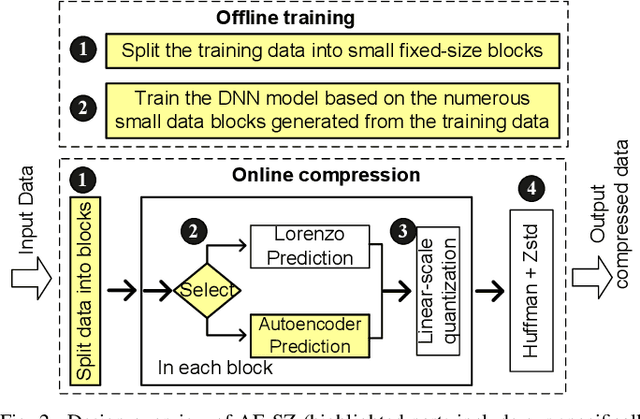
Error-bounded lossy compression is becoming an indispensable technique for the success of today's scientific projects with vast volumes of data produced during the simulations or instrument data acquisitions. Not only can it significantly reduce data size, but it also can control the compression errors based on user-specified error bounds. Autoencoder (AE) models have been widely used in image compression, but few AE-based compression approaches support error-bounding features, which are highly required by scientific applications. To address this issue, we explore using convolutional autoencoders to improve error-bounded lossy compression for scientific data, with the following three key contributions. (1) We provide an in-depth investigation of the characteristics of various autoencoder models and develop an error-bounded autoencoder-based framework in terms of the SZ model. (2) We optimize the compression quality for main stages in our designed AE-based error-bounded compression framework, fine-tuning the block sizes and latent sizes and also optimizing the compression efficiency of latent vectors. (3) We evaluate our proposed solution using five real-world scientific datasets and comparing them with six other related works. Experiments show that our solution exhibits a very competitive compression quality from among all the compressors in our tests. In absolute terms, it can obtain a much better compression quality (100% ~ 800% improvement in compression ratio with the same data distortion) compared with SZ2.1 and ZFP in cases with a high compression ratio.
Image Transformation can make Neural Networks more robust against Adversarial Examples
Jan 10, 2019
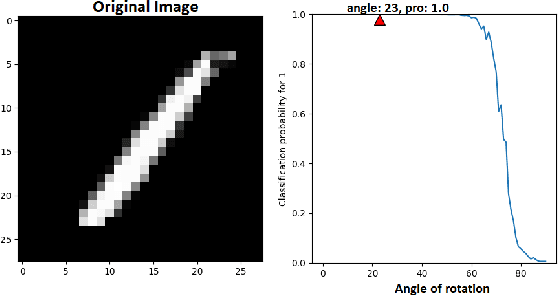
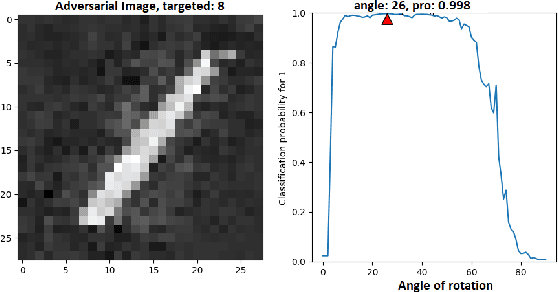
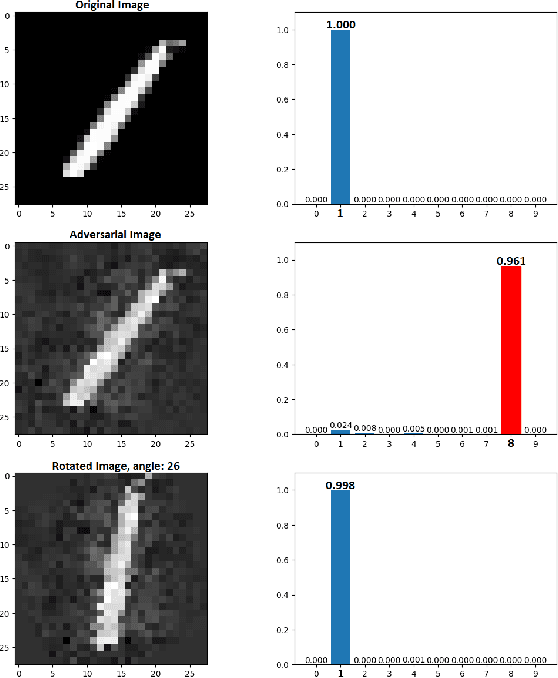
Neural networks are being applied in many tasks related to IoT with encouraging results. For example, neural networks can precisely detect human, objects and animal via surveillance camera for security purpose. However, neural networks have been recently found vulnerable to well-designed input samples that called adversarial examples. Such issue causes neural networks to misclassify adversarial examples that are imperceptible to humans. We found giving a rotation to an adversarial example image can defeat the effect of adversarial examples. Using MNIST number images as the original images, we first generated adversarial examples to neural network recognizer, which was completely fooled by the forged examples. Then we rotated the adversarial image and gave them to the recognizer to find the recognizer to regain the correct recognition. Thus, we empirically confirmed rotation to images can protect pattern recognizer based on neural networks from adversarial example attacks.
Compassionately Conservative Balanced Cuts for Image Segmentation
Mar 27, 2018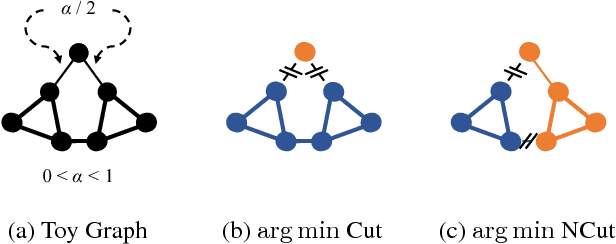
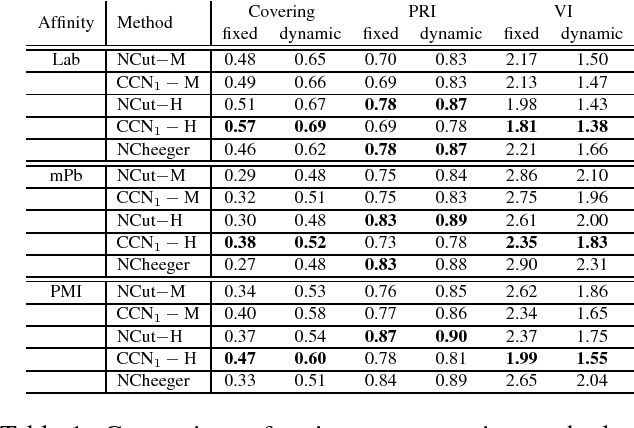
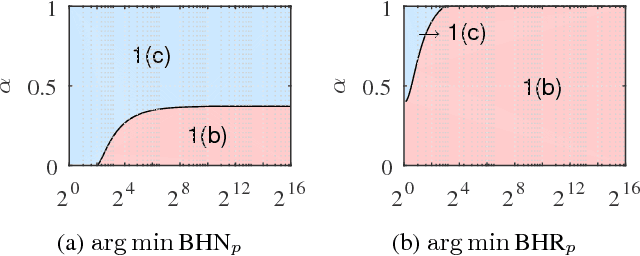
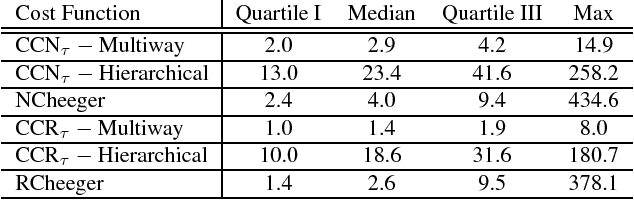
The Normalized Cut (NCut) objective function, widely used in data clustering and image segmentation, quantifies the cost of graph partitioning in a way that biases clusters or segments that are balanced towards having lower values than unbalanced partitionings. However, this bias is so strong that it avoids any singleton partitions, even when vertices are very weakly connected to the rest of the graph. Motivated by the B\"uhler-Hein family of balanced cut costs, we propose the family of Compassionately Conservative Balanced (CCB) Cut costs, which are indexed by a parameter that can be used to strike a compromise between the desire to avoid too many singleton partitions and the notion that all partitions should be balanced. We show that CCB-Cut minimization can be relaxed into an orthogonally constrained $\ell_{\tau}$-minimization problem that coincides with the problem of computing Piecewise Flat Embeddings (PFE) for one particular index value, and we present an algorithm for solving the relaxed problem by iteratively minimizing a sequence of reweighted Rayleigh quotients (IRRQ). Using images from the BSDS500 database, we show that image segmentation based on CCB-Cut minimization provides better accuracy with respect to ground truth and greater variability in region size than NCut-based image segmentation.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 22, 2020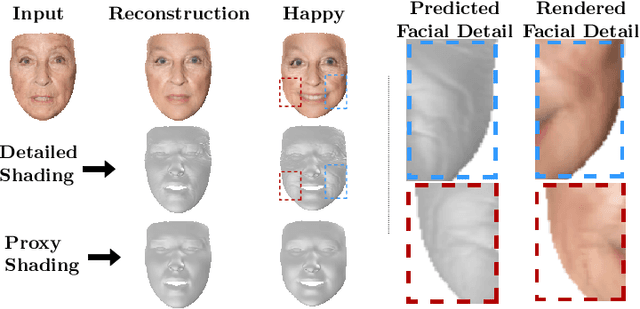
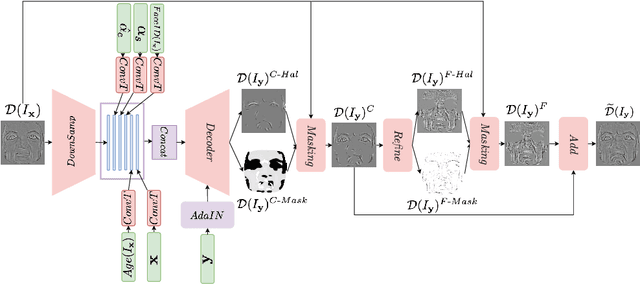
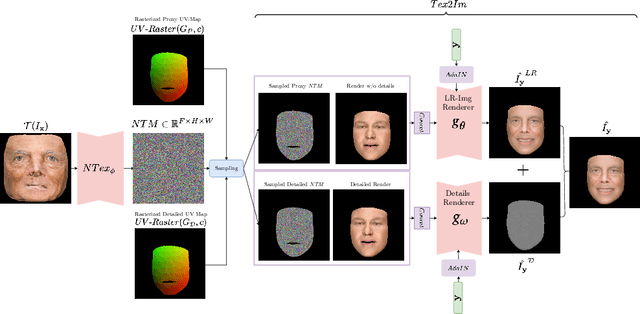

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
Deep Parallel MRI Reconstruction Network Without Coil Sensitivities
Aug 18, 2020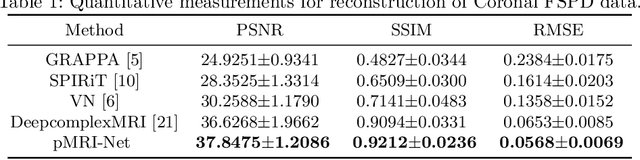
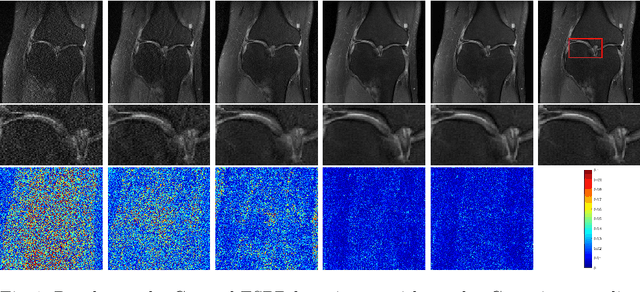
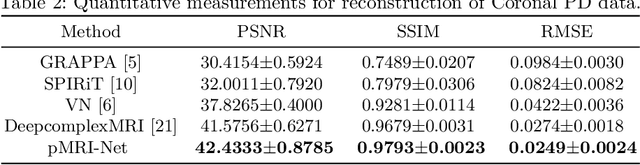
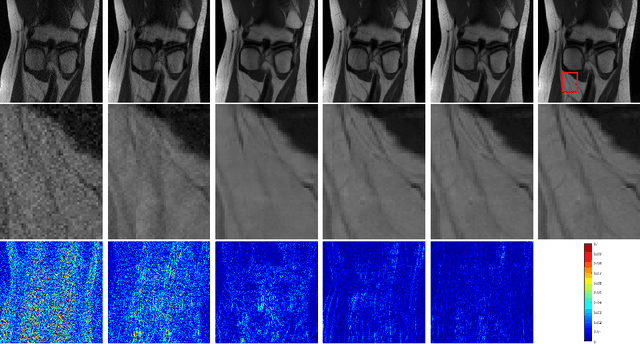
We propose a novel deep neural network architecture by mapping the robust proximal gradient scheme for fast image reconstruction in parallel MRI (pMRI) with regularization function trained from data. The proposed network learns to adaptively combine the multi-coil images from incomplete pMRI data into a single image with homogeneous contrast, which is then passed to a nonlinear encoder to efficiently extract sparse features of the image. Unlike most of existing deep image reconstruction networks, our network does not require knowledge of sensitivity maps, which can be difficult to estimate accurately, and have been a major bottleneck of image reconstruction in real-world pMRI applications. The experimental results demonstrate the promising performance of our method on a variety of pMRI imaging data sets.