 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Unsupervised Learning Model for Deformable Medical Image Registration
Apr 20, 2018
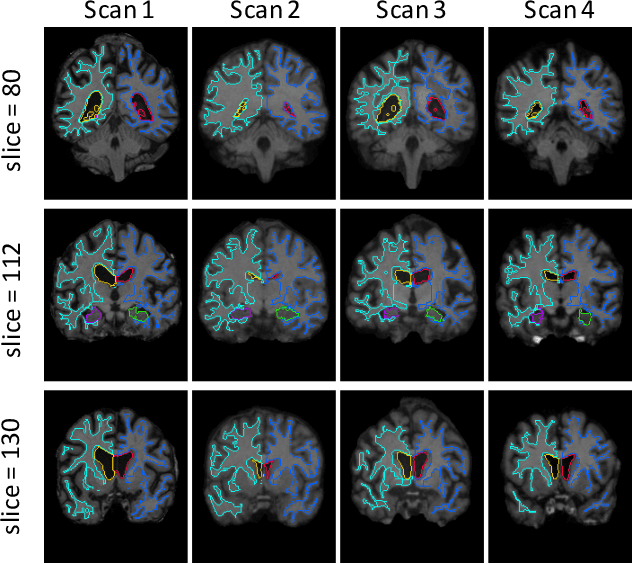
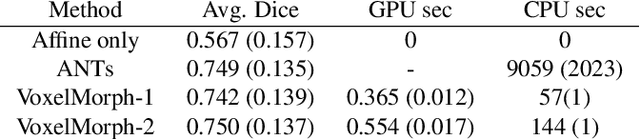
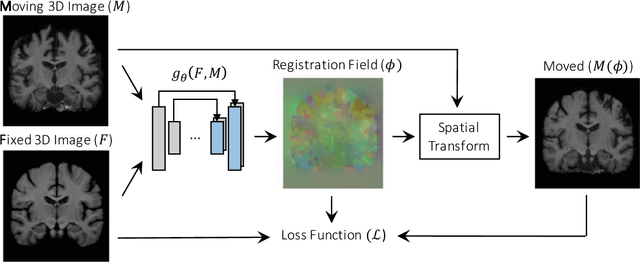
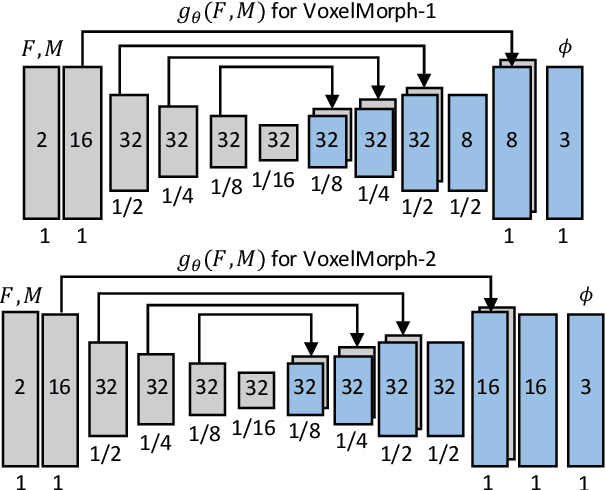
We present a fast learning-based algorithm for deformable, pairwise 3D medical image registration. Current registration methods optimize an objective function independently for each pair of images, which can be time-consuming for large data. We define registration as a parametric function, and optimize its parameters given a set of images from a collection of interest. Given a new pair of scans, we can quickly compute a registration field by directly evaluating the function using the learned parameters. We model this function using a convolutional neural network (CNN), and use a spatial transform layer to reconstruct one image from another while imposing smoothness constraints on the registration field. The proposed method does not require supervised information such as ground truth registration fields or anatomical landmarks. We demonstrate registration accuracy comparable to state-of-the-art 3D image registration, while operating orders of magnitude faster in practice. Our method promises to significantly speed up medical image analysis and processing pipelines, while facilitating novel directions in learning-based registration and its applications. Our code is available at https://github.com/balakg/voxelmorph .
Learning a Dynamic Map of Visual Appearance
Dec 29, 2020
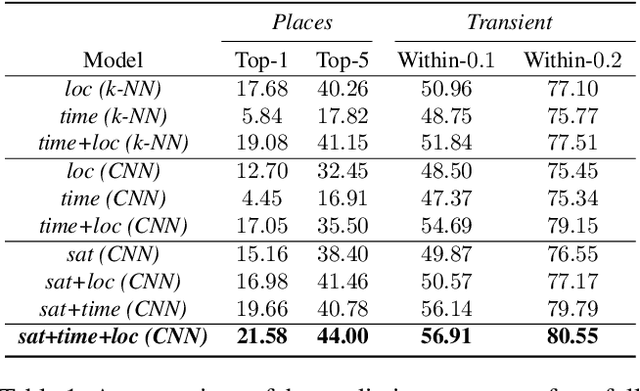

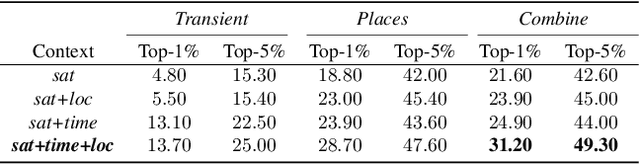
The appearance of the world varies dramatically not only from place to place but also from hour to hour and month to month. Every day billions of images capture this complex relationship, many of which are associated with precise time and location metadata. We propose to use these images to construct a global-scale, dynamic map of visual appearance attributes. Such a map enables fine-grained understanding of the expected appearance at any geographic location and time. Our approach integrates dense overhead imagery with location and time metadata into a general framework capable of mapping a wide variety of visual attributes. A key feature of our approach is that it requires no manual data annotation. We demonstrate how this approach can support various applications, including image-driven mapping, image geolocalization, and metadata verification.
Mesh Graphormer
Apr 01, 2021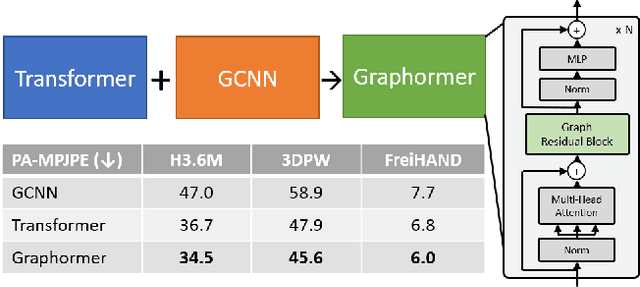
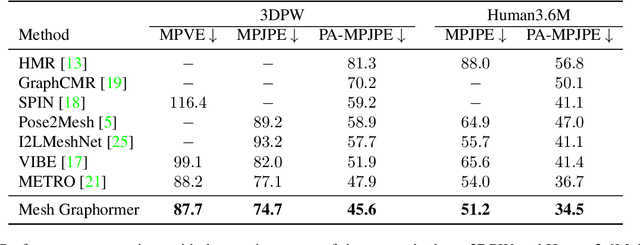
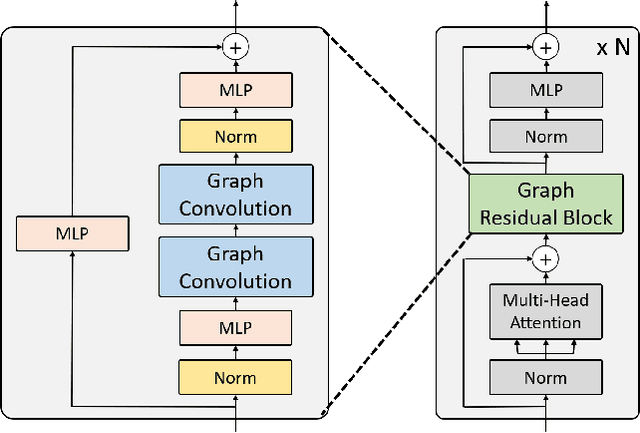
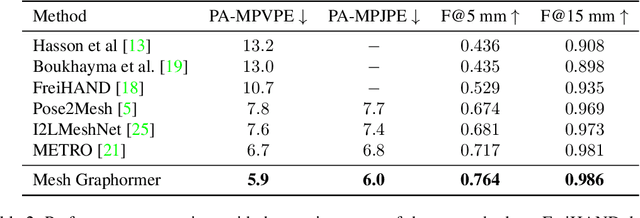
We present a graph-convolution-reinforced transformer, named Mesh Graphormer, for 3D human pose and mesh reconstruction from a single image. Recently both transformers and graph convolutional neural networks (GCNNs) have shown promising progress in human mesh reconstruction. Transformer-based approaches are effective in modeling non-local interactions among 3D mesh vertices and body joints, whereas GCNNs are good at exploiting neighborhood vertex interactions based on a pre-specified mesh topology. In this paper, we study how to combine graph convolutions and self-attentions in a transformer to model both local and global interactions. Experimental results show that our proposed method, Mesh Graphormer, significantly outperforms the previous state-of-the-art methods on multiple benchmarks, including Human3.6M, 3DPW, and FreiHAND datasets
Wide & Deep neural network model for patch aggregation in CNN-based prostate cancer detection systems
May 20, 2021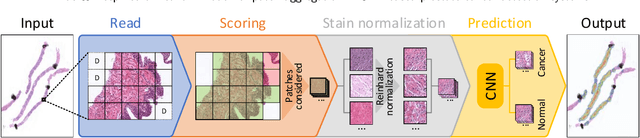
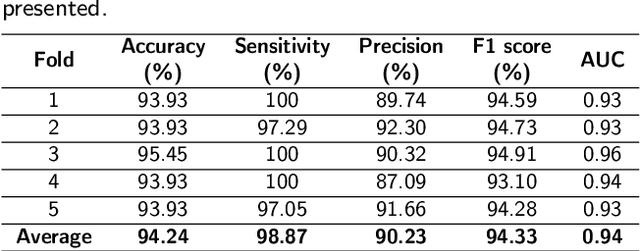
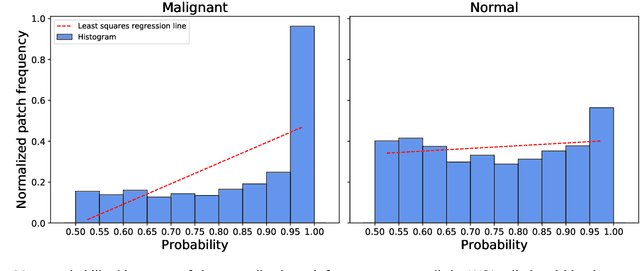
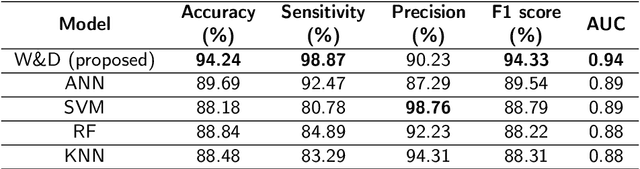
Prostate cancer (PCa) is one of the most commonly diagnosed cancer and one of the leading causes of death among men, with almost 1.41 million new cases and around 375,000 deaths in 2020. Artificial Intelligence algorithms have had a huge impact in medical image analysis, including digital histopathology, where Convolutional Neural Networks (CNNs) are used to provide a fast and accurate diagnosis, supporting experts in this task. To perform an automatic diagnosis, prostate tissue samples are first digitized into gigapixel-resolution whole-slide images. Due to the size of these images, neural networks cannot use them as input and, therefore, small subimages called patches are extracted and predicted, obtaining a patch-level classification. In this work, a novel patch aggregation method based on a custom Wide & Deep neural network model is presented, which performs a slide-level classification using the patch-level classes obtained from a CNN. The malignant tissue ratio, a 10-bin malignant probability histogram, the least squares regression line of the histogram, and the number of malignant connected components are used by the proposed model to perform the classification. An accuracy of 94.24% and a sensitivity of 98.87% were achieved, proving that the proposed system could aid pathologists by speeding up the screening process and, thus, contribute to the fight against PCa.
FlipReID: Closing the Gap between Training and Inference in Person Re-Identification
May 12, 2021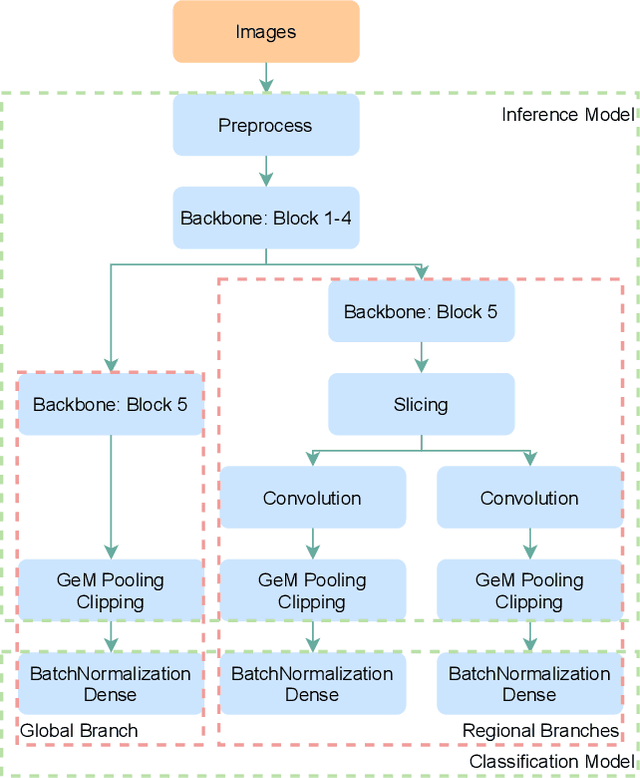
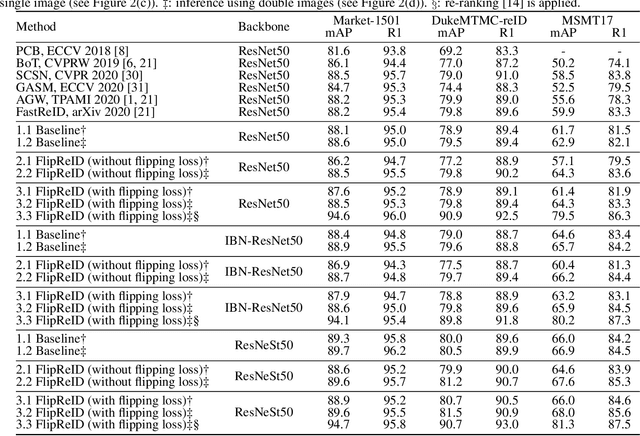
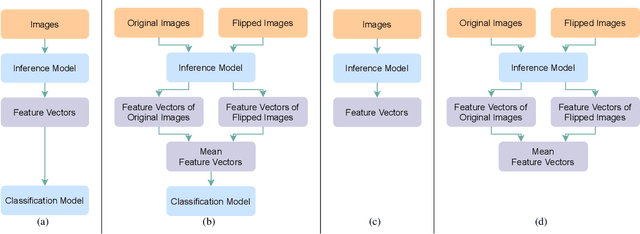
Since neural networks are data-hungry, incorporating data augmentation in training is a widely adopted technique that enlarges datasets and improves generalization. On the other hand, aggregating predictions of multiple augmented samples (i.e., test-time augmentation) could boost performance even further. In the context of person re-identification models, it is common practice to extract embeddings for both the original images and their horizontally flipped variants. The final representation is the mean of the aforementioned feature vectors. However, such scheme results in a gap between training and inference, i.e., the mean feature vectors calculated in inference are not part of the training pipeline. In this study, we devise the FlipReID structure with the flipping loss to address this issue. More specifically, models using the FlipReID structure are trained on the original images and the flipped images simultaneously, and incorporating the flipping loss minimizes the mean squared error between feature vectors of corresponding image pairs. Extensive experiments show that our method brings consistent improvements. In particular, we set a new record for MSMT17 which is the largest person re-identification dataset. The source code is available at https://github.com/nixingyang/FlipReID.
Glioblastoma Multiforme Patient Survival Prediction
Jan 26, 2021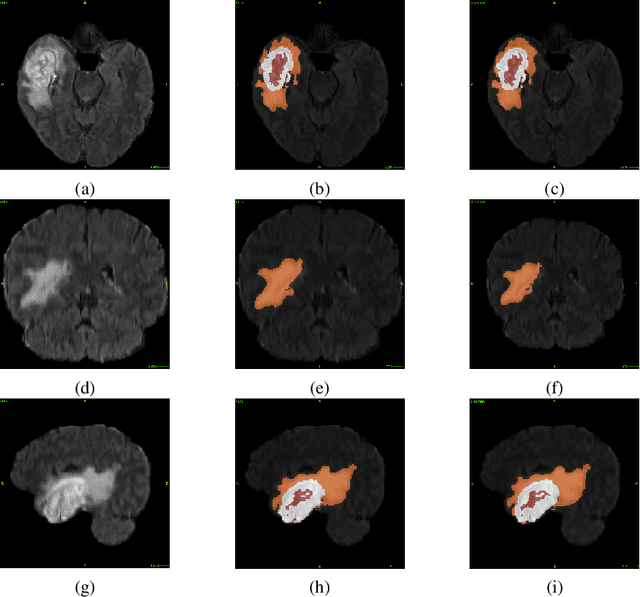
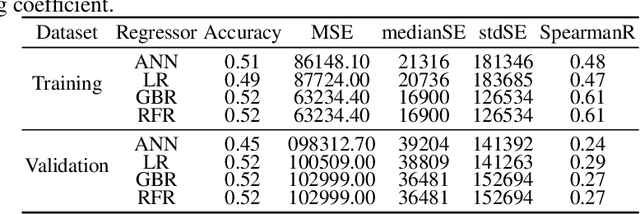

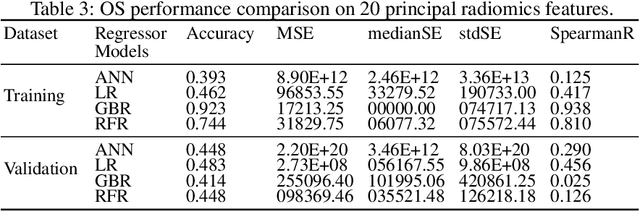
Glioblastoma Multiforme is a very aggressive type of brain tumor. Due to spatial and temporal intra-tissue inhomogeneity, location and the extent of the cancer tissue, it is difficult to detect and dissect the tumor regions. In this paper, we propose survival prognosis models using four regressors operating on handcrafted image-based and radiomics features. We hypothesize that the radiomics shape features have the highest correlation with survival prediction. The proposed approaches were assessed on the Brain Tumor Segmentation (BraTS-2020) challenge dataset. The highest accuracy of image features with random forest regressor approach was 51.5\% for the training and 51.7\% for the validation dataset. The gradient boosting regressor with shape features gave an accuracy of 91.5\% and 62.1\% on training and validation datasets respectively. It is better than the BraTS 2020 survival prediction challenge winners on the training and validation datasets. Our work shows that handcrafted features exhibit a strong correlation with survival prediction. The consensus based regressor with gradient boosting and radiomics shape features is the best combination for survival prediction.
* 10 pages, 9 figures
Towards Geometry Guided Neural Relighting with Flash Photography
Aug 12, 2020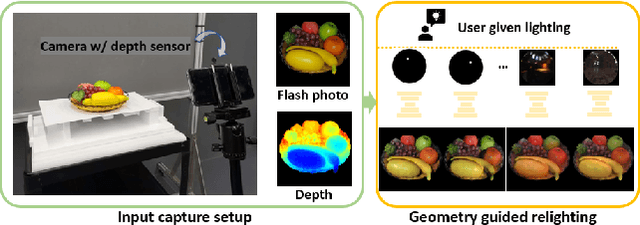

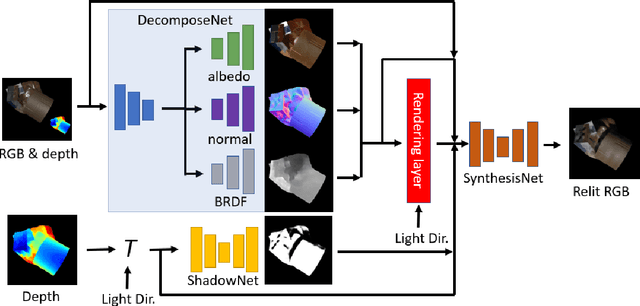
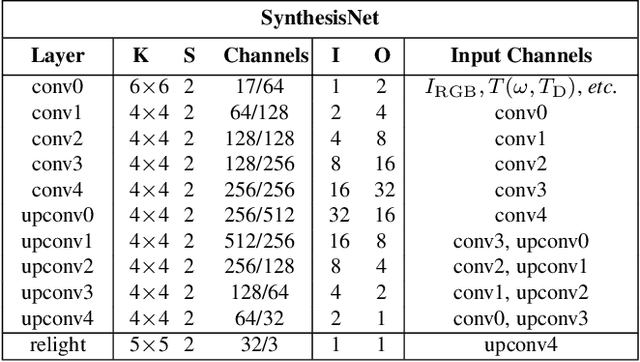
Previous image based relighting methods require capturing multiple images to acquire high frequency lighting effect under different lighting conditions, which needs nontrivial effort and may be unrealistic in certain practical use scenarios. While such approaches rely entirely on cleverly sampling the color images under different lighting conditions, little has been done to utilize geometric information that crucially influences the high-frequency features in the images, such as glossy highlight and cast shadow. We therefore propose a framework for image relighting from a single flash photograph with its corresponding depth map using deep learning. By incorporating the depth map, our approach is able to extrapolate realistic high-frequency effects under novel lighting via geometry guided image decomposition from the flashlight image, and predict the cast shadow map from the shadow-encoding transformed depth map. Moreover, the single-image based setup greatly simplifies the data capture process. We experimentally validate the advantage of our geometry guided approach over state-of-the-art image-based approaches in intrinsic image decomposition and image relighting, and also demonstrate our performance on real mobile phone photo examples.
Single Image Haze Removal using a Generative Adversarial Network
Oct 22, 2018
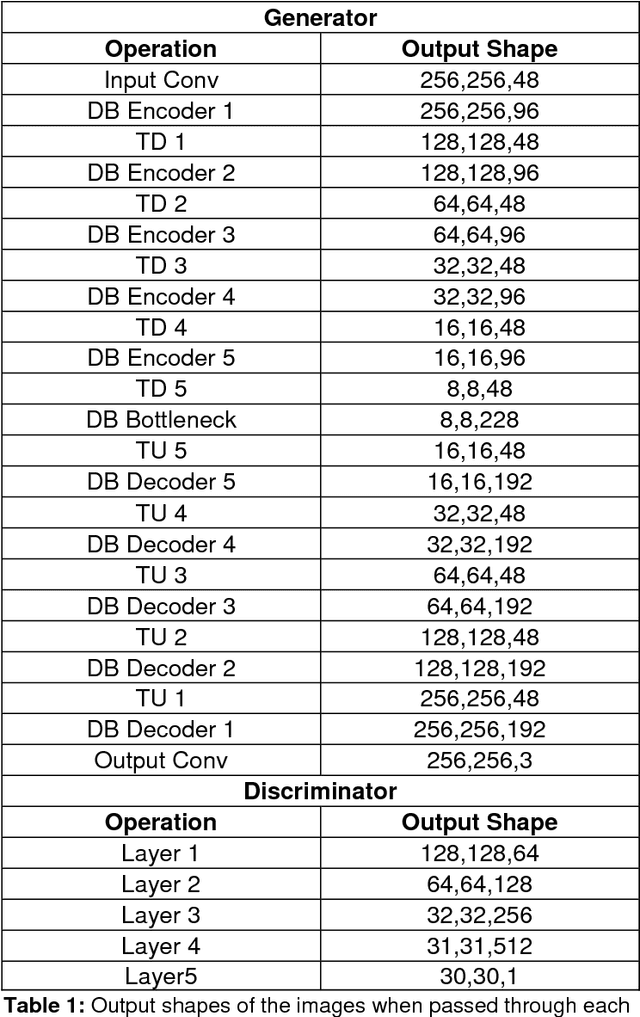
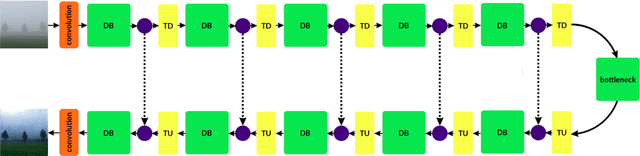

Single image haze removal is an under constrained problem due to lack of depth information. It is usually performed by estimating the transmission map directly or by using a prior. Other methods use predictive models to estimate the transmission map and perform guided dehazing. In this paper, we propose a conditional GAN, that can directly remove haze from an image, without explicitly estimating transmission map or haze relevant features. We find that, only one module, comprising of the generator and discriminator is enough. We replaced the classic U-Net with the Tiramisu model, yielding much higher parameter efficiency and performance. We also observe that the performance during inference is dependent on the diversity of the dataset used for training. Experiments on synthetic and real world hazy images prove that our model performs competitively with the state of the art models.
Sandwich Batch Normalization
Feb 22, 2021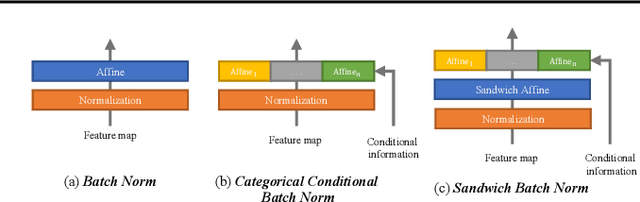

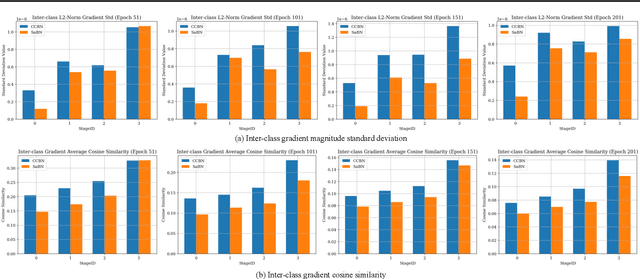

We present Sandwich Batch Normalization (SaBN), an embarrassingly easy improvement of Batch Normalization (BN) with only a few lines of code changes. SaBN is motivated by addressing the inherent feature distribution heterogeneity that one can be identified in many tasks, which can arise from data heterogeneity (multiple input domains) or model heterogeneity (dynamic architectures, model conditioning, etc.). Our SaBN factorizes the BN affine layer into one shared sandwich affine layer, cascaded by several parallel independent affine layers. Concrete analysis reveals that, during optimization, SaBN promotes balanced gradient norms while still preserving diverse gradient directions: a property that many application tasks seem to favor. We demonstrate the prevailing effectiveness of SaBN as a drop-in replacement in four tasks: $\textbf{conditional image generation}$, $\textbf{neural architecture search}$ (NAS), $\textbf{adversarial training}$, and $\textbf{arbitrary style transfer}$. Leveraging SaBN immediately achieves better Inception Score and FID on CIFAR-10 and ImageNet conditional image generation with three state-of-the-art GANs; boosts the performance of a state-of-the-art weight-sharing NAS algorithm significantly on NAS-Bench-201; substantially improves the robust and standard accuracies for adversarial defense; and produces superior arbitrary stylized results. We also provide visualizations and analysis to help understand why SaBN works. Codes are available at https://github.com/VITA-Group/Sandwich-Batch-Normalization.
MRRC: Multiple Role Representation Crossover Interpretation for Image Captioning With R-CNN Feature Distribution Composition (FDC)
Feb 15, 2020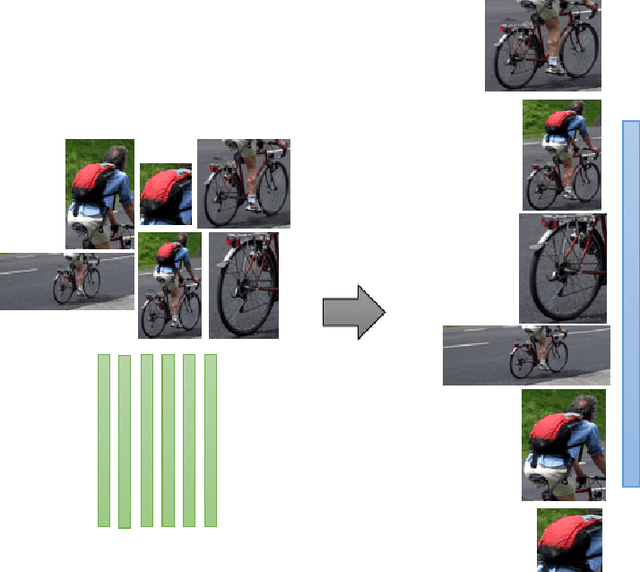
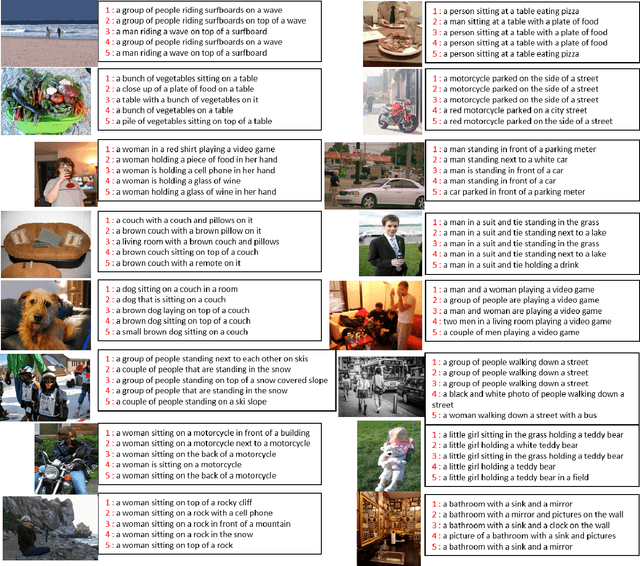
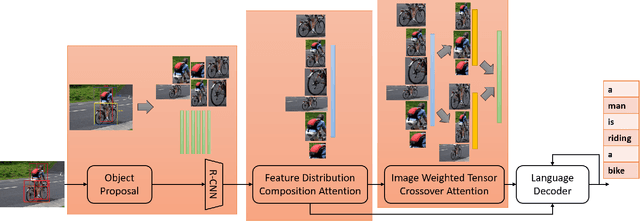
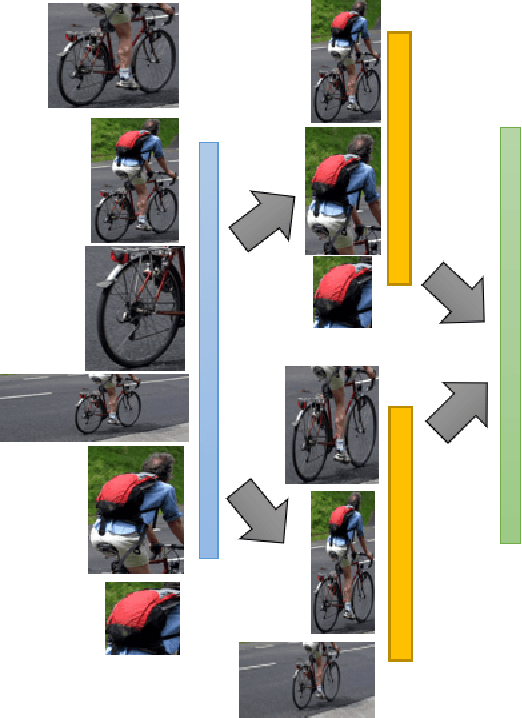
While image captioning through machines requires structured learning and basis for interpretation, improvement requires multiple context understanding and processing in a meaningful way. This research will provide a novel concept for context combination and will impact many applications to deal visual features as an equivalence of descriptions of objects, activities and events. There are three components of our architecture: Feature Distribution Composition (FDC) Layer Attention, Multiple Role Representation Crossover (MRRC) Attention Layer and the Language Decoder. FDC Layer Attention helps in generating the weighted attention from RCNN features, MRRC Attention Layer acts as intermediate representation processing and helps in generating the next word attention, while Language Decoder helps in estimation of the likelihood for the next probable word in the sentence. We demonstrated effectiveness of FDC, MRRC, regional object feature attention and reinforcement learning for effective learning to generate better captions from images. The performance of our model enhanced previous performances by 35.3\% and created a new standard and theory for representation generation based on logic, better interpretability and contexts.