 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Efficient FPGA Implementation of Sigmoid Function Using Mixed-Radix Hyperbolic Rotation CORDIC
Apr 26, 2026Efficient hardware implementation of nonlinear activation functions is a crucial task in deploying artificial neural networks on resource-constrained and edge devices such as Field-Programmable Gate Arrays (FPGAs). The sigmoid activation function is widely used for probabilistic output, binary classification, and gating mechanisms in recurrent neural networks, despite its reliance on exponential computations. This paper presents a hardware-efficient FPGA implementation of the sigmoid activation function using a mixed-radix CORDIC-based architecture. The proposed approach leverages the mathematical relationship between the sigmoid and hyperbolic tangent functions. The input range is normalized to 1, enabling the corresponding tanh computation to operate within a reduced range of 0.5, which significantly improves convergence behavior. To achieve high accuracy with minimal hardware overhead, a modified mixed-radix hyperbolic rotation CORDIC (MR-HRC) algorithm combining radix-2 and radix-4 iterations is introduced. The initial radix-2 stage ensures stable convergence, while the subsequent radix-4 stage accelerates convergence without requiring scale-factor compensation. In the final stage, a radix-2 linear vectoring CORDIC (R2-LVC) is used to compute the hyperbolic tangent by dividing hyperbolic sine and cosine values derived from the MR-HRC algorithm. The entire architecture is fully pipelined and implemented on an FPGA. The design is realized on an Xilinx Virtex-7 FPGA using a 16-bit fixed-point representation. Experimental results demonstrate a significant reduction in hardware utilization, requiring only 835 logic slices with zero DSP usage. Additionally, the design achieves a mean absolute error of 4.23 10^-4, outperforming several recent sigmoid implementations.
From Alignment to Prediction: A Study of Self-Supervised Learning and Predictive Representation Learning
Apr 15, 2026Self-supervised learning has emerged as a major technique for the task of learning from unlabeled data, where the current methods mostly revolve around alignment of representations and input recon struction. Although such approaches have demonstrated excellent performance in practice, their scope remains mostly confined to learning from observed data and does not provide much help in terms of a learning structure that is predictive of the data distribution. In this paper, we study some of the recent developments in the realm of self-supervised learning. We define a new category called Predictive Representation Learning (PRL), which revolves around the latent prediction of unobserved components of data based on the observation. We propose a common taxonomy that classifies PRL along with alignment and reconstruction-based learning approaches. Furthermore, we argue that Joint-Embedding Predictive Architecture(JEPA) can be considered as an exemplary member of this new paradigm. We further discuss theoretical perspectives and open challenges, highlighting predictive representation learning as a promising direction for future self-supervised learning research. In this study, we implemented Bootstrap Your Own Latent (BYOL), Masked Autoencoders (MAE), and Image-JEPA (I-JEPA) for comparative analysis. The results indicate that MAE achieves perfect similarity of 1.00, but exhibits relatively weak robustness of 0.55. In contrast, BYOL and I-JEPA attain accuracies of 0.98 and 0.95, with robustness scores of 0.75 and 0.78, respectively.
Design and Development of an ML/DL Attack Resistance of RC-Based PUF for IoT Security
Mar 26, 2026Physically Unclonable Functions (PUFs) provide promising hardware security for IoT authentication, leveraging inherent randomness suitable for resource constrained environments. However, ML/DL modeling attacks threaten PUF security by learning challenge-response patterns. This work introduces a custom resistor-capacitor (RC) based dynamically reconfigurable PUF using 32-bit challenge-response pairs (CRPs) designed to resist such attacks. We systematically evaluated robustness by generating a CRP dataset and splitting it into training, validation, and test sets. Multiple ML techniques including Artificial Neural Networks (ANN), Gradient Boosted Neural Networks (GBNN), Decision Trees (DT), Random Forests (RF), and XGBoost, were trained to model PUF behavior. While all models achieved 100% training accuracy, test performance remained near random guessing: 51.05% (ANN), 53.27% (GBNN), 50.06% (DT), 52.08% (RF), and 50.97% (XGBoost). These results demonstrate the proposed PUF's strong resistance to ML-driven modeling attacks, as advanced algorithms fail to reproduce accurate responses. The dynamically reconfigurable architecture enhances robustness against adversarial threats with minimal resource overhead. This simple RC-PUF offers an effective, low-cost alternative to complex encryption for securing next-generation IoT authentication against machine learning-based threats, ensuring reliable device verification without compromising computational efficiency or scalability in deployed IoT networks.
Attention-gated U-Net model for semantic segmentation of brain tumors and feature extraction for survival prognosis
Feb 14, 2026Gliomas, among the most common primary brain tumors, vary widely in aggressiveness, prognosis, and histology, making treatment challenging due to complex and time-intensive surgical interventions. This study presents an Attention-Gated Recurrent Residual U-Net (R2U-Net) based Triplanar (2.5D) model for improved brain tumor segmentation. The proposed model enhances feature representation and segmentation accuracy by integrating residual, recurrent, and triplanar architectures while maintaining computational efficiency, potentially aiding in better treatment planning. The proposed method achieves a Dice Similarity Score (DSC) of 0.900 for Whole Tumor (WT) segmentation on the BraTS2021 validation set, demonstrating performance comparable to leading models. Additionally, the triplanar network extracts 64 features per planar model for survival days prediction, which are reduced to 28 using an Artificial Neural Network (ANN). This approach achieves an accuracy of 45.71%, a Mean Squared Error (MSE) of 108,318.128, and a Spearman Rank Correlation Coefficient (SRC) of 0.338 on the test dataset.
Artificial Intelligence in Material Engineering: A review on applications of AI in Material Engineering
Sep 15, 2022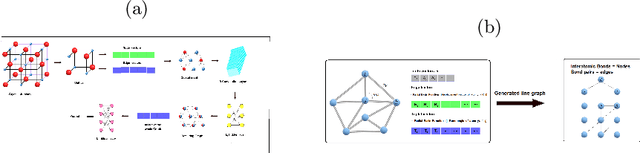
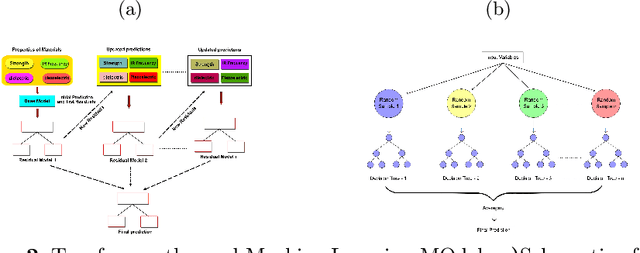
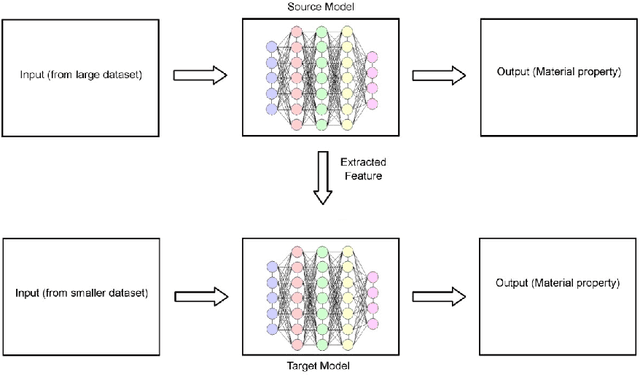
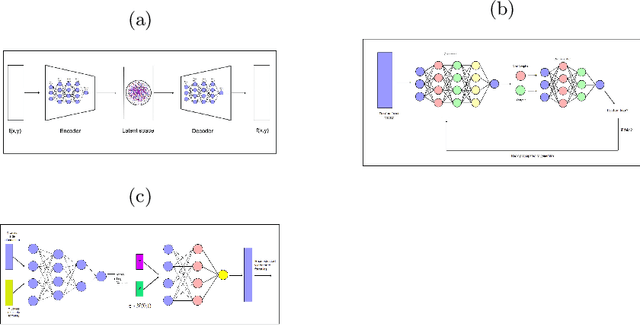
Recently, there has been extensive use of artificial Intelligence (AI) in the field of material engineering. This can be attributed to the development of high performance computing and thereby feasibility to test deep learning models with large parameters. In this article we tried to review some of the latest developments in the applications of AI in material engineering.
A Hybrid CNN-LSTM model for Video Deepfake Detection by Leveraging Optical Flow Features
Jul 28, 2022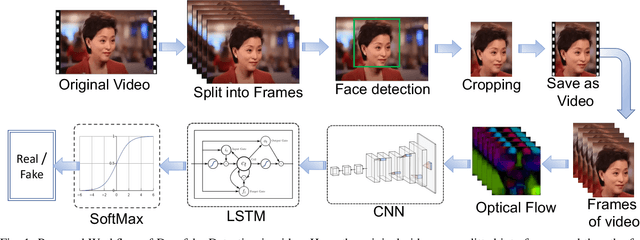

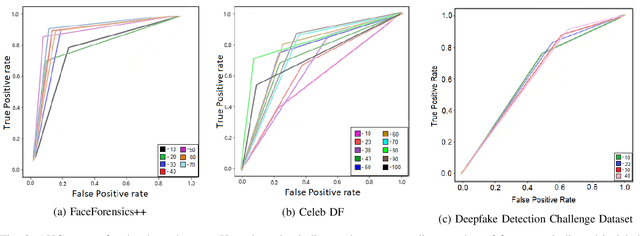
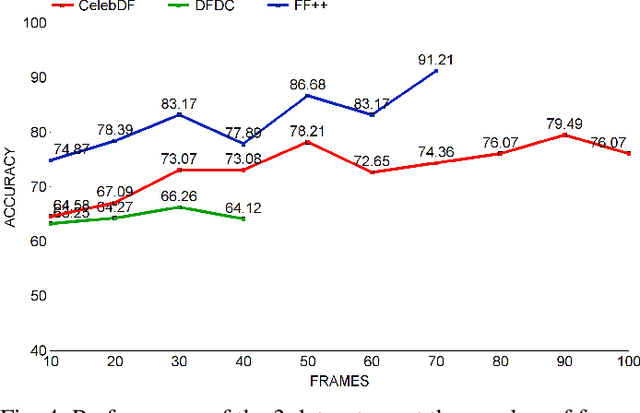
Deepfakes are the synthesized digital media in order to create ultra-realistic fake videos to trick the spectator. Deep generative algorithms, such as, Generative Adversarial Networks(GAN) are widely used to accomplish such tasks. This approach synthesizes pseudo-realistic contents that are very difficult to distinguish by traditional detection methods. In most cases, Convolutional Neural Network(CNN) based discriminators are being used for detecting such synthesized media. However, it emphasise primarily on the spatial attributes of individual video frames, thereby fail to learn the temporal information from their inter-frame relations. In this paper, we leveraged an optical flow based feature extraction approach to extract the temporal features, which are then fed to a hybrid model for classification. This hybrid model is based on the combination of CNN and recurrent neural network (RNN) architectures. The hybrid model provides effective performance on open source data-sets such as, DFDC, FF++ and Celeb-DF. This proposed method shows an accuracy of 66.26%, 91.21% and 79.49% in DFDC, FF++, and Celeb-DF respectively with a very reduced No of sample size of approx 100 samples(frames). This promises early detection of fake contents compared to existing modalities.
Modelling Social Context for Fake News Detection: A Graph Neural Network Based Approach
Jul 27, 2022
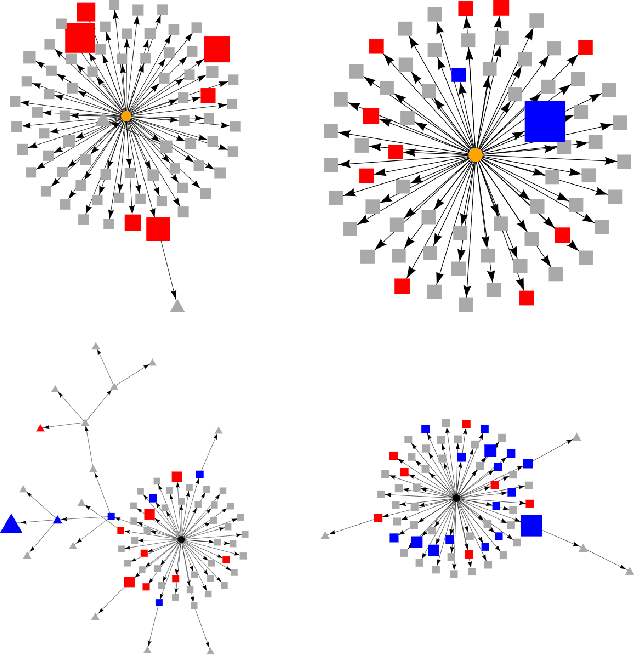
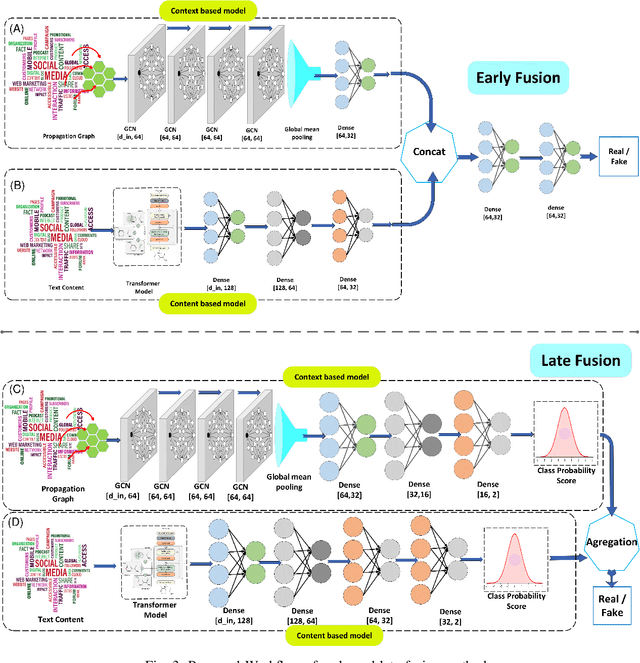
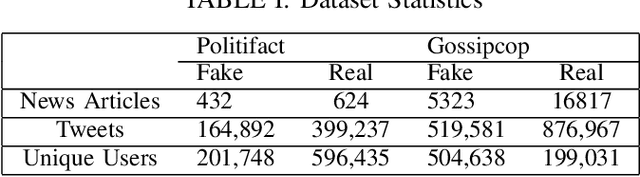
Detection of fake news is crucial to ensure the authenticity of information and maintain the news ecosystems reliability. Recently, there has been an increase in fake news content due to the recent proliferation of social media and fake content generation techniques such as Deep Fake. The majority of the existing modalities of fake news detection focus on content based approaches. However, most of these techniques fail to deal with ultra realistic synthesized media produced by generative models. Our recent studies find that the propagation characteristics of authentic and fake news are distinguishable, irrespective of their modalities. In this regard, we have investigated the auxiliary information based on social context to detect fake news. This paper has analyzed the social context of fake news detection with a hybrid graph neural network based approach. This hybrid model is based on integrating a graph neural network on the propagation of news and bi directional encoder representations from the transformers model on news content to learn the text features. Thus this proposed approach learns the content as well as the context features and hence able to outperform the baseline models with an f1 score of 0.91 on PolitiFact and 0.93 on the Gossipcop dataset, respectively
Machine learning based lens-free imaging technique for field-portable cytometry
Mar 03, 2022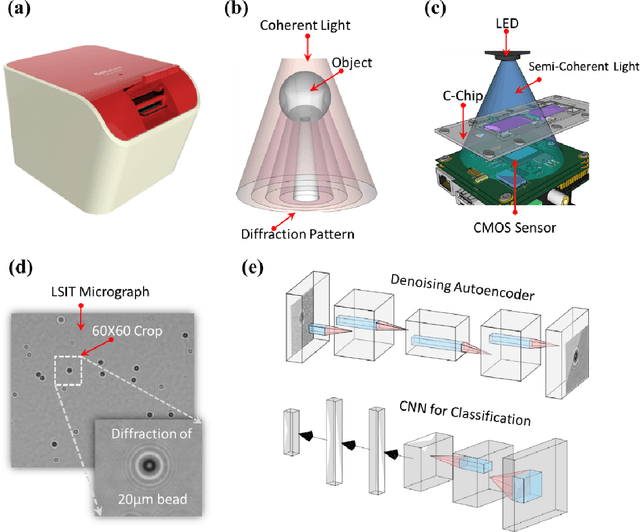
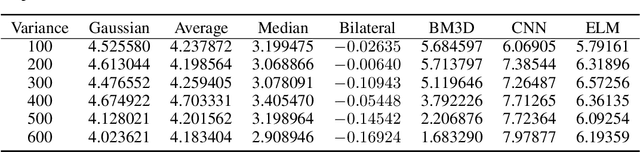


Lens-free Shadow Imaging Technique (LSIT) is a well-established technique for the characterization of microparticles and biological cells. Due to its simplicity and cost-effectiveness, various low-cost solutions have been evolved, such as automatic analysis of complete blood count (CBC), cell viability, 2D cell morphology, 3D cell tomography, etc. The developed auto characterization algorithm so far for this custom-developed LSIT cytometer was based on the hand-crafted features of the cell diffraction patterns from the LSIT cytometer, that were determined from our empirical findings on thousands of samples of individual cell types, which limit the system in terms of induction of a new cell type for auto classification or characterization. Further, its performance is suffering from poor image (cell diffraction pattern) signatures due to its small signal or background noise. In this work, we address these issues by leveraging the artificial intelligence-powered auto signal enhancing scheme such as denoising autoencoder and adaptive cell characterization technique based on the transfer of learning in deep neural networks. The performance of our proposed method shows an increase in accuracy >98% along with the signal enhancement of >5 dB for most of the cell types, such as Red Blood Cell (RBC) and White Blood Cell (WBC). Furthermore, the model is adaptive to learn new type of samples within a few learning iterations and able to successfully classify the newly introduced sample along with the existing other sample types.
* Published in Biosensors Journal
Artificial Intelligence Powered Material Search Engine
Jan 19, 2022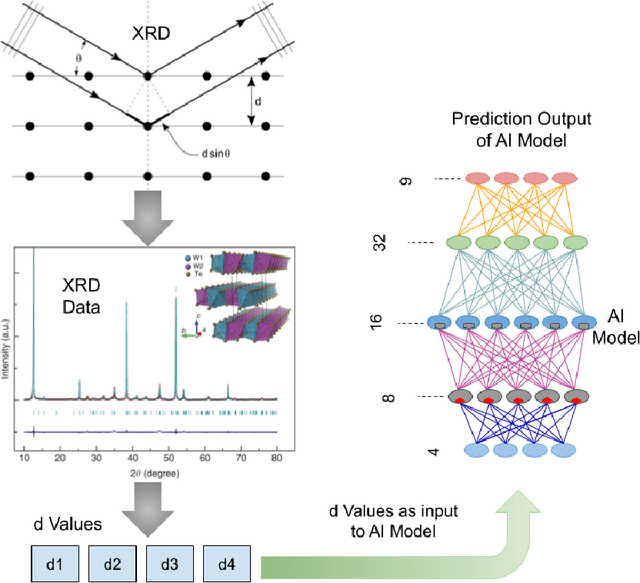

Many data-driven applications in material science have been made possible because of recent breakthroughs in artificial intelligence(AI). The use of AI in material engineering is becoming more viable as the number of material data such as X-Ray diffraction, various spectroscopy, and microscope data grows. In this work, we have reported a material search engine that uses the interatomic space (d value) from X-ray diffraction to provide material information. We have investigated various techniques for predicting prospective material using X-ray diffraction data. We used the Random Forest, Naive Bayes (Gaussian), and Neural Network algorithms to achieve this. These algorithms have an average accuracy of 88.50\%, 100.0\%, and 88.89\%, respectively. Finally, we combined all these techniques into an ensemble approach to make the prediction more generic. This ensemble method has a ~100\% accuracy rate. Furthermore, we are designing a graph neural network (GNN)-based architecture to improve interpretability and accuracy. Thus, we want to solve the computational and time complexity of traditional dictionary-based and metadata-based material search engines and to provide a more generic prediction.
* 4 pages
Glioblastoma Multiforme Patient Survival Prediction
Jan 26, 2021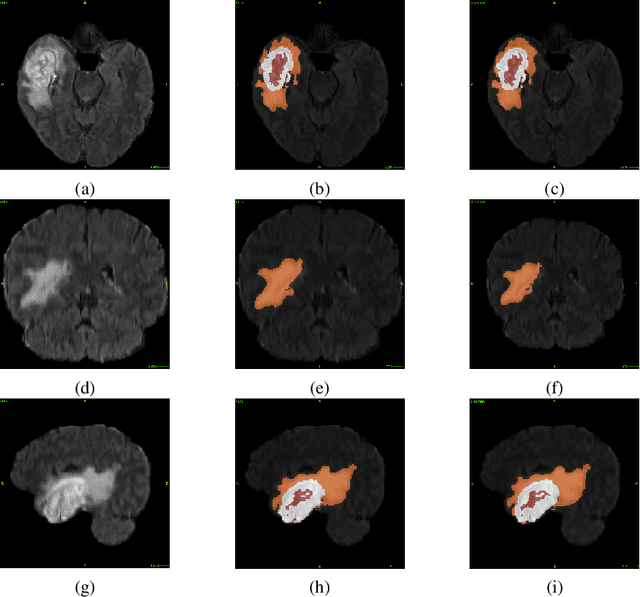
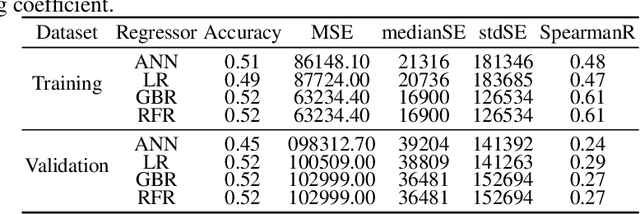

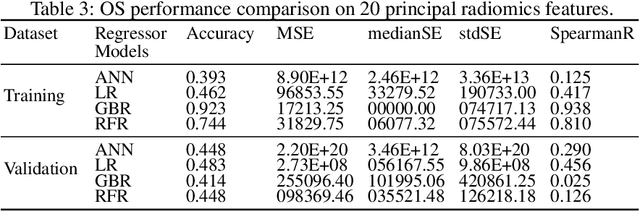
Glioblastoma Multiforme is a very aggressive type of brain tumor. Due to spatial and temporal intra-tissue inhomogeneity, location and the extent of the cancer tissue, it is difficult to detect and dissect the tumor regions. In this paper, we propose survival prognosis models using four regressors operating on handcrafted image-based and radiomics features. We hypothesize that the radiomics shape features have the highest correlation with survival prediction. The proposed approaches were assessed on the Brain Tumor Segmentation (BraTS-2020) challenge dataset. The highest accuracy of image features with random forest regressor approach was 51.5\% for the training and 51.7\% for the validation dataset. The gradient boosting regressor with shape features gave an accuracy of 91.5\% and 62.1\% on training and validation datasets respectively. It is better than the BraTS 2020 survival prediction challenge winners on the training and validation datasets. Our work shows that handcrafted features exhibit a strong correlation with survival prediction. The consensus based regressor with gradient boosting and radiomics shape features is the best combination for survival prediction.
* 10 pages, 9 figures