 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Look Wide and Interpret Twice: Improving Performance on Interactive Instruction-following Tasks
Jun 01, 2021
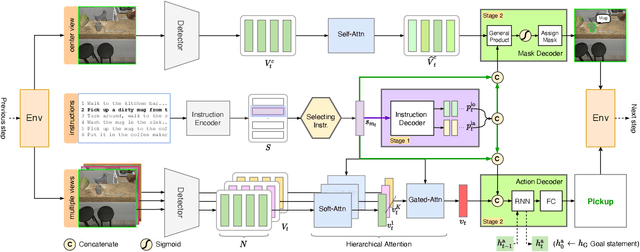
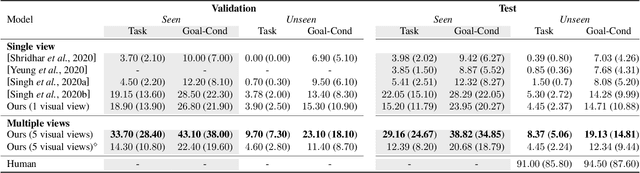
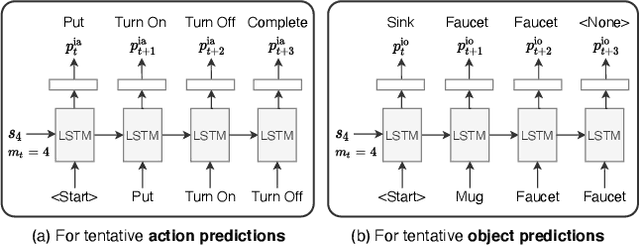
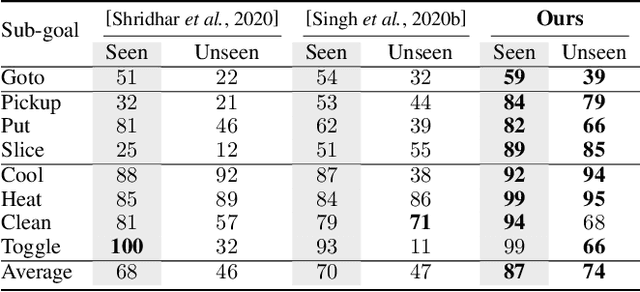
There is a growing interest in the community in making an embodied AI agent perform a complicated task while interacting with an environment following natural language directives. Recent studies have tackled the problem using ALFRED, a well-designed dataset for the task, but achieved only very low accuracy. This paper proposes a new method, which outperforms the previous methods by a large margin. It is based on a combination of several new ideas. One is a two-stage interpretation of the provided instructions. The method first selects and interprets an instruction without using visual information, yielding a tentative action sequence prediction. It then integrates the prediction with the visual information etc., yielding the final prediction of an action and an object. As the object's class to interact is identified in the first stage, it can accurately select the correct object from the input image. Moreover, our method considers multiple egocentric views of the environment and extracts essential information by applying hierarchical attention conditioned on the current instruction. This contributes to the accurate prediction of actions for navigation. A preliminary version of the method won the ALFRED Challenge 2020. The current version achieves the unseen environment's success rate of 4.45% with a single view, which is further improved to 8.37% with multiple views.
Big Plastic Masses Detection using Sentinel 2 Images
Mar 17, 2021

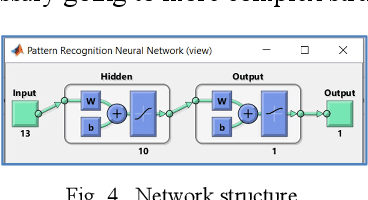
This communication describes a preliminary research on detection of big masses of plastic (marine litter) on the oceans and seas using EO (Earth Observation) satellite systems. Free images from the Sentinel 2 (Copernicus Project) platform are used. To develop a plastic recognizer, we start with an image where we can find a big accumulation of "nonfloating" plastic: Almer\'ia greenhouses. We made a test using remote sensing differential indexes, but we got much better results using all available wavelengths (thirteen frequency bands) and applying Neural Networks to that feature vector.
Classic versus deep approaches to address computer vision challenges
Jan 24, 2021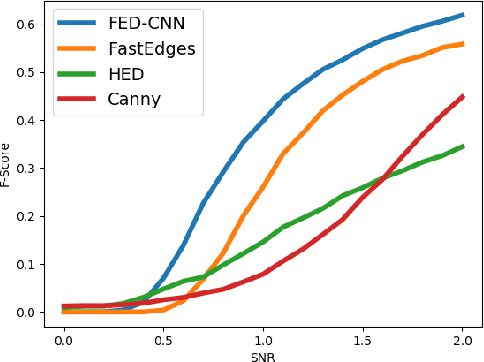
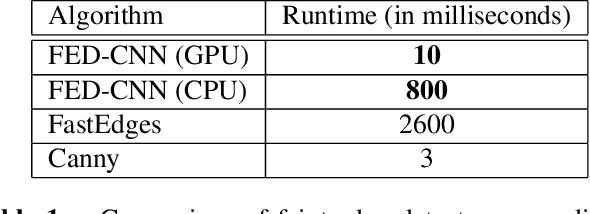

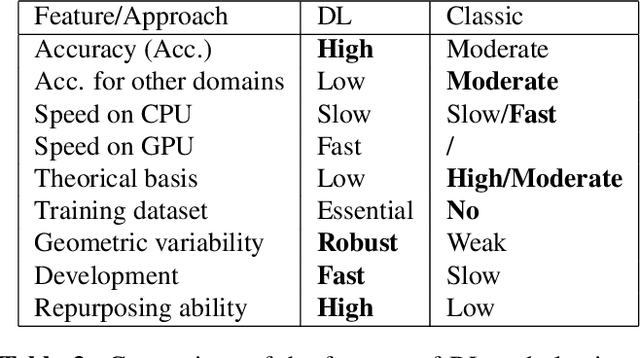
Computer vision and image processing address many challenging applications. While the last decade has seen deep neural network architectures revolutionizing those fields, early methods relied on 'classic', i.e., non-learned approaches. In this study, we explore the differences between classic and deep learning (DL) algorithms to gain new insight regarding which is more suitable for a given application. The focus is on two challenging ill-posed problems, namely faint edge detection and multispectral image registration, studying recent state-of-the-art DL and classic solutions. While those DL algorithms outperform classic methods in terms of accuracy and development time, they tend to have higher resource requirements and are unable to perform outside their training space. Moreover, classic algorithms are more transparent, which facilitates their adoption for real-life applications. As both classes of approaches have unique strengths and limitations, the choice of a solution is clearly application dependent.
Influence of Image Classification Accuracy on Saliency Map Estimation
Jul 27, 2018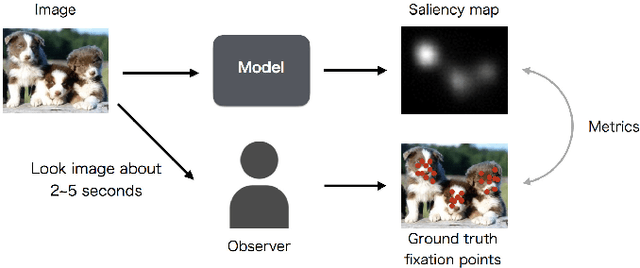
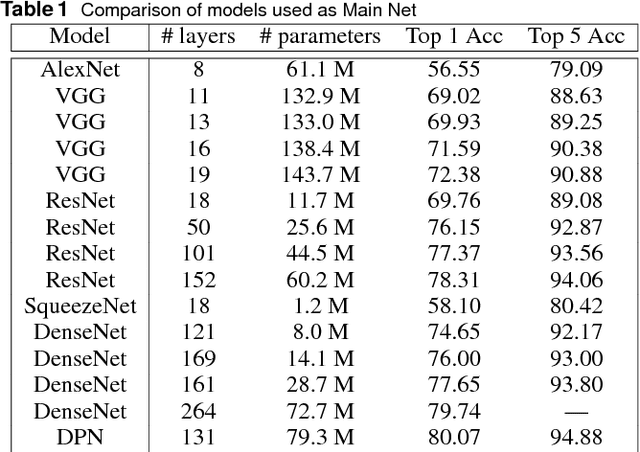
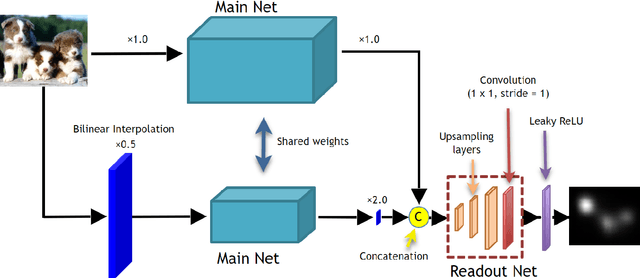
Saliency map estimation in computer vision aims to estimate the locations where people gaze in images. Since people tend to look at objects in images, the parameters of the model pretrained on ImageNet for image classification are useful for the saliency map estimation. However, there is no research on the relationship between the image classification accuracy and the performance of the saliency map estimation. In this paper, it is shown that there is a strong correlation between image classification accuracy and saliency map estimation accuracy. We also investigated the effective architecture based on multi scale images and the upsampling layers to refine the saliency-map resolution. Our model achieved the state-of-the-art accuracy on the PASCAL-S, OSIE, and MIT1003 datasets. In the MIT Saliency Benchmark, our model achieved the best performance in some metrics and competitive results in the other metrics.
SAR Image Despeckling by Deep Neural Networks: from a pre-trained model to an end-to-end training strategy
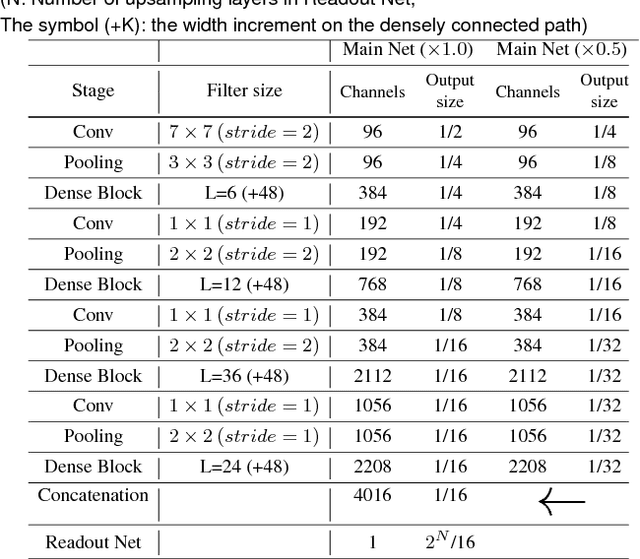
Jun 30, 2020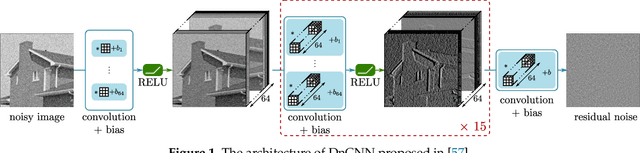
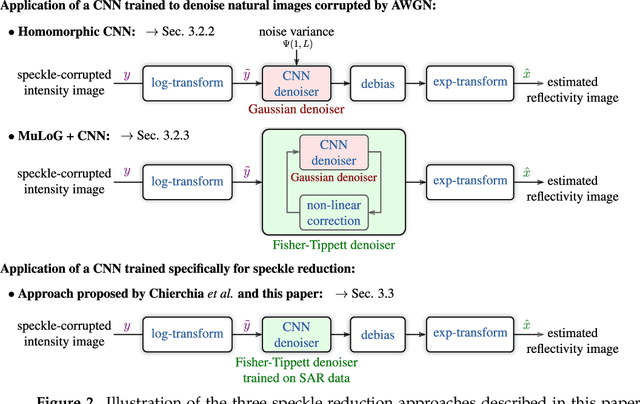
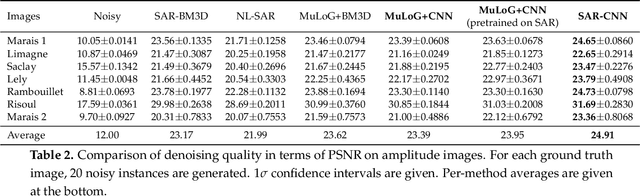
Speckle reduction is a longstanding topic in synthetic aperture radar (SAR) images. Many different schemes have been proposed for the restoration of intensity SAR images. Among the different possible approaches, methods based on convolutional neural networks (CNNs) have recently shown to reach state-of-the-art performance for SAR image restoration. CNN training requires good training data: many pairs of speckle-free / speckle-corrupted images. This is an issue in SAR applications, given the inherent scarcity of speckle-free images. To handle this problem, this paper analyzes different strategies one can adopt, depending on the speckle removal task one wishes to perform and the availability of multitemporal stacks of SAR data. The first strategy applies a CNN model, trained to remove additive white Gaussian noise from natural images, to a recently proposed SAR speckle removal framework: MuLoG (MUlti-channel LOgarithm with Gaussian denoising). No training on SAR images is performed, the network is readily applied to speckle reduction tasks. The second strategy considers a novel approach to construct a reliable dataset of speckle-free SAR images necessary to train a CNN model. Finally, a hybrid approach is also analyzed: the CNN used to remove additive white Gaussian noise is trained on speckle-free SAR images. The proposed methods are compared to other state-of-the-art speckle removal filters, to evaluate the quality of denoising and to discuss the pros and cons of the different strategies. Along with the paper, we make available the weights of the trained network to allow its usage by other researchers.
Joint Characterization of Multiscale Information in High Dimensional Data
Feb 18, 2021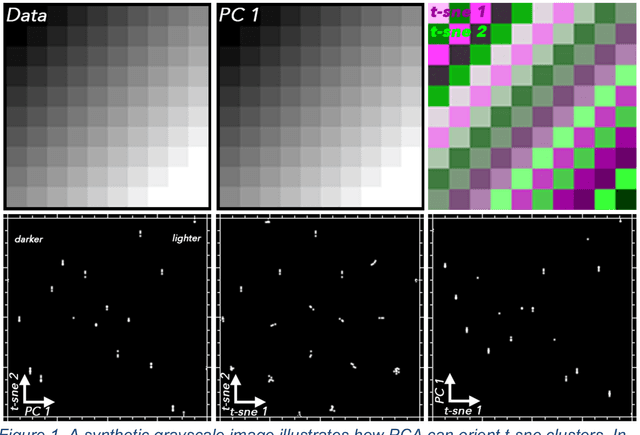
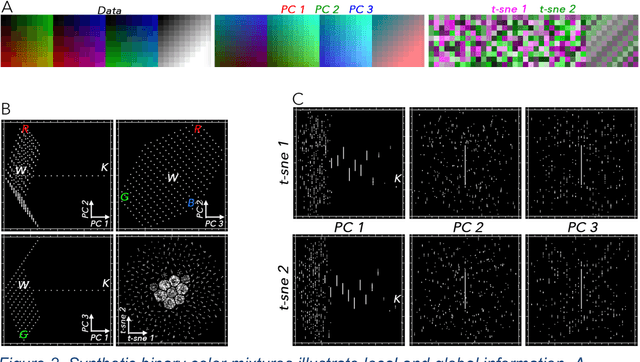
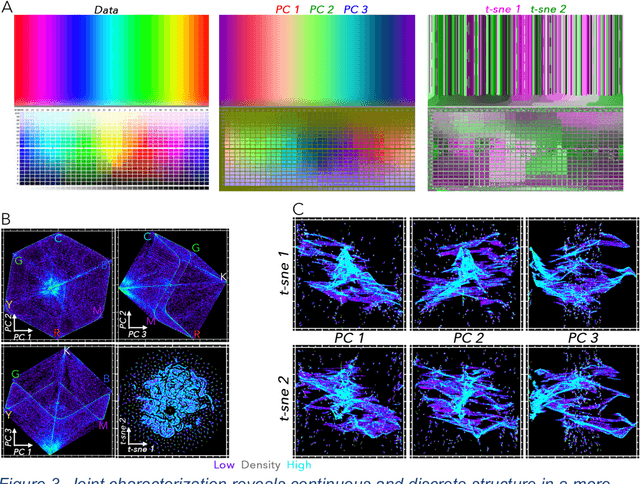
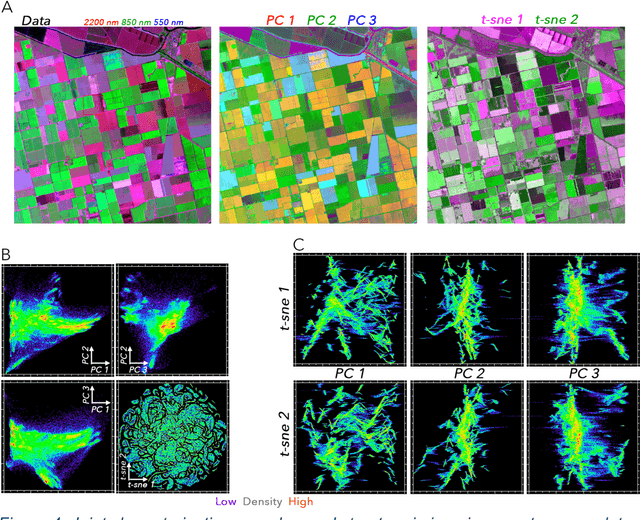
High dimensional data can contain multiple scales of variance. Analysis tools that preferentially operate at one scale can be ineffective at capturing all the information present in this cross-scale complexity. We propose a multiscale joint characterization approach designed to exploit synergies between global and local approaches to dimensionality reduction. We illustrate this approach using Principal Components Analysis (PCA) to characterize global variance structure and t-stochastic neighbor embedding (t-sne) to characterize local variance structure. Using both synthetic images and real-world imaging spectroscopy data, we show that joint characterization is capable of detecting and isolating signals which are not evident from either PCA or t-sne alone. Broadly, t-sne is effective at rendering a randomly oriented low-dimensional map of local clusters, and PCA renders this map interpretable by providing global, physically meaningful structure. This approach is illustrated using imaging spectroscopy data, and may prove particularly useful for other geospatial data given robust local variance structure due to spatial autocorrelation and physical interpretability of global variance structure due to spectral properties of Earth surface materials. However, the fundamental premise could easily be extended to other high dimensional datasets, including image time series and non-image data.
Image Dehazing using Bilinear Composition Loss Function
Oct 01, 2017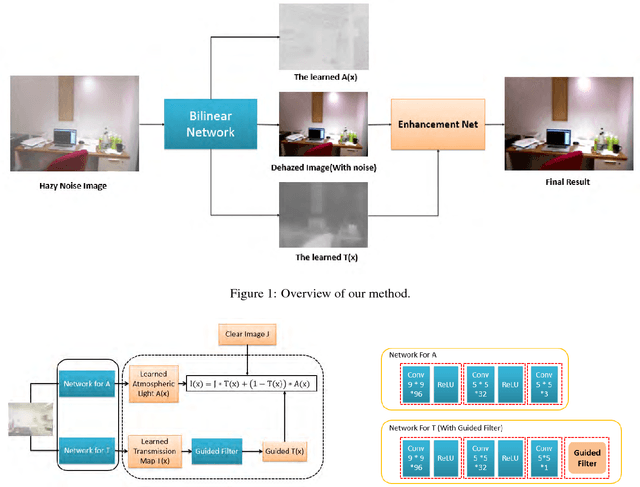



In this paper, we introduce a bilinear composition loss function to address the problem of image dehazing. Previous methods in image dehazing use a two-stage approach which first estimate the transmission map followed by clear image estimation. The drawback of a two-stage method is that it tends to boost local image artifacts such as noise, aliasing and blocking. This is especially the case for heavy haze images captured with a low quality device. Our method is based on convolutional neural networks. Unique in our method is the bilinear composition loss function which directly model the correlations between transmission map, clear image, and atmospheric light. This allows errors to be back-propagated to each sub-network concurrently, while maintaining the composition constraint to avoid overfitting of each sub-network. We evaluate the effectiveness of our proposed method using both synthetic and real world examples. Extensive experiments show that our method outperfoms state-of-the-art methods especially for haze images with severe noise level and compressions.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021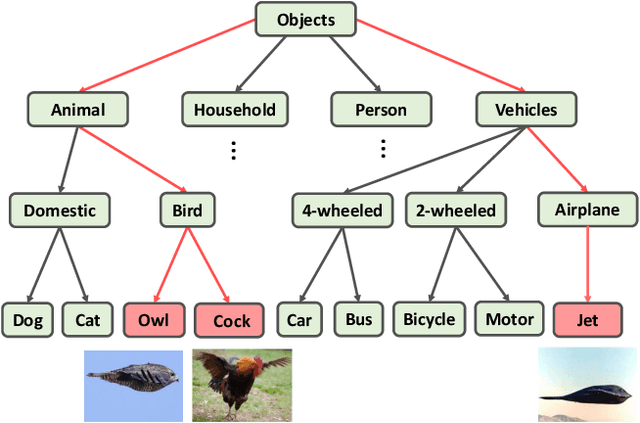
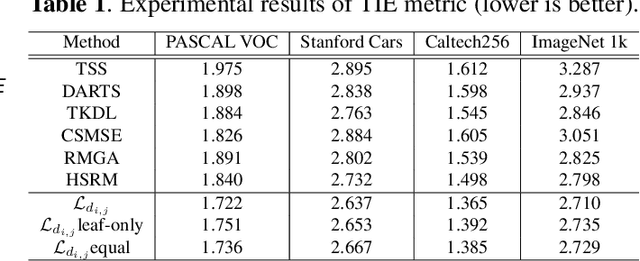
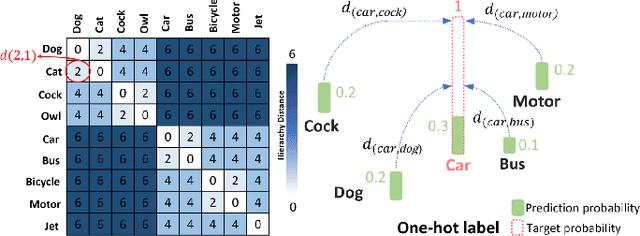
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.
Single-Pixel Compressive Imaging in Shift-Invariant Spaces via Exact Wavelet Frames
Jun 01, 2021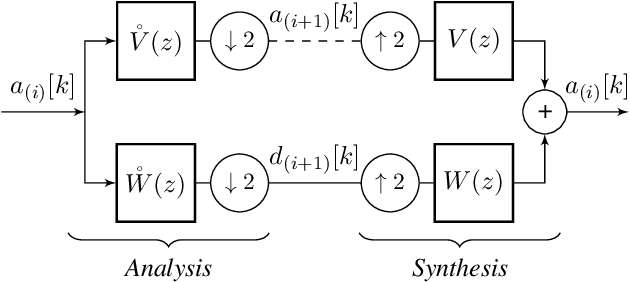


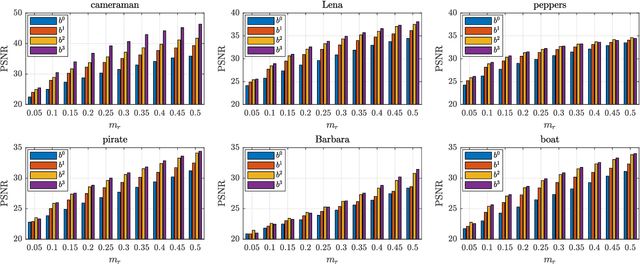
This paper introduces a novel framework for single-pixel imaging via compressive sensing (CS) in shift-invariant (SI) spaces by exploiting the sparsity property of a wavelet representation. We reinterpret the acquisition procedure of a single-pixel camera as filtering of the observed signal with continuous-domain functions that lie in an SI subspace spanned by the integer shifts of the box function. The signal is modeled by an arbitrary SI generator whose special case is the box function, which, as we show in the paper, is conventionally used in single-pixel imaging. We propose to use separable B-spline generators which are intuitively complemented by sparsity-inducing spline wavelets. The SI models of the acquisition and the underlying signal lead to an exact discretization of an inherently continuous-domain inverse problem to a finite-dimensional problem of CS type. By solving the CS optimization problem, a parametric representation of the signal is obtained. Such a representation offers many practical advantages in image processing applications. We propose an efficient matrix-free implementation of the framework and conduct it on the standard test images and real-world measurement data. Experimental results show that the proposed framework achieves a significant improvement of the reconstruction quality relative to the conventional CS setting.
A Logical Neural Network Structure With More Direct Mapping From Logical Relations
Jun 22, 2021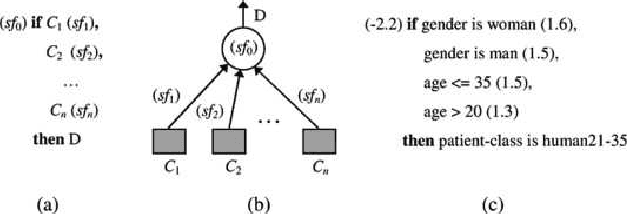
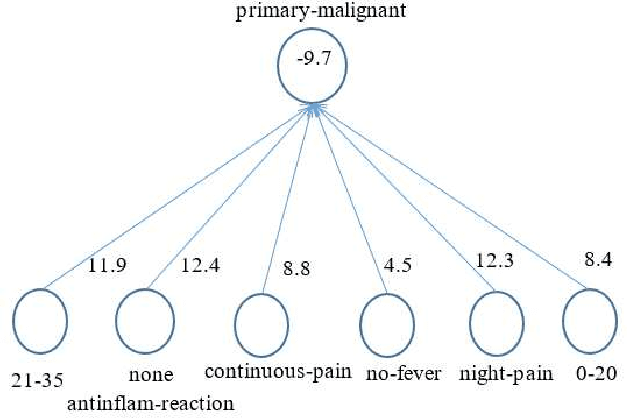
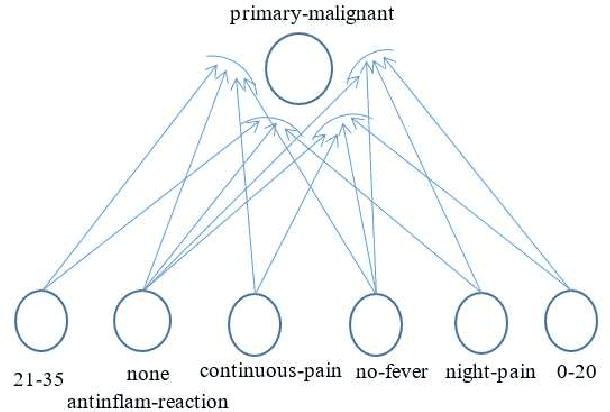
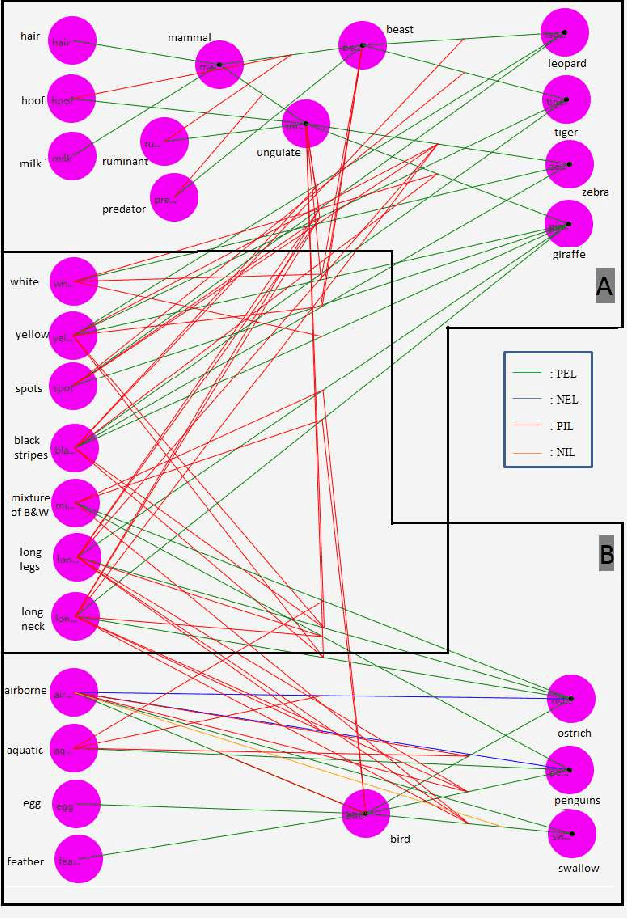
Logical relations widely exist in human activities. Human use them for making judgement and decision according to various conditions, which are embodied in the form of \emph{if-then} rules. As an important kind of cognitive intelligence, it is prerequisite of representing and storing logical relations rightly into computer systems so as to make automatic judgement and decision, especially for high-risk domains like medical diagnosis. However, current numeric ANN (Artificial Neural Network) models are good at perceptual intelligence such as image recognition while they are not good at cognitive intelligence such as logical representation, blocking the further application of ANN. To solve it, researchers have tried to design logical ANN models to represent and store logical relations. Although there are some advances in this research area, recent works still have disadvantages because the structures of these logical ANN models still don't map more directly with logical relations which will cause the corresponding logical relations cannot be read out from their network structures. Therefore, in order to represent logical relations more clearly by the neural network structure and to read out logical relations from it, this paper proposes a novel logical ANN model by designing the new logical neurons and links in demand of logical representation. Compared with the recent works on logical ANN models, this logical ANN model has more clear corresponding with logical relations using the more direct mapping method herein, thus logical relations can be read out following the connection patterns of the network structure. Additionally, less neurons are used.