 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TetraPackNet: Four-Corner-Based Object Detection in Logistics Use-Cases
Apr 19, 2021


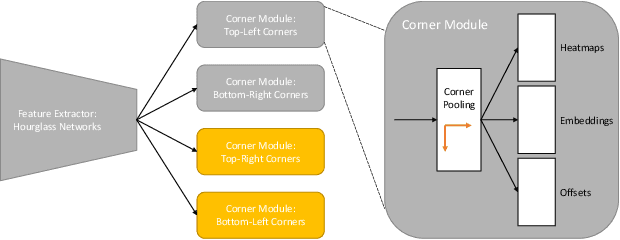

While common image object detection tasks focus on bounding boxes or segmentation masks as object representations, we propose a novel method, named TetraPackNet, using fourcorner based object representations. TetraPackNet is inspired by and based on CornerNet and uses similar base algorithms and ideas. It is designated for applications were the high-accuracy detection of regularly shaped objects is crucial, which is the case in the logistics use-case of packaging structure recognition. We evaluate our model on our specific real-world dataset for this use-case. Baselined against a previous solution, consisting of a a Mask R-CNN model and suitable post-processing steps, TetraPackNet achieves superior results (6% higher in accuracy) in the application of four-corner based transport unit side detection.
Look Wide and Interpret Twice: Improving Performance on Interactive Instruction-following Tasks
Jun 06, 2021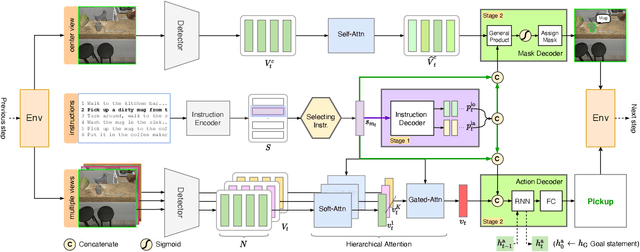
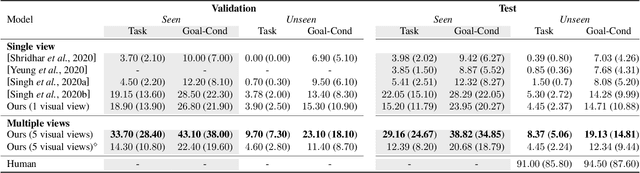
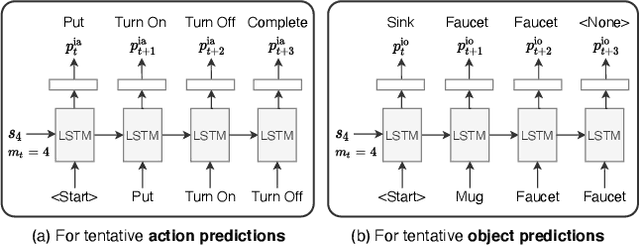
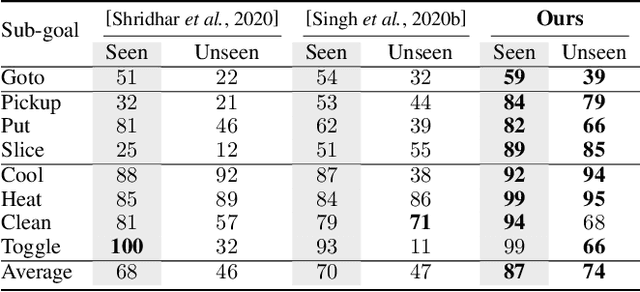
There is a growing interest in the community in making an embodied AI agent perform a complicated task while interacting with an environment following natural language directives. Recent studies have tackled the problem using ALFRED, a well-designed dataset for the task, but achieved only very low accuracy. This paper proposes a new method, which outperforms the previous methods by a large margin. It is based on a combination of several new ideas. One is a two-stage interpretation of the provided instructions. The method first selects and interprets an instruction without using visual information, yielding a tentative action sequence prediction. It then integrates the prediction with the visual information etc., yielding the final prediction of an action and an object. As the object's class to interact is identified in the first stage, it can accurately select the correct object from the input image. Moreover, our method considers multiple egocentric views of the environment and extracts essential information by applying hierarchical attention conditioned on the current instruction. This contributes to the accurate prediction of actions for navigation. A preliminary version of the method won the ALFRED Challenge 2020. The current version achieves the unseen environment's success rate of 4.45% with a single view, which is further improved to 8.37% with multiple views.
3D Convolution Neural Network based Person Identification using Gait cycles
Jun 06, 2021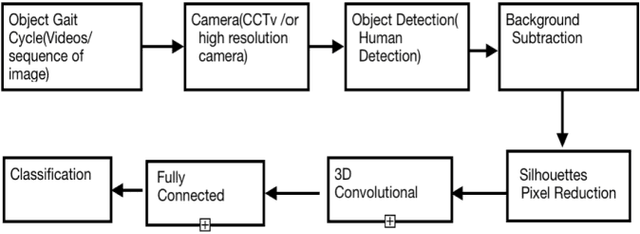

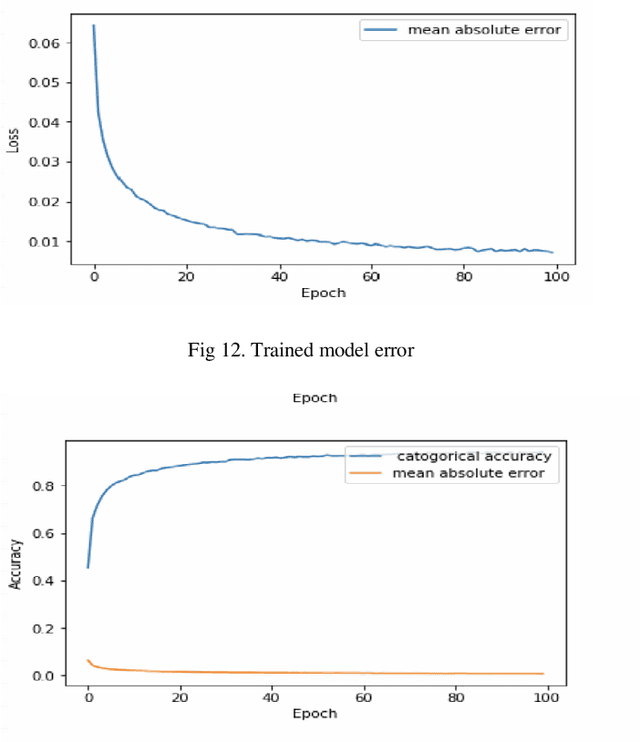
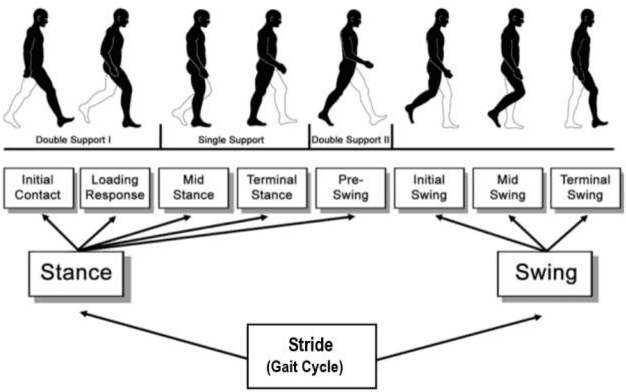
Human identification plays a prominent role in terms of security. In modern times security is becoming the key term for an individual or a country, especially for countries which are facing internal or external threats. Gait analysis is interpreted as the systematic study of the locomotive in humans. It can be used to extract the exact walking features of individuals. Walking features depends on biological as well as the physical feature of the object; hence, it is unique to every individual. In this work, gait features are used to identify an individual. The steps involve object detection, background subtraction, silhouettes extraction, skeletonization, and training 3D Convolution Neural Network on these gait features. The model is trained and evaluated on the dataset acquired by CASIA B Gait, which consists of 15000 videos of 124 subjects walking pattern captured from 11 different angles carrying objects such as bag and coat. The proposed method focuses more on the lower body part to extract features such as the angle between knee and thighs, hip angle, angle of contact, and many other features. The experimental results are compared with amongst accuracies of silhouettes as datasets for training and skeletonized image as training data. The results show that extracting the information from skeletonized data yields improved accuracy.
CAFE-GAN: Arbitrary Face Attribute Editing with Complementary Attention Feature
Nov 24, 2020
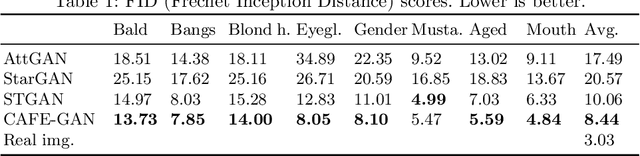

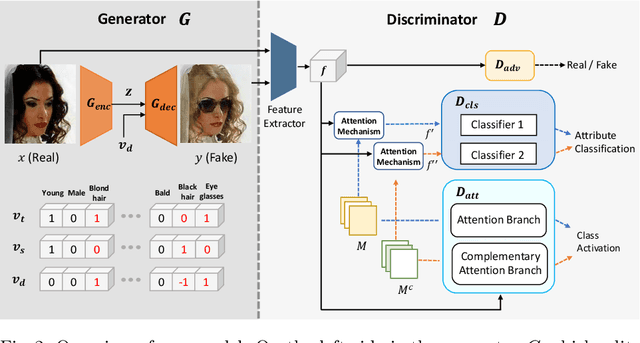
The goal of face attribute editing is altering a facial image according to given target attributes such as hair color, mustache, gender, etc. It belongs to the image-to-image domain transfer problem with a set of attributes considered as a distinctive domain. There have been some works in multi-domain transfer problem focusing on facial attribute editing employing Generative Adversarial Network (GAN). These methods have reported some successes but they also result in unintended changes in facial regions - meaning the generator alters regions unrelated to the specified attributes. To address this unintended altering problem, we propose a novel GAN model which is designed to edit only the parts of a face pertinent to the target attributes by the concept of Complementary Attention Feature (CAFE). CAFE identifies the facial regions to be transformed by considering both target attributes as well as complementary attributes, which we define as those attributes absent in the input facial image. In addition, we introduce a complementary feature matching to help in training the generator for utilizing the spatial information of attributes. Effectiveness of the proposed method is demonstrated by analysis and comparison study with state-of-the-art methods.
Unsupervised Learning of Local Discriminative Representation for Medical Images
Dec 17, 2020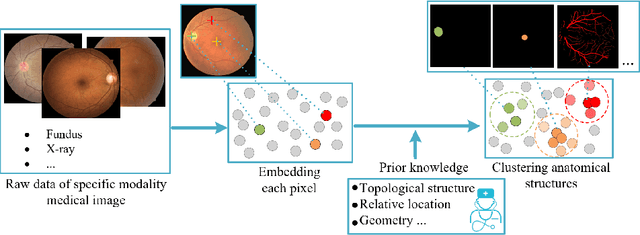
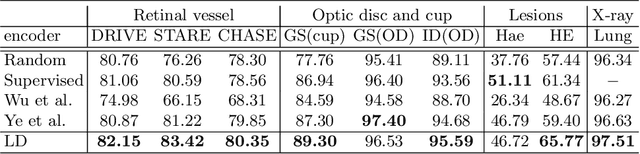
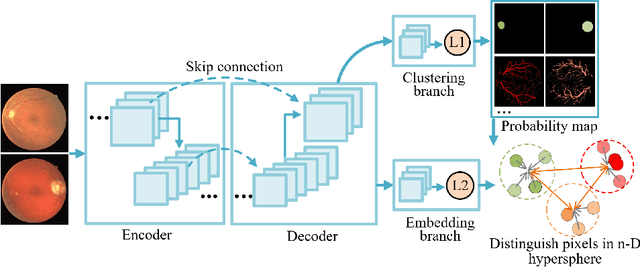
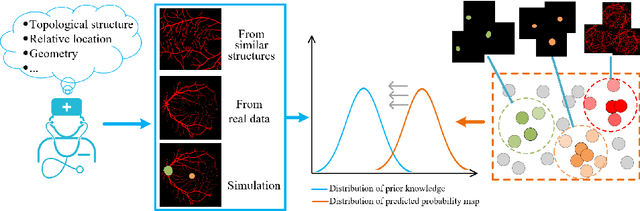
Local discriminative representation is needed in many medical image analysis tasks such as identifying sub-types of lesion or segmenting detailed components of anatomical structures by measuring similarity of local image regions. However, the commonly applied supervised representation learning methods require a large amount of annotated data, and unsupervised discriminative representation learning distinguishes different images by learning a global feature. In order to avoid the limitations of these two methods and be suitable for localized medical image analysis tasks, we introduce local discrimination into unsupervised representation learning in this work. The model contains two branches: one is an embedding branch which learns an embedding function to disperse dissimilar pixels over a low-dimensional hypersphere; and the other is a clustering branch which learns a clustering function to classify similar pixels into the same cluster. These two branches are trained simultaneously in a mutually beneficial pattern, and the learnt local discriminative representations are able to well measure the similarity of local image regions. These representations can be transferred to enhance various downstream tasks. Meanwhile, they can also be applied to cluster anatomical structures from unlabeled medical images under the guidance of topological priors from simulation or other structures with similar topological characteristics. The effectiveness and usefulness of the proposed method are demonstrated by enhancing various downstream tasks and clustering anatomical structures in retinal images and chest X-ray images. The corresponding code is available at https://github.com/HuaiChen-1994/LDLearning.
Submodular Mutual Information for Targeted Data Subset Selection
Apr 30, 2021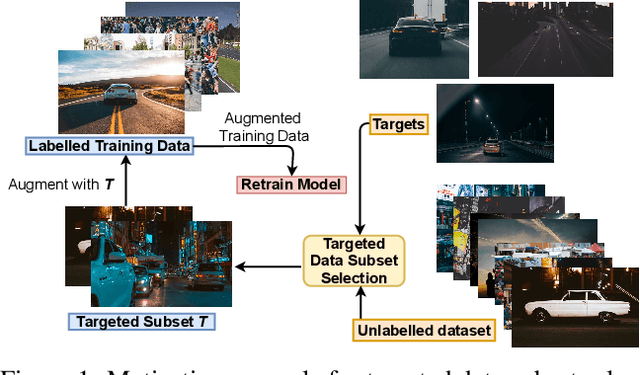
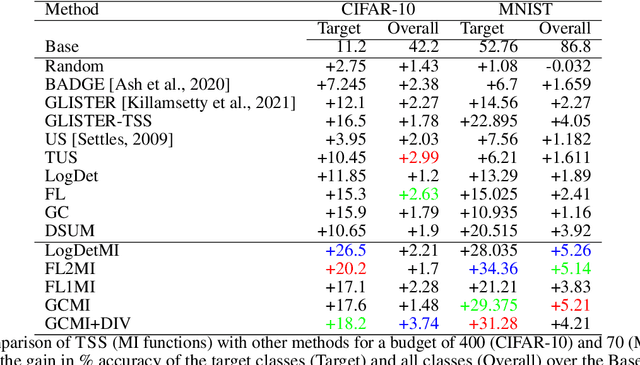
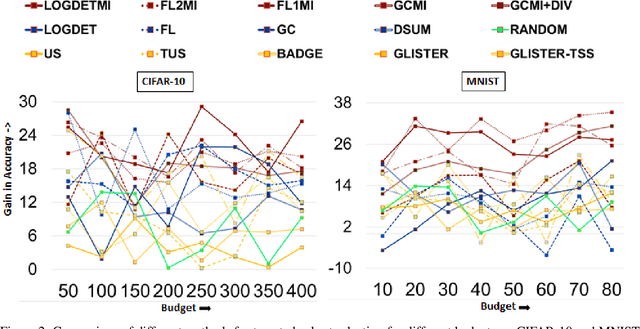
With the rapid growth of data, it is becoming increasingly difficult to train or improve deep learning models with the right subset of data. We show that this problem can be effectively solved at an additional labeling cost by targeted data subset selection(TSS) where a subset of unlabeled data points similar to an auxiliary set are added to the training data. We do so by using a rich class of Submodular Mutual Information (SMI) functions and demonstrate its effectiveness for image classification on CIFAR-10 and MNIST datasets. Lastly, we compare the performance of SMI functions for TSS with other state-of-the-art methods for closely related problems like active learning. Using SMI functions, we observe ~20-30% gain over the model's performance before re-training with added targeted subset; ~12% more than other methods.
Convolutional Block Design for Learned Fractional Downsampling
May 20, 2021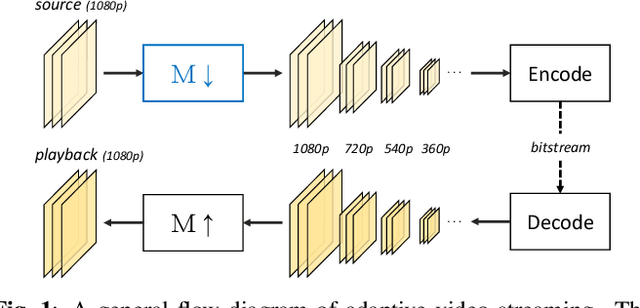
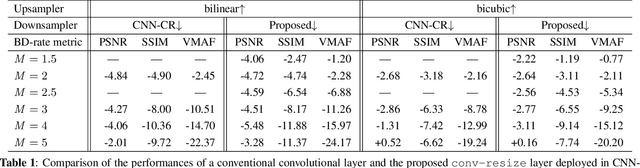
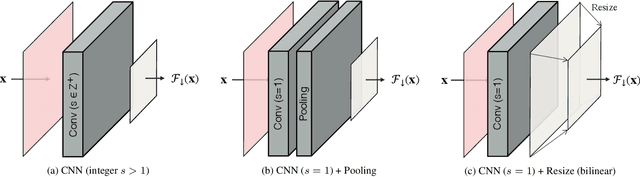
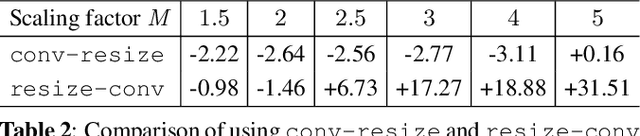
The layers of convolutional neural networks (CNNs) can be used to alter the resolution of their inputs, but the scaling factors are limited to integer values. However, in many image and video processing applications, the ability to resize by a fractional factor would be advantageous. One example is conversion between resolutions standardized for video compression, such as from 1080p to 720p. To solve this problem, we propose an alternative building block, formulated as a conventional convolutional layer followed by a differentiable resizer. More concretely, the convolutional layer preserves the resolution of the input, while the resizing operation is fully handled by the resizer. In this way, any CNN architecture can be adapted for non-integer resizing. As an application, we replace the resizing convolutional layer of a modern deep downsampling model by the proposed building block, and apply it to an adaptive bitrate video streaming scenario. Our experimental results show that an improvement in coding efficiency over the conventional Lanczos algorithm is attained, in terms of PSNR, SSIM, and VMAF on test videos.
LM-Reloc: Levenberg-Marquardt Based Direct Visual Relocalization
Oct 13, 2020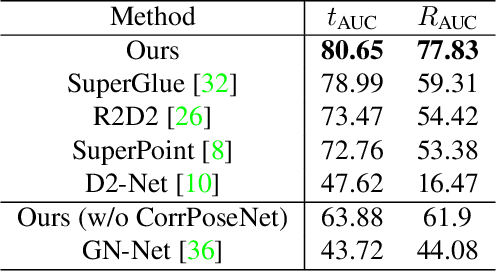
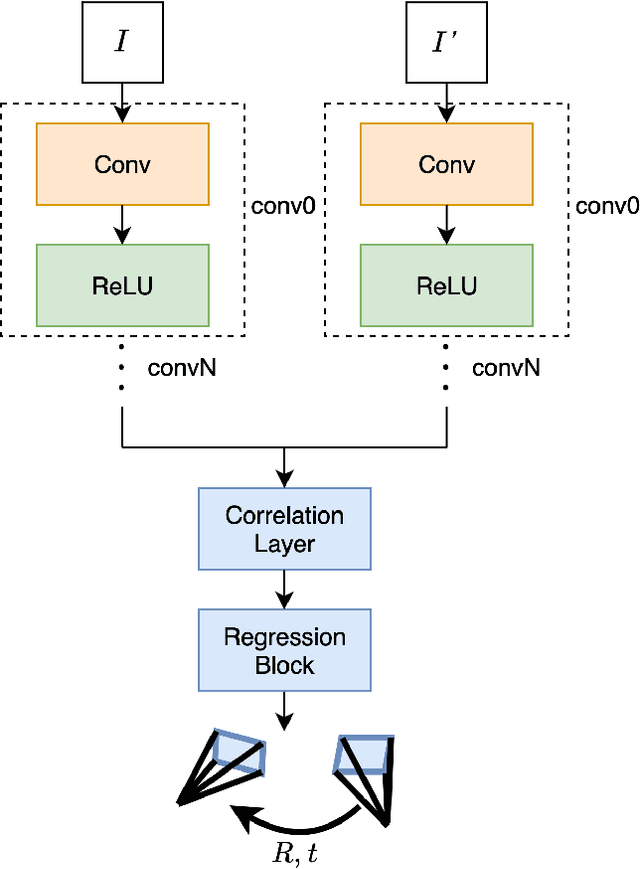
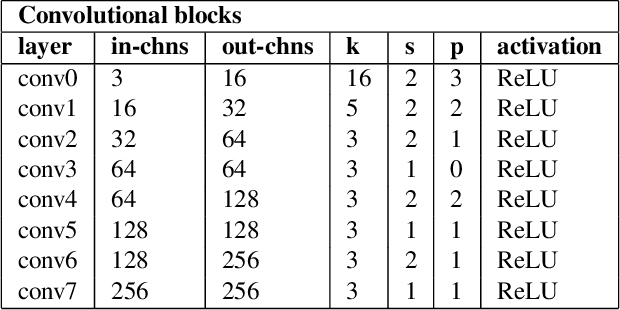
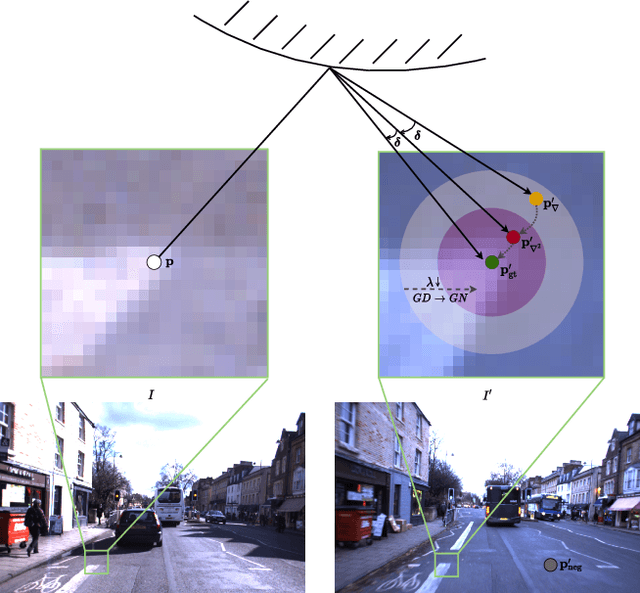
We present LM-Reloc -- a novel approach for visual relocalization based on direct image alignment. In contrast to prior works that tackle the problem with a feature-based formulation, the proposed method does not rely on feature matching and RANSAC. Hence, the method can utilize not only corners but any region of the image with gradients. In particular, we propose a loss formulation inspired by the classical Levenberg-Marquardt algorithm to train LM-Net. The learned features significantly improve the robustness of direct image alignment, especially for relocalization across different conditions. To further improve the robustness of LM-Net against large image baselines, we propose a pose estimation network, CorrPoseNet, which regresses the relative pose to bootstrap the direct image alignment. Evaluations on the CARLA and Oxford RobotCar relocalization tracking benchmark show that our approach delivers more accurate results than previous state-of-the-art methods while being comparable in terms of robustness.
Deep Matching Prior: Test-Time Optimization for Dense Correspondence
Jun 06, 2021
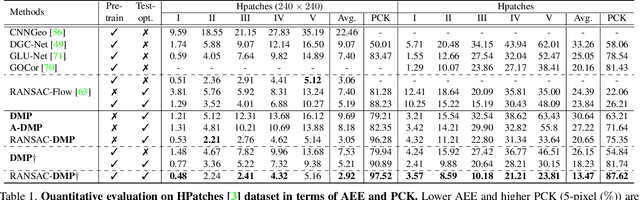
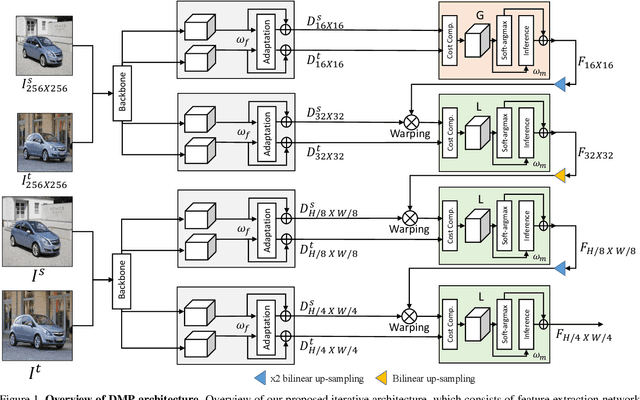
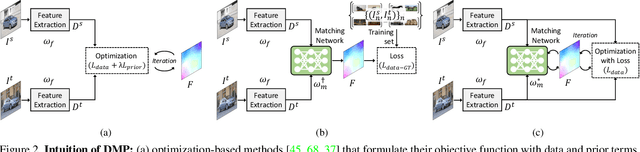
Conventional techniques to establish dense correspondences across visually or semantically similar images focused on designing a task-specific matching prior, which is difficult to model. To overcome this, recent learning-based methods have attempted to learn a good matching prior within a model itself on large training data. The performance improvement was apparent, but the need for sufficient training data and intensive learning hinders their applicability. Moreover, using the fixed model at test time does not account for the fact that a pair of images may require their own prior, thus providing limited performance and poor generalization to unseen images. In this paper, we show that an image pair-specific prior can be captured by solely optimizing the untrained matching networks on an input pair of images. Tailored for such test-time optimization for dense correspondence, we present a residual matching network and a confidence-aware contrastive loss to guarantee a meaningful convergence. Experiments demonstrate that our framework, dubbed Deep Matching Prior (DMP), is competitive, or even outperforms, against the latest learning-based methods on several benchmarks for geometric matching and semantic matching, even though it requires neither large training data nor intensive learning. With the networks pre-trained, DMP attains state-of-the-art performance on all benchmarks.
Evaluation of quality measures for color quantization
Nov 25, 2020
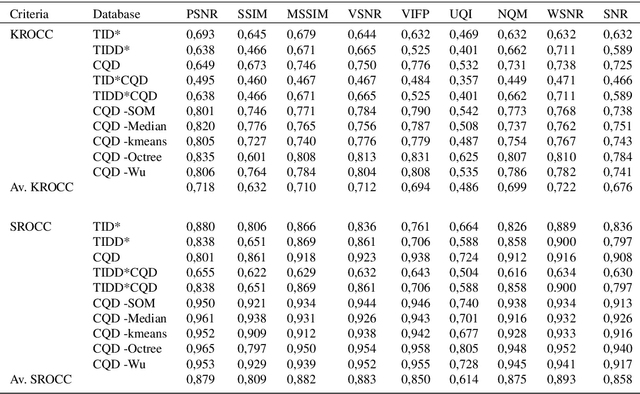
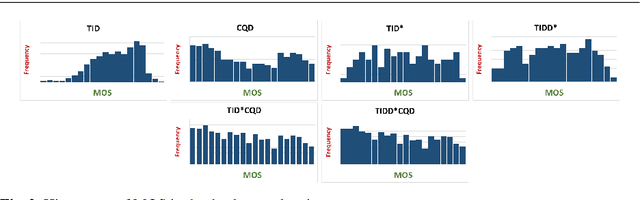
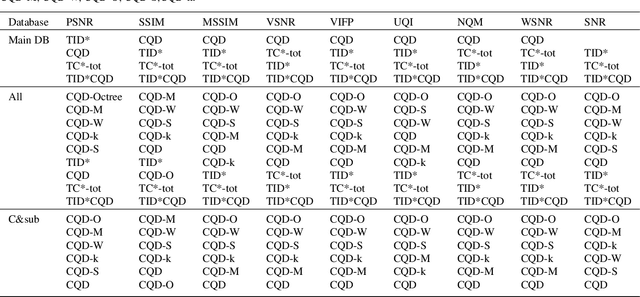
Visual quality evaluation is one of the challenging basic problems in image processing. It also plays a central role in the shaping, implementation, optimization, and testing of many methods. The existing image quality assessment methods focused on images corrupted by common degradation types while little attention was paid to color quantization. This in spite there is a wide range of applications requiring color quantization assessment being used as a preprocessing step when color-based tasks are more efficiently accomplished on a reduced number of colors. In this paper, we propose and carry-out a quantitative performance evaluation of nine well-known and commonly used full-reference image quality assessment measures. The evaluation is done by using two publicly available and subjectively rated image quality databases for color quantization degradation and by considering suitable combinations or subparts of them. The results indicate the quality measures that have closer performances in terms of their correlation to the subjective human rating and show that the evaluation of the statistical performance of the quality measures for color quantization is significantly impacted by the selected image quality database while maintaining a similar trend on each database. The detected strong similarity both on individual databases and on databases obtained by integration provides the ability to validate the integration process and to consider the quantitative performance evaluation on each database as an indicator for performance on the other databases. The experimental results are useful to address the choice of suitable quality measures for color quantization and to improve their future employment.