 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Super Resolution of Arterial Spin Labeling MR Imaging Using Unsupervised Multi-Scale Generative Adversarial Network
Sep 14, 2020
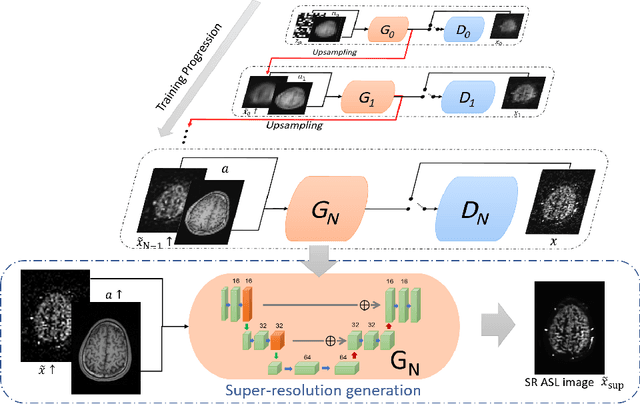
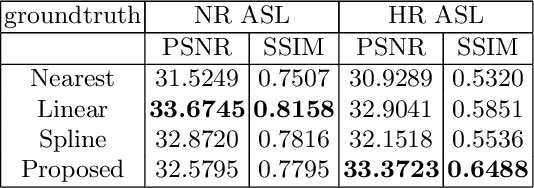
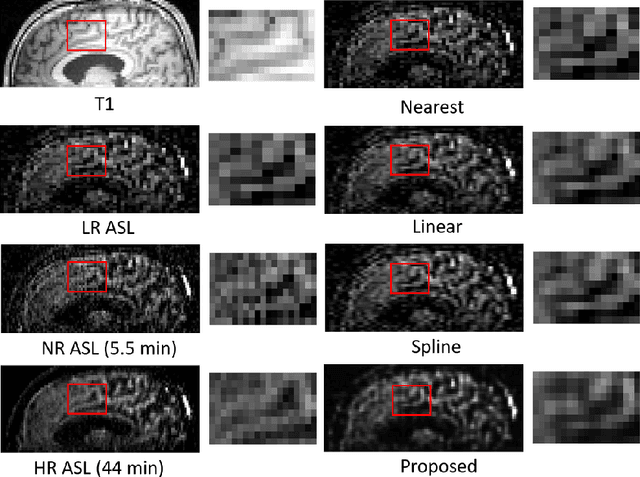
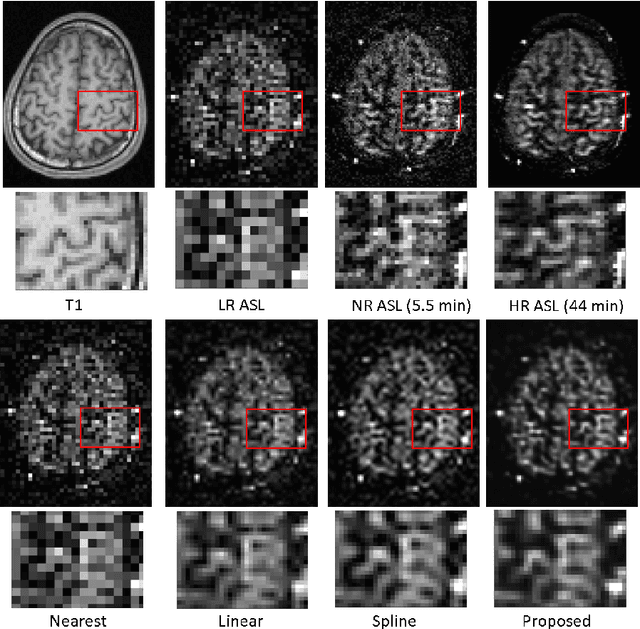
Arterial spin labeling (ASL) magnetic resonance imaging (MRI) is a powerful imaging technology that can measure cerebral blood flow (CBF) quantitatively. However, since only a small portion of blood is labeled compared to the whole tissue volume, conventional ASL suffers from low signal-to-noise ratio (SNR), poor spatial resolution, and long acquisition time. In this paper, we proposed a super-resolution method based on a multi-scale generative adversarial network (GAN) through unsupervised training. The network only needs the low-resolution (LR) ASL image itself for training and the T1-weighted image as the anatomical prior. No training pairs or pre-training are needed. A low-pass filter guided item was added as an additional loss to suppress the noise interference from the LR ASL image. After the network was trained, the super-resolution (SR) image was generated by supplying the upsampled LR ASL image and corresponding T1-weighted image to the generator of the last layer. Performance of the proposed method was evaluated by comparing the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) using normal-resolution (NR) ASL image (5.5 min acquisition) and high-resolution (HR) ASL image (44 min acquisition) as the ground truth. Compared to the nearest, linear, and spline interpolation methods, the proposed method recovers more detailed structure information, reduces the image noise visually, and achieves the highest PSNR and SSIM when using HR ASL image as the ground-truth.
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 12, 2020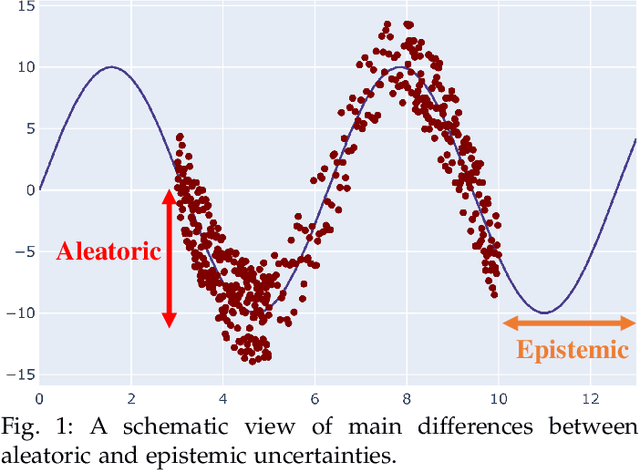
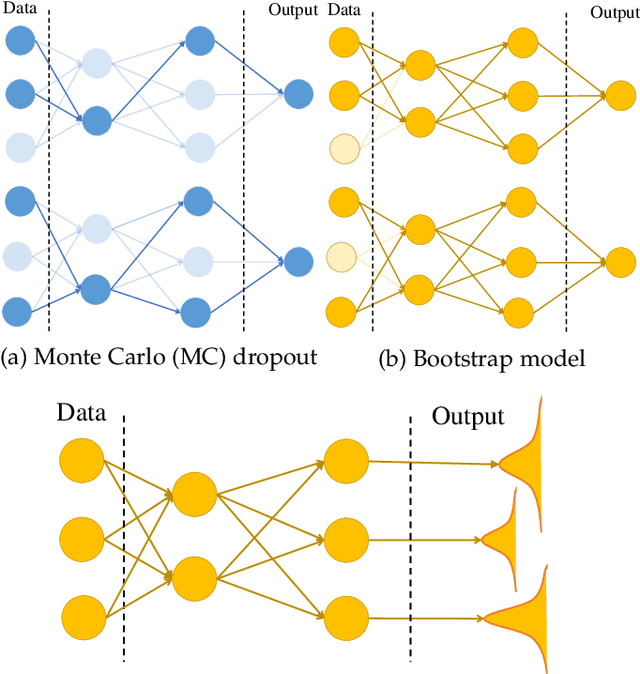
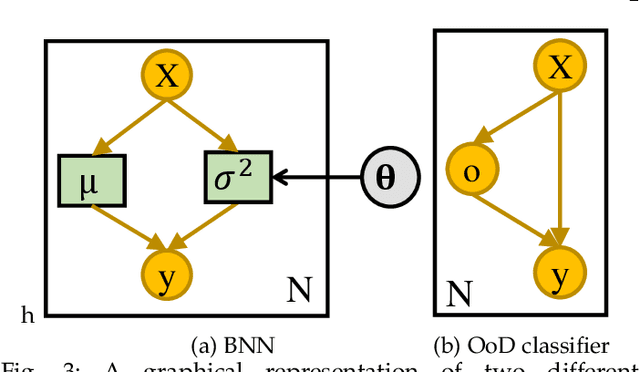
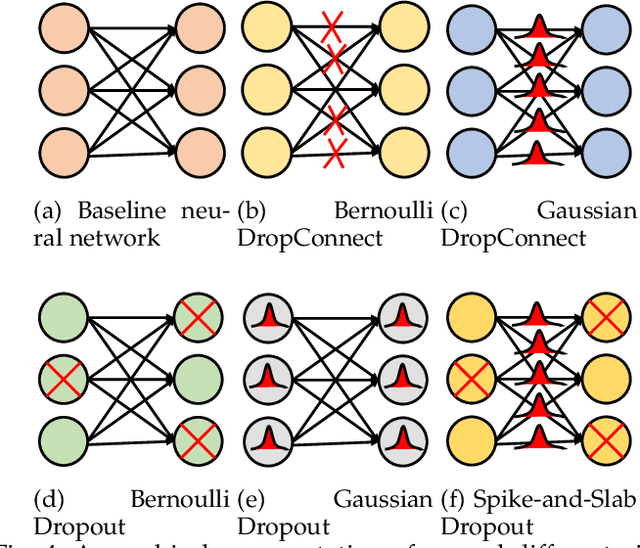
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc.This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
Communication conditions in virtual acoustic scenes in an underground station
Jun 30, 2021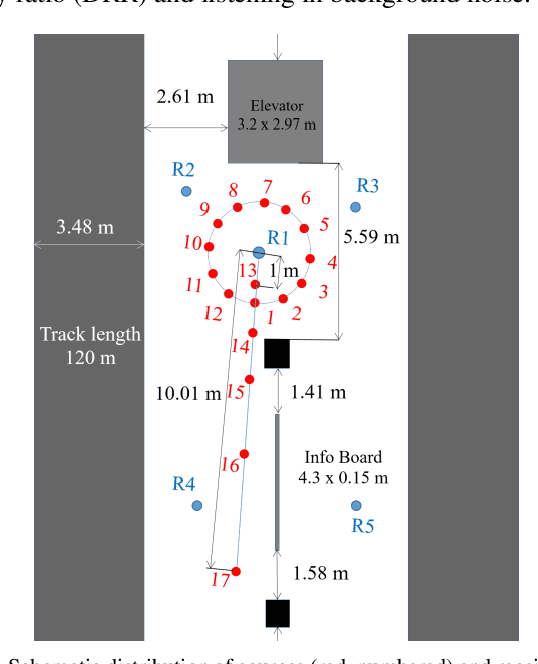
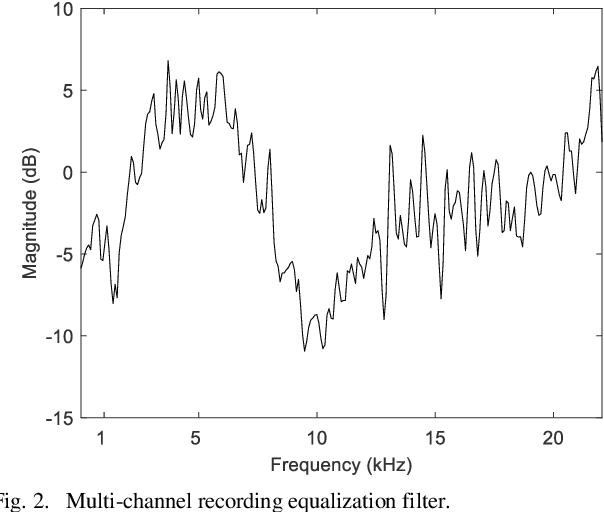
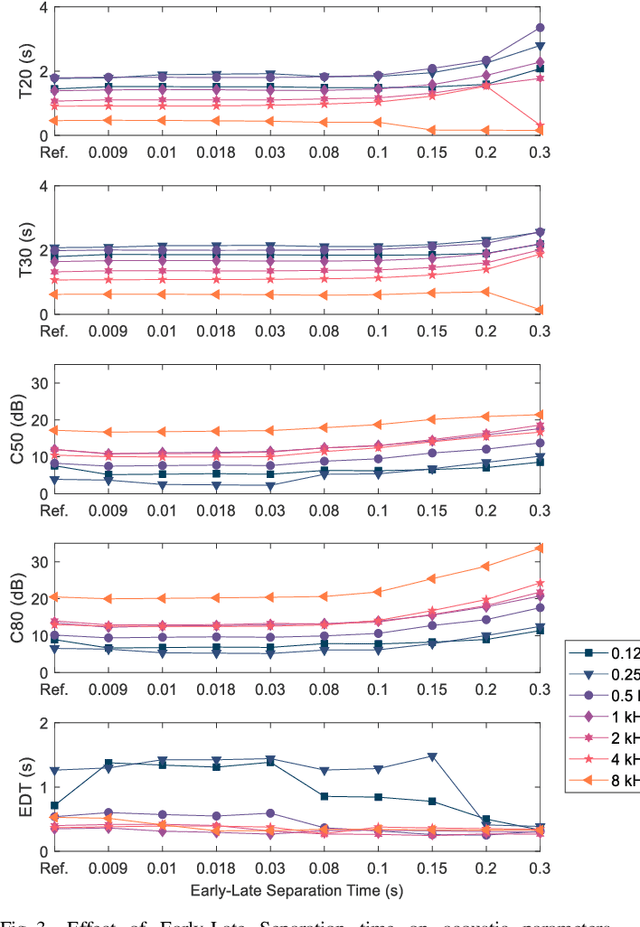
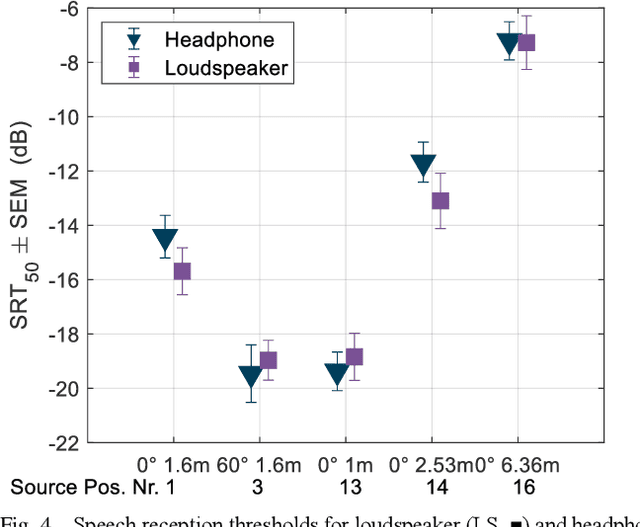
Underground stations are a common communication situation in towns: we talk with friends or colleagues, listen to announcements or shop for titbits while background noise and reverberation are challenging communication. Here, we perform an acoustical analysis of two communication scenes in an underground station in Munich and test speech intelligibility. The acoustical conditions were measured in the station and are compared to simulations in the real-time Simulated Open Field Environment (rtSOFE). We compare binaural room impulse responses measured with an artificial head in the station to modeled impulse responses for free-field auralization via 60 loudspeakers in the rtSOFE. We used the image source method to model early reflections and a set of multi-microphone recordings to model late reverberation. The first communication scene consists of 12 equidistant (1.6 m) horizontally spaced source positions around a listener, simulating different direction-dependent spatial unmasking conditions. The second scene mimics an approaching speaker across six radially spaced source positions (from 1 m to 10 m) with varying direct sound level and thus direct-to-reverberant energy. The acoustic parameters of the underground station show a moderate amount of reverberation (T30 in octave bands was between 2.3 s and 0.6 s and early-decay times between 1.46 s and 0.46 s). The binaural and energetic parameters of the auralization were in a close match to the measurement. Measured speech reception thresholds were within the error of the speech test, letting us to conclude that the auralized simulation reproduces acoustic and perceptually relevant parameters for speech intelligibility with high accuracy.
Feature-Align Network with Knowledge Distillation for Efficient Denoising
Mar 18, 2021
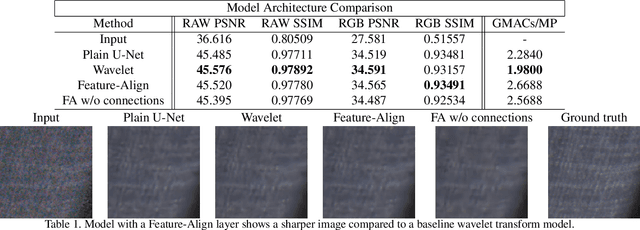
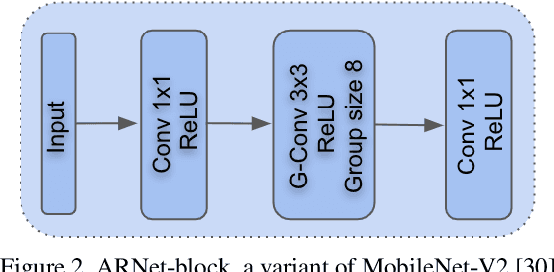
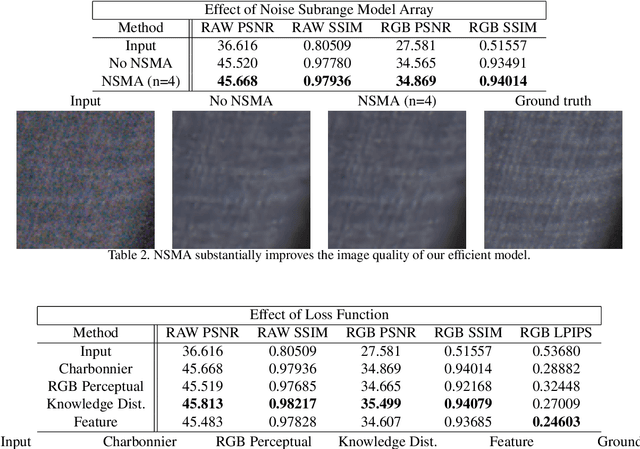
We propose an efficient neural network for RAW image denoising. Although neural network-based denoising has been extensively studied for image restoration, little attention has been given to efficient denoising for compute limited and power sensitive devices, such as smartphones and smartwatches. In this paper, we present a novel architecture and a suite of training techniques for high quality denoising in mobile devices. Our work is distinguished by three main contributions. (1) Feature-Align layer that modulates the activations of an encoder-decoder architecture with the input noisy images. The auto modulation layer enforces attention to spatially varying noise that tend to be "washed away" by successive application of convolutions and non-linearity. (2) A novel Feature Matching Loss that allows knowledge distillation from large denoising networks in the form of a perceptual content loss. (3) Empirical analysis of our efficient model trained to specialize on different noise subranges. This opens additional avenue for model size reduction by sacrificing memory for compute. Extensive experimental validation shows that our efficient model produces high quality denoising results that compete with state-of-the-art large networks, while using significantly fewer parameters and MACs. On the Darmstadt Noise Dataset benchmark, we achieve a PSNR of 48.28dB, while using 263 times fewer MACs, and 17.6 times fewer parameters than the state-of-the-art network, which achieves 49.12dB.
A selectional auto-encoder approach for document image binarization
Sep 06, 2018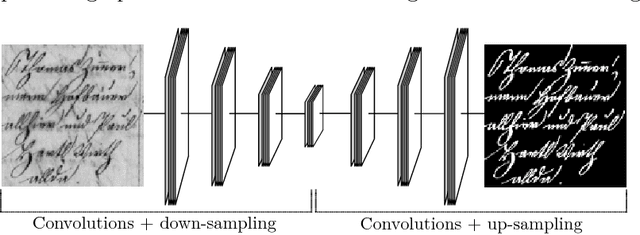
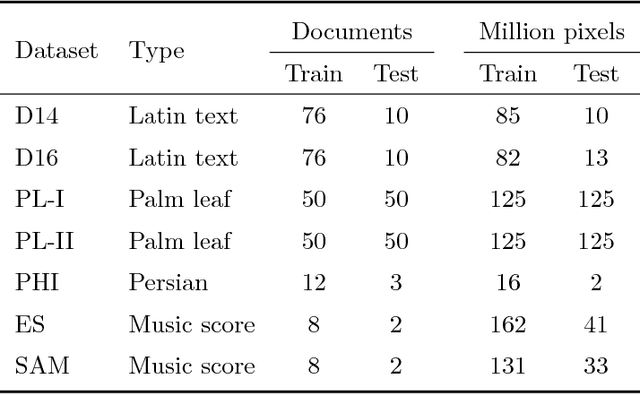

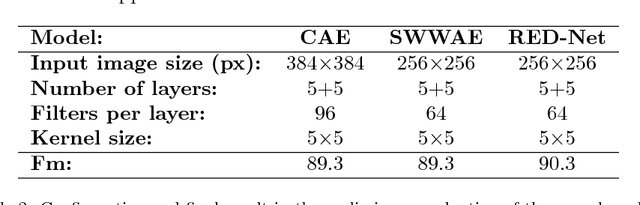
Binarization plays a key role in the automatic information retrieval from document images. This process is usually performed in the first stages of documents analysis systems, and serves as a basis for subsequent steps. Hence it has to be robust in order to allow the full analysis workflow to be successful. Several methods for document image binarization have been proposed so far, most of which are based on hand-crafted image processing strategies. Recently, Convolutional Neural Networks have shown an amazing performance in many disparate duties related to computer vision. In this paper we discuss the use of convolutional auto-encoders devoted to learning an end-to-end map from an input image to its selectional output, in which activations indicate the likelihood of pixels to be either foreground or background. Once trained, documents can therefore be binarized by parsing them through the model and applying a threshold. This approach has proven to outperform existing binarization strategies in a number of document domains.
Efficient DWT-based fusion techniques using genetic algorithm for optimal parameter estimation
Sep 22, 2020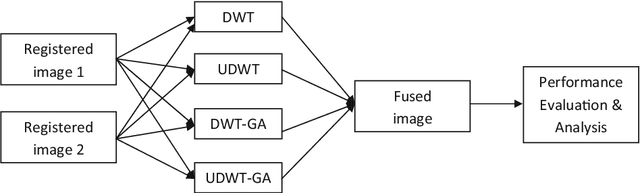

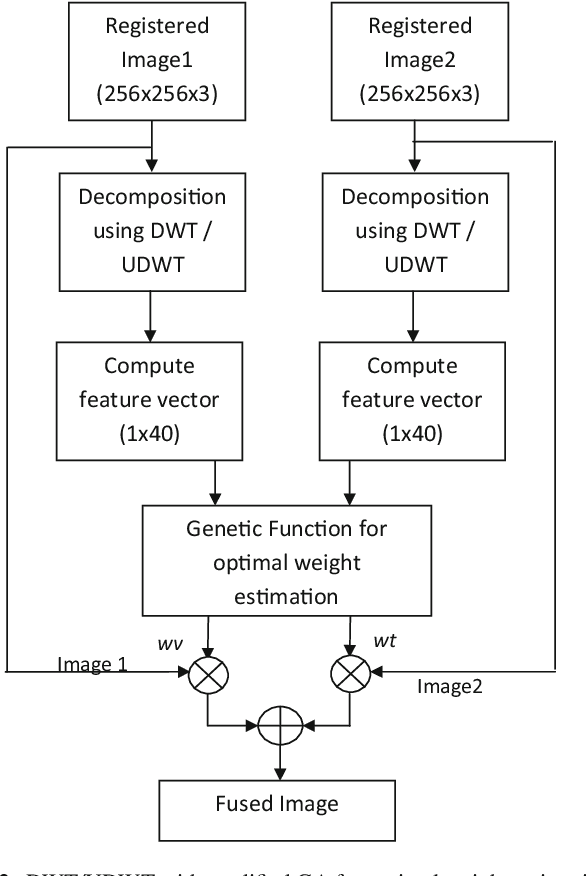
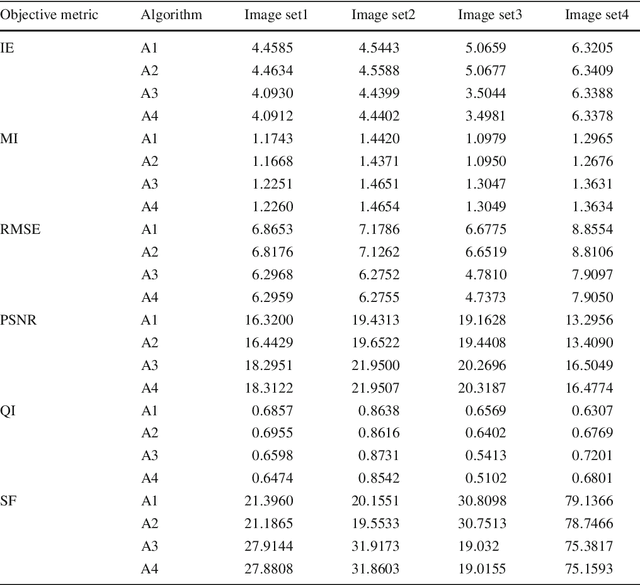
Image fusion plays a vital role in medical imaging. Image fusion aims to integrate complementary as well as redundant information from multiple modalities into a single fused image without distortion or loss of information. In this research work, discrete wavelet transform (DWT)and undecimated discrete wavelet transform (UDWT)-based fusion techniques using genetic algorithm (GA)foroptimalparameter(weight)estimationinthefusionprocessareimplemented and analyzed with multi-modality brain images. The lack of shift variance while performing image fusion using DWT is addressed using UDWT. The proposed fusion model uses an efficient, modified GA in DWT and UDWT for optimal parameter estimation, to improve the image quality and contrast. The complexity of the basic GA (pixel level) has been reduced in the modified GA (feature level), by limiting the search space. It is observed from our experiments that fusion using DWT and UDWT techniques with GA for optimal parameter estimation resulted in a better fused image in the aspects of retaining the information and contrast without error, both in human perception as well as evaluation using objective metrics. The contributions of this research work are (1) reduced time and space complexity in estimating the weight values using GA for fusion (2) system is scalable for input image of any size with similar time complexity, owing to feature level GA implementation and (3) identification of source image that contributes more to the fused image, from the weight values estimated.
PRICURE: Privacy-Preserving Collaborative Inference in a Multi-Party Setting
Feb 19, 2021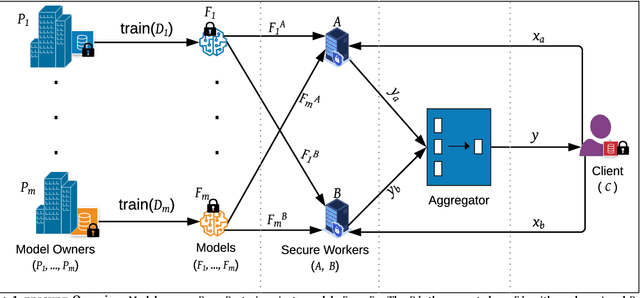

When multiple parties that deal with private data aim for a collaborative prediction task such as medical image classification, they are often constrained by data protection regulations and lack of trust among collaborating parties. If done in a privacy-preserving manner, predictive analytics can benefit from the collective prediction capability of multiple parties holding complementary datasets on the same machine learning task. This paper presents PRICURE, a system that combines complementary strengths of secure multi-party computation (SMPC) and differential privacy (DP) to enable privacy-preserving collaborative prediction among multiple model owners. SMPC enables secret-sharing of private models and client inputs with non-colluding secure servers to compute predictions without leaking model parameters and inputs. DP masks true prediction results via noisy aggregation so as to deter a semi-honest client who may mount membership inference attacks. We evaluate PRICURE on neural networks across four datasets including benchmark medical image classification datasets. Our results suggest PRICURE guarantees privacy for tens of model owners and clients with acceptable accuracy loss. We also show that DP reduces membership inference attack exposure without hurting accuracy.
Algebraic Image Processing
Oct 11, 2017We propose an approach to image processing related to algebraic operators acting in the space of images. In view of the interest in the applications in optics and computer science, mathematical aspects of the paper have been simplified as much as possible. Underlying theory, related to rigged Hilbert spaces and Lie algebras, is discussed elsewhere
SA-GAN: Structure-Aware Generative Adversarial Network for Shape-Preserving Synthetic CT Generation
May 14, 2021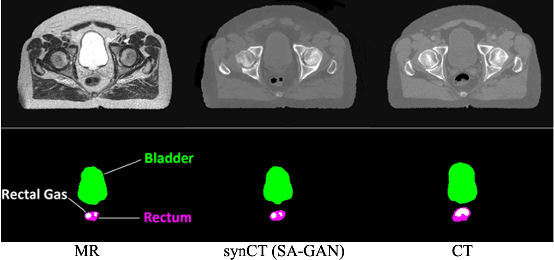

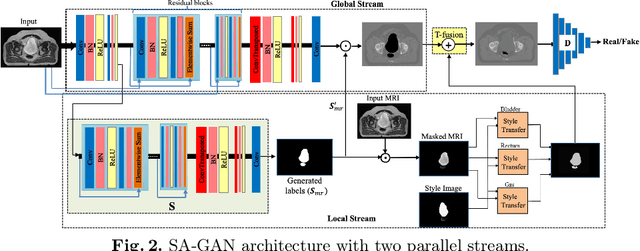
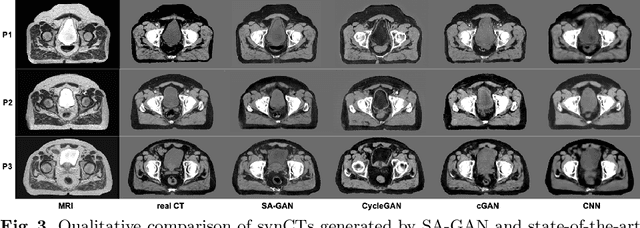
In medical image synthesis, model training could be challenging due to the inconsistencies between images of different modalities even with the same patient, typically caused by internal status/tissue changes as different modalities are usually obtained at a different time. This paper proposes a novel deep learning method, Structure-aware Generative Adversarial Network (SA-GAN), that preserves the shapes and locations of in-consistent structures when generating medical images. SA-GAN is employed to generate synthetic computed tomography (synCT) images from magnetic resonance imaging (MRI) with two parallel streams: the global stream translates the input from the MRI to the CT domain while the local stream automatically segments the inconsistent organs, maintains their locations and shapes in MRI, and translates the organ intensities to CT. Through extensive experiments on a pelvic dataset, we demonstrate that SA-GAN provides clinically acceptable accuracy on both synCTs and organ segmentation and supports MR-only treatment planning in disease sites with internal organ status changes.
Select Good Regions for Deblurring based on Convolutional Neural Networks
Aug 12, 2020
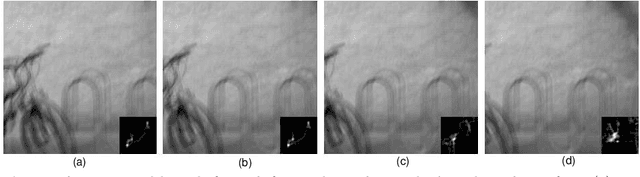


The goal of blind image deblurring is to recover sharp image from one input blurred image with an unknown blur kernel. Most of image deblurring approaches focus on developing image priors, however, there is not enough attention to the influence of image details and structures on the blur kernel estimation. What is the useful image structure and how to choose a good deblurring region? In this work, we propose a deep neural network model method for selecting good regions to estimate blur kernel. First we construct image patches with labels and train a deep neural networks, then the learned model is applied to determine which region of the image is most suitable to deblur. Experimental results illustrate that the proposed approach is effective, and could be able to select good regions for image deblurring.