 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Monocular Depth Parameterizing Networks
Dec 21, 2020

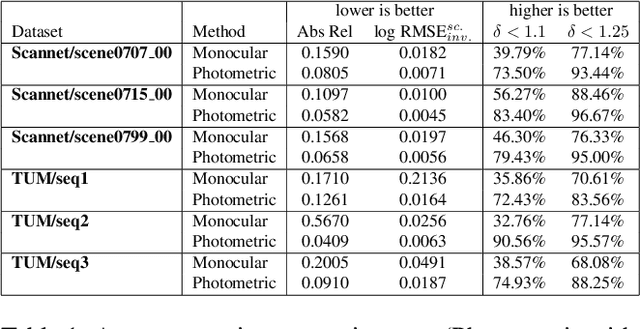
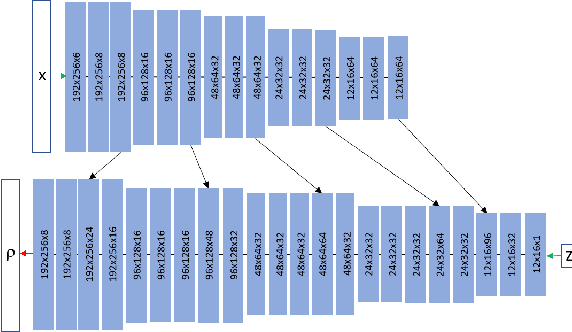
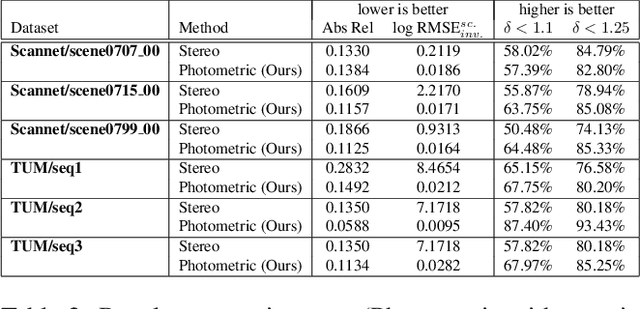
Monocular depth estimation is a highly challenging problem that is often addressed with deep neural networks. While these are able to use recognition of image features to predict reasonably looking depth maps the result often has low metric accuracy. In contrast traditional stereo methods using multiple cameras provide highly accurate estimation when pixel matching is possible. In this work we propose to combine the two approaches leveraging their respective strengths. For this purpose we propose a network structure that given an image provides a parameterization of a set of depth maps with feasible shapes. Optimizing over the parameterization then allows us to search the shapes for a photo consistent solution with respect to other images. This allows us to enforce geometric properties that are difficult to observe in single image as well as relaxes the learning problem allowing us to use relatively small networks. Our experimental evaluation shows that our method generates more accurate depth maps and generalizes better than competing state-of-the-art approaches.
A Survey on the Visual Perceptions of Gaussian Noise Filtering on Photography
Dec 18, 2020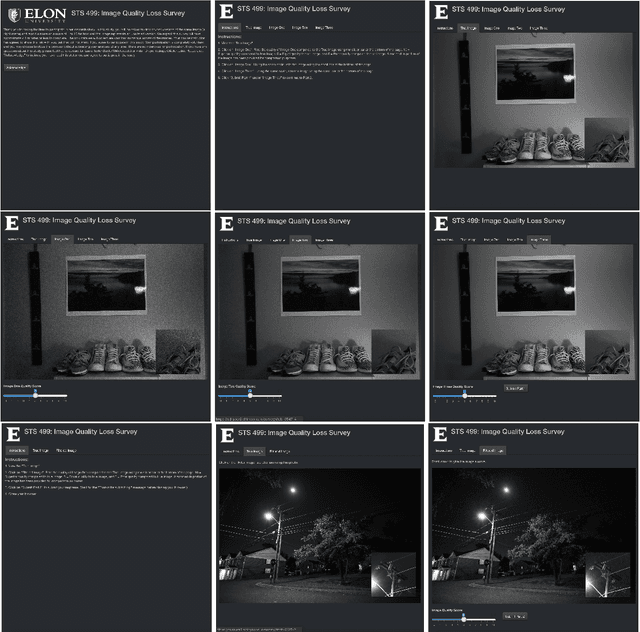



Statisticians, as well as machine learning and computer vision experts, have been studying image reconstitution through denoising different domains of photography, such as textual documentation, tomographic, astronomical, and low-light photography. In this paper, we apply common inferential kernel filters in the R and python languages, as well as Adobe Lightroom's denoise filter, and compare their effectiveness in removing noise from JPEG images. We ran standard benchmark tests to evaluate each method's effectiveness for removing noise. In doing so, we also surveyed students at Elon University about their opinion of a single filtered photo from a collection of photos processed by the various filter methods. Many scientists believe that noise filters cause blurring and image quality loss so we analyzed whether or not people felt as though denoising causes any quality loss as compared to their noiseless images. Individuals assigned scores indicating the image quality of a denoised photo compared to its noiseless counterpart on a 1 to 10 scale. Survey scores are compared across filters to evaluate whether there were significant differences in image quality scores received. Benchmark scores were compared to the visual perception scores. Then, an analysis of covariance test was run to identify whether or not survey training scores explained any unplanned variation in visual scores assigned by students across the filter methods.
Representation and Correlation Enhanced Encoder-Decoder Framework for Scene Text Recognition
Jun 13, 2021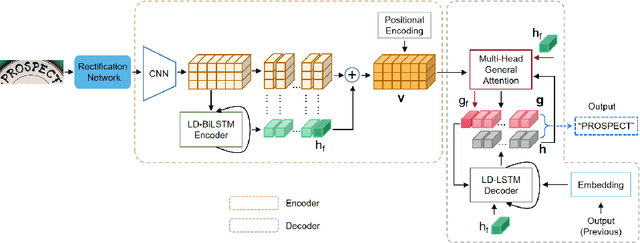
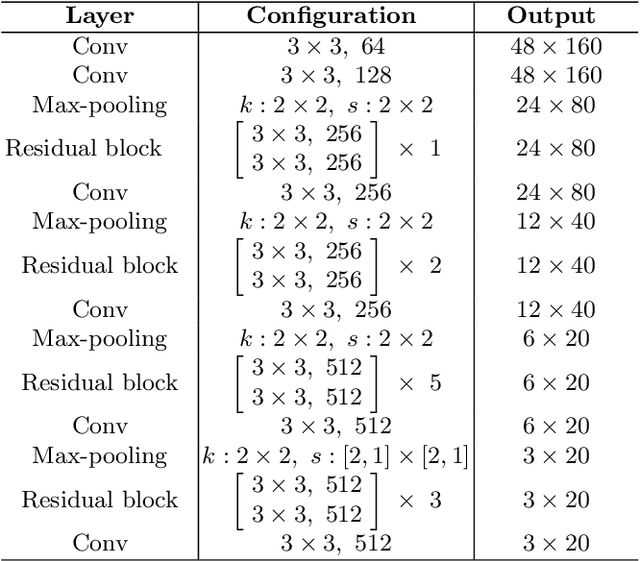

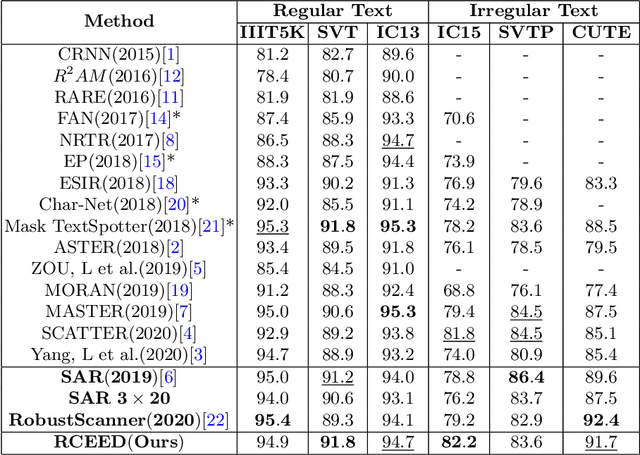
Attention-based encoder-decoder framework is widely used in the scene text recognition task. However, for the current state-of-the-art(SOTA) methods, there is room for improvement in terms of the efficient usage of local visual and global context information of the input text image, as well as the robust correlation between the scene processing module(encoder) and the text processing module(decoder). In this paper, we propose a Representation and Correlation Enhanced Encoder-Decoder Framework(RCEED) to address these deficiencies and break performance bottleneck. In the encoder module, local visual feature, global context feature, and position information are aligned and fused to generate a small-size comprehensive feature map. In the decoder module, two methods are utilized to enhance the correlation between scene and text feature space. 1) The decoder initialization is guided by the holistic feature and global glimpse vector exported from the encoder. 2) The feature enriched glimpse vector produced by the Multi-Head General Attention is used to assist the RNN iteration and the character prediction at each time step. Meanwhile, we also design a Layernorm-Dropout LSTM cell to improve model's generalization towards changeable texts. Extensive experiments on the benchmarks demonstrate the advantageous performance of RCEED in scene text recognition tasks, especially the irregular ones.
Do Not Escape From the Manifold: Discovering the Local Coordinates on the Latent Space of GANs
Jun 13, 2021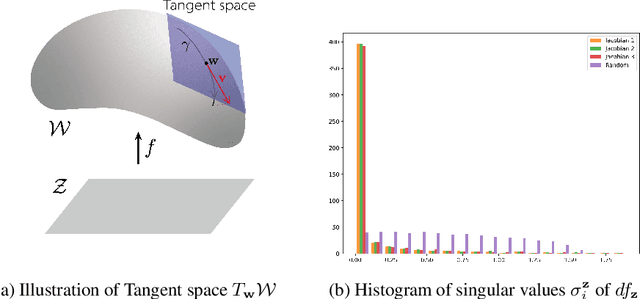



In this paper, we propose a method to find local-geometry-aware traversal directions on the intermediate latent space of Generative Adversarial Networks (GANs). These directions are defined as an ordered basis of tangent space at a latent code. Motivated by the intrinsic sparsity of the latent space, the basis is discovered by solving the low-rank approximation problem of the differential of the partial network. Moreover, the local traversal basis leads to a natural iterative traversal on the latent space. Iterative Curve-Traversal shows stable traversal on images, since the trajectory of latent code stays close to the latent space even under the strong perturbations compared to the linear traversal. This stability provides far more diverse variations of the given image. Although the proposed method can be applied to various GAN models, we focus on the W-space of the StyleGAN2, which is renowned for showing the better disentanglement of the latent factors of variation. Our quantitative and qualitative analysis provides evidence showing that the W-space is still globally warped while showing a certain degree of global consistency of interpretable variation. In particular, we introduce some metrics on the Grassmannian manifolds to quantify the global warpage of the W-space and the subspace traversal to test the stability of traversal directions.
More About Covariance Descriptors for Image Set Coding: Log-Euclidean Framework based Kernel Matrix Representation
Sep 16, 2019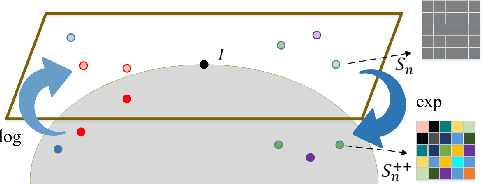
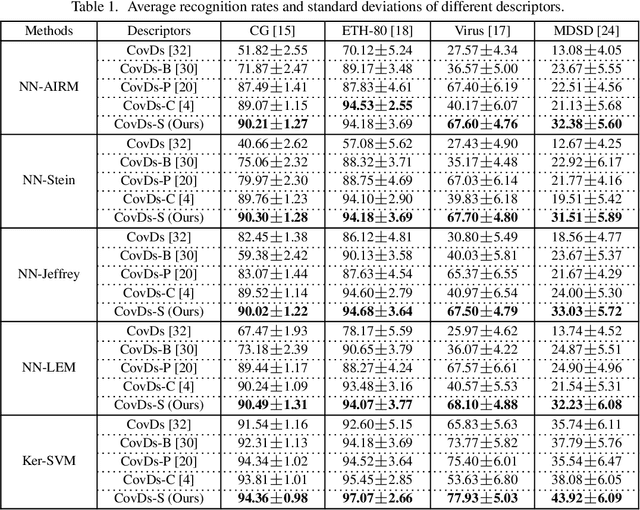
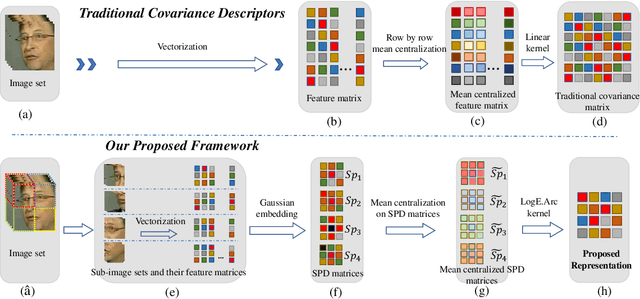
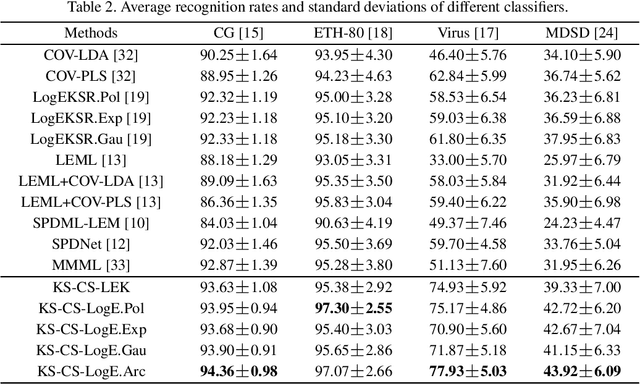
We consider a family of structural descriptors for visual data, namely covariance descriptors (CovDs) that lie on a non-linear symmetric positive definite (SPD) manifold, a special type of Riemannian manifolds. We propose an improved version of CovDs for image set coding by extending the traditional CovDs from Euclidean space to the SPD manifold. Specifically, the manifold of SPD matrices is a complete inner product space with the operations of logarithmic multiplication and scalar logarithmic multiplication defined in the Log-Euclidean framework. In this framework, we characterise covariance structure in terms of the arc-cosine kernel which satisfies Mercer's condition and propose the operation of mean centralization on SPD matrices. Furthermore, we combine arc-cosine kernels of different orders using mixing parameters learnt by kernel alignment in a supervised manner. Our proposed framework provides a lower-dimensional and more discriminative data representation for the task of image set classification. The experimental results demonstrate its superior performance, measured in terms of recognition accuracy, as compared with the state-of-the-art methods.
* 10 pages
A Pilot Study For Fragment Identification Using 2D NMR and Deep Learning
Mar 18, 2021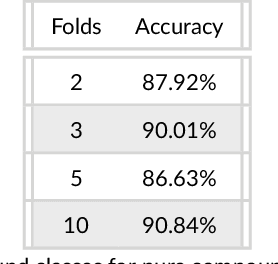
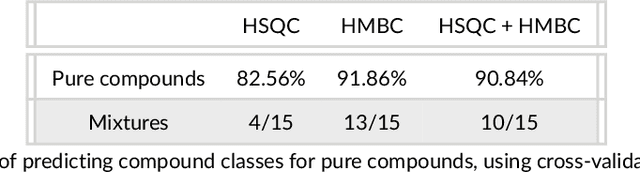
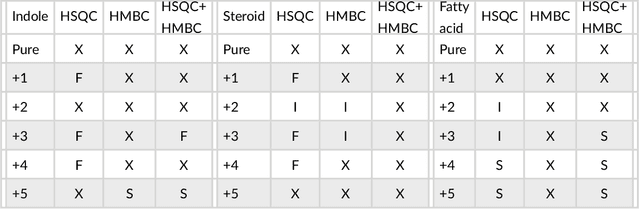
This paper presents a method to identify substructures in NMR spectra of mixtures, specifically 2D spectra, using a bespoke image-based Convolutional Neural Network application. This is done using HSQC and HMBC spectra separately and in combination. The application can reliably detect substructures in pure compounds, using a simple network. It can work for mixtures when trained on pure compounds only. HMBC data and the combination of HMBC and HSQC show better results than HSQC alone.
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
Jun 05, 2021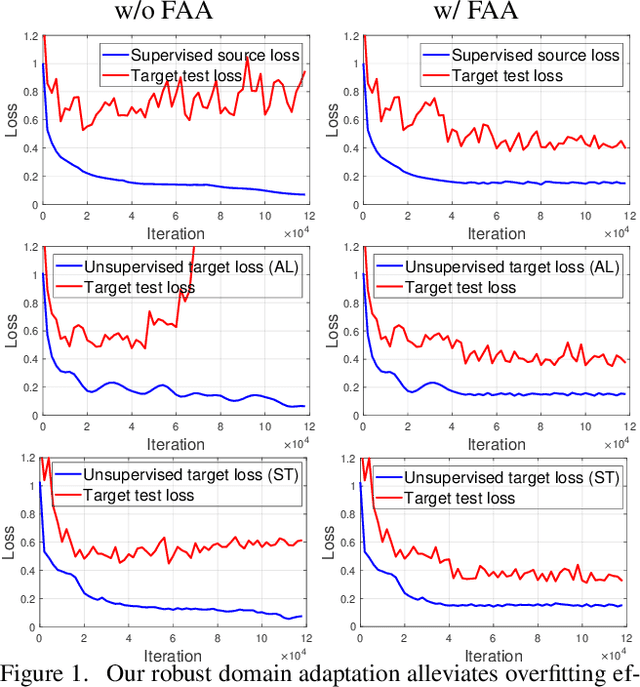
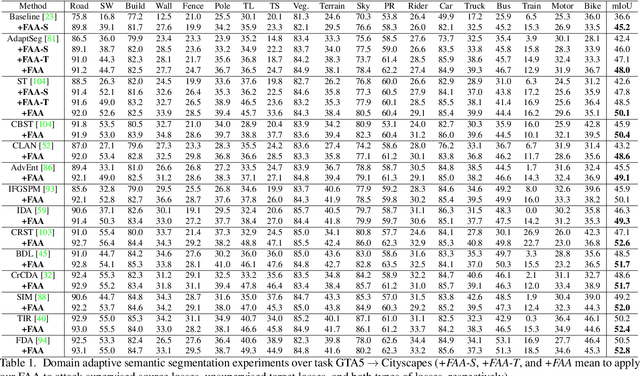
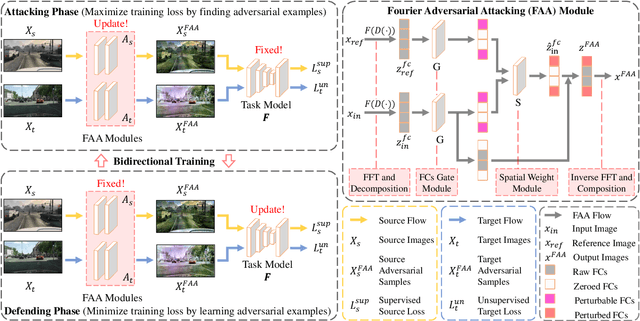
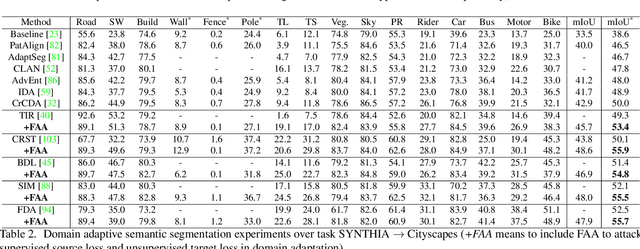
Unsupervised domain adaptation (UDA) involves a supervised loss in a labeled source domain and an unsupervised loss in an unlabeled target domain, which often faces more severe overfitting (than classical supervised learning) as the supervised source loss has clear domain gap and the unsupervised target loss is often noisy due to the lack of annotations. This paper presents RDA, a robust domain adaptation technique that introduces adversarial attacking to mitigate overfitting in UDA. We achieve robust domain adaptation by a novel Fourier adversarial attacking (FAA) method that allows large magnitude of perturbation noises but has minimal modification of image semantics, the former is critical to the effectiveness of its generated adversarial samples due to the existence of 'domain gaps'. Specifically, FAA decomposes images into multiple frequency components (FCs) and generates adversarial samples by just perturbating certain FCs that capture little semantic information. With FAA-generated samples, the training can continue the 'random walk' and drift into an area with a flat loss landscape, leading to more robust domain adaptation. Extensive experiments over multiple domain adaptation tasks show that RDA can work with different computer vision tasks with superior performance.
Mutual Contrastive Learning for Visual Representation Learning
Apr 26, 2021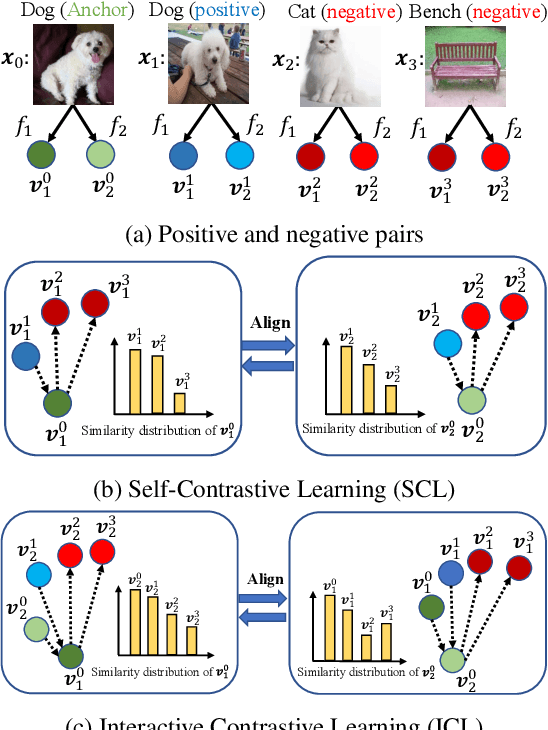
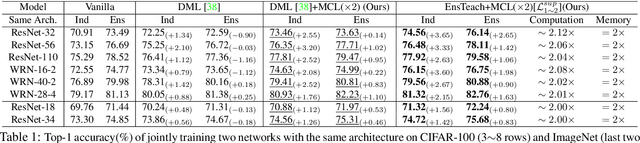
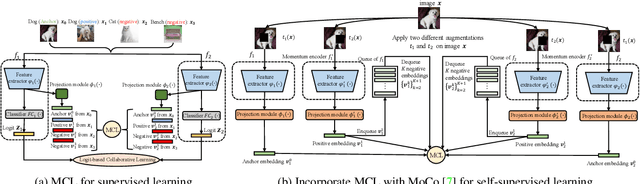
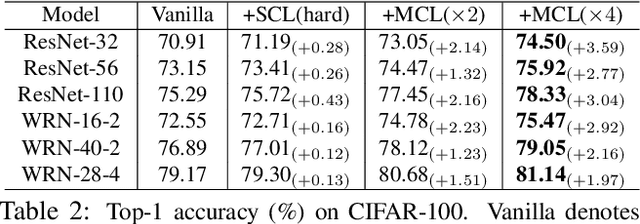
We present a collaborative learning method called Mutual Contrastive Learning (MCL) for general visual representation learning. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of models. Benefiting from MCL, each model can learn extra contrastive knowledge from others, leading to more meaningful feature representations for visual recognition tasks. We emphasize that MCL is conceptually simple yet empirically powerful. It is a generic framework that can be applied to both supervised and self-supervised representation learning. Experimental results on supervised and self-supervised image classification, transfer learning and few-shot learning show that MCL can lead to consistent performance gains, demonstrating that MCL can guide the network to generate better feature representations.
Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation
Jul 30, 2019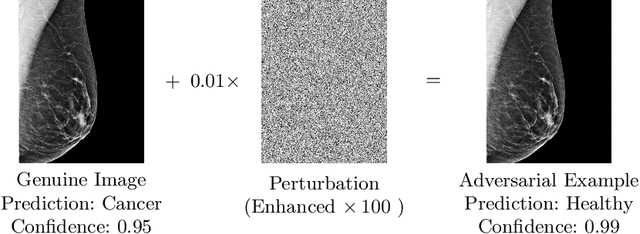
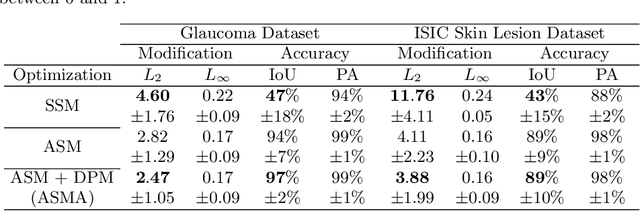

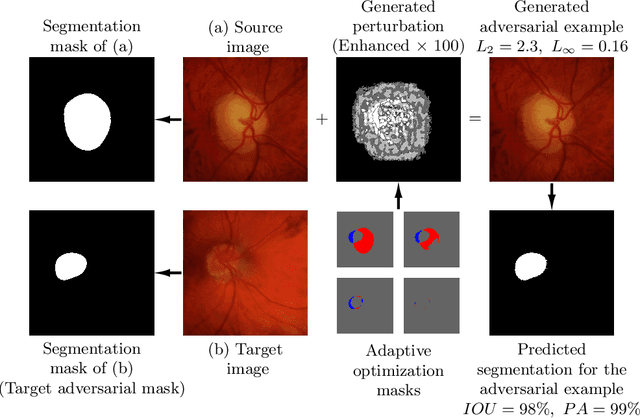
Deep learning models, which are increasingly being used in the field of medical image analysis, come with a major security risk, namely, their vulnerability to adversarial examples. Adversarial examples are carefully crafted samples that force machine learning models to make mistakes during testing time. These malicious samples have been shown to be highly effective in misguiding classification tasks. However, research on the influence of adversarial examples on segmentation is significantly lacking. Given that a large portion of medical imaging problems are effectively segmentation problems, we analyze the impact of adversarial examples on deep learning-based image segmentation models. Specifically, we expose the vulnerability of these models to adversarial examples by proposing the Adaptive Segmentation Mask Attack (ASMA). This novel algorithm makes it possible to craft targeted adversarial examples that come with (1) high intersection-over-union rates between the target adversarial mask and the prediction and (2) with perturbation that is, for the most part, invisible to the bare eye. We lay out experimental and visual evidence by showing results obtained for the ISIC skin lesion segmentation challenge and the problem of glaucoma optic disc segmentation. An implementation of this algorithm and additional examples can be found at https://github.com/utkuozbulak/adaptive-segmentation-mask-attack.
Visual Navigation with Spatial Attention
Apr 20, 2021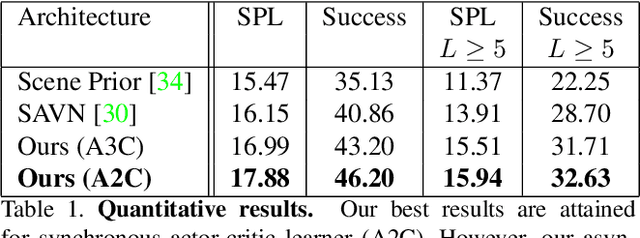
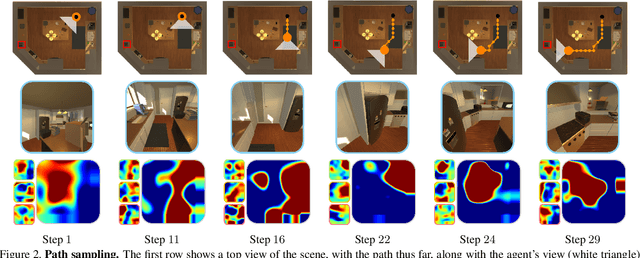
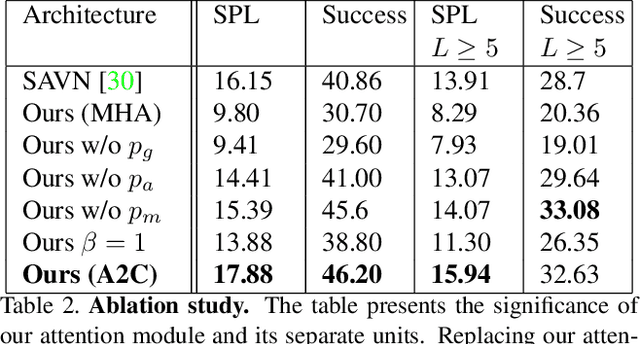
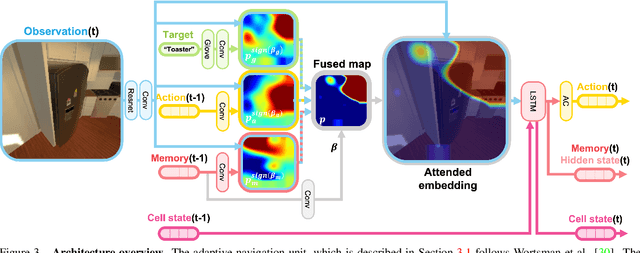
This work focuses on object goal visual navigation, aiming at finding the location of an object from a given class, where in each step the agent is provided with an egocentric RGB image of the scene. We propose to learn the agent's policy using a reinforcement learning algorithm. Our key contribution is a novel attention probability model for visual navigation tasks. This attention encodes semantic information about observed objects, as well as spatial information about their place. This combination of the "what" and the "where" allows the agent to navigate toward the sought-after object effectively. The attention model is shown to improve the agent's policy and to achieve state-of-the-art results on commonly-used datasets.