 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Hybrid Approach Between Adversarial Generative Networks and Actor-Critic Policy Gradient for Low Rate High-Resolution Image Compression
Jun 11, 2019
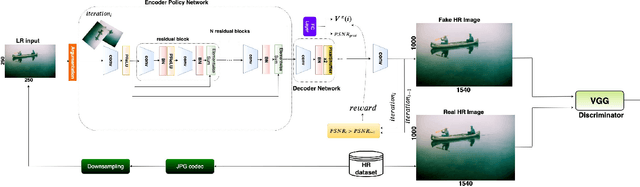
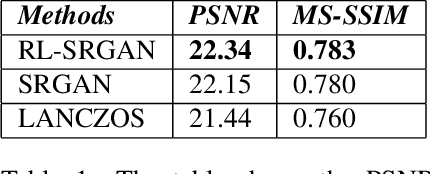

Image compression is an essential approach for decreasing the size in bytes of the image without deteriorating the quality of it. Typically, classic algorithms are used but recently deep-learning has been successfully applied. In this work, is presented a deep super-resolution work-flow for image compression that maps low-resolution JPEG image to the high-resolution. The pipeline consists of two components: first, an encoder-decoder neural network learns how to transform the downsampling JPEG images to high resolution. Second, a combination between Generative Adversarial Networks (GANs) and reinforcement learning Actor-Critic (A3C) loss pushes the encoder-decoder to indirectly maximize High Peak Signal-to-Noise Ratio (PSNR). Although PSNR is a fully differentiable metric, this work opens the doors to new solutions for maximizing non-differential metrics through an end-to-end approach between encoder-decoder networks and reinforcement learning policy gradient methods.
Joint High Dynamic Range Imaging and Super-Resolution from a Single Image
May 02, 2019
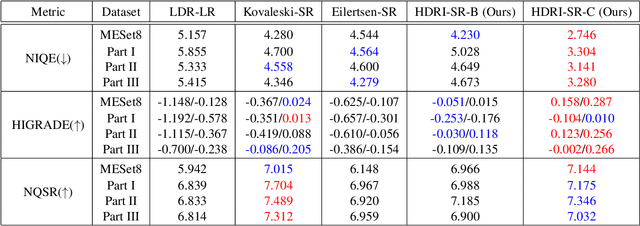
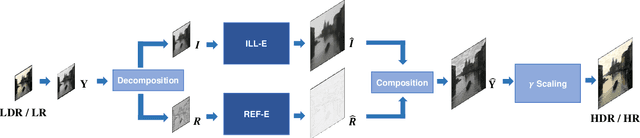

This paper presents a new framework for jointly enhancing the resolution and the dynamic range of an image, i.e., simultaneous super-resolution (SR) and high dynamic range imaging (HDRI), based on a convolutional neural network (CNN). From the common trends of both tasks, we train a CNN for the joint HDRI and SR by focusing on the reconstruction of high-frequency details. Specifically, the high-frequency component in our work is the reflectance component according to the Retinex-based image decomposition, and only the reflectance component is manipulated by the CNN while another component (illumination) is processed in a conventional way. In training the CNN, we devise an appropriate loss function that contributes to the naturalness quality of resulting images. Experiments show that our algorithm outperforms the cascade implementation of CNN-based SR and HDRI.
Understanding and Improving Early Stopping for Learning with Noisy Labels
Jun 30, 2021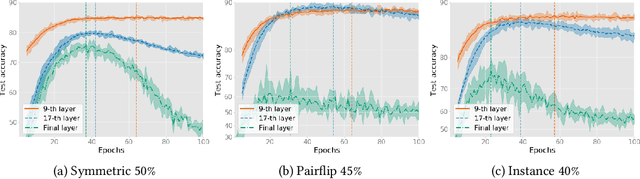
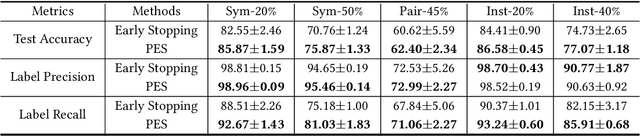
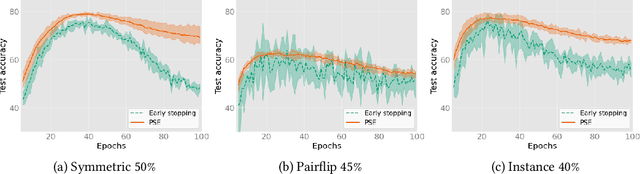
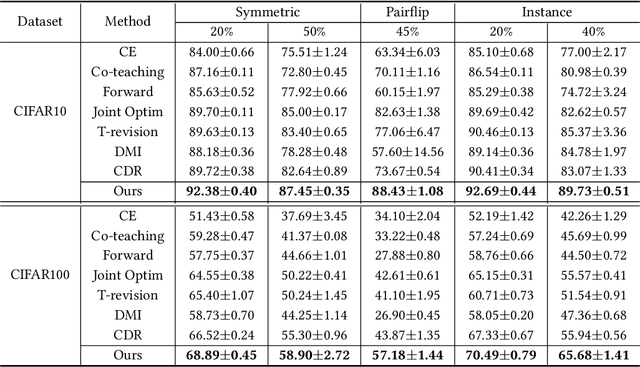
The memorization effect of deep neural network (DNN) plays a pivotal role in many state-of-the-art label-noise learning methods. To exploit this property, the early stopping trick, which stops the optimization at the early stage of training, is usually adopted. Current methods generally decide the early stopping point by considering a DNN as a whole. However, a DNN can be considered as a composition of a series of layers, and we find that the latter layers in a DNN are much more sensitive to label noise, while their former counterparts are quite robust. Therefore, selecting a stopping point for the whole network may make different DNN layers antagonistically affected each other, thus degrading the final performance. In this paper, we propose to separate a DNN into different parts and progressively train them to address this problem. Instead of the early stopping, which trains a whole DNN all at once, we initially train former DNN layers by optimizing the DNN with a relatively large number of epochs. During training, we progressively train the latter DNN layers by using a smaller number of epochs with the preceding layers fixed to counteract the impact of noisy labels. We term the proposed method as progressive early stopping (PES). Despite its simplicity, compared with the early stopping, PES can help to obtain more promising and stable results. Furthermore, by combining PES with existing approaches on noisy label training, we achieve state-of-the-art performance on image classification benchmarks.
Generative adversarial network with object detector discriminator for enhanced defect detection on ultrasonic B-scans
Jun 08, 2021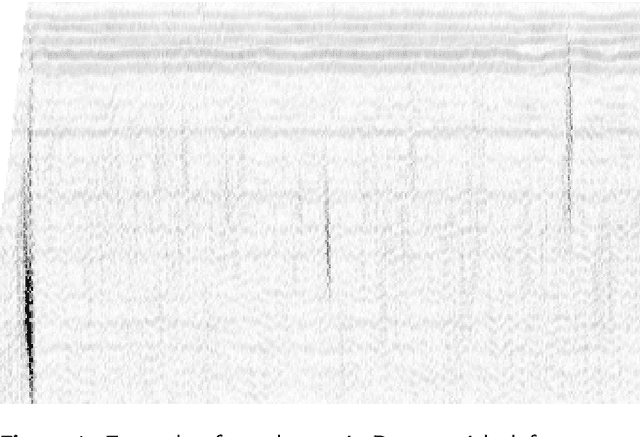

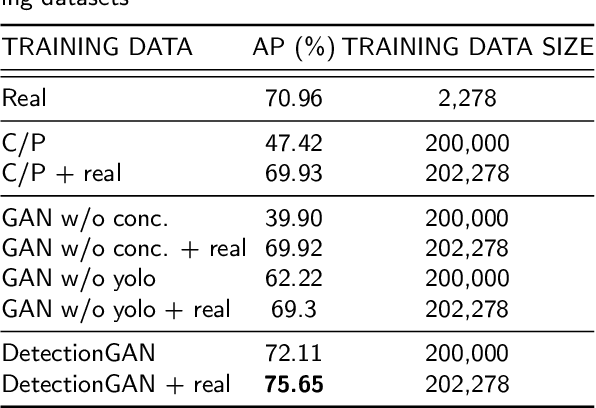
Non-destructive testing is a set of techniques for defect detection in materials. While the set of imaging techniques are manifold, ultrasonic imaging is the one used the most. The analysis is mainly performed by human inspectors manually analyzing recorded images. The low number of defects in real ultrasonic inspections and legal issues considering data from such inspections make it difficult to obtain proper results from automatic ultrasonic image (B-scan) analysis. In this paper, we present a novel deep learning Generative Adversarial Network model for generating ultrasonic B-scans with defects in distinct locations. Furthermore, we show that generated B-scans can be used for synthetic data augmentation, and can improve the performance of deep convolutional neural object detection networks. Our novel method is demonstrated on a dataset of almost 4000 B-scans with more than 6000 annotated defects. Defect detection performance when training on real data yielded average precision of 71%. By training only on generated data the results increased to 72.1%, and by mixing generated and real data we achieve 75.7% average precision. We believe that synthetic data generation can generalize to other challenges with limited datasets and could be used for training human personnel.
Monitoring the Impacts of a Tailings Dam Failure Using Satellite Images
Jan 30, 2021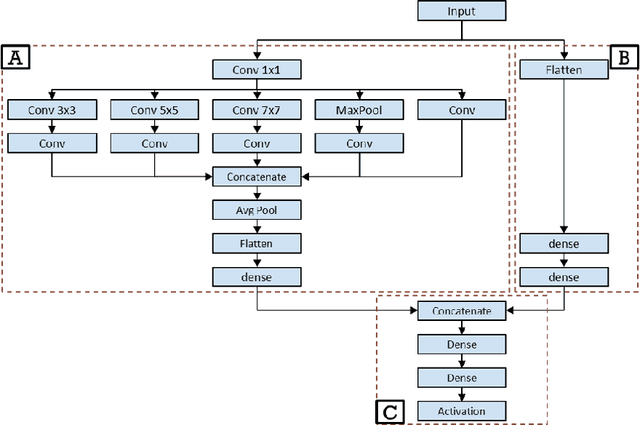
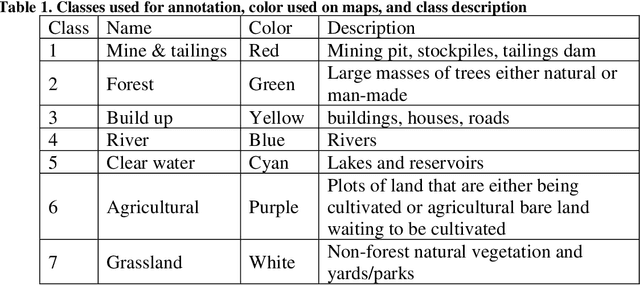
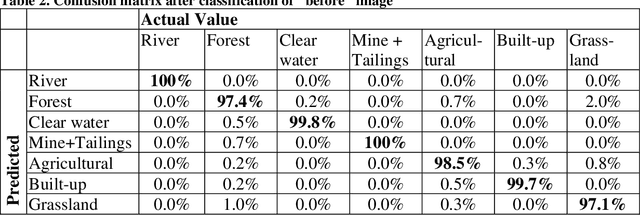
Monitoring dam failures using satellite images provides first responders with efficient management of early interventions. It is also equally important to monitor spatial and temporal changes in the inundation area to track the post-disaster recovery. On January 25th, 2019, the tailings dam of the C\'orrego do Feij\~ao iron ore mine, located in Brumadinho, Brazil, collapsed. This disaster caused more than 230 fatalities and 30 missing people leading to damage on the order of multiple billions of dollars. This study uses Sentinel-2 satellite images to map the inundation area and assess and delineate the land use and land cover impacted by the dam failure. The images correspond to data captures from January 22nd (3 days before), and February 02 (7 days after the collapse). Satellite images of the region were classified for before and aftermath of the disaster implementing a machine learning algorithm. In order to have sufficient land cover types to validate the quality and accuracy of the algorithm, 7 classes were defined: mine, forest, build-up, river, agricultural, clear water, and grassland. The developed classification algorithm yielded a high accuracy (99%) for the image before the collapse. This paper determines land cover impact using two different models, 1) by using the trained network in the "after" image, and 2) by creating a second network, trained in a subset of points of the "after" image, and then comparing the land cover results of the two trained networks. In the first model, applying the trained network to the "after" image, the accuracy is still high (86%), but lower than using the second model (98%). This strategy can be applied at a low cost for monitoring and assessment by using openly available satellite information and, in case of dam collapse or with a larger budget, higher resolution and faster data can be obtained by fly-overs on the area of concern.
A comparative study of semi- and self-supervised semantic segmentation of biomedical microscopy data
Nov 11, 2020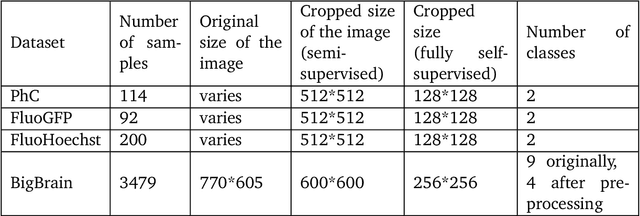
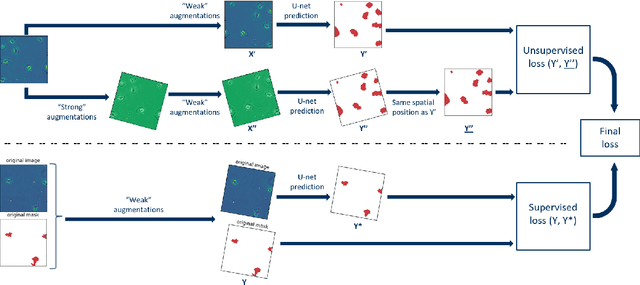

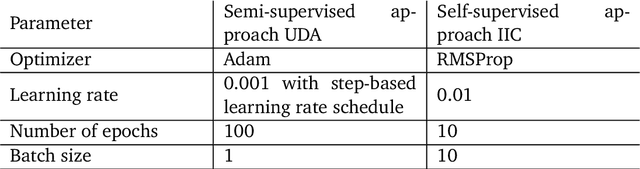
In recent years, Convolutional Neural Networks (CNNs) have become the state-of-the-art method for biomedical image analysis. However, these networks are usually trained in a supervised manner, requiring large amounts of labelled training data. These labelled data sets are often difficult to acquire in the biomedical domain. In this work, we validate alternative ways to train CNNs with fewer labels for biomedical image segmentation using. We adapt two semi- and self-supervised image classification methods and analyse their performance for semantic segmentation of biomedical microscopy images.
REMAP: Multi-layer entropy-guided pooling of dense CNN features for image retrieval
Jun 15, 2019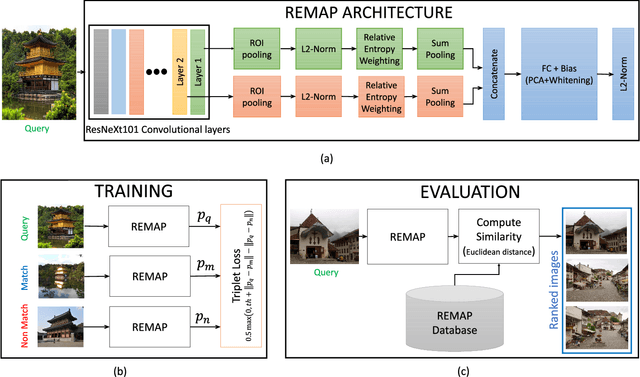
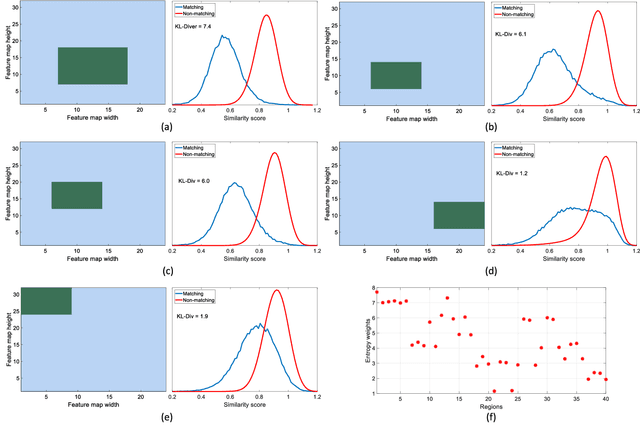

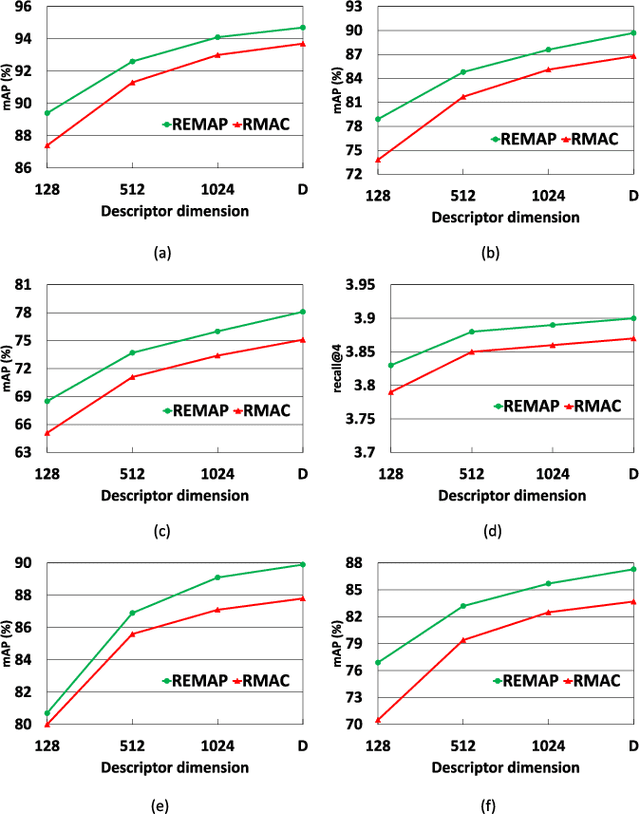
This paper addresses the problem of very large-scale image retrieval, focusing on improving its accuracy and robustness. We target enhanced robustness of search to factors such as variations in illumination, object appearance and scale, partial occlusions, and cluttered backgrounds - particularly important when search is performed across very large datasets with significant variability. We propose a novel CNN-based global descriptor, called REMAP, which learns and aggregates a hierarchy of deep features from multiple CNN layers, and is trained end-to-end with a triplet loss. REMAP explicitly learns discriminative features which are mutually-supportive and complementary at various semantic levels of visual abstraction. These dense local features are max-pooled spatially at each layer, within multi-scale overlapping regions, before aggregation into a single image-level descriptor. To identify the semantically useful regions and layers for retrieval, we propose to measure the information gain of each region and layer using KL-divergence. Our system effectively learns during training how useful various regions and layers are and weights them accordingly. We show that such relative entropy-guided aggregation outperforms classical CNN-based aggregation controlled by SGD. The entire framework is trained in an end-to-end fashion, outperforming the latest state-of-the-art results. On image retrieval datasets Holidays, Oxford and MPEG, the REMAP descriptor achieves mAP of 95.5%, 91.5%, and 80.1% respectively, outperforming any results published to date. REMAP also formed the core of the winning submission to the Google Landmark Retrieval Challenge on Kaggle.
* Submitted to IEEE Trans. Image Processing on 24 May 2018, published 22 May 2019
Deep Spectral Correspondence for Matching Disparate Image Pairs
Sep 12, 2018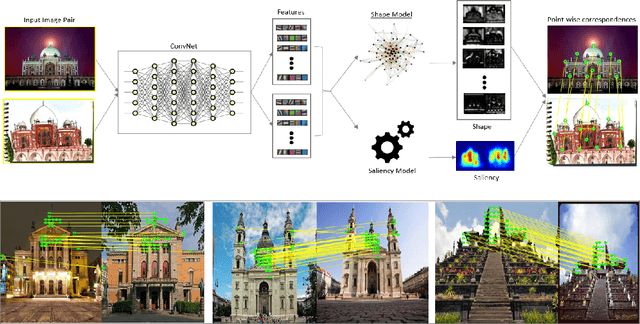
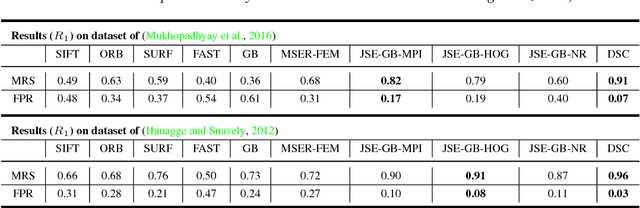

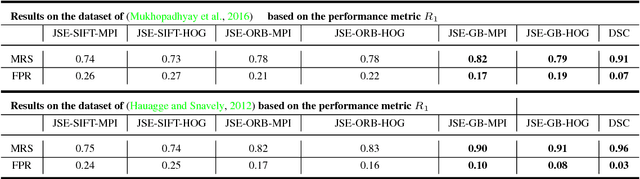
A novel, non-learning-based, saliency-aware, shape-cognizant correspondence determination technique is proposed for matching image pairs that are significantly disparate in nature. Images in the real world often exhibit high degrees of variation in scale, orientation, viewpoint, illumination and affine projection parameters, and are often accompanied by the presence of textureless regions and complete or partial occlusion of scene objects. The above conditions confound most correspondence determination techniques by rendering impractical the use of global contour-based descriptors or local pixel-level features for establishing correspondence. The proposed deep spectral correspondence (DSC) determination scheme harnesses the representational power of local feature descriptors to derive a complex high-level global shape representation for matching disparate images. The proposed scheme reasons about correspondence between disparate images using high-level global shape cues derived from low-level local feature descriptors. Consequently, the proposed scheme enjoys the best of both worlds, i.e., a high degree of invariance to affine parameters such as scale, orientation, viewpoint, illumination afforded by the global shape cues and robustness to occlusion provided by the low-level feature descriptors. While the shape-based component within the proposed scheme infers what to look for, an additional saliency-based component dictates where to look at thereby tackling the noisy correspondences arising from the presence of textureless regions and complex backgrounds. In the proposed scheme, a joint image graph is constructed using distances computed between interest points in the appearance (i.e., image) space. Eigenspectral decomposition of the joint image graph allows for reasoning about shape similarity to be performed jointly, in the appearance space and eigenspace.
Histopathology WSI Encoding based on GCNs for Scalable and Efficient Retrieval of Diagnostically Relevant Regions
Apr 16, 2021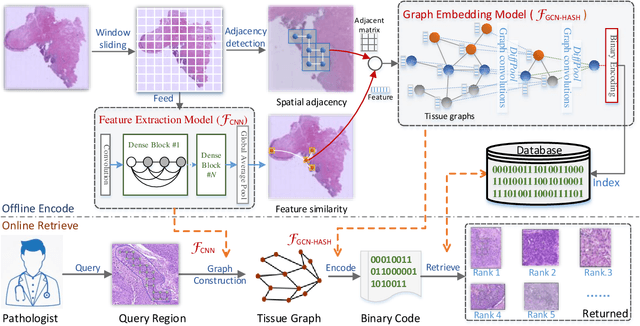
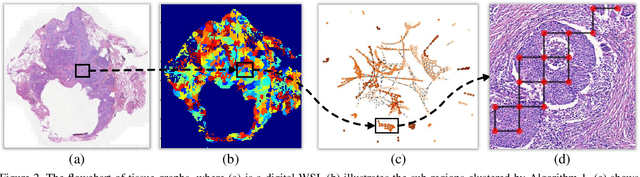

Content-based histopathological image retrieval (CBHIR) has become popular in recent years in the domain of histopathological image analysis. CBHIR systems provide auxiliary diagnosis information for pathologists by searching for and returning regions that are contently similar to the region of interest (ROI) from a pre-established database. While, it is challenging and yet significant in clinical applications to retrieve diagnostically relevant regions from a database that consists of histopathological whole slide images (WSIs) for a query ROI. In this paper, we propose a novel framework for regions retrieval from WSI-database based on hierarchical graph convolutional networks (GCNs) and Hash technique. Compared to the present CBHIR framework, the structural information of WSI is preserved through graph embedding of GCNs, which makes the retrieval framework more sensitive to regions that are similar in tissue distribution. Moreover, benefited from the hierarchical GCN structures, the proposed framework has good scalability for both the size and shape variation of ROIs. It allows the pathologist defining query regions using free curves according to the appearance of tissue. Thirdly, the retrieval is achieved based on Hash technique, which ensures the framework is efficient and thereby adequate for practical large-scale WSI-database. The proposed method was validated on two public datasets for histopathological WSI analysis and compared to the state-of-the-art methods. The proposed method achieved mean average precision above 0.857 on the ACDC-LungHP dataset and above 0.864 on the Camelyon16 dataset in the irregular region retrieval tasks, which are superior to the state-of-the-art methods. The average retrieval time from a database within 120 WSIs is 0.802 ms.
Distribution Matching Losses Can Hallucinate Features in Medical Image Translation
Oct 03, 2018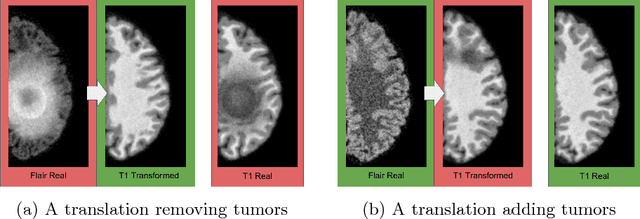
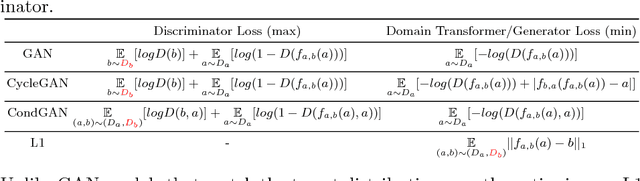
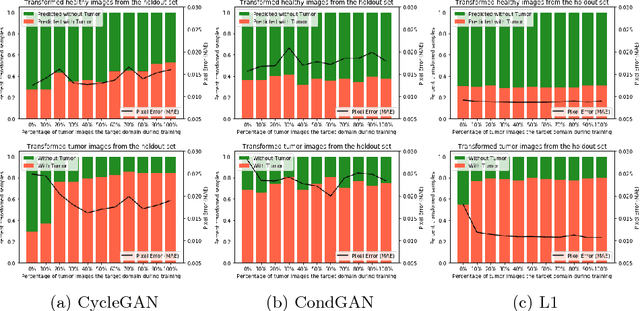

This paper discusses how distribution matching losses, such as those used in CycleGAN, when used to synthesize medical images can lead to mis-diagnosis of medical conditions. It seems appealing to use these new image synthesis methods for translating images from a source to a target domain because they can produce high quality images and some even do not require paired data. However, the basis of how these image translation models work is through matching the translation output to the distribution of the target domain. This can cause an issue when the data provided in the target domain has an over or under representation of some classes (e.g. healthy or sick). When the output of an algorithm is a transformed image there are uncertainties whether all known and unknown class labels have been preserved or changed. Therefore, we recommend that these translated images should not be used for direct interpretation (e.g. by doctors) because they may lead to misdiagnosis of patients based on hallucinated image features by an algorithm that matches a distribution. However there are many recent papers that seem as though this is the goal.
* Published at Medical Image Computing & Computer Assisted Intervention (MICCAI 2018). An abstract is published at the Medical Imaging with Deep Learning Conference (MIDL 2018) as "How to Cure Cancer (in images) with Unpaired Image Translation"