 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Does enhanced shape bias improve neural network robustness to common corruptions?
Apr 20, 2021
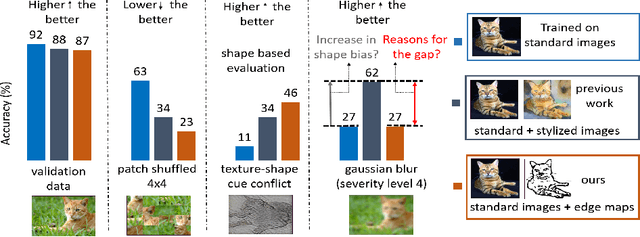
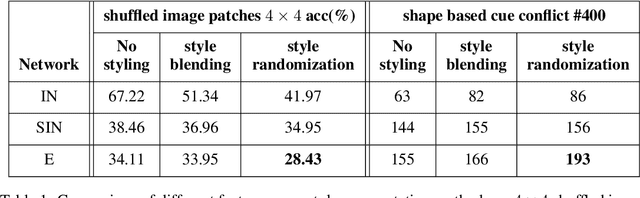

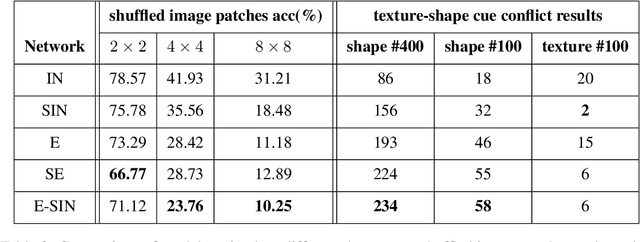
Convolutional neural networks (CNNs) learn to extract representations of complex features, such as object shapes and textures to solve image recognition tasks. Recent work indicates that CNNs trained on ImageNet are biased towards features that encode textures and that these alone are sufficient to generalize to unseen test data from the same distribution as the training data but often fail to generalize to out-of-distribution data. It has been shown that augmenting the training data with different image styles decreases this texture bias in favor of increased shape bias while at the same time improving robustness to common corruptions, such as noise and blur. Commonly, this is interpreted as shape bias increasing corruption robustness. However, this relationship is only hypothesized. We perform a systematic study of different ways of composing inputs based on natural images, explicit edge information, and stylization. While stylization is essential for achieving high corruption robustness, we do not find a clear correlation between shape bias and robustness. We conclude that the data augmentation caused by style-variation accounts for the improved corruption robustness and increased shape bias is only a byproduct.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 08, 2021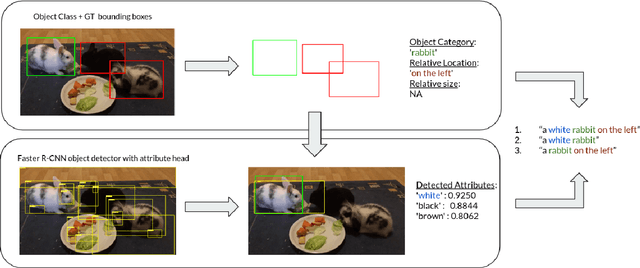



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
ColorNet: Investigating the importance of color spaces for image classification
Feb 01, 2019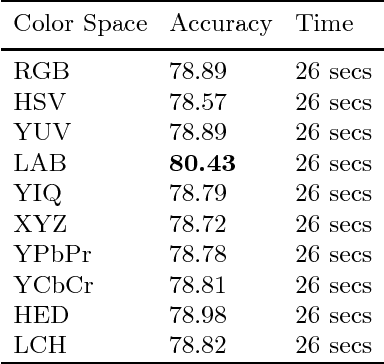
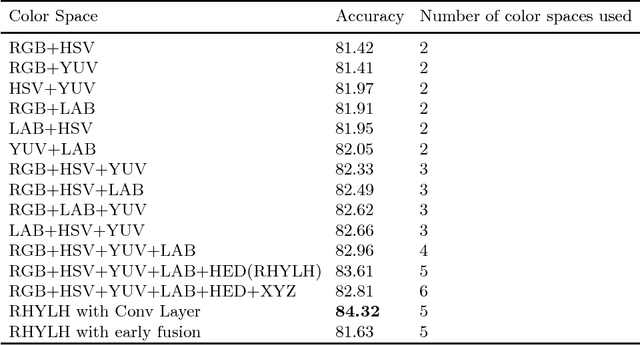
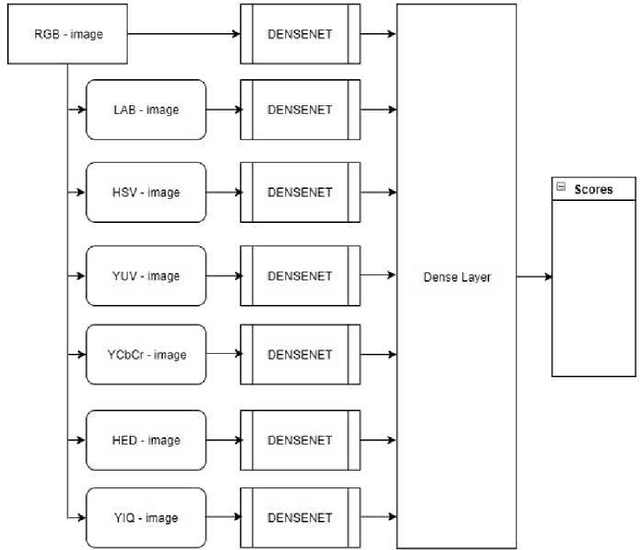
Image classification is a fundamental application in computer vision. Recently, deeper networks and highly connected networks have shown state of the art performance for image classification tasks. Most datasets these days consist of a finite number of color images. These color images are taken as input in the form of RGB images and classification is done without modifying them. We explore the importance of color spaces and show that color spaces (essentially transformations of original RGB images) can significantly affect classification accuracy. Further, we show that certain classes of images are better represented in particular color spaces and for a dataset with a highly varying number of classes such as CIFAR and Imagenet, using a model that considers multiple color spaces within the same model gives excellent levels of accuracy. Also, we show that such a model, where the input is preprocessed into multiple color spaces simultaneously, needs far fewer parameters to obtain high accuracy for classification. For example, our model with 1.75M parameters significantly outperforms DenseNet 100-12 that has 12M parameters and gives results comparable to Densenet-BC-190-40 that has 25.6M parameters for classification of four competitive image classification datasets namely: CIFAR-10, CIFAR-100, SVHN and Imagenet. Our model essentially takes an RGB image as input, simultaneously converts the image into 7 different color spaces and uses these as inputs to individual densenets. We use small and wide densenets to reduce computation overhead and number of hyperparameters required. We obtain significant improvement on current state of the art results on these datasets as well.
ALADIN: All Layer Adaptive Instance Normalization for Fine-grained Style Similarity
Mar 17, 2021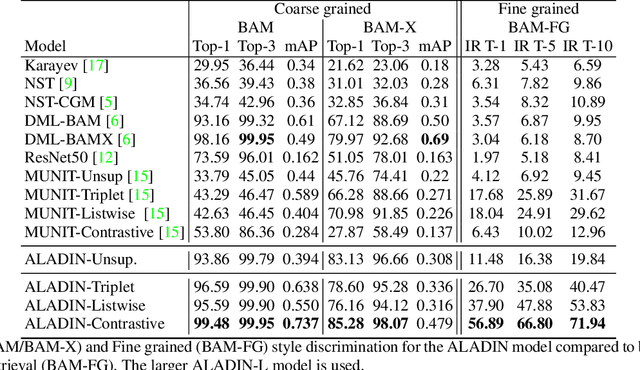
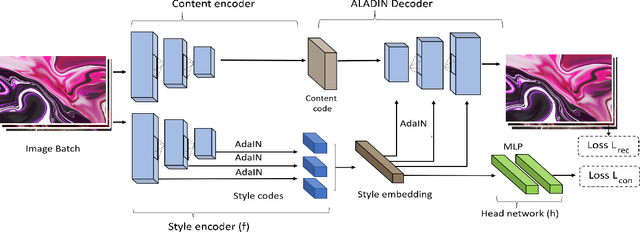
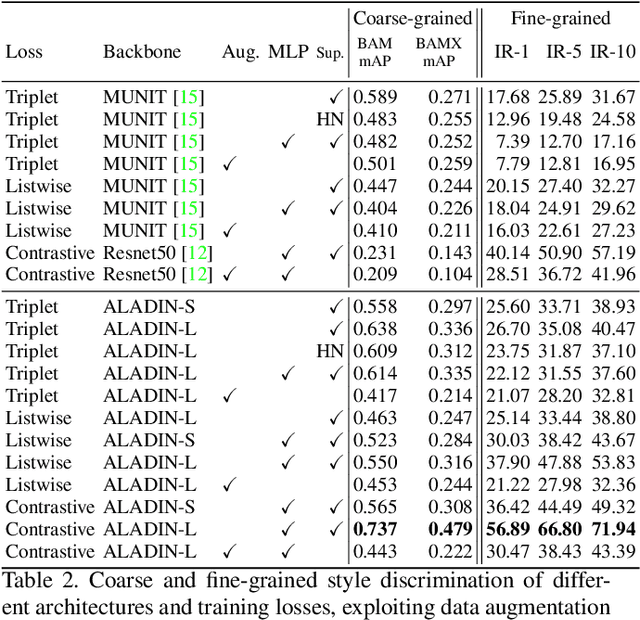

We present ALADIN (All Layer AdaIN); a novel architecture for searching images based on the similarity of their artistic style. Representation learning is critical to visual search, where distance in the learned search embedding reflects image similarity. Learning an embedding that discriminates fine-grained variations in style is hard, due to the difficulty of defining and labelling style. ALADIN takes a weakly supervised approach to learning a representation for fine-grained style similarity of digital artworks, leveraging BAM-FG, a novel large-scale dataset of user generated content groupings gathered from the web. ALADIN sets a new state of the art accuracy for style-based visual search over both coarse labelled style data (BAM) and BAM-FG; a new 2.62 million image dataset of 310,000 fine-grained style groupings also contributed by this work.
toon2real: Translating Cartoon Images to Realistic Images
Feb 01, 2021
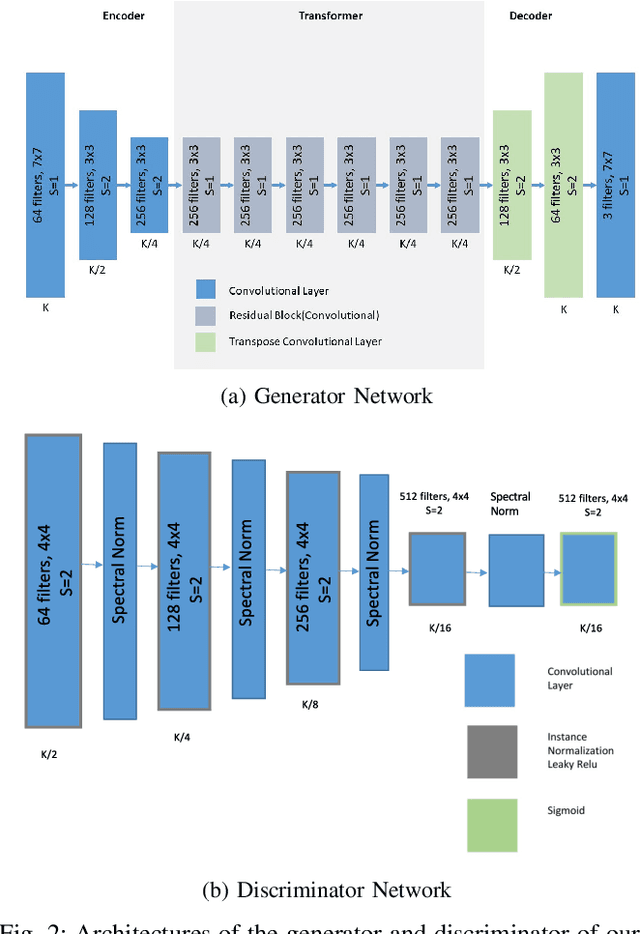

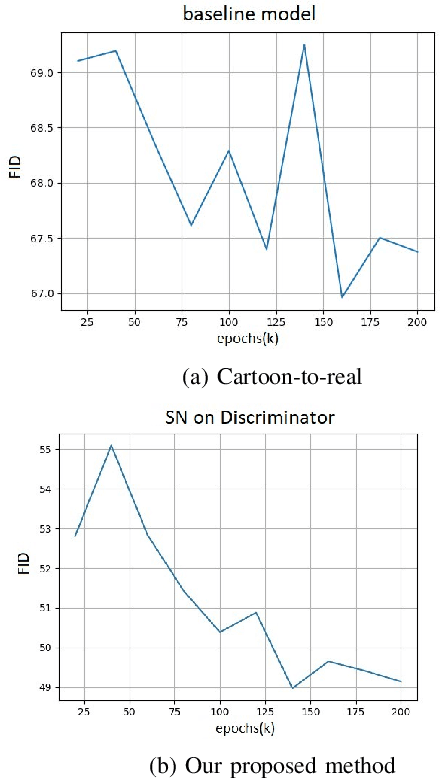
In terms of Image-to-image translation, Generative Adversarial Networks (GANs) has achieved great success even when it is used in the unsupervised dataset. In this work, we aim to translate cartoon images to photo-realistic images using GAN. We apply several state-of-the-art models to perform this task; however, they fail to perform good quality translations. We observe that the shallow difference between these two domains causes this issue. Based on this idea, we propose a method based on CycleGAN model for image translation from cartoon domain to photo-realistic domain. To make our model efficient, we implemented Spectral Normalization which added stability in our model. We demonstrate our experimental results and show that our proposed model has achieved the lowest Frechet Inception Distance score and better results compared to another state-of-the-art technique, UNIT.
Sexing Caucasian 2D footprints using convolutional neural networks
Jul 23, 2021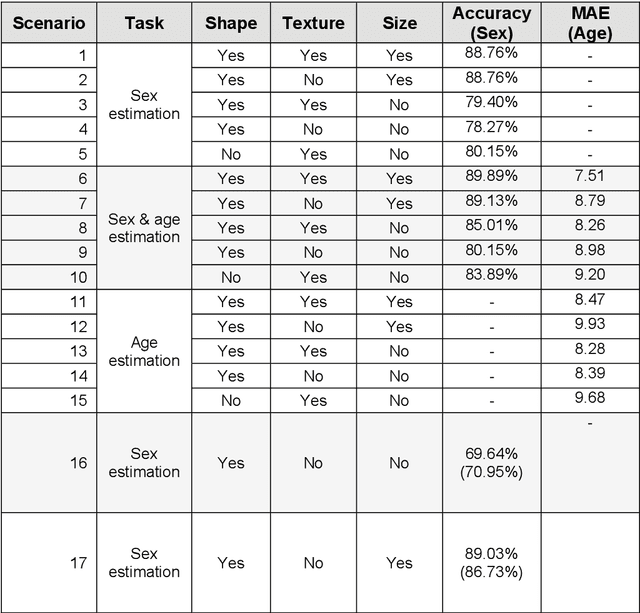
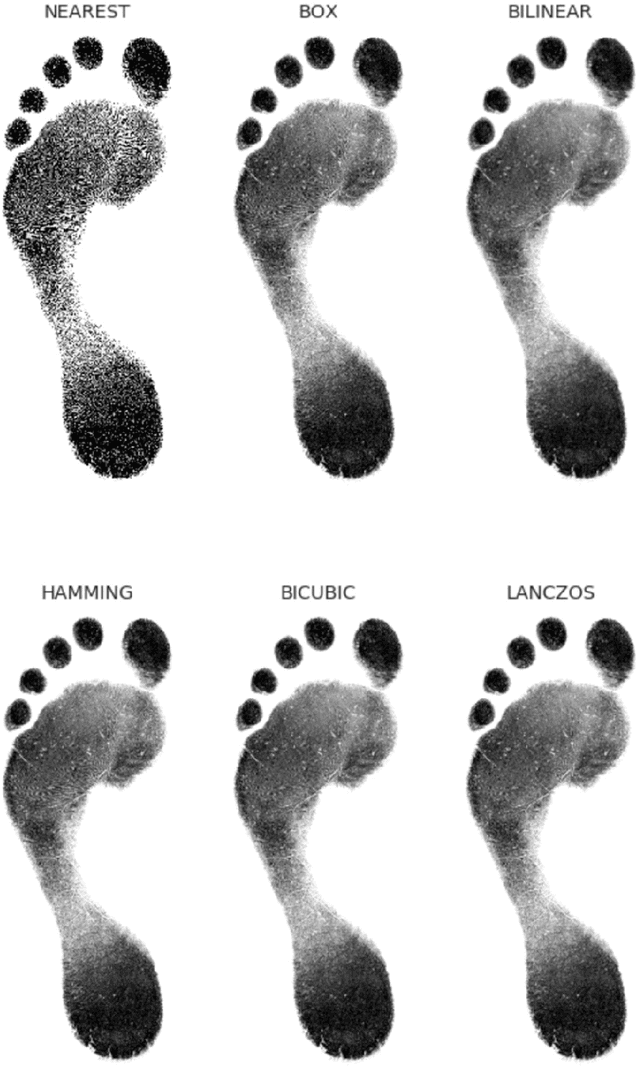
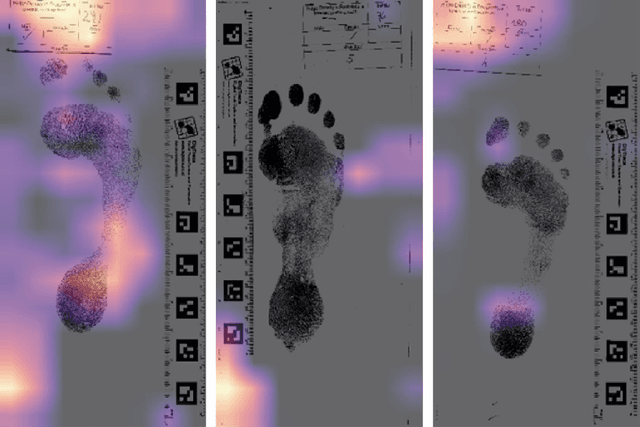
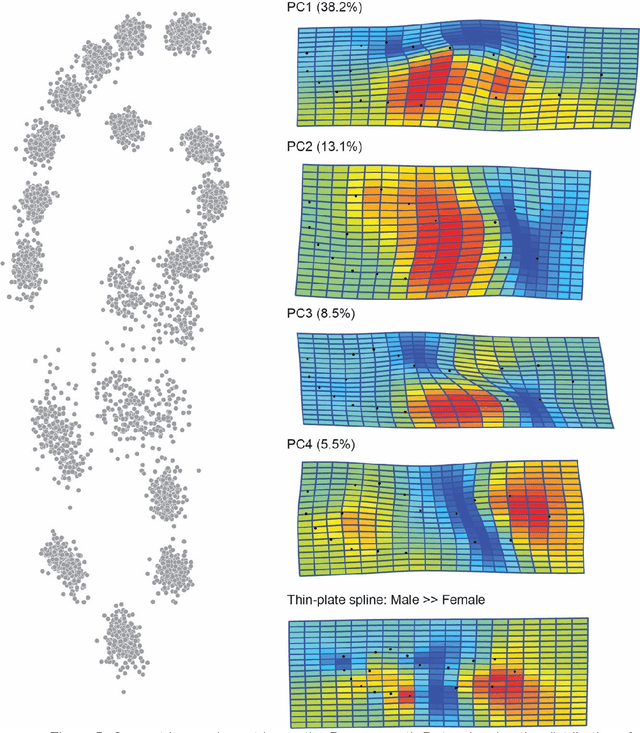
Footprints are left, or obtained, in a variety of scenarios from crime scenes to anthropological investigations. Determining the sex of a footprint can be useful in screening such impressions and attempts have been made to do so using single or multi landmark distances, shape analyses and via the density of friction ridges. Here we explore the relative importance of different components in sexing two-dimensional foot impressions namely, size, shape and texture. We use a machine learning approach and compare this to more traditional methods of discrimination. Two datasets are used, a pilot data set collected from students at Bournemouth University (N=196) and a larger data set collected by podiatrists at Sheffield NHS Teaching Hospital (N=2677). Our convolutional neural network can sex a footprint with accuracy of around 90% on a test set of N=267 footprint images using all image components, which is better than an expert can achieve. However, the quality of the impressions impacts on this success rate, but the results are promising and in time it may be possible to create an automated screening algorithm in which practitioners of whatever sort (medical or forensic) can obtain a first order sexing of a two-dimensional footprint.
Black-Box Diagnosis and Calibration on GAN Intra-Mode Collapse: A Pilot Study
Jul 23, 2021

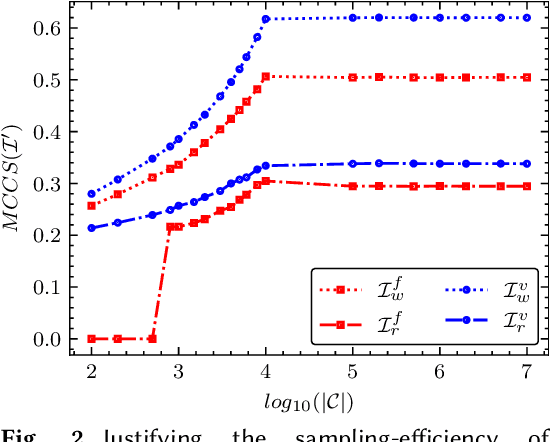

Generative adversarial networks (GANs) nowadays are capable of producing images of incredible realism. One concern raised is whether the state-of-the-art GAN's learned distribution still suffers from mode collapse, and what to do if so. Existing diversity tests of samples from GANs are usually conducted qualitatively on a small scale, and/or depends on the access to original training data as well as the trained model parameters. This paper explores to diagnose GAN intra-mode collapse and calibrate that, in a novel black-box setting: no access to training data, nor the trained model parameters, is assumed. The new setting is practically demanded, yet rarely explored and significantly more challenging. As a first stab, we devise a set of statistical tools based on sampling, that can visualize, quantify, and rectify intra-mode collapse. We demonstrate the effectiveness of our proposed diagnosis and calibration techniques, via extensive simulations and experiments, on unconditional GAN image generation (e.g., face and vehicle). Our study reveals that the intra-mode collapse is still a prevailing problem in state-of-the-art GANs and the mode collapse is diagnosable and calibratable in black-box settings. Our codes are available at: https://github.com/VITA-Group/BlackBoxGANCollapse.
Deep Network Approximation: Achieving Arbitrary Accuracy with Fixed Number of Neurons
Jul 07, 2021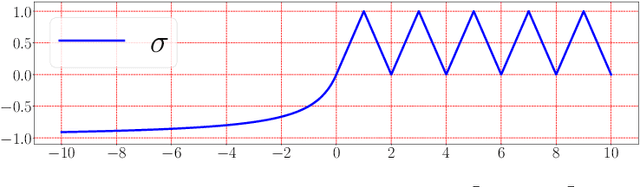
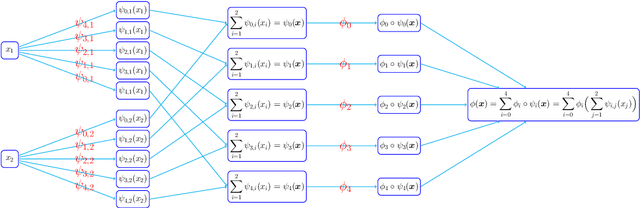
This paper develops simple feed-forward neural networks that achieve the universal approximation property for all continuous functions with a fixed finite number of neurons. These neural networks are simple because they are designed with a simple and computable continuous activation function $\sigma$ leveraging a triangular-wave function and a softsign function. We prove that $\sigma$-activated networks with width $36d(2d+1)$ and depth $11$ can approximate any continuous function on a $d$-dimensioanl hypercube within an arbitrarily small error. Hence, for supervised learning and its related regression problems, the hypothesis space generated by these networks with a size not smaller than $36d(2d+1)\times 11$ is dense in the space of continuous functions. Furthermore, classification functions arising from image and signal classification are in the hypothesis space generated by $\sigma$-activated networks with width $36d(2d+1)$ and depth $12$, when there exist pairwise disjoint closed bounded subsets of $\mathbb{R}^d$ such that the samples of the same class are located in the same subset.
GPLA-12: An Acoustic Signal Dataset of Gas Pipeline Leakage
Jun 19, 2021

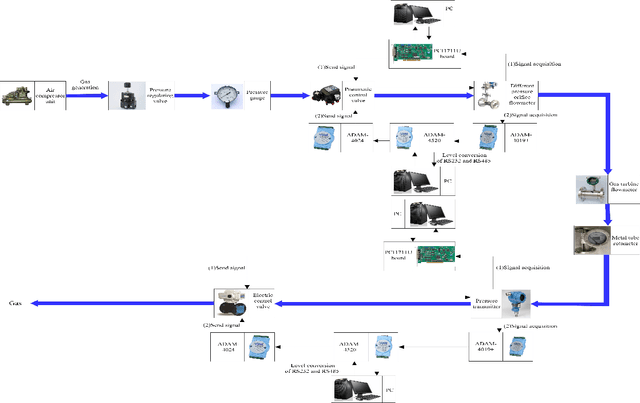

In this paper, we introduce a new acoustic leakage dataset of gas pipelines, called as GPLA-12, which has 12 categories over 684 training/testing acoustic signals. Unlike massive image and voice datasets, there have relatively few acoustic signal datasets, especially for engineering fault detection. In order to enhance the development of fault diagnosis, we collect acoustic leakage signals on the basis of an intact gas pipe system with external artificial leakages, and then preprocess the collected data with structured tailoring which are turned into GPLA-12. GPLA-12 dedicates to serve as a feature learning dataset for time-series tasks and classifications. To further understand the dataset, we train both shadow and deep learning algorithms to observe the performance. The dataset as well as the pretrained models have been released at both www.daip.club and github.com/Deep-AI-Application-DAIP
DeepRED: Deep Image Prior Powered by RED
Mar 25, 2019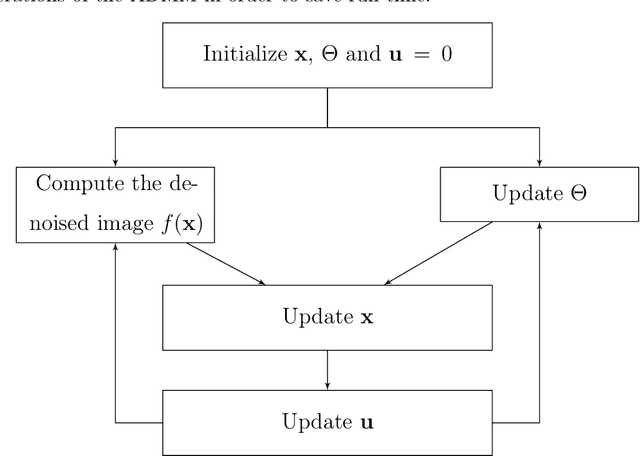
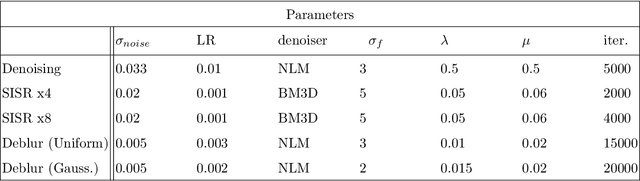

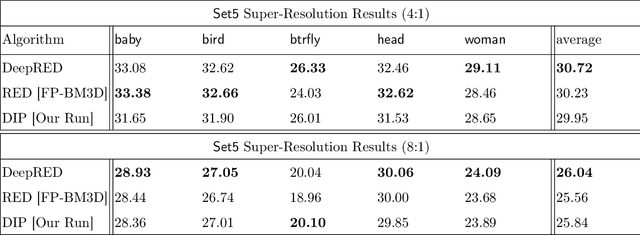
Inverse problems in imaging are extensively studied, with a variety of strategies, tools, and theory that have been accumulated over the years. Recently, this field has been immensely influenced by the emergence of deep-learning techniques. One such contribution, which is the focus of this paper, is the Deep Image Prior (DIP) work by Ulyanov, Vedaldi, and Lempitsky (2018). DIP offers a new approach towards the regularization of inverse problems, obtained by forcing the recovered image to be synthesized from a given deep architecture. While DIP has been shown to be effective, its results fall short when compared to state-of-the-art alternatives. In this work, we aim to boost DIP by adding an explicit prior, which enriches the overall regularization effect in order to lead to better-recovered images. More specifically, we propose to bring-in the concept of Regularization by Denoising (RED), which leverages existing denoisers for regularizing inverse problems. Our work shows how the two (DeepRED) can be merged to a highly effective recovery process while avoiding the need to differentiate the chosen denoiser, and leading to very effective results, demonstrated for several tested inverse problems.