 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Teacher's pet: understanding and mitigating biases in distillation
Jul 08, 2021
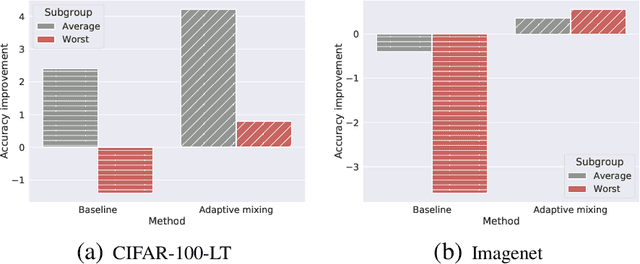

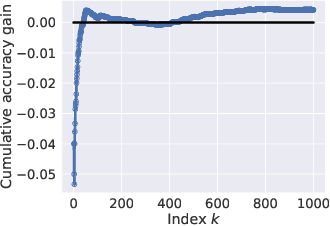
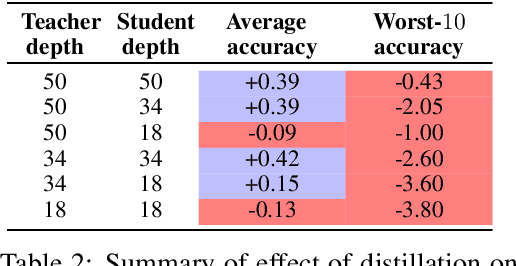
Knowledge distillation is widely used as a means of improving the performance of a relatively simple student model using the predictions from a complex teacher model. Several works have shown that distillation significantly boosts the student's overall performance; however, are these gains uniform across all data subgroups? In this paper, we show that distillation can harm performance on certain subgroups, e.g., classes with few associated samples. We trace this behaviour to errors made by the teacher distribution being transferred to and amplified by the student model. To mitigate this problem, we present techniques which soften the teacher influence for subgroups where it is less reliable. Experiments on several image classification benchmarks show that these modifications of distillation maintain boost in overall accuracy, while additionally ensuring improvement in subgroup performance.
Flow Guided Transformable Bottleneck Networks for Motion Retargeting
Jun 14, 2021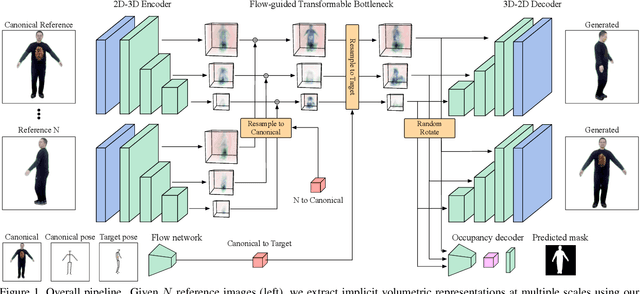
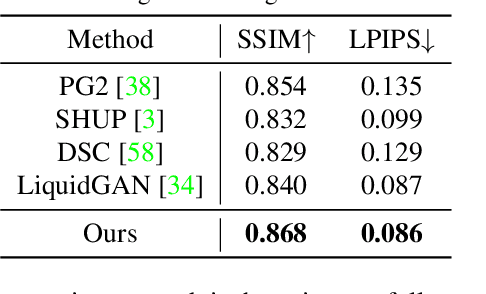
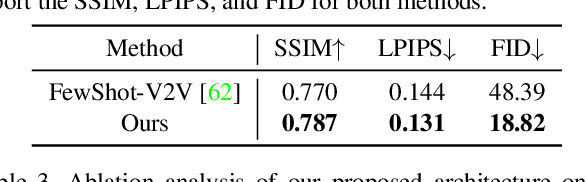

Human motion retargeting aims to transfer the motion of one person in a "driving" video or set of images to another person. Existing efforts leverage a long training video from each target person to train a subject-specific motion transfer model. However, the scalability of such methods is limited, as each model can only generate videos for the given target subject, and such training videos are labor-intensive to acquire and process. Few-shot motion transfer techniques, which only require one or a few images from a target, have recently drawn considerable attention. Methods addressing this task generally use either 2D or explicit 3D representations to transfer motion, and in doing so, sacrifice either accurate geometric modeling or the flexibility of an end-to-end learned representation. Inspired by the Transformable Bottleneck Network, which renders novel views and manipulations of rigid objects, we propose an approach based on an implicit volumetric representation of the image content, which can then be spatially manipulated using volumetric flow fields. We address the challenging question of how to aggregate information across different body poses, learning flow fields that allow for combining content from the appropriate regions of input images of highly non-rigid human subjects performing complex motions into a single implicit volumetric representation. This allows us to learn our 3D representation solely from videos of moving people. Armed with both 3D object understanding and end-to-end learned rendering, this categorically novel representation delivers state-of-the-art image generation quality, as shown by our quantitative and qualitative evaluations.
Single-Read Reconstruction for DNA Data Storage Using Transformers
Sep 12, 2021

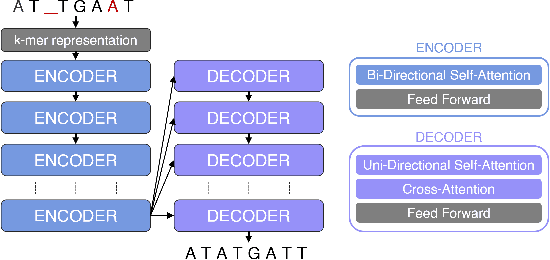
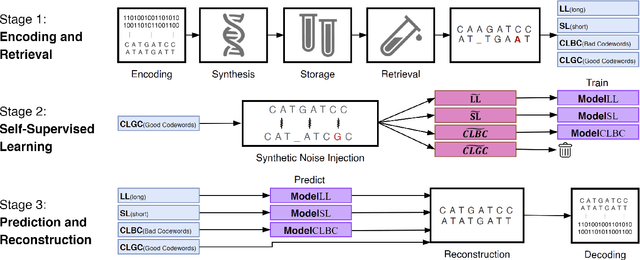
As the global need for large-scale data storage is rising exponentially, existing storage technologies are approaching their theoretical and functional limits in terms of density and energy consumption, making DNA based storage a potential solution for the future of data storage. Several studies introduced DNA based storage systems with high information density (petabytes/gram). However, DNA synthesis and sequencing technologies yield erroneous outputs. Algorithmic approaches for correcting these errors depend on reading multiple copies of each sequence and result in excessive reading costs. The unprecedented success of Transformers as a deep learning architecture for language modeling has led to its repurposing for solving a variety of tasks across various domains. In this work, we propose a novel approach for single-read reconstruction using an encoder-decoder Transformer architecture for DNA based data storage. We address the error correction process as a self-supervised sequence-to-sequence task and use synthetic noise injection to train the model using only the decoded reads. Our approach exploits the inherent redundancy of each decoded file to learn its underlying structure. To demonstrate our proposed approach, we encode text, image and code-script files to DNA, produce errors with high-fidelity error simulator, and reconstruct the original files from the noisy reads. Our model achieves lower error rates when reconstructing the original data from a single read of each DNA strand compared to state-of-the-art algorithms using 2-3 copies. This is the first demonstration of using deep learning models for single-read reconstruction in DNA based storage which allows for the reduction of the overall cost of the process. We show that this approach is applicable for various domains and can be generalized to new domains as well.
TPsgtR: Neural-Symbolic Tensor Product Scene-Graph-Triplet Representation for Image Captioning
Nov 22, 2019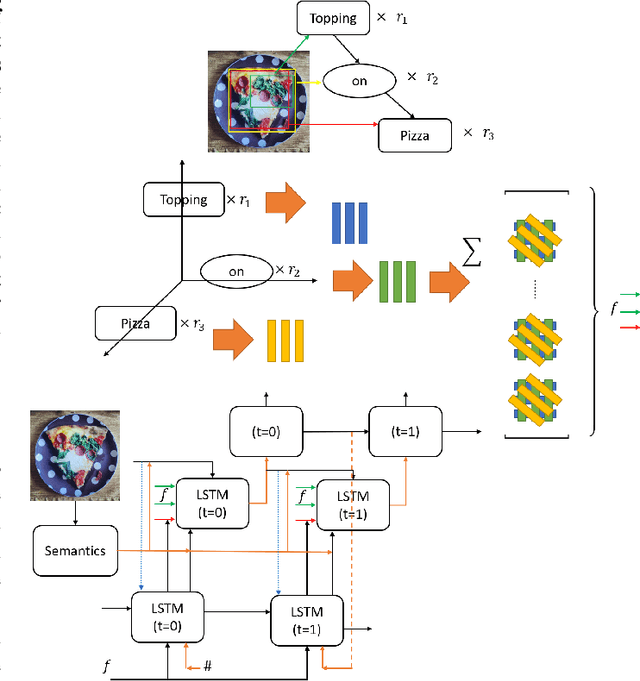
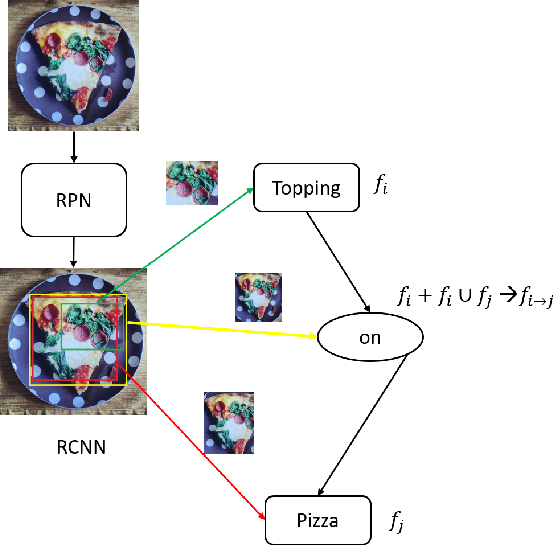
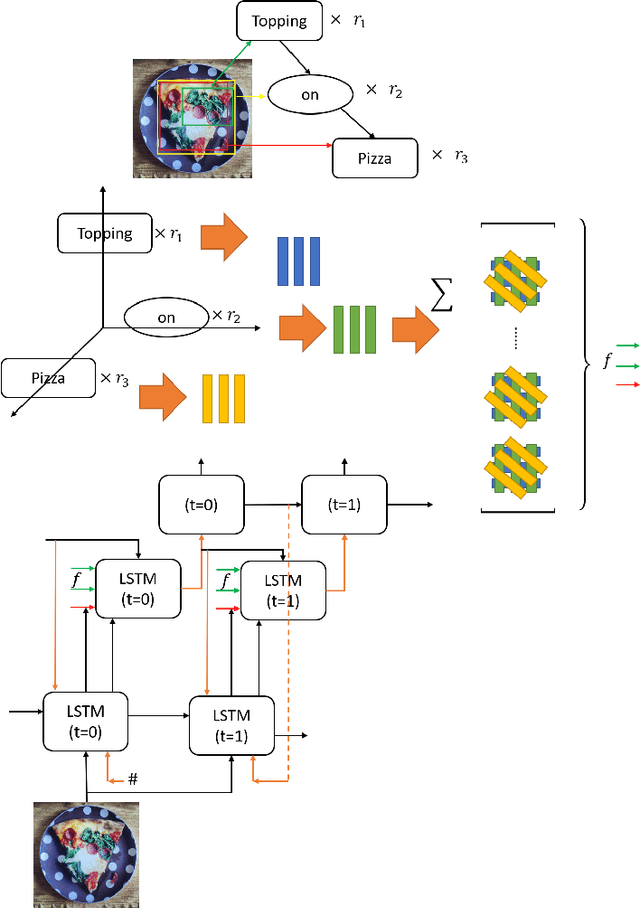
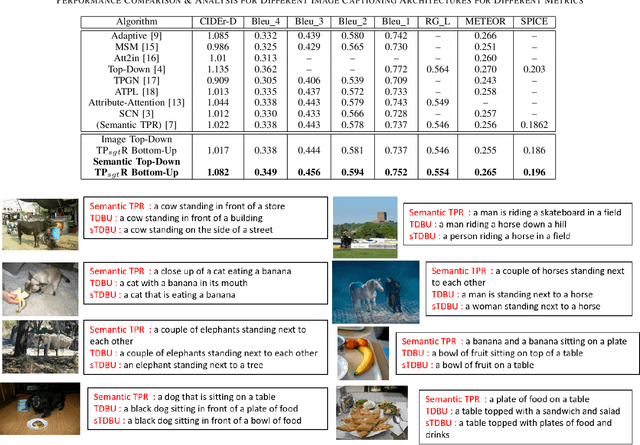
Image captioning can be improved if the structure of the graphical representations can be formulated with conceptual positional binding. In this work, we have introduced a novel technique for caption generation using the neural-symbolic encoding of the scene-graphs, derived from regional visual information of the images and we call it Tensor Product Scene-Graph-Triplet Representation (TP$_{sgt}$R). While, most of the previous works concentrated on identification of the object features in images, we introduce a neuro-symbolic embedding that can embed identified relationships among different regions of the image into concrete forms, instead of relying on the model to compose for any/all combinations. These neural symbolic representation helps in better definition of the neural symbolic space for neuro-symbolic attention and can be transformed to better captions. With this approach, we introduced two novel architectures (TP$_{sgt}$R-TDBU and TP$_{sgt}$R-sTDBU) for comparison and experiment result demonstrates that our approaches outperformed the other models, and generated captions are more comprehensive and natural.
PAS-MEF: Multi-exposure image fusion based on principal component analysis, adaptive well-exposedness and saliency map
May 25, 2021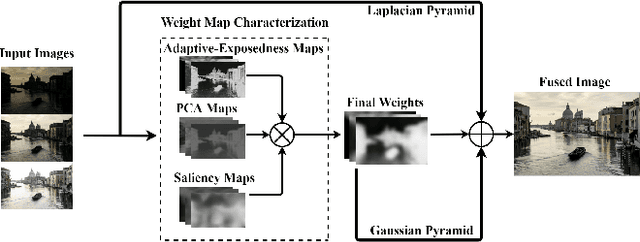
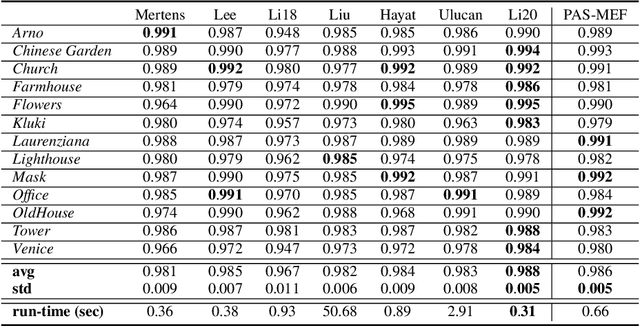


High dynamic range (HDR) imaging enables to immortalize natural scenes similar to the way that they are perceived by human observers. With regular low dynamic range (LDR) capture/display devices, significant details may not be preserved in images due to the huge dynamic range of natural scenes. To minimize the information loss and produce high quality HDR-like images for LDR screens, this study proposes an efficient multi-exposure fusion (MEF) approach with a simple yet effective weight extraction method relying on principal component analysis, adaptive well-exposedness and saliency maps. These weight maps are later refined through a guided filter and the fusion is carried out by employing a pyramidal decomposition. Experimental comparisons with existing techniques demonstrate that the proposed method produces very strong statistical and visual results.
Siamese Infrared and Visible Light Fusion Network for RGB-T Tracking
Mar 12, 2021
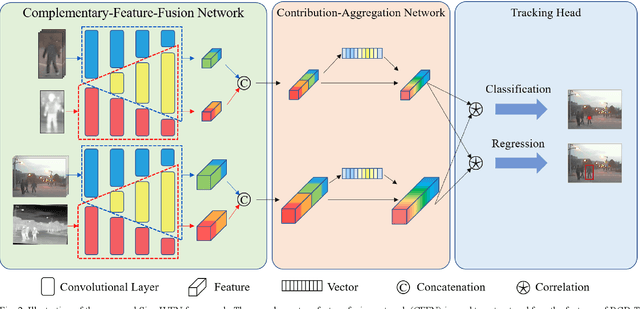
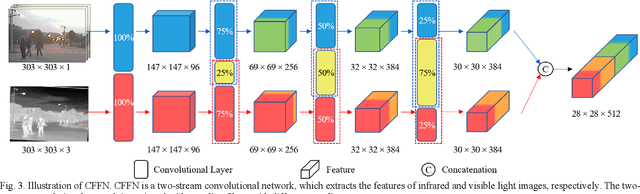
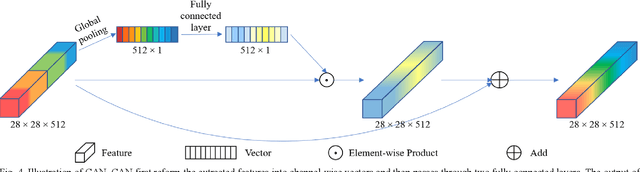
Due to the different photosensitive properties of infrared and visible light, the registered RGB-T image pairs shot in the same scene exhibit quite different characteristics. This paper proposes a siamese infrared and visible light fusion Network (SiamIVFN) for RBG-T image-based tracking. SiamIVFN contains two main subnetworks: a complementary-feature-fusion network (CFFN) and a contribution-aggregation network (CAN). CFFN utilizes a two-stream multilayer convolutional structure whose filters for each layer are partially coupled to fuse the features extracted from infrared images and visible light images. CFFN is a feature-level fusion network, which can cope with the misalignment of the RGB-T image pairs. Through adaptively calculating the contributions of infrared and visible light features obtained from CFFN, CAN makes the tracker robust under various light conditions. Experiments on two RGB-T tracking benchmark datasets demonstrate that the proposed SiamIVFN has achieved state-of-the-art performance. The tracking speed of SiamIVFN is 147.6FPS, the current fastest RGB-T fusion tracker.
SAT: 2D Semantics Assisted Training for 3D Visual Grounding
May 24, 2021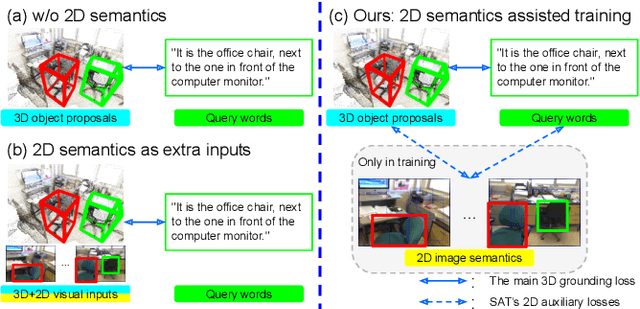
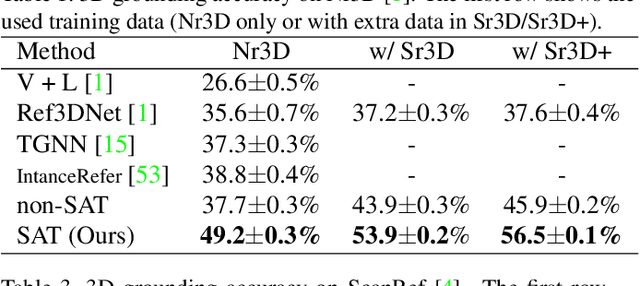
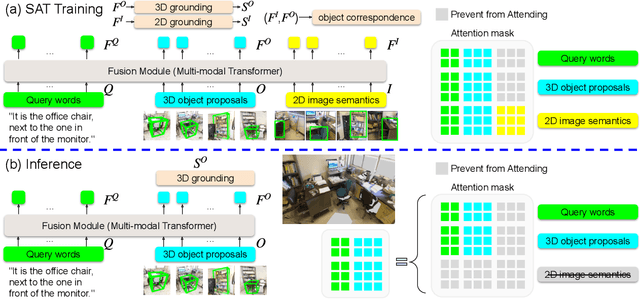
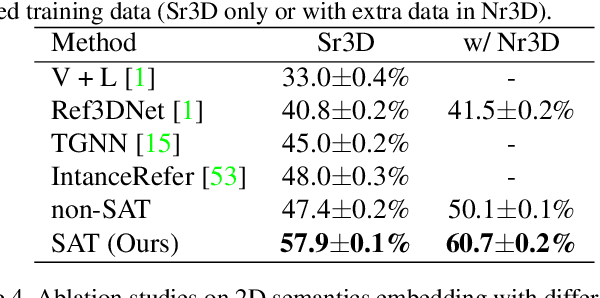
3D visual grounding aims at grounding a natural language description about a 3D scene, usually represented in the form of 3D point clouds, to the targeted object region. Point clouds are sparse, noisy, and contain limited semantic information compared with 2D images. These inherent limitations make the 3D visual grounding problem more challenging. In this study, we propose 2D Semantics Assisted Training (SAT) that utilizes 2D image semantics in the training stage to ease point-cloud-language joint representation learning and assist 3D visual grounding. The main idea is to learn auxiliary alignments between rich, clean 2D object representations and the corresponding objects or mentioned entities in 3D scenes. SAT takes 2D object semantics, i.e., object label, image feature, and 2D geometric feature, as the extra input in training but does not require such inputs during inference. By effectively utilizing 2D semantics in training, our approach boosts the accuracy on the Nr3D dataset from 37.7% to 49.2%, which significantly surpasses the non-SAT baseline with the identical network architecture and inference input. Our approach outperforms the state of the art by large margins on multiple 3D visual grounding datasets, i.e., +10.4% absolute accuracy on Nr3D, +9.9% on Sr3D, and +5.6% on ScanRef.
T-Net: A Template-Supervised Network for Task-specific Feature Extraction in Biomedical Image Analysis
Feb 19, 2020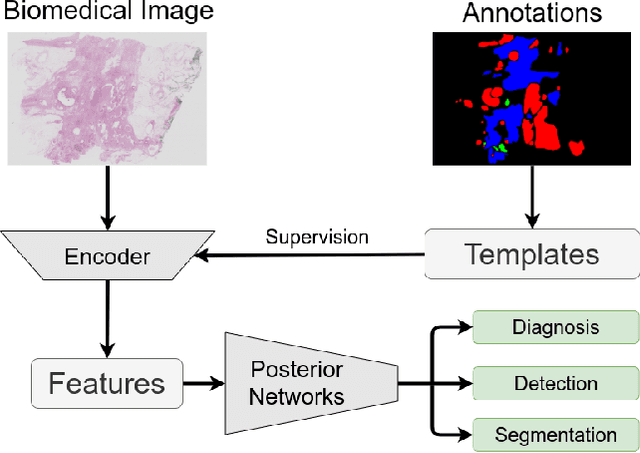

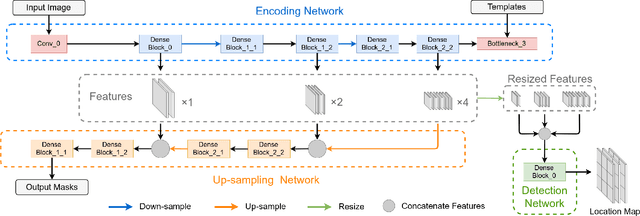
Existing deep learning methods depend on an encoder-decoder structure to learn feature representation from the segmentation annotation in biomedical image analysis. However, the effectiveness of feature extraction under this structure decreases due to the indirect optimization process, limited training data size, and simplex supervision method. In this paper, we propose a template-supervised network T-Net for task-specific feature extraction. Specifically, we first obtain templates from pixel-level annotations by down-sampling binary masks of recognition targets according to specific tasks. Then, we directly train the encoding network under the supervision of the derived task-specific templates. Finally, we combine the resulting encoding network with a posterior network for the specific task, e.g. an up-sampling network for segmentation or a region proposal network for detection. Extensive experiments on three public datasets (BraTS-17, MoNuSeg and IDRiD) show that T-Net achieves competitive results to the state-of-the-art methods and superior performance to an encoder-decoder based network. To the best of our knowledge, this is the first in-depth study to improve feature extraction by directly supervise the encoding network and by applying task-specific supervision in biomedical image analysis.
Membership Inference Attacks on Lottery Ticket Networks
Aug 07, 2021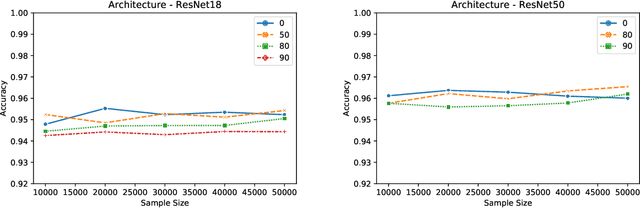
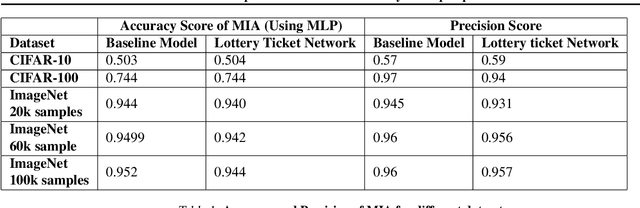
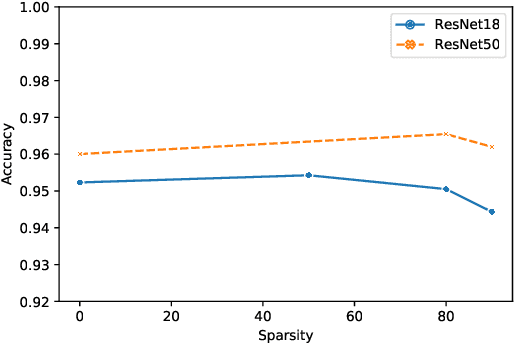
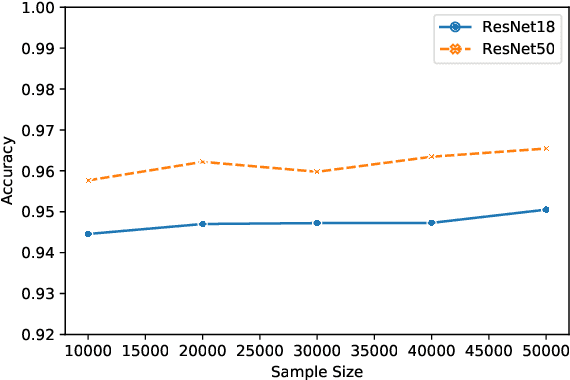
The vulnerability of the Lottery Ticket Hypothesis has not been studied from the purview of Membership Inference Attacks. Through this work, we are the first to empirically show that the lottery ticket networks are equally vulnerable to membership inference attacks. A Membership Inference Attack (MIA) is the process of determining whether a data sample belongs to a training set of a trained model or not. Membership Inference Attacks could leak critical information about the training data that can be used for targeted attacks. Recent deep learning models often have very large memory footprints and a high computational cost associated with training and drawing inferences. Lottery Ticket Hypothesis is used to prune the networks to find smaller sub-networks that at least match the performance of the original model in terms of test accuracy in a similar number of iterations. We used CIFAR-10, CIFAR-100, and ImageNet datasets to perform image classification tasks and observe that the attack accuracies are similar. We also see that the attack accuracy varies directly according to the number of classes in the dataset and the sparsity of the network. We demonstrate that these attacks are transferable across models with high accuracy.
Multi-Process Fusion: Visual Place Recognition Using Multiple Image Processing Methods
Mar 08, 2019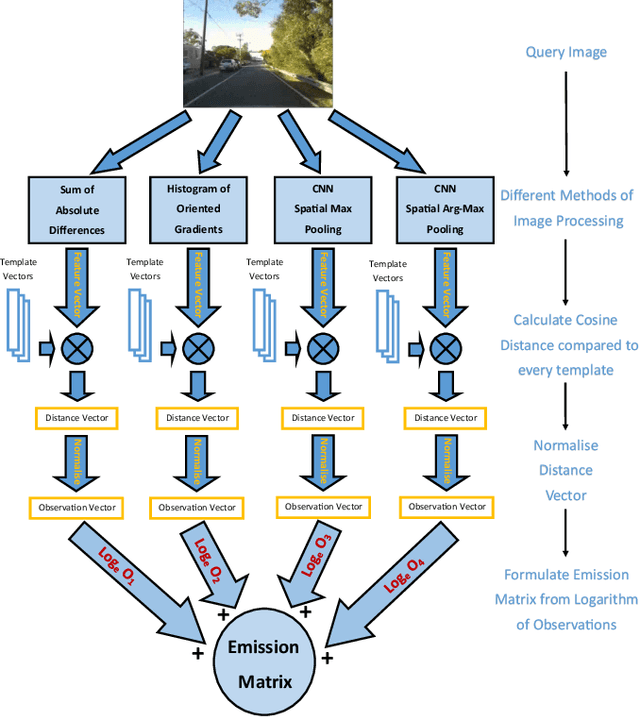
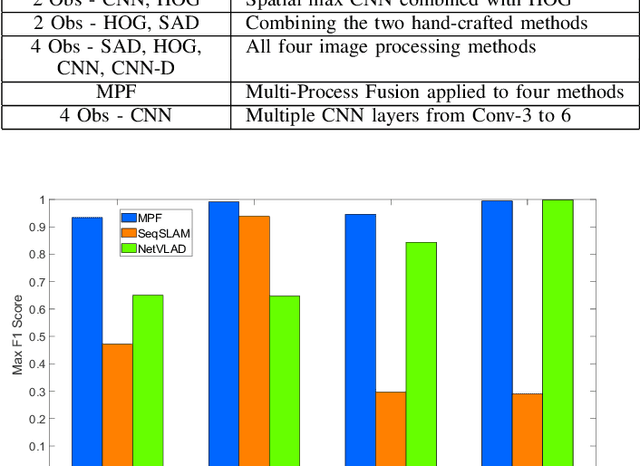
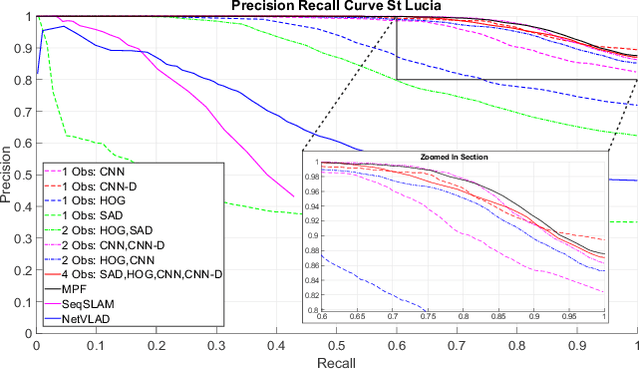
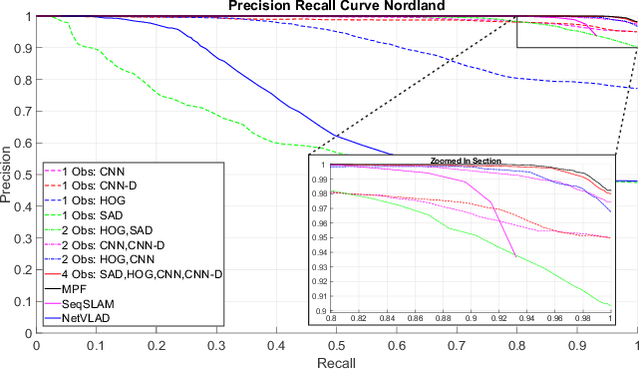
Typical attempts to improve the capability of visual place recognition techniques include the use of multi-sensor fusion and integration of information over time from image sequences. These approaches can improve performance but have disadvantages including the need for multiple physical sensors and calibration processes, both for multiple sensors and for tuning the image matching sequence length. In this paper we address these shortcomings with a novel "multi-sensor" fusion approach applied to multiple image processing methods for a single visual image stream, combined with a dynamic sequence matching length technique and an automatic processing method weighting scheme. In contrast to conventional single method approaches, our approach reduces the performance requirements of a single image processing methodology, instead requiring that within the suite of image processing methods, at least one performs well in any particular environment. In comparison to static sequence length techniques, the dynamic sequence matching technique enables reduced localization latencies through analysis of recognition quality metrics when re-entering familiar locations. We evaluate our approach on multiple challenging benchmark datasets, achieving superior performance to two state-of-the-art visual place recognition systems across environmental changes including winter to summer, afternoon to morning and night to day. Across the four benchmark datasets our proposed approach achieves an average F1 score of 0.96, compared to 0.78 for NetVLAD and 0.49 for SeqSLAM. We provide source code for the multi-fusion method and present analysis explaining how superior performance is achieved despite the multiple, disparate, image processing methods all being applied to a single source of imagery, rather than to multiple separate sensors.
* Pre-print version of article published in Robotics and Automation Letters