 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Domain Generalization via Gradient Surgery
Aug 03, 2021

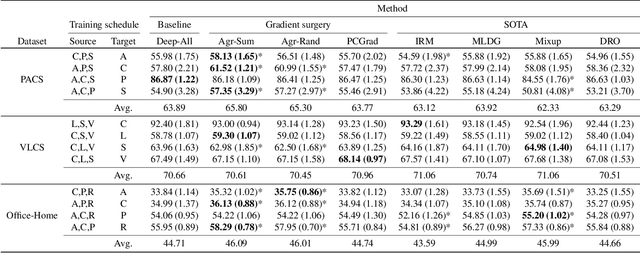
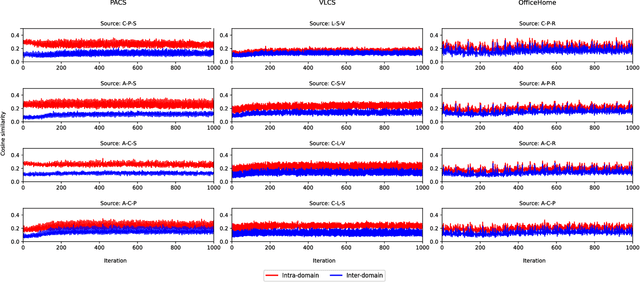
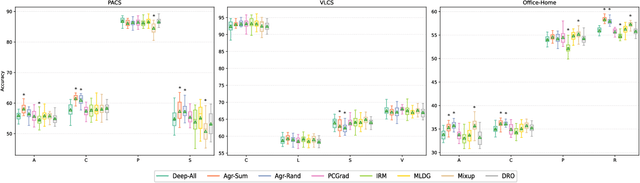
In real-life applications, machine learning models often face scenarios where there is a change in data distribution between training and test domains. When the aim is to make predictions on distributions different from those seen at training, we incur in a domain generalization problem. Methods to address this issue learn a model using data from multiple source domains, and then apply this model to the unseen target domain. Our hypothesis is that when training with multiple domains, conflicting gradients within each mini-batch contain information specific to the individual domains which is irrelevant to the others, including the test domain. If left untouched, such disagreement may degrade generalization performance. In this work, we characterize the conflicting gradients emerging in domain shift scenarios and devise novel gradient agreement strategies based on gradient surgery to alleviate their effect. We validate our approach in image classification tasks with three multi-domain datasets, showing the value of the proposed agreement strategy in enhancing the generalization capability of deep learning models in domain shift scenarios.
Interpretable Discovery in Large Image Data Sets
Jun 21, 2018
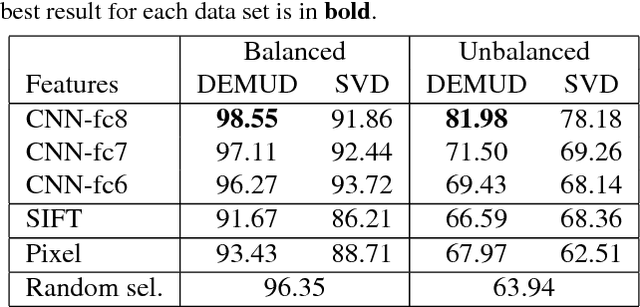
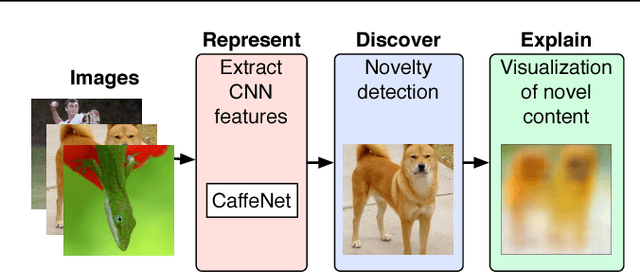
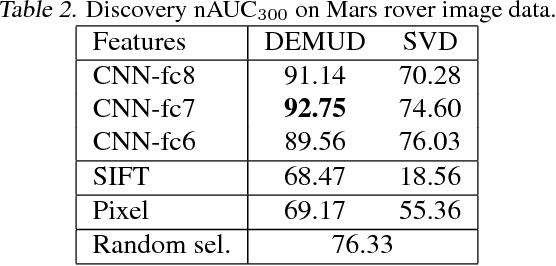
Automated detection of new, interesting, unusual, or anomalous images within large data sets has great value for applications from surveillance (e.g., airport security) to science (observations that don't fit a given theory can lead to new discoveries). Many image data analysis systems are turning to convolutional neural networks (CNNs) to represent image content due to their success in achieving high classification accuracy rates. However, CNN representations are notoriously difficult for humans to interpret. We describe a new strategy that combines novelty detection with CNN image features to achieve rapid discovery with interpretable explanations of novel image content. We applied this technique to familiar images from ImageNet as well as to a scientific image collection from planetary science.
Virus-MNIST: A Benchmark Malware Dataset
Feb 28, 2021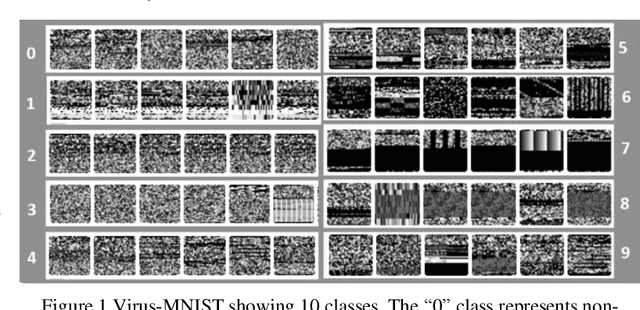
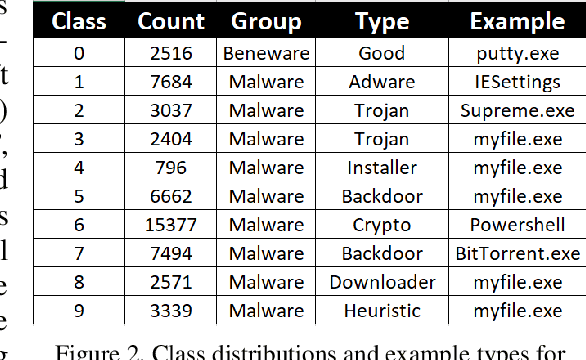
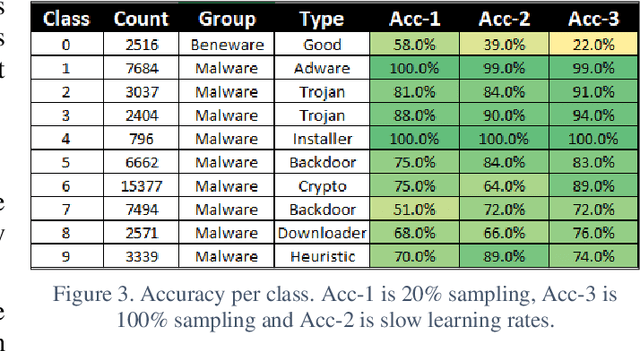
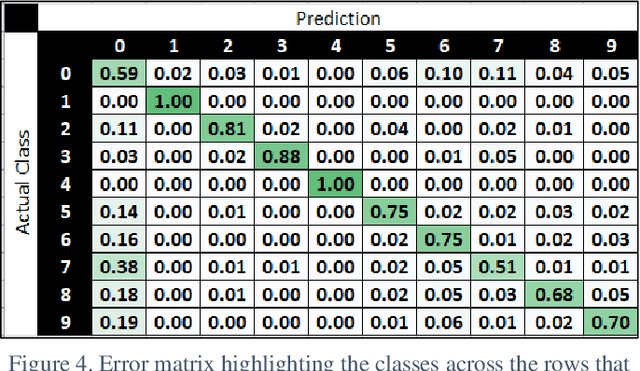
The short note presents an image classification dataset consisting of 10 executable code varieties and approximately 50,000 virus examples. The malicious classes include 9 families of computer viruses and one benign set. The image formatting for the first 1024 bytes of the Portable Executable (PE) mirrors the familiar MNIST handwriting dataset, such that most of the previously explored algorithmic methods can transfer with minor modifications. The designation of 9 virus families for malware derives from unsupervised learning of class labels; we discover the families with KMeans clustering that excludes the non-malicious examples. As a benchmark using deep learning methods (MobileNetV2), we find an overall 80% accuracy for virus identification by families when beneware is included. We also find that once a positive malware detection occurs (by signature or heuristics), the projection of the first 1024 bytes into a thumbnail image can classify with 87% accuracy the type of virus. The work generalizes what other malware investigators have demonstrated as promising convolutional neural networks originally developed to solve image problems but applied to a new abstract domain in pixel bytes from executable files. The dataset is available on Kaggle and Github.
Representation Learning for Remote Sensing: An Unsupervised Sensor Fusion Approach
Aug 11, 2021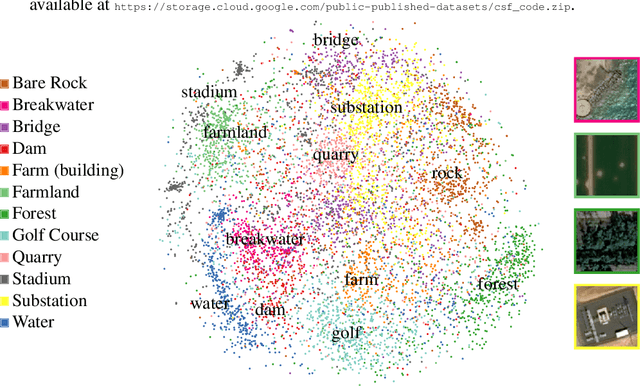
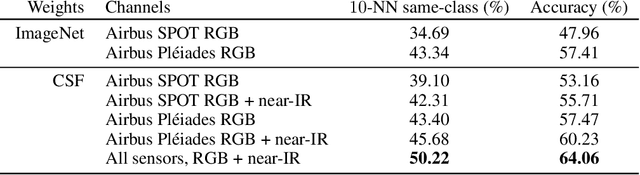

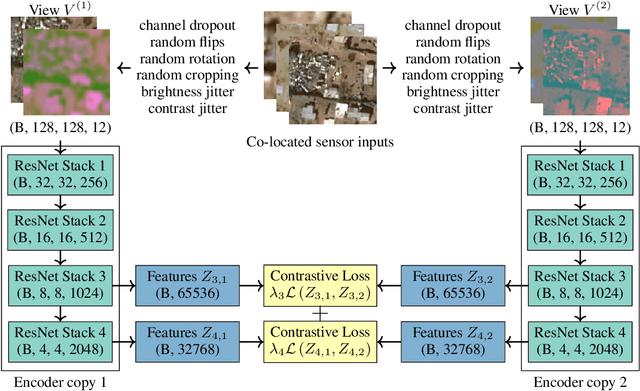
In the application of machine learning to remote sensing, labeled data is often scarce or expensive, which impedes the training of powerful models like deep convolutional neural networks. Although unlabeled data is abundant, recent self-supervised learning approaches are ill-suited to the remote sensing domain. In addition, most remote sensing applications currently use only a small subset of the multi-sensor, multi-channel information available, motivating the need for fused multi-sensor representations. We propose a new self-supervised training objective, Contrastive Sensor Fusion, which exploits coterminous data from multiple sources to learn useful representations of every possible combination of those sources. This method uses information common across multiple sensors and bands by training a single model to produce a representation that remains similar when any subset of its input channels is used. Using a dataset of 47 million unlabeled coterminous image triplets, we train an encoder to produce semantically meaningful representations from any possible combination of channels from the input sensors. These representations outperform fully supervised ImageNet weights on a remote sensing classification task and improve as more sensors are fused. Our code is available at https://storage.cloud.google.com/public-published-datasets/csf_code.zip.
SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
Aug 20, 2019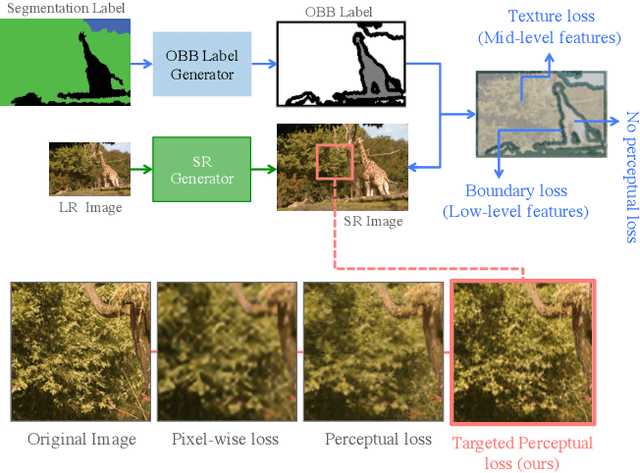
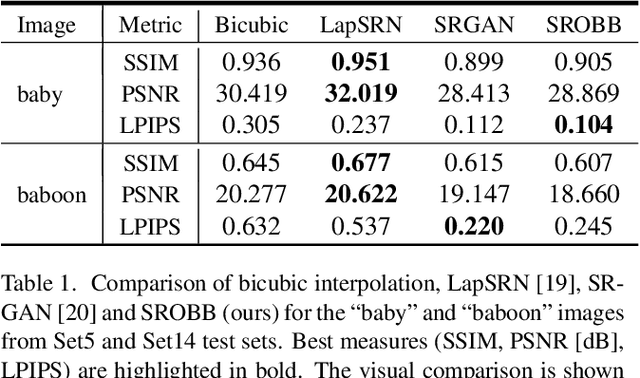

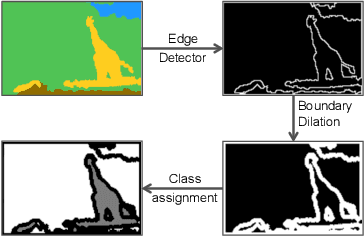
By benefiting from perceptual losses, recent studies have improved significantly the performance of the super-resolution task, where a high-resolution image is resolved from its low-resolution counterpart. Although such objective functions generate near-photorealistic results, their capability is limited, since they estimate the reconstruction error for an entire image in the same way, without considering any semantic information. In this paper, we propose a novel method to benefit from perceptual loss in a more objective way. We optimize a deep network-based decoder with a targeted objective function that penalizes images at different semantic levels using the corresponding terms. In particular, the proposed method leverages our proposed OBB (Object, Background and Boundary) labels, generated from segmentation labels, to estimate a suitable perceptual loss for boundaries, while considering texture similarity for backgrounds. We show that our proposed approach results in more realistic textures and sharper edges, and outperforms other state-of-the-art algorithms in terms of both qualitative results on standard benchmarks and results of extensive user studies.
Domain Adaptation for Real-World Single View 3D Reconstruction
Aug 24, 2021
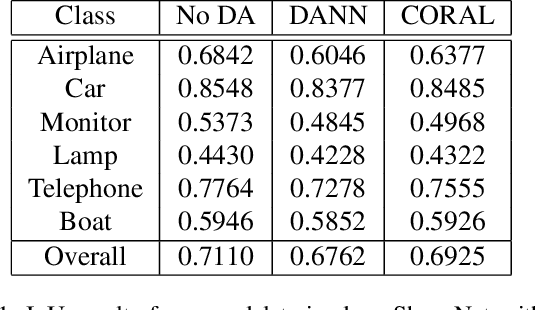
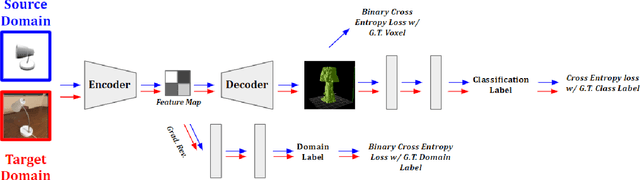
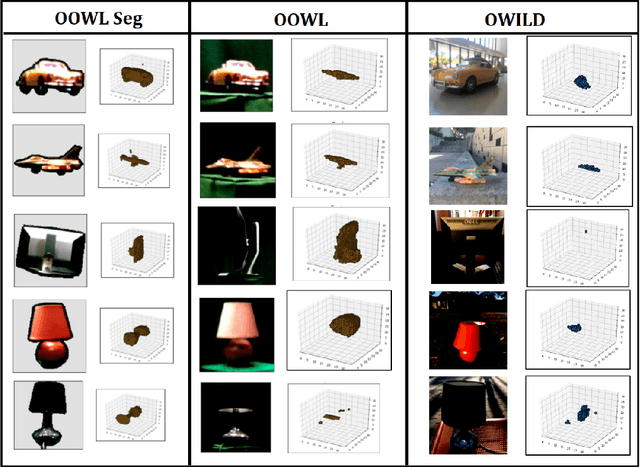
Deep learning-based object reconstruction algorithms have shown remarkable improvements over classical methods. However, supervised learning based methods perform poorly when the training data and the test data have different distributions. Indeed, most current works perform satisfactorily on the synthetic ShapeNet dataset, but dramatically fail in when presented with real world images. To address this issue, unsupervised domain adaptation can be used transfer knowledge from the labeled synthetic source domain and learn a classifier for the unlabeled real target domain. To tackle this challenge of single view 3D reconstruction in the real domain, we experiment with a variety of domain adaptation techniques inspired by the maximum mean discrepancy (MMD) loss, Deep CORAL, and the domain adversarial neural network (DANN). From these findings, we additionally propose a novel architecture which takes advantage of the fact that in this setting, target domain data is unsupervised with regards to the 3D model but supervised for class labels. We base our framework off a recent network called pix2vox. Results are performed with ShapeNet as the source domain and domains within the Object Dataset Domain Suite (ODDS) dataset as the target, which is a real world multiview, multidomain image dataset. The domains in ODDS vary in difficulty, allowing us to assess notions of domain gap size. Our results are the first in the multiview reconstruction literature using this dataset.
Real-time Indian Sign Language (ISL) Recognition
Aug 24, 2021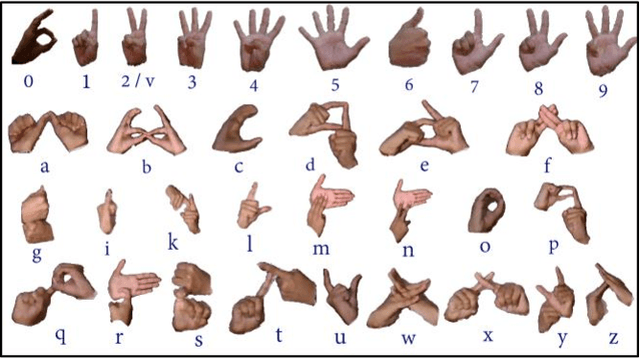
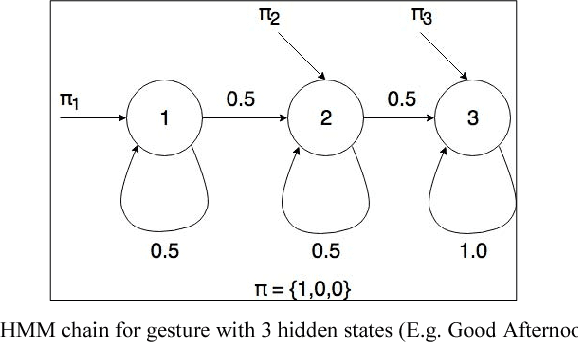

This paper presents a system which can recognise hand poses & gestures from the Indian Sign Language (ISL) in real-time using grid-based features. This system attempts to bridge the communication gap between the hearing and speech impaired and the rest of the society. The existing solutions either provide relatively low accuracy or do not work in real-time. This system provides good results on both the parameters. It can identify 33 hand poses and some gestures from the ISL. Sign Language is captured from a smartphone camera and its frames are transmitted to a remote server for processing. The use of any external hardware (such as gloves or the Microsoft Kinect sensor) is avoided, making it user-friendly. Techniques such as Face detection, Object stabilisation and Skin Colour Segmentation are used for hand detection and tracking. The image is further subjected to a Grid-based Feature Extraction technique which represents the hand's pose in the form of a Feature Vector. Hand poses are then classified using the k-Nearest Neighbours algorithm. On the other hand, for gesture classification, the motion and intermediate hand poses observation sequences are fed to Hidden Markov Model chains corresponding to the 12 pre-selected gestures defined in ISL. Using this methodology, the system is able to achieve an accuracy of 99.7% for static hand poses, and an accuracy of 97.23% for gesture recognition.
* 9 pages
Kernel-Free Image Deblurring with a Pair of Blurred/Noisy Images
Mar 27, 2019
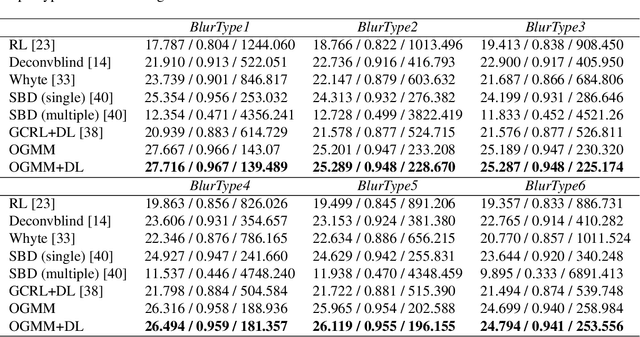
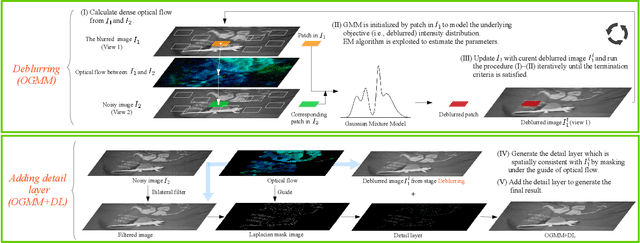

Complex blur like the mixup of space-variant and space-invariant blur, which is hard to be modeled mathematically, widely exists in real images. In the real world, a common type of blur occurs when capturing images in low-light environments. In this paper, we propose a novel image deblurring method that does not need to estimate blur kernels. We utilize a pair of images which can be easily acquired in low-light situations: (1) a blurred image taken with low shutter speed and low ISO noise, and (2) a noisy image captured with high shutter speed and high ISO noise. Specifically, the blurred image is first sliced into patches, and we extend the Gaussian mixture model (GMM) to model the underlying intensity distribution of each patch using the corresponding patches in the noisy image. We compute patch correspondences by analyzing the optical flow between the two images. The Expectation-Maximization (EM) algorithm is utilized to estimate the involved parameters in the GMM. To preserve sharp features, we add an additional bilateral term to the objective function in the M-step. We eventually add a detail layer to the deblurred image for refinement. Extensive experiments on both synthetic and real-world data demonstrate that our method outperforms state-of-the-art techniques, in terms of robustness, visual quality and quantitative metrics. We will make our dataset and source code publicly available.
S4T: Source-free domain adaptation for semantic segmentation via self-supervised selective self-training
Jul 21, 2021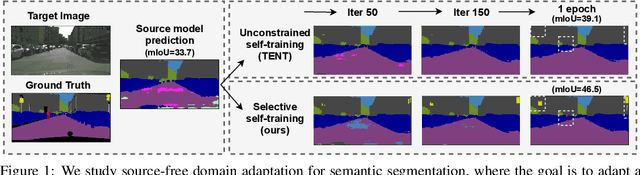
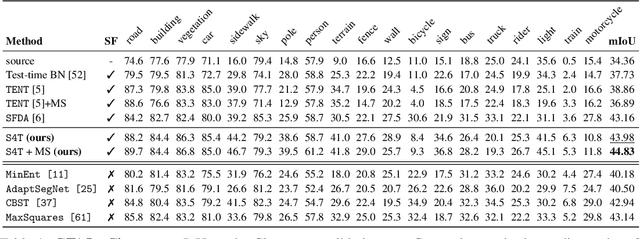
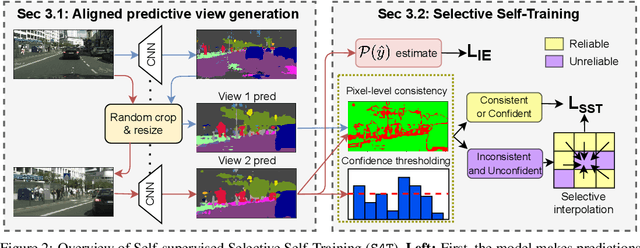

Most modern approaches for domain adaptive semantic segmentation rely on continued access to source data during adaptation, which may be infeasible due to computational or privacy constraints. We focus on source-free domain adaptation for semantic segmentation, wherein a source model must adapt itself to a new target domain given only unlabeled target data. We propose Self-Supervised Selective Self-Training (S4T), a source-free adaptation algorithm that first uses the model's pixel-level predictive consistency across diverse views of each target image along with model confidence to classify pixel predictions as either reliable or unreliable. Next, the model is self-trained, using predicted pseudolabels for reliable predictions and pseudolabels inferred via a selective interpolation strategy for unreliable ones. S4T matches or improves upon the state-of-the-art in source-free adaptation on 3 standard benchmarks for semantic segmentation within a single epoch of adaptation.
RFN-Nest: An end-to-end residual fusion network for infrared and visible images
Mar 14, 2021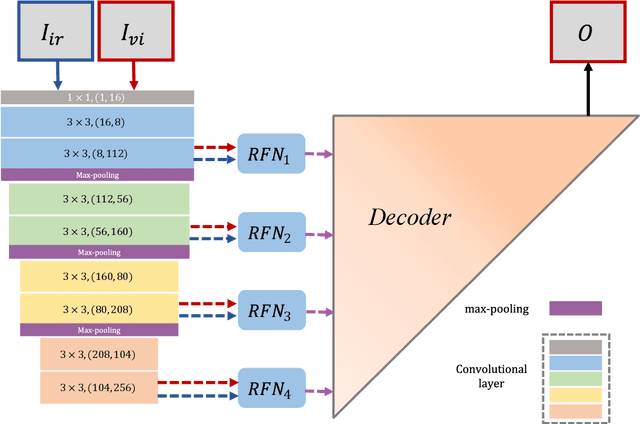
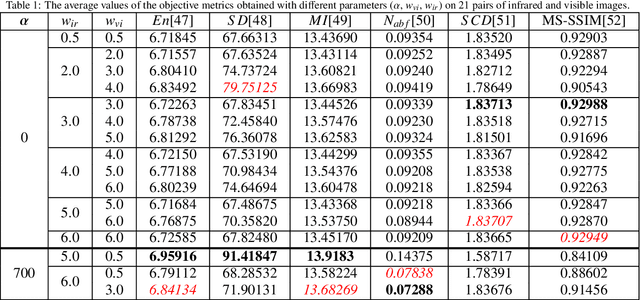
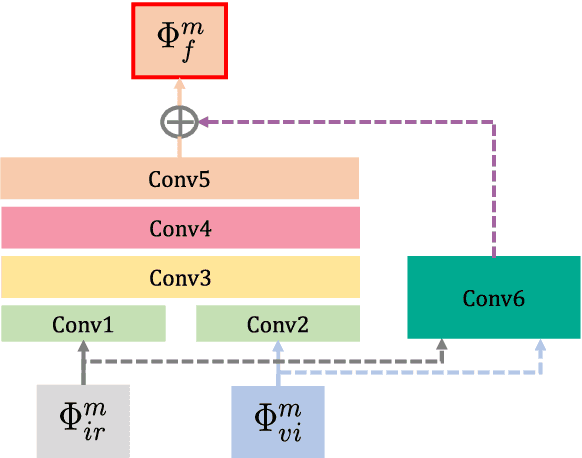

In the image fusion field, the design of deep learning-based fusion methods is far from routine. It is invariably fusion-task specific and requires a careful consideration. The most difficult part of the design is to choose an appropriate strategy to generate the fused image for a specific task in hand. Thus, devising learnable fusion strategy is a very challenging problem in the community of image fusion. To address this problem, a novel end-to-end fusion network architecture (RFN-Nest) is developed for infrared and visible image fusion. We propose a residual fusion network (RFN) which is based on a residual architecture to replace the traditional fusion approach. A novel detail-preserving loss function, and a feature enhancing loss function are proposed to train RFN. The fusion model learning is accomplished by a novel two-stage training strategy. In the first stage, we train an auto-encoder based on an innovative nest connection (Nest) concept. Next, the RFN is trained using the proposed loss functions. The experimental results on public domain data sets show that, compared with the existing methods, our end-to-end fusion network delivers a better performance than the state-of-the-art methods in both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-rfn-nest